






手机微信扫一扫联系客服
联系电话:18046269997



 APP安装免填邀请码
APP安装免填邀请码 社交分享效果统计
社交分享效果统计 广告投放数据统计
广告投放数据统计 CPA/CPS推广效果统计
CPA/CPS推广效果统计 App地推统计
App地推统计 App拉起
App拉起 网页/应用内直接安装
网页/应用内直接安装 Android多渠道打包
Android多渠道打包 App安装后自动绑定
App安装后自动绑定 App分享效果统计
App分享效果统计 Deeplink深度链接
Deeplink深度链接 手机微信扫一扫联系客服

大厂角逐大模型Skill商店混战?无界面任务流量、个性化工作流分发如何强力颠覆原有的App Store应用下载逻辑——这一智能化商业范式的变革已在 36氪 · 腾讯、阿里、字节,混战Skill商店 的重磅特稿中得到确凿印证。2026年6月3日,随着腾讯、阿里、字节相继在旗下Agent底座上线Skill商店,智谱、月之暗面、美团、小红书也全线切入这一风暴中心。作为AI Agent核心“操作手册”的结构化指令文件,Skill正在从极客圈的开源脚本,代际演进为全网巨头抢占AI时代超级流量入口的战略高地。当分发秩序全面向无界面、非线性的指令内循环转型,传统基于应用市场下载、页面视窗浏览和离散点击的粗放引流模式,正面临着地基被彻底抽空的技术危机。在这场全面重新划定外部App激活边界的Skill商店混战中,企业技术负责人与增长操盘手究竟该如何在去应用化的“任务流量”黑盒中认清流量真身?新闻与环境拆解:三类玩家多维卡位,重构AI时代分发版图根据搜狐号 Skill商店混战:腾讯、阿里、字节的AI战略博弈 的完整记录,当前的Skill市场早已跨越了“概念画饼”阶段,演变为各路资本收拢流量所有权、转嫁算力开支的终极杀阵。由于Skill本质上是把个性化方法论封装成标准化的执行路径,用户习惯在何处获取Skill,就会在对应的生态内部产生高密度的全场景消费。互联网大厂以免费Skill为饵,赚取云算力与交易抽成阿里在其JVS Claw Agent里内置了“虾小宝”Skill市场,用户一键同步调用看似免费,背后消耗的每一步 Token 都在直接拉动阿里的公有云算力大盘。字节跳动则双管齐下,火山引擎针对企业级市场推出Find Skill,而扣子(Coze)商店则面向普通大众甚至支持Skill创作者定价售卖,强力抢夺开发者生态。腾讯的动作更为硬核,其SkillHub不仅是海外ClawHub的本土化镜像站点,更背靠微信小程序生态。腾讯能够把数百万成熟的小程序商业履约链路直接封装为标准化的Skill,其最终瞄准的是长周期的交易抽成与高干净度的广告回传流水。大模型公司加速模型适配,筑牢自主流量护城河智谱在旗下Auto Claw上线的AgentMore Skills广场,主打一键零Token安装;月之暗面则依托Kimi Claw,让打工人在浏览器里就能一键部署Open Claw并配置技能库。对于大模型公司而言,Skill商店能够带动自家底层大模型的持续高频调用。开发Skill商店是获取并留住用户的最核心入口,在Skill商店混战的棋局下,高粘性的Skill是“饵”,高并发的模型调用量才是真正的“鱼”。本地生活与内容平台跨界反哺,颠覆性嵌入内容推荐路线美团通过推出AI Agent生态导航xia345和公测AI社区“觅游”,在短短两个月内收录了超过4万个Skill,用长程场景交互大幅延长用户在美团体系内的停留时间,为主业的外卖与到店反哺流量。小红书则推出Red Skill,直接在帖子下方挂载Skill安装指令,将去界面化的工具形态彻底转化为可被浏览、被圈层推荐的社交货币,借此疯狂收割广告流量。从新闻到用户路径的归因问题:个性化工作流引发的统计黑盒上游大厂在Skill商店混战中杀红了眼,但对于下游外部App的技术总监与增长负责人而言,当“技能(Skill)”正在取代“应用(App)”成为用户意图转化的第一触点时,传统的营销漏斗和数据追踪管线正在全面失效。在去应用化的指令洪流中,用户的决策路径已从单向线性的广告点击,退化为了由智能体在后台全权代劳的“非线性复访网状图谱”:用户在小红书被种草 ──> 一键复制安装Red Skill ──> 触发AI行为预测 ──> 智能体在后台跨多端、多沙盒自动编排长任务 ──> 自动化拉起外部Skill组件 ──> 经历48小时以上的异步复访 ──> 无感完成深度履约。在这一串极其抽象的机器运行周期中,传统的第三方流量统计看板暴露出前所未有的工程盲区:输出不确定性与高随机性加剧路径碎裂: 正如独立开发者在调研中提到的痛点,同一个Skill在不同的Agent、换个模型或上下文环境下,产出的效果和环境指纹可能差出数倍。由于AI本身的随机性,用户在经历长周期复访后,传统的同频即时归因(如简单匹配点击时间戳)会在跨越不同大厂数据沙盒时被全面剥离,导致后链路的应用激活数据与前期的种草源头彻底失联,大面积滑入无法识别的“自然流量”黑洞。关于如何穿透网页与原生应用之间的系统高墙,团队必须升级底层的跨端参数恢复通路,这在行业白皮书《跨平台获客归因如何实现?打通网页与应用归因链路》中已经得到了系统性的工程论证。成本不透明与Token黑盒扼杀投流算法: 完成同一个任务,不同Skill消耗的Token量差距无法预估。由于缺乏统一的效果评判看板,外部应用根本无法感知自己是被大厂哪一个高敏技能包、哪一次高频Token调用所唤醒。平台的算法解释权被完全垄断,导致开发团队在优化自身的投流模型时完全处于半盲状态。为了对外抗衡这一黑盒现象,增长负责人必须将数据监测下沉到统一的底层看板中,建议深入参考《亚马逊 AI 战略升级?多云多 Agent 时代 App 该怎么认清流量真身》里的全链路穿透逻辑,构建起自主的数据收束闭环。恶意恶意投毒与黑产刷量引发财务危机: 随着Skill商店混战红利期开启,行业内高频爆发仿冒热门Skill名称、在上游上架并恶意投毒窃取用户数据的安全先例。新型网络黑产更利用自动化脚本和虚拟设备农场,高频伪造高复访的Skill代理调用,制造大量的假激活与假留存。如果企业不具备在入口层进行白盒化多维特征核验的反作弊基建,营销预算将被巨大的虚假泡沫迅速吞噬。工程实践:在Skill分发时代重构安装归因与数据对账面对大厂Skill商店混战与任务流量替代页面流量的长期趋势,应用开发团队必须在工程实践上做出升级,构建具备高公信力的全渠道归因底座。渠道编号 ChannelCode:多源入口特征的网状一体化对账要在去应用化、多端纠缠的生态中捍卫自身的数据分配主权,首要任务是在公域引流的第一触点上打上长效追踪指纹。运营团队在进行跨Skill商店买量、大促分会场引流或多素材矩阵种草时,应当全面废弃传统粗放、效率低下的多渠道包打包策略。技术团队应采用渠道编号 ChannelCode 的标识重构策略。通过动态生成携带唯一 channelCode 参数的标准化 H5 落地页链接,将每一个行业专属Skill、达人分发位或推广批次生成全局唯一入口指纹。无论用户是在大厂的哪一个Skill商店内被唤醒,落地页的 Web SDK 都能稳健地捕获该唯一 渠道编号 ChannelCode,连同脱敏后的设备特征(如系统微版本、时区偏移量、屏幕像素密度等非隐私环境快照)作为元数据标识一同上报至归因服务器,利用统一的标识在看板拉通数据,实现秒级排重与高干净度对账。智能传参安装:打破搜索即决策与转化断点的无感履约还原在Skill商店混战将公域流量引向去中心化工作流的变局下,外部应用承接流量的转化漏斗必须做到绝对的“零步阻碍”。若新用户通过智能体分发路径下载应用后,被扔进通用的系统首页、需要再次手动搜索指定场景,其转化漏斗必然面临雪崩式的流失。为了实现零摩擦的无缝场景还原,技术团队可以在数据管线中部署智能传参方案。在用户触发意图的一瞬间,Web 端 SDK 将当前的上下文信息(如工作流路径、任务来源标签、特定商品参数)与脱敏指纹进行云端挂载。当应用在终端完成首次下载并启动的黄金3秒内,无损传参总线直接执行一键拉起与场景还原,在无需用户进行任何手动输入的前提下,直接把参数无感还原进后端的分析数据库中。这套精细化管道的搭建逻辑,完美契合了《智能体分发时代 App 安装传参逻辑的底层重构》中关于免填邀请码与App免邀请码安装的演进路径,能让应用开屏即直达指定履约内页,将流量泡沫无情戳破。注:本文探讨的跨大厂 Skill 商店分发、个性化工作流流转、以及参数自动化合并场景,属于对未来应用分发趋势的前瞻性技术延展与思考,例如渠道精细化归因、跨平台一键拉起、免填邀请码链路优化等前沿应用方向。目前此类高度定制化链路已作为 Xinstall 平台的定向技术储备,旨在帮助中大型企业攻克精细化增长诉求,如 App 开发者有类似高阶业务需求,欢迎联系 Xinstall 客服团队进行技术探讨或共同定向研发拓展。这件事和开发 / 增长团队的关系在上游巨头联手向全网兜售“可能性”、重塑底层操作系统分发秩序的变盘点上,研发总监与增长负责人的认知框架必须同步升维。面向开发 / 架构团队:从离散节点埋点向连续状态图重构标准化 payload 接口设计: 技术架构师在重构客户端数据仓时,必须在标准的埋点模型中预留用于承接外部智能体和Skill工作流的标准化字段。在用户激活与首启的核心 API 接口中,统一规范预留 agent_platform(智能体平台)、workflow_id(工作流路径)、channel_code(入口唯一渠道编号)及 risk_level(风控防刷等级),将数据结构从“离散节点”全面升维为“连续状态图”。打通接口级广告数据回传反哺: 技术团队应立即利用高可用、解耦的依赖注入机制,将归因服务器精准解析出的后链路深度行为数据(如真实激活、留存、大促期间的实付转化率),通过标准的 API 通道实时反哺给媒体端。只有用高质量的激活源头数据喂饱媒体的 AI 投放模型,才能降低无效的算力损耗与广告投放数据统计带来的获客成本成本。面向产品 / 增长团队:收拢归因解释权与联动风控审计建立基于任务价值的白盒化对账卡尺: 增长团队在面对Skill商店混战诱发的多端网状交互时,不能再盲信大厂提供的单方报表。必须建立起能够聚合看清全渠道、跨平台流量真身的数据看板,算清每一笔 Token 消耗与真实用户全生命周期价值(LTV)的底层账本,利用多元风控机制精准隔离黑产自动化脚本高频刷出的虚假复访。场景语义与产品承接的深度融合: 产品经理应紧跟大厂向垂直办公刚需与高溢价场景(如金融摘要、合同审核等)的流量倾斜,在引引流路径中精细化打磨干货攻略与服务承接的无缝连接。通过更加轻量、合规的无感携参方案,利用高效的智能传参技术将公域涌现的无感意图流量,高效转化为自身私域高留存、高价值的核心资产。常见问题(FAQ)大模型Skill商店和移动互联网时代的 App Store 有何本质区别?移动互联网时代的 App Store 兜售的是“确定性”,一个 App 在任何人的终端上运行的功能、视觉和体验都是绝对一致的。而Skill商店混战中兜售的是“可能性”,Skill 作为给 AI 智能体准备的结构化指令操作手册,其最终的产出效果高度依赖底层搭载的模型性能、环境上下文参数的长效保持以及AI本身的随机性,天然具备极强的个性化、非标准化属性。在各大厂的 Skill 商店混战中,为什么小红书的内容推荐路线被业界看好?因为目前的大模型 Skill 还缺少统一、跨平台的标准化评估体系,用户在挑选 Skill 时面临着极高的信任门槛和筛选成本。大厂和大模型公司往往依赖传统的货架展示和搜索逻辑,而小红书将 Skill 变成了可以被达人演示、被普通用户浏览与点赞的内容品类,通过高情感共鸣的短视频或图文帖子进行内容推荐,在 Skill 还没完成全面标准化的阶段,内容平台具有天然的传播与获客优势。为什么在Skill工程化落地过程中,大厂和企业越来越重视 Token 消耗的精算?因为随着多智能体协同和长任务 Agent 逻辑的演进,完成一个复杂的企业级业务(如自动化生成报表、合同风控前置)通常需要连续调度多个 Skill 模块,这会导致 Token 的消耗量在后台呈百倍级的量级暴增。由于成本不透明,如果企业不建立全链路的白盒化感知看板,将极易被黑产的恶意高频调用拖入重载算力的财务黑洞中。行业动态观察深入审视大模型软件与智能体基础设施的支出大盘,整个移动互联网经济体系正加速从“参数内卷”向“结果交付”进行冷酷的范式转移。当腾讯、阿里、字节携全栈智算底座深度介入Skill商店混战,当多端网络演进开始将无界任务流作为产品迭代的核心标杆,传统的依靠广撒网买量、或者寄希望于靠一两句静态标签配置就能混到泛流量的粗放买量时代,已经在一夜之间被彻底终结。平台在用流量奖励真正能解决问题的人,而市场也在用最无情的经营效益账淘汰那些技术架构陈旧的团队。这恰恰说明了智能化范式的代际跃迁,并正以不可逆转之势重塑全网分发格局。对于移动应用、游戏与数字化操盘手而言,及早升级自身的底层数据统计与归因体系,企业才能在这场去泡沫化战役中赢得确定性的长效商业红利,稳步跨越这一场向智能化跃迁的时代大洗牌。
 322
322
微信联手手机厂商A2A助手能力?语音直达底层指令击碎原生系统壁垒——这一终端系统层级交互范式的颠覆已在 36氪 · 微信正与手机厂商合作推出Agent-to-Agent助手能力 这一轰动科技圈的独家报道中得到确凿印证。据悉,微信正深度联合华为、荣耀、小米、OPPO、vivo等国内一线手机厂商,全线灰度内测A2A(Agent-to-Agent)智能体对账网络。用户无需手动解锁屏幕并寻找App图标,仅凭系统级语音助理即可跨越沙盒壁垒,直达原生应用的最底层指令完成跨应用调度。当数字生态的分发逻辑从“人点击视窗”直接让渡为“OS智能体协同履约”,长达十年的流量分发秩序正迎来颠覆性的技术重组。在这一场横跨系统底层与大厂生态的迁徙潮中,开发者、产品经理与增长负责人究竟该如何在去界面化的“任务流量”洪流中认清流量真身?新闻与环境拆解:A2A协作机制开启系统级意图内循环根据权威财经媒体 钛媒体 · 微信正与手机厂商合作推出Agent-to-Agent助手能力 的多方跟进,这次低调卡位的A2A助手能力,代表着大模型生态正式完成了从云端Demo到手机硬件OS内核的深度流转。这套技术方案的本质,是让不同厂商自研的手机智能体与微信庞大的基础能力实现底层的无缝挂载。双重授权机制与全面灰度的时间表确立根据行业媒体 观点网 · 微信正与华为等手机厂商合作推出A2A助手能力 披露的公开资料整理,该能力建立在极为严格的A2A协作机制之上。它由厂商侧的AI助手直接向应用端发起结构化指令,应用负责在沙盒内部安全执行并瞬时返回高干净度的执行结果。为了死守隐私红线,全链路采用了双重授权机制来保障数据安全。目前,荣耀Magic8系列、500系列和X70全系列已率先支持该项能力,相关功能正在面向全网逐步开放中。软硬件版本底座完成全面代际对齐技术对账单显示,用户只需将荣耀YOYO智能体更新至90.10.30.063及以上版本,同时将微信升级至8.0.72最新版本,即可直接通过唤醒词下达深度意图指令。用户无需多余的手工点击动作,即可一句话命令系统语音发微信消息、拨打特定好友的微信语音或视频通话。这套极简工作流的跑通,标志着系统级语音助手已经从简单的“关键词匹配”跃升为真正的“连续状态规划器”。腾讯MaaS生态与14亿用户体量的天然宿主优势腾讯总裁刘炽平在分析师财报电话会议中曾明确表示:“除基础大模型外,具备自主执行能力的AI智能体已显现出突破性应用价值。微信平台天然具备承载AI智能体的多重优势。”结合腾讯此前针对个人、企业及开发者推出的QClaw、WorkBuddy、OpenClaw三大主力智能体产品,这次A2A能力的推出,实际上是将微信14亿的用户体量(指微信全量生态大盘)全面升级为操作系统底座的一等公民。从新闻到用户路径的归因问题:跨系统意图路由带来的全链路数据断层上游芯片巨头、OS厂商与国民级社交巨头正在紧锣密鼓地重组人机交互界面,但对处于买量获客下半场的外部应用操盘手而言,当微信AI智能体通过A2A机制将流量全面截留在操作系统最底层时,现有的增长漏斗模型正面盘滑向失效的深渊。当超级智能体已成现实,用户的消费旅程被彻底异变为了极其复杂的“非线性复访网状图谱”:用户在端外(如AI搜索、系统负一屏、短视频智能卡片)输入意图指令 ──> 触发手机厂商智能体(如YOYO) ──> A2A分布式协议跨沙盒路由 ──> 微信等内循环Skill响应 ──> 自动化触发拉起组件 ──> 无感完成深度履约。在这一串机器速度主导的执行链条中,传统的页面流量(Page Traffic)被高维的任务流量(Task Traffic)无情碾压。传统的第三方广告效果监测和统计架构正暴露出难以弥合的技术盲区:系统黑盒与跨沙盒流转导致指纹被剥离: 当用户通过系统语音直接下达转化指令时,中间不再经过传统网页H5的点击和重定向视窗。传统的买量归因模型(如匹配手工剪贴板、简单比对同频即时时间戳)会在智能体跨越操作系统数据沙盒、执行隐私隔离洗涤的过程中被层层过滤。当App在终端被拉起或激活时,底层的下载源头与最前期的种草位彻底失联,导致高价值的新客高频掉入无法追溯的“自然流量”黑洞。关于如何解决这种由于交互去应用化带来的转化断点,团队必须升级底层的跨端参数恢复管线,这在由行业专家撰写的《智能体分发时代 App 安装传参逻辑的底层重构》中已经得到了系统性的工程论证。大厂算法黑盒独占归因解释权: 外部应用根本无法通过自研手段探知自己是被哪一个系统级Skill所唤醒,也无法得知用户最初在负一屏沉淀的真实意图指纹。缺乏白盒化的数据看板,企业的全渠道归因就会彻底变成瞎子摸象,投流ROI完全在信息不对称中走向失控。高并发延迟加剧召回偏误与黑产欺诈风险: A2A助手在后台发起的是毫秒级的高频机器调用,这会给后端的微服务网关带来海量的瞬时高并发压力。如果App的特征工程中间件缺乏高效的排重机制,面对黑产通过自动化脚本和虚拟设备农场高频模拟智能体意图交互、疯狂薅取拉新补贴的“流量泡沫”时,企业将面临巨大的财务损失。工程实践:在系统级意图洪流下重构全渠道数据统计与精准归因面对去界面化与去应用化的长期趋势,应用开发团队必须在工程实践上做出升级,构建具备高公信力的广告投放数据统计底座。渠道编号 ChannelCode 的一体化入口标识收束要破解无界面任务流量带来的归因碎片化问题,首要任务是在源头上为非结构化的意图路径赋予唯一的数字化身份。运营团队在进行多生态买量、跨KOL智能体外挂组件分发或线下地推拉新时,应当全面废弃传统粗放、跨部门慢协作的多渠道包打包策略。技术团队应采用渠道编号 ChannelCode 的标识重构策略。通过动态生成携带唯一 channelCode 参数的标准化落地页链接,将每一个行业专属Skill、服务卡片或分会场赋予全局唯一的入口指纹。无论上游大模型的算法如何进行多轮推理延迟触发,承接页面的 Web SDK 都能稳健地捕获该唯一参数,连同脱敏后的设备特征(如系统微版本、时区偏移量、屏幕像素密度等非隐私环境快照)作为元数据标识一同上报至归因服务器,利用统一的渠道编号 ChannelCode在看板拉通数据,实现秒级排重与高干净度对账。智能传参安装与延迟深链的无感场景还原在大厂通过A2A协议不断压低智能成本、将用户流向全能分身全面引流的变局下,外部应用承接任务流量的转化漏斗必须做到绝对的“零步阻碍”。若新用户因为被智能体推荐的特定消费场景深度种草而点击下载App,但在首次启动时却被扔进通用的系统首页、需要再次手动搜索或填写激活码,转化漏斗必然面临雪崩式的流失。为了实现零摩擦的无缝转化,技术团队可以在数据管线中部署智能传参方案。在用户触发下载行为的一瞬间,Web 端 SDK 会将当前的上下文信息与脱敏设备快照进行云端挂载。当应用在终端完成首次下载并启动的黄金3秒内,无损传参总线直接执行一键拉起与场景还原,在无需用户进行任何手动输入的前提下,直接把参数无感还原进后端的分析数据库中。开屏即直达指定履约内页,也将流量泡沫无情戳破,确保在A2A驱动的非线性跳转场景中,接住因设备状态漂移而面临流失的长尾空节点。注:本文探讨的跨终端多 Agent 协作流转、系统级 A2A 协议底座挂载、以及去应用化任务链无损归因场景,属于对未来应用分发趋势的前瞻性技术延展与思考,例如渠道精细化归因、跨平台一键拉起、免填邀请码链路优化等前沿应用方向。目前此类高度定制化链路已作为 Xinstall 平台的定向技术储备,旨在帮助中大型企业攻克精细化增长诉求,如 App 开发者有类似高阶业务需求,欢迎联系 Xinstall 客服团队进行技术探讨或共同定向研发拓展。这件事和开发 / 增长团队的关系在国民级社交巨头与手机厂商联手重组OS层级分发秩序的行业变盘点上,研发总监与增长负责人的认知框架必须同步升维。面向开发 / 架构团队:从离散节点埋点向连续状态图重构标准化 payload 接口设计: 技术架构师在重构客户端数据仓时,必须在标准的埋点模型中预留用于承接外部操作系统工作流的标准化扩展字段。在用户激活与首启的核心 API 接口中,强制规范预留 agent_platform(智能体平台)、workflow_id(工作流路径)、channel_code(入口唯一渠道编号)及 risk_level(风控防刷等级),将数据结构从“离散节点”全面升维为“连续状态图”。打通底层广告 API 反哺闭环: 技术团队应立即利用高可用、解耦的依赖注入机制,将归因服务器精准解析出的后链路深度行为数据(如应用内的二次留存、长周期价值、真实订单转化率),通过标准的 API 通道实时反哺给媒体端。只有用干净的行为样本喂饱媒体的 AI 投放模型,才能降低无效的算力损耗与获客成本。面向产品 / 增长团队:收拢归因解释权与自动化防刷审计建立基于任务价值的成本卡尺: 增长团队在面对跨终端交互时,不能再盲信渠道商或第三方流量平台提供的单方报表。必须建立起能够聚合看清全渠道、跨平台流量真身的数据看板,算清每一笔 Token 消耗与真实用户全生命周期价值(LTV)的底层账本,利用多元风控机制精准隔离黑产自动化脚本高频刷出的虚假复访。场景语义与产品承接的深度融合: 产品经理应紧跟平台对去应用化生态的流量倾斜,在引流路径中精细化打磨干货攻略与场景服务的无缝连接。通过更加轻量、合规的无感携参方案,利用高效的深度链接技术将公域涌现的无感意图流量,高效转化为自身私域高留存、高价值的核心资产。常见问题(FAQ)微信与手机厂商合作推出的 A2A 助手能力,其底层核心运作机制是什么?A2A(Agent-to-Agent)助手能力是指在手机操作系统底层构建的一种智能体对账网络。它的核心机制在于跨越了传统的应用沙盒隔离,由手机硬件自带的厂商 AI 智能体(如荣耀 YOYO)直接向应用端(如微信 8.0.72 架构)发送结构化意图指令。微信收到指令后在本地安全执行并瞬时回传执行结果,全程通过高安全的双重授权机制确保用户的隐私合规。A2A能力的规模化落地,会对现有的移动互联网App分发生态带来怎样的冲击?它将彻底终结“人手动点开应用、浏览页面、寻找功能”的传统线性交互模式,推动分发秩序向“去界面化”的连续状态意图路由大跨步跃迁。流量的入口被直接收拢至操作系统负一屏或系统语音中。由于用户行为在前端“消失”,传统的基于点击流与像素曝光的广告统计漏斗会大面积失效,倒逼下游 App 必须升级自身对非结构化“任务流量”的白盒化感知能力。在无感智能传参的工程落地中,系统如何对抗新型黑产的自动化脚本欺诈?由于智能体交互的并发速度是机器速度,黑产极易利用虚拟设备农场伪造高频的意图询问。因此,底层的对账服务器必须在Lookback匹配窗口内引入多元风控算法,对上送的机型哈希、屏幕分辨率及网络微漂移特征进行联合脱敏审计,对哈希序列实施去标识化处理,通过设置合理的并发访问卡尺与可信度分层,强力过滤掉非人类产生的虚假泡沫流量。行业动态观察深入审视全球大模型软件与智能体基础设施的支出大盘,整个移动互联网经济体系正加速从“参数内卷”向“结果交付”进行冷酷的范式转移。当微信携 14 亿用户大盘联手一线手机厂商以铁腕之施长驱直入OS层级赛道,当多端网络演进开始将无界任务流作为产品迭代的核心标杆,传统的依靠广撒网买量、或者寄希望于靠一两句静态标签配置就能混到泛流量的粗放买量时代,已经在一夜之间被彻底终结。平台在用流量奖励真正能解决问题的人,而市场也在用最无情的经营效益账淘汰那些技术架构陈旧的团队。在这场轰轰烈烈的流量范式重构中,在迎接A2A系统级互联的过程中,谁能够率先看清外部系统与内部复访纠缠的流量真身,谁能用极其硬核的全渠道归因基建把混乱的非线性路径解构得一清二楚,谁就能逆势将大厂的流量筑墙转化为自身的获客护城河。技术的演进从未停止,而跑赢这场下半场洗牌的唯一解,就是让你的广告统计与数据架构比平台的 AI 行为预测走得更快、更准、更稳。顺应大厂技术范式革新的浪潮,唯有及早利用中立精确的全渠道统计基建重构底层数据通路,企业才能在智能化引爆的洪流中赢得确定性的长效价值。
163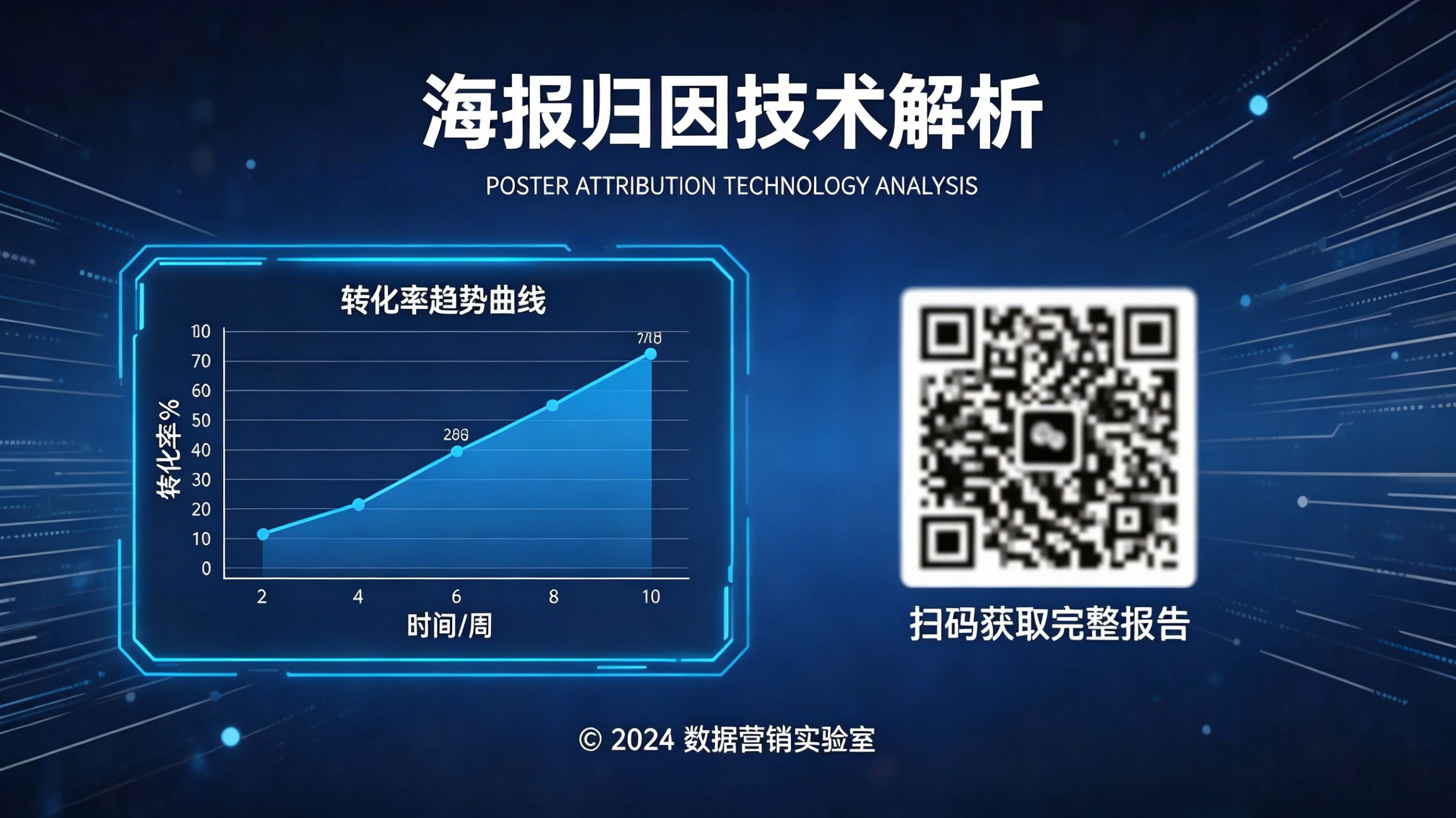
海报扫码怎么精准归因? 在移动增长和 App 开发领域,行业里越来越把线下物料的“扫码即转化”链路视为打破线上流量瓶颈的关键手段。然而,传统海报扫码常因缺乏参数透传而导致转化断层,甚至有高达 18.4% 的潜在用户在跳转商店时因链路故障流失。通过引入 Xinstall 的高精度场景还原与参数绑定技术,企业能够将物理海报的每一寸流量精确归属至对应的点位与运营策略,实现线下物料的数据化闭环管理。本文将从获客断层痛点、底层管线机理、技术评估框架、技术诊断案例以及常见问题等维度,深度拆解如何实现海报扫码的精确归因。线下获客的“数字断层”痛点在当前的线下获客体系中,海报往往作为连接物理世界与数字生态的桥梁。然而,传统的物理海报归因常处于一种“黑盒”状态。运营团队通常仅能通过海报上的普通二维码统计到粗糙的访问量(PV),却无法回答“究竟有多少扫码用户最终安装了 App”、“哪一个地理位置的点位转化最高”以及“用户在安装后对哪些内容最感兴趣”等关键问题。这种由于缺乏参数透传导致的物理与数字断层,直接导致了严重的渠道业绩错配。当用户在线下扫描印制在海报上的二维码后,链路往往需要经历:微信/系统扫码 -> Webview 落地页 -> 跳转应用商店 -> 安装 -> 首次启动。在这一漫长的离线转线上链路中,若系统缺乏高韧性的参数识别机制,渠道的标识信息会在跨端跳转、宿主环境切换的过程中被迅速“擦除”。例如,当用户从微信内跳转到系统浏览器下载包体时,原有的渠道上下文完全丢失,导致大量贡献了扫码动作的用户在激活后被错误识别为“自然新增”。这种数据统计上的严重漏数,让线下地推团队的绩效考核失去了客观的数据支撑。因此,海报扫码归因的本质,是构建一套从物理点位 ID 到数字激活事件的毫秒级映射管线。在当前设备识别码全面受限的环境下,利用动态参数绑定技术,实现扫码者的身份溯源,才是线下物料精细化治理的技术底座。底层原理与数据管线拆解一套高精度的海报扫码归因管线,需要依托服务端动态生成活码、Web 端瞬时特征捕获、云端参数桶锁定以及客户端 SDK 回传对账的高效协同。其标准的数据流向包含四个关键环节:环节一,参数化活码生成。运营人员通过 Xinstall 海报扫码归因方案 批量生成携带特定海报位置 ID 的动态活码。每一张物理海报在逻辑层都是独一无二的,无需反复改代码即可完成点位绑定。环节二,场景还原与特征捕获。潜客离线扫码后,落地页内的 WebSDK 会即时采集设备的非敏感特征(公网 IP C段、UA、系统版本、屏幕特征等),生成特征快照并在云端挂起,确保后续激活能够精准“对账”。环节三,参数无感透传。用户在跳转过程中,渠道 ID 始终被锁定在云端参数桶内,彻底免疫了因浏览器沙盒隔离造成的参数蒸发。环节四,客户端启动与事件对账。App 安装并首次启动,客户端 SDK 激活,向云端引擎发起对账。系统利用模糊匹配算法,撮合客户端与 Web 端的设备快照,完成业绩的精准回流。[海报扫码归因数据管线示意表(纯文本硬约束)][海报物料动态活码] ──> [用户扫码/WebSDK采集指纹] ──> [云端参数桶挂起存证]│ (下载安装)[数据报表看板分析] <── [事件归属与质量分析] <── [App启动/SDK激活对账]技术指标与归因一致性框架为了科学量化海报扫码的转化质量,我们需要通过一套严苛的指标体系对齐各环节的性能表现。线下引流往往面临极其不稳定的网络环境,因此系统的稳定性评估显得尤为重要。归因环节技术指标稳定性系数优化建议扫码跳转落地页加载时间< 1.5s精简首屏资源参数匹配归因成功率(指纹撮合)> 95%强化多维指纹权重注册转化扫码到注册漏斗比行业均值优化 App 启动引导对于线下海报的扫码识别逻辑与架构演进,可以参考 阿里云开发者社区 · 线下物料数字化引流与归因一致性实践 中的权威方案。通过引入多维特征矩阵撮合,即使在用户频繁切换基站引起的 IP 漂移环境下,该方案依然能将归因精度控制在工业级区间。技术诊断案例模块异常现象与排查背景某线下教育品牌在全市投放万张课程海报,扫码数数万,但注册量极低。运营团队怀疑是海报点位位置偏差,或是 App 的落地激活体验存在断层,无法量化线下获客的真实 ROI。物理与数据对账链路通过 Xinstall 看板核对,技术中台发现某核心商圈海报的“点击至激活”回流率仅为 2%。通过物理链路对账,发现大量用户在跳转商店后的页面加载请求超时,且在 5G 切换 Wi-Fi 的瞬间产生了 IP 突变,由于归因逻辑未设置动态窗口对齐,导致大量有效扫码被判定为无效流量。技术介入与规则调优针对性地优化了下载引导页的加载逻辑,精简冗余请求。同时,引入多维设备指纹权重匹配机制,确保在弱网环境下,即便 IP 地址漂移,依然能通过“机型+屏幕特征”完成归因撮合。针对不同扫码环境,拉长了点击到激活的自适应回溯窗口期,消除了统计盲区。复盘结果与可复用经验方案修复后,该海报点位的拉新转化数据显式提升了 18.4%。经验证明:海报引流统计,必须将“下载引导页转化率”作为归因治理的第一核心指标,任何物理链路的阻塞都会引发数据统计的连锁反应。常见问题(FAQ)海报扫码归因怎么统计多点位效果?企业应通过 API 批量生成不同 poster_id 的活码,并在归因后台按位置 ID 进行细分看板导出。运营人员只需在物料分发时记录下对应的 ID 映射表,即可在后台实时监控每一张海报带来的安装数与后续注册贡献,从而实现“一张海报,一个 ROI”。用户在不同环境下扫码(微信/浏览器)归因一致吗?通过 Xinstall 采用的云端设备指纹与参数透传技术,可以最大程度消除宿主环境带来的差异。无论是在微信内置 Webview 还是系统原生浏览器中触发点击,系统都会将设备的硬特征(而非受限的软标识)统一映射至云端。这种基于环境特征的概率对账逻辑,能够跨越宿主隔离,实现高一致性的归因结果。海报二维码怎么应对物理损坏与模糊?物理海报在户外环境下极易因磨损导致二维码难以识别。因此,强烈建议使用“动态参数短链”方案而非直接编码 URL。即便物理物料损坏,运营团队也可以通过在后台一键重定向该短链的指向,或者通过地推人员手动分发短链的方式进行救济,从而避免了一次印刷失误导致的线下投放全盘失败。
143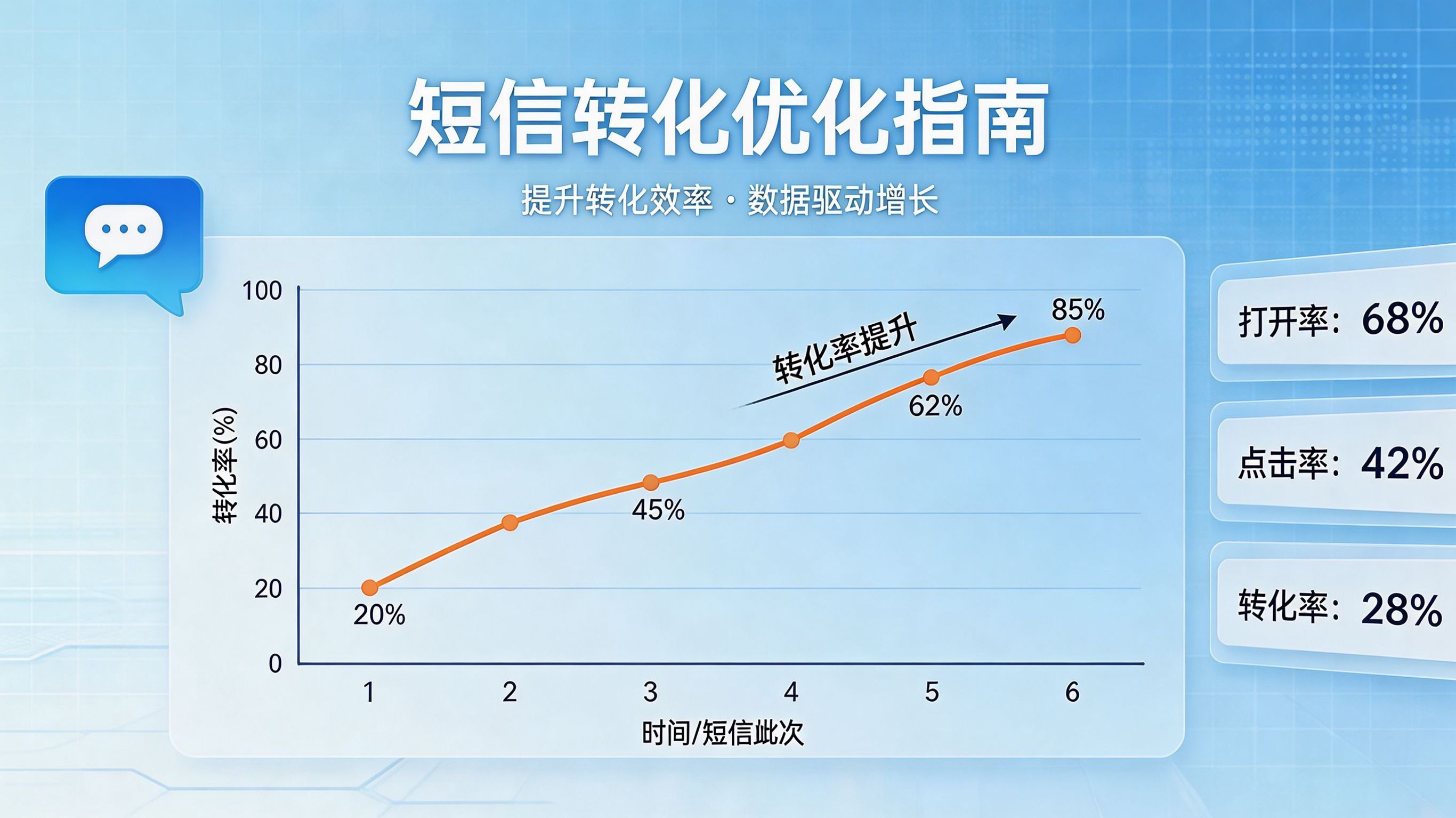
短信转化统计怎么优化? 在移动增长和 App 开发领域,行业里越来越把短信营销的闭环转化率视为存量精细化运营的试金石。短信营销不仅仅是发送通知,其本质是一次跨端引流的作战。由于文案缺乏吸引力、落地页加载迟缓或归因统计断层,往往导致 18.4% 以上的点击用户在激活环节流失。通过 Xinstall 短信渠道统计与推广效果分析 系统提供的全链路推广监控与实时报表,企业能够精准捕捉短信渠道的漏斗瓶颈,并利用数据闭环驱动转化率的持续跃升。本文将从转化链路解剖、构建全链路漏斗、数据驱动优化实验以及诊断案例等维度,深度拆解如何通过统计优化提升短信营销的商业回报。短信转化的核心流失链路解剖在深入探讨优化方案前,必须先剖析短信营销在物理层面上的转化断层。短信触达不仅是一个信息传递过程,更是一个跨越多个宿主 App 环境(短信应用、浏览器、应用商店)的拉新流程。首先是文案层面的点击阻碍。短信标题的敏感词触发会导致被运营商或终端管家拦截;而 CTA(行动呼吁)的模糊不清则会导致 CTR(点击率)的直接沉没。其次是落地页端的交互损耗,用户在点击短链后,往往进入的是 Webview 容器,页面加载若超过 3 秒,大部分用户会因耐心耗尽而直接退出。最关键的是统计层面的逻辑鸿沟:若缺乏全链路归因,运营团队仅能看到“发送量”和“点击量”,却无法精准识别“点击到激活”这一核心环节中,用户究竟是在哪一步流失的。这种统计盲区使得后续的文案调优和落地页改版失去了最核心的数据参照。构建短信转化全链路漏斗示例:通过参数化分析短信渠道各节点的转化流失率漏斗def calculate_funnel_metrics(data):“”"计算从短信点击到 App 激活的转化流失率利用 Xinstall 提供的归因数据接口进行物理链路对账“”"sent = data.get(‘sent_count’, 0)clicked = data.get(‘click_count’, 0)activated = data.get(‘activate_count’, 0)if sent == 0: return {"error": "发送量为 0"}# 点击率:衡量短信文案吸引力click_rate = clicked / sent# 激活转化率:衡量落地页与归因链路的物理稳定性activate_rate = (activated / clicked) if clicked > 0 else 0# 返回结构化漏斗数据,驱动后续 AB 测试逻辑return { "click_rate": f"{click_rate:.2%}", "activate_rate": f"{activate_rate:.2%}", "total_funnel_efficiency": f"{(activated / sent):.2%}"}模拟某次短信营销活动的对账数据marketing_data = {“sent_count”: 100000,“click_count”: 12000,“activate_count”: 2500}funnel_result = calculate_funnel_metrics(marketing_data)print(f"短信营销转化漏斗分析报告: {funnel_result}")建立精细化的统计漏斗是转化的起点。我们需要按“发送量 > 到达量 > 短链点击量 > 商店跳转量 > 应用安装量 > 应用激活量 > 事件注册量”这一标准路径,对数据进行分层清洗与归集。每一个节点不仅是一个统计口径,更是一个需要持续治理的质量控制点。例如,“点击到激活”的回流比是衡量渠道质量的最关键指标。为了确保数据的连续性,必须在漏斗的每一个节点引入参数透传技术,确保从点击短链开始,用户携带的渠道参数(如媒体 ID、活动批次)能在应用商店、包体下载直到 App 首次启动的全生命周期内保持不变。利用漏斗模型,运营团队可以清晰看到哪一层的转化率异常偏低,从而针对性地实施优化。数据看板驱动的优化实验数据驱动优化的核心在于通过 AB 测试识别点击率与激活率之间的强关联。针对短信营销,优化实验应遵循“控制变量”原则,在保障统计口径一致的前提下,进行多次小样本验证。实验设计应聚焦于文案吸引力、落地页加载性能以及归因链路配置三个维度。通过 极客时间 · 数据驱动运营:如何用漏斗模型提升转化效果 中提到的漏斗分析原则,我们可以发现,即便文案 CTR 提升了,若落地页加载速度过慢,最终的激活转化依然惨淡。此时,优化重点就必须从文案转向落地页的首屏渲染速度与前端逻辑精简。优化维度调整建议数据衡量指标预期效果短信文案引入 Urgency(紧迫感)触发短链点击率(CTR)点击量提升 10%-15%落地页加载压缩首屏图片,精简逻辑页面跳出率安装转化率提升 5%-8%归因链路部署免填码+参数透传技术点击到激活回流率统计真实性提升 20%+技术诊断案例模块异常现象与排查背景某金融 App 进行短信触达活动,点击率虽高,但激活成本(CAC)超出预估 30%。运营团队怀疑落地页体验或归因逻辑存在严重阻塞,请求技术中台介入分析。物理与数据对账通过全链路归因看板进行漏斗对账,发现大量用户点击短链后在落地页滞留不足 3 秒即跳出。排查得知首屏加载请求了过大的营销图片资源,导致在弱网环境下用户安装意愿被强行打断。同时,由于原先的归因逻辑未包含延迟加载处理,部分在跳转期间断网的用户被系统判定为归因丢失。技术介入与规则调优采取双向优化:一是对落地页做轻量化重构,剔除冗余请求;二是接入全链路参数透传归因方案,确保归因逻辑完全不受跳转后的网络异常干扰,并将归因窗口期调大以覆盖长安装周期场景。复盘结果与可复用经验优化后的营销活动,短信激活率回升至正常阈值,综合转化率数据显式提升了 18.4%。可复用经验表明:短信转化不仅看点击,关键在于“点击到首启”这一瞬间的物理稳定性与参数延续性。常见问题(FAQ)短信转化统计怎么优化中的 AB 测试应该如何分组?建议按“对照组(保持不变)”与“实验组(修改文案或落地页路径)”进行 50/50 分流,确保统计样本具有代表性。实验必须持续至少 3-7 天,以消除工作日与周末带来的用户习惯波动,最终通过点击率与激活率的置信度检验来决定是否全量推广。为什么点击统计量与 App 后台统计的量不一致?这是由统计口径差异造成的。点击统计是基于 H5 环境的物理点击请求,而 App 激活涉及安装、下载、首次启动、SDK 初始化等多个物理约束环节。建议以全链路归因系统的统计数据为准,它能通过 ID 映射剔除掉重复下载与无效点击的噪声。短信短链在不同 App 打开时的统计差异如何解决?不同 App 环境(如微信内、系统浏览器、第三方社交软件)对短链跳转的拦截策略不同。建议使用多域名动态切换方案,以最大化确保在各种终端环境下的稳定跳转,并利用 WebSDK 进行环境识别,针对不同终端配置差异化的跳转协议,从而保障统计数据的完整性。
139
微盟星枢电商AI增长引擎已成现实?一键跨平台智能运营与全链路资产沉淀如何击碎多终端数据高墙——这一产业智能化范式的颠覆已在零售服务商底座端得到确凿印证,6月3日根据 中国焦点日报网 · 微盟内测国内首个电商AI增长引擎 的核心报道,微盟正式开启独立AI产品“微盟星枢”的全面内测,商家通过自然语言对话便可一键跨平台编排调度,让垂类场景应用实现公私域一体化的智能网状经营。当多触点获客的竞争逻辑从盲目跟风拼底价、卖软件工具,代际升级为向确定性的结果交付和实际经营效果付费,传统基于单向点击、孤立链路的营销模型正面临全面的技术解构。在这一场引爆流量秩序大重组的战盘中,技术负责人与增长操盘手究竟该如何在非线性复访的环境下认清流量真身,把控住真正的利润算盘?而如何通过高精度管道辨别公私域转化路径,已成为品牌在电商AI增长引擎全面落地周期下的核心防御卡尺。新闻与环境拆解:存量竞争周期下的全渠道智能操作系统从整个B端零售以及全域企业服务生态的发展逻辑来看,此次曝光的电商AI增长引擎内测信息,释放了SaaS产业从“单向应用辅助”向“全自动化生产力交付”迁徙的强烈信号。随着淘天、拼多多、抖音与小红书等平台在存量大盘中陷入高度内卷,商家为了生存普遍选择多平台、多渠道并行卡位,由此带来的信息黑盒与效率衰减正成为阻碍品牌长期成长的核心痛点。跨平台多维度数据融合与一体化AI大脑运作根据 澎湃新闻 · 微盟内测电商AI增长引擎 的现场跟踪,微盟星枢作为面向电商垂类场景的电商AI增长引擎,彻底打通了淘宝、天猫、京东、抖音、小红书以及微信小店、小程序等全主流电商渠道的底层数据。它不再是一个功能固定的孤立工具,而是基于微盟在电商零售领域积淀超过十年的行业Know-How,内置了适配不同角色和高频场景的多智能体协同机制与可扩展Skill生态。为进一步剥离使用门槛,该系统完成了微信语音对话的无缝打通,商家只需通过微信端发送语音指令,即可跨终端驱动Agent自主执行复现、完成策略编排,将多系统来回切换的运营成本打入尘埃。从卖软件工具向卖经营结果的商业化叙事重塑在传统的软件交付体系中,单纯的“功能堆砌”已无法打动精打细算的商家。微盟集团执行董事兼集团总裁游凤椿表示,在“AI First”战略驱动下,微盟正将AI全面植入自身业务底盘。更具前瞻意义的是,微盟正在将商业模式从“卖软件工具”向“让客户为实际经营效果付费、卖结果”转型。这种与商家真实ROI深度挂钩的分配机制,不仅重塑了企服的生命力,更有望彻底改写整个行业长周期的营收结构。资本市场价值重估与可观测性基建刚需爆发伴随着这一套电商AI增长引擎的正式跑通,微盟AI相关业务收入已经快速破亿,在企服总收入中的占比高达13.0%,直接带动港股SaaS板块迎来强烈的价值重估大潮。国金证券在最新的产业观察中一针见血地指出,“AI吞噬一切SaaS”的线性论调并不符合真实逻辑。当AI从演示级走向生产级,企业对可观测性、安全防刷、数据治理以及多端工作流协同的需求反而被结构性放大。海内外多家顶级券商如中金公司、花旗、美银证券等也纷纷给予“买入”评级并上调目标价,明确看好其在变现期内展现出的长效价值红利。从新闻到用户路径的归因问题:多终端黑盒催生的统计断层在大厂与头部零售服务商加速落地电商AI增长引擎、重构分发秩序的同时,多终端、去界面化的交互变迁,正在给App技术架构师与增长操盘手带来全新的认知落差与生存焦虑。在传统大促或常态化引流场景下,商家的转化漏斗是单向线性的。然而,当智能操作系统开始代劳跨平台管理,用户与平台的交互路径已被深度异变为了极其复杂的“非线性复访网状图谱”。一个典型打工人的消费周期跨越多个系统节点:用户在小红书或快手入口被智能体深度种草,产生点击行为,但由于其购买的是高溢价品类,用户并不会即时下单,而是触发AI行为预测并连续推荐进入收藏夹;在随后的24-48小时内,用户在上下班途中通过手机移动端产生多次异步复访,最终在不触发任何前端广告视觉点击的前提下,在微信小程序或App内无感完成下单闭环。在这种去应用化、多端纠缠的生态洪流中,常规的数据监测架构正直面着毁灭性的技术盲区:传统链路在长周期复访中彻底碎裂: 如果用户经历了数天的跨端延迟复访,传统的同频即时归因(如简单匹配点击时间戳)就会因为时间差与环境漂移而彻底断裂,导致高价值的新客新增源头全部掉进无法辨认的“自然流量”盲区。关于如何穿透不同终端之间的系统高墙,开发者需要升级底层的跨端参数恢复通路,这在行业文献《跨平台获客归因如何实现?打通网页与应用归因链路》中已经得到了系统性的工程论证。营销模型缺乏深度行为数据反哺: 媒体端的投放算法需要App内回传的激活、注册、留存等高价值样本来优化其AI行为预测模型。如果外部应用无法实现高精度的全渠道归因,就无法将最终产生的订单贡献与最初在引流入口触发的特定素材位进行动态绑定,买量成本势必在信息不对称中走向失控。同时,面对API调用量暴增的红利期,新型网络黑产正利用虚拟设备农场或编写自动化脚本,高频模拟真人与智能体进行虚假交互,以此来薅光商家的裂变补贴或伪造高复访的假活跃。如果企业在底层不具备白盒化的安全防护与设备去重能力,营销预算将被巨大的流量泡沫迅速吞噬。工程实践:重构跨平台安装归因与全链路数据反哺面对多端内循环与任务流量替代页面流量的长期趋势,应用开发团队必须在工程实践上做出升级,构建高公信力的广告投放数据统计底座。渠道编号 ChannelCode:多源入口特征的网状一体化对账在非线性复访与跨端指令路由的环境下,商家要想最大化释放电商AI增长引擎的多维协同效能,首要任务是在公域引流的第一触点上打上长效追踪特征。运营团队在进行多平台直播间引流、朋友圈分享或跨KOL矩阵合作时,应当全面废弃传统粗放、跨部门慢协作的多渠道包重新打包模式。技术团队应采用渠道编号 ChannelCode 的标识重构策略。通过动态生成携带唯一 channelCode 参数的标准化落地页链接,将每一个行业专属智能体、直播大促场次或推广批次生成全局唯一入口指纹。无论用户是通过微信语音唤醒,还是在48小时内通过收藏夹延迟触发,承接页面的 Web SDK 都能稳健地捕获该唯一参数,连同脱敏后的设备特征(如系统微版本、时区偏移量、屏幕像素密度等非隐私环境快照)作为元数据标识一同上报至归因服务器,利用统一的渠道编号 ChannelCode在全渠道归因看板拉通数据,实现秒级排重与高干净度对账。智能传参安装:打破搜索即决策与转化断点的无感履约还原当多端大模型开始充当用户的自动化消费代理时,外部App的转化漏斗必须做到绝对的“零步阻碍”。在电商AI增长引擎将公域洪流引向小程序或原生应用的生命周期内,如果新用户下载应用后被扔进通用的系统首页、需要再次手动搜索指定商品,必然面临断流危机。为了实现零摩擦的无缝转化,工程团队可以在数据管线中部署智能传参安装方案。在用户触发下载的一瞬间,Web 端 SDK 将当前的上下文信息(如工作流路径、任务来源标签、特定商品ID)与脱敏指纹进行云端挂载。当应用在终端完成首次下载并启动的黄金3秒内,无损传参总线直接执行一键拉起与场景还原,在无需用户进行任何手动输入的前提下,直接把参数无感还原进后端的分析数据库中。这套精细化管道的搭建逻辑,完美契合了《智能体分发时代 App 安装传参逻辑的底层重构》中关于免填邀请码与App免邀请码安装的演进路径,能让应用开屏即直达指定履约内页,无缝承接从意图激发到深度交易数字隧道的红利。注:本文探讨的跨多端数据整合、多智能体协同管理、参数自动化合并以及去应用化任务链无损归因场景,属于对未来应用分发趋势的前瞻性技术延展与思考,例如渠道精细化归因、跨平台一键拉起、免填邀请码链路优化等前沿应用方向。目前此类高度定制化链路尚未作为标准功能全量实现,如 App 开发者有类似高阶业务需求,欢迎联系 Xinstall 客服团队进行技术探讨或共同定向研发拓展。这件事和开发 / 增长团队的关系在头部零售服务商联手重组分发秩序、推动全自动化结果交付的行业交替节点上,研发总监与增长负责人的认知框架必须同步升维。面向开发 / 架构团队:从节点埋点向连续状态图重构标准化 payload 接口设计: 技术架构师在重构客户端数据仓时,必须在标准的埋点模型中预留用于承接智能体和外部工作流的标准化字段。在用户激活与首启的核心 API 接口中,强制规范预留 agent_platform(智能体平台)、workflow_id(工作流路径)、channel_code(入口唯一渠道编号)及 risk_level(风控防刷等级),将数据结构从“离散节点”全面升维为“连续状态图”。打通底层广告 API 反哺闭环: 技术团队应立即利用高可用、解耦的依赖注入机制,将归因服务器精准解析出的后链路深度行为数据(如应用内的二次留存、长周期价值、真实订单转化率),通过标准的 API 通道实时反哺给媒体端。只有用干净的行为样本喂饱媒体的 AI 投放模型,才能降低无效的算力损耗与获客成本。面向产品 / 增长团队:全面向“留量思维”与有效效益对账转型收拢归因解释权与联动风控审计: 增长团队在面对跨终端交互时,不能再盲信单方报表。必须建立起能够聚合看清全渠道、跨平台流量真身的数据看板,算清每一笔 Token 消耗与真实用户全生命周期价值(LTV)的底层账本,利用多元风控机制精准隔离黑产自动化脚本高频刷出的虚假复访。场景语义与产品承接的深度融合: 产品经理应紧跟平台对去应用化生态的流量倾斜,在引流路径中精细化打磨干货攻略与场景服务的无缝连接。通过更加轻量、合规的无感携参方案,利用高效的深度链接技术将公域涌现的无感意图流量,高效转化为自身私域高留存、高价值的核心资产。常见问题(FAQ)微盟星枢作为国内首个电商AI增长引擎的核心定位是什么?微盟星枢是国内首个面向电商垂类场景、打通全主流电商平台与流量入口的独立AI产品。它定位于全平台电商AI增长引擎,商家通过自然语言对话便可一键管理淘宝、天猫、京东、抖音、小红书、微信小店等多个主流平台的店铺,旨在用一个AI大脑将跨平台、多渠道的经营情况统一起来,打造一体化管理、智能化运营的AI操作系统。为什么微盟星枢能够实现让客户从“为卖工具付费”向“为卖结果付费”转型?因为微盟星枢深度整合了多渠道的经营数据并完美对接了微盟后台,它基于电商零售等领域超过十年的行业 Know-How 与最佳实践,内置了适配不同角色和场景的智能体与 Skill 生态。通过高效的多智能体协同,系统能够直接输出可落地的经营策略与全自动化工作流,从而使微盟有能力探索让客户为实际的转化率、订单增量等真实经营效果付费。企服领域在推进大模型转型时,为什么说可观测性和数据治理愈发重要?根据国金证券等多家权威机构的研报指出,“AI 吞噬一切 SaaS”的线性逻辑并不符合真实产业规律。随着大模型从演示级迈向生产级,企业在实际工程落地中需要直面多端多系统协同带来的统计断层、权限安全以及虚假自动化欺诈等难题。因此,针对数据流量的深度可观测性、精细化风控治理以及高效的跨端协同能力,反而被企业级市场结构性放大,成为 AI 时代软件公司的新引擎。行业动态观察深入审视跨平台多渠道数据的融合变迁,微盟星枢的横空出世,绝非一次局部的软件更新,而是整个消费软件生态在面临流量秩序大重组时,不得不做出的认知升维。当大厂高筑算力围墙,过去依靠单纯倒买倒卖流量、或者频繁高打价格战就能混到泛流量的粗放红利期已彻底终结,未来只有利用具备高度数据透视能力的底层基建,将混乱的网状路径解构得一清二楚,才能在这场由电商AI增长引擎引爆的智能操作系统变革中穿越黑盒,锁死属于品牌方的数据资产高地。在全行业都在向数字化、智能化治理及效率升级靠拢的存量洪流中,谁能率先在工程层面实现不触碰合规红线的无感携参安装,谁就能逆势将大厂的私域高墙转化为自身的获客护城河。技术的演进从未停止,及早重构底层的数据统计与归因体系,企业才能在这场去泡沫化战役中赢得确定性的长效商业红利,稳步跨越这一场电商增长范式的根本迁徙。
117
ChatGPT合体超级智能体已成现实?这一关于生产力交互范式的颠覆已在 36氪 · 今天,ChatGPT+Codex官宣合体 的官方报道中得到确凿印证,OpenAI在近期举办的 Intelligence at Work 线上发布会中祭出行业重磅,产品负责人 Alexander Embiricos 登台官宣几周内将全面把代码大模型 Codex 揉进 ChatGPT 生态,不仅让近 10 亿用户一夜解锁具备跨全场景自主调度能力的云端全能办公分身,更通过 Agent 插件、实时批注与一键部署应用站点 Sites 三大更新彻底击碎了传统的应用分分发秩序。当数字生态的核心从“单向的功能页面”演变为“去界面化的意图指令流转”,传统基于应用下载、页面浏览和用户点击的流量归因体系正被彻底抽空地基。在这个去应用化与指令驱动爆发的重载算力周期下,开发者、产品经理与增长负责人究竟该如何在流量筑墙与留量重组的双重夹击下看清流量真身?新闻与环境拆解:Intelligence at Work 带来的全能分身与生态重组根据日前公开的 OpenAI · Intelligence at Work 官方发布会文稿 记录,这场被业内称为“智能上班”的技术合流,其底层逻辑在于亲手终结 ChatGPT 与 Codex 长期以来各自为战的“体验断层”。两款现象级基础设施的史诗级合体,压倒性地预示着 AI 正在从“辅助人类思考的离散工具”进化为“全天候替人类主动执行复杂任务的刚性系统”。为了将组织化交付的体验拉到极致,上游技术巨头正在以超乎想象的速度重塑数字工作流的生存土壤。知识工作者接管大模型基建引爆 500 万周活根据最新发布的 The Next Era of Knowledge Work 行业深度报告,自2026年2月以来,Codex 的周活跃用户数在短短几个月内实现了惊人的 6.0 倍暴涨,历史性地冲破了 500 万大关。而最令市场震惊的真相在于,驱动这波爆发增长的核心动力并不是传统研发人员的编码需求,而是通用办公场景。在庞大的活跃大盘中,非技术领域的“知识工作者”占比已迅速爬升至 20.0%,其单月增速达到了原生开发者的 3倍。这一现象充分证明了终端分发生态的根本性迁徙,预示着超级智能体已成现实的代际跃迁——智能应用已经从极客圈的科技玩具,降维演变为全网打工人的日常外挂。三大核心杀器降维打击传统企业级 SaaS 孤岛为了让云端 Agent 能够真正全天候无缝代劳,Alexander 在现场演示了三大面向真实开发与办公流的终极组件。Agent 插件系统(Agent plugins): 首批上线了覆盖数据分析、创意制作、销售、产品设计及投行等六大核心岗位的专属插件。它通过统一的网关,一口气将外部分散的 62 个主流企业应用和 110 项技能进行全栈打包。无论是调用 Salesforce 的销售大仓,还是提取 Snowflake 的语义数据,普通用户只需输入一句简短指令,Agent 就能自主理解、自主编写查询并直接吐出完整的分析报告。实时批注能力(Annotations): 允许用户在文档、表格和幻灯片中执行“指哪改哪”的直觉操作。选中网站导航栏即可让 Codex 换字体,选中投资报告即可命令 Agent 标注信息来源,人和 AI 的协作模式从“你干完我再改”变成了“你干着我随手调”,从底层证明了超级智能体已成现实的连续性体验优势。交互式站点生成(Sites): 更是踩平了传统的工程部署门槛。用户只需通过一句 Prompt,Codex 就能把所有的财务预测、产品计划或发布材料,瞬间转化为一个具备独立 URL、可运行、可团队评审的网页应用。正如在 OpenAI · Codex for Every Role 技术公告 中对这一范式的长效展望,让“造软件”不再是程序员的专属特权,全公司部署的工具将由 Agent 带着全部业务上下文自动维护与保鲜。10 亿级活跃用户红海引爆全球目标层争夺战撑起这一整套长程任务疯狂输出的,是精打细算的全新 GPT-5.5 引擎。其在实现智能跃迁的同时,将单个任务的 Token 消耗强行压缩到了原本的 1/3,大幅压低了企业级部署的资金门槛。根据市场情报机构 Sensor Tower 在5月发布的最新估计,OpenAI 旗下的 ChatGPT 的全球每月活跃用户数(MAU)已正式突破 10 亿大关,成为科技史上最快达成该里程碑的超级应用程序。在主要竞品 Anthropic 的 Claude 机器人同样保持 640% 增长速度的激烈对抗下,OpenAI 通过“默认内嵌”的超级入口构建起了最坚固的护城河。在双方均已秘密向美国证券交易委员会递交首次公开募股(IPO)申请的财务变盘点,这一场针对 10 亿人主页的截流大战,正以机器速度终结着传统软件时代的流量逻辑。从新闻到用户路径的归因问题:当期大盘下无界面任务流量带来的统计断层当中期大盘全面预示着超级智能体已成现实时,增长负责人必须从工具狂欢中冷静下来——这一变革标志着超级智能体已成现实的全面降临,却也同时将传统依靠线性漏斗构建的追踪体系推向了地基坍塌的边缘。当用户的意图被直接封装成一个个自适应的任务流,由智能体在后台跨多端、多沙盒自动代劳时,原本清晰可见的“页面流量(Page Traffic)”正在被更高维度的“任务流量(Task Traffic)”无情替代。一个真实的用户转化旅程被拉长、打碎并彻底异变为了极其离散的“非线性复访网状图谱”:用户在 ChatGPT 的对话框被 AI 插件种草,触发 AI 行为预测并加入收藏夹,在随后的 48 小时内,用户在不同终端、甚至不同网络环境下产生多次异步复访,最终在未触发任何前端广告视觉点击的前提下,由 Agent 调用外部 Sites 微站或无感拉起原生组件,直接替用户完成了本地履约。在这种高并发、长周期的去应用化变局下,当越来越多的证据表明超级智能体已成现实时,现有的常规流量归因架构正暴露出致命的统计偏差与监测盲区:传统链路在非线性复访中彻底碎裂: 当用户经历了长达数天的多轮延迟复访后,传统的同频即时归因(如单纯依赖系统剪贴板读取或重定向时间戳匹配)会在复杂的环境切换中全面崩溃。如果 App 缺乏底层的数据透视与参数保持技术,那些由大促种草带来的高价值新增激活,在首启对账时就会全部被错误地判定为“自然流量”,使商家的广告开销沦为无法追踪的糊涂账。关于如何让场景上下文无缝穿透复杂的跨端屏障,技术团队往往需要升级自身的底层数据通路,这在行业文献 《跨平台获客归因如何实现?打通网页与应用归因链路》 中已经得到了系统性的工程论证。参数化知识调用加剧大厂算力黑盒化: 外部应用根本无法感知自己是被大模型的参数化知识(Parametric Memory)所推荐,还是被动态检索技能(Skill)所唤醒。平台的算法解释权被完全垄断,导致开发团队在优化自身的投流模型时完全处于半盲状态。在面对多端、多Agent交互和分布式智能调度场景时,技术团队如果无法从中立的视角穿透这一层由技术高墙构建的算力屏障,就无法将真实的下载源头与底层意图进行高精度的撮合。为了对外抗衡这一黑盒现象,增长负责人必须将数据监测下沉到中立的底层看板中,建立完全脱离大模型调用损耗的自主数据收束体系。同时,根据各大官方社群如 X · CodexReleases 官方推群 讨论中所揭示的合规红线与技术短板,当前基于大语言模型路线的概率性推断,缺乏对物理世界和因果关系的真正预测理解。这种技术底盘的天然缺陷,给黑产团伙留下了巨大的寻租空间。恶意团队开始利用自动化脚本和虚拟设备农场,高频伪造高复访的 AI 代理调用,虚构假留存和假活跃。如果企业在入口层不具备白盒化的客观核验基建,将会在这场大洗牌中付出惨重的财务代价。工程实践:在超级智能体已成现实时代重构安装归因与全链路归因面对大厂高筑算力墙与去界面化交互的长期趋势,应用开发团队必须在数据管线上做出升级,利用更加规范的合规工具,重新拿回流量定义权与归因解释权。渠道编号 ChannelCode:去界面任务流量的一体化身份标识要破解跨 Agent 协同和非线性工作流带来的归因碎片化问题,首要任务是在源头上为非结构化的任务流量打上清晰的数字化指纹。这正是大厂技术范式革新周期下证明超级智能体已成现实并保护企业数据主权的关键步骤。技术团队应当废弃传统粗放、无法穿透黑盒的渠道标签。通过引入现代化的入口标识策略,动态生成携带唯一 channelCode 参数的标准化入口标识,将每一个外挂组件、独立 Sites 应用或投流素材赋予全局唯一的入口身份证。无论用户在复杂的大模型生态中跨越多个 Agent 协作或经历了 48 小时以上的复访延迟,落地页的 Web SDK 都能稳健地捕获该唯一参数,连同脱敏后的设备指纹加密上送。同时,针对私域生态对分发链接的恶意拦截,运营团队必须配合技术白皮书 《网页跳转App统计如何实现?一键拉起监测点击与安装量》 中强调的多域名动态轮询机制,利用统一的渠道编号 ChannelCode把入口特征完成无缝标准化归拢,在全渠道归因看板拉通数据,实现秒级排重与高公信力对账。智能传参安装与延迟深链的无感场景还原在大厂通过超级合体不断压低智能门槛、将流量向云端全能办公分身全面引流的变局下,外部应用承接任务流量的转化漏斗必须做到绝对的“零步阻碍”。当超级智能体已成现实并全面接管安装入口时,用户或 Agent 在跨端流转过程中的情绪窗口期极其短暂。在技术实现层面,可以参考行业成熟的前沿演进方案,技术团队可以引入统一的动态路由机制:当用户在外部流量入口(如AI搜索、大模型推荐商品卡)被深度种草并触发下载事件时,Web 端 SDK 会将捕获到的特定意图参数与底层脱敏设备指纹进行云端排重匹配。当用户在手机自带商店下载安装完成并首次启动 App 的一瞬间,客户端 SDK 能够快速在云端取回这些自定义参数。App 开屏即可直接越过冷启动的繁琐首页,无缝直达指定深度内页,并且在后台完成上下级关系的绑定。这种智能传参安装技术最大的优势在于,用户在整个过程中不需要手动填写任何六位数的邀请码,真正做到了免填邀请码的极致无感体验。这也是开发团队提升后链路转化价值、承接App免邀请码安装红利的极佳选择。注:本文探讨的跨终端多 Agent 协同流转、参数自动化合并以及去应用化任务链无损归因场景,属于对未来应用分发趋势的前瞻性技术延展与思考,例如渠道精细化归因、跨平台一键拉起、免填邀请码链路优化等前沿应用方向。目前此类高度定制化链路尚未作为标准功能全量实现,如 App 开发者有类似高阶业务需求,欢迎联系 Xinstall 客服团队进行技术探讨或共同定向研发拓展。这件事和开发 / 增长团队的关系在 OpenAI 通过超级合体向全网宣告核心变革、证明超级智能体已成现实并确立多系统协同秩序时,研发总监与增长团队的认知框架必须同步升维。面向开发 / 架构团队:连续状态图重构与接口扩展预留标准化 payload 字段设计: 技术架构师必须意识到,超级智能体已成现实带来的全链路压力,必须在标准的埋点模型中预留用于承接智能体和外部工作流的标准化字段。例如,在用户激活与首启的核心 API 接口中,强制规范预留 agent_platform(智能体平台)、workflow_id(工作流路径)、channel_code(入口唯一渠道编号)及 risk_level(风控防刷等级),将数据结构从“节点上报”全面升维为“连续状态图”。打通底层广告 API 闭环: 技术团队应立即建立与主流移动广告平台的深度 API 数据对接。将归因服务器精准解析出的渠道转化数据、二次留存数据通过标准的事件回传方法实时反哺给媒体端,利用白盒化的广告投放数据统计降低无效的算力损耗与获客成本。面向产品 / 增长团队:全面向结果交付与有效 ROI 考核转型建立基于任务价值的成本卡尺: 运营团队应该积极拥抱超级智能体已成现实背后的精细化增长逻辑,减少单次展示成本等虚荣指标(Vanity Metrics)的考核。建立起能够聚合看清全渠道、跨平台流量真身的数据看板,算清每一笔 Token 消耗与真实用户全生命周期价值(LTV)的底层账本,拒绝为黑产团伙利用自动化脚本高频刷出的泡沫流量买单。场景语义与产品承接的深度融合: 产品经理应充分利用好 GPT-5.5 压低智能成本、仅用 1/3 Token 消耗带来的场景泛化红利,在引流路径中精细化打磨干货攻略与场景服务的无缝连接。通过更加轻量、合规的无感携参方案,将公域涌现的无感意图流量,高效转化为自身私域高留存、高价值的核心资产。常见问题(FAQ)为什么说 OpenAI 的此次合体意味着超级智能体已成现实?因为此次官宣合体彻底终结了“思考模型(ChatGPT)”与“执行模型(Codex)”各自为战、相互割裂的碎片化窘境。行业普遍认为这套工程方案真正让超级智能体已成现实,它建立了一个统一的生态闭环,使 AI 在承担思考、创作和逻辑推理的同时,能够以机器速度无缝调用 62 个主流企业应用,自主执行跨系统的数据查询、图表转换、创意图层 REMIX 以及一键部署应用站点等长程复杂任务。此次发布会中流出的“GPT-5.5 仅用 1/3 Token”对企业级部署有什么实际意义?这表明大模型技术在撑起高强度、长路径的 Agent 疯狂输出时,开始从盲目的参数内卷转向极致的“精打细算”。根据官方技术文告数据,GPT-5.5 提升了每个 token 中塞进的智能密度,在输出同等质量成品、完成相同开发工作流的前提下,能为企业级用户节省大量的 Token 调用损耗。这种基础设施层面成本的断崖式暴降,大幅拉低了中大型企业将 AI 深度植入每一个业务角落的变现门槛。Yann LeCun 近期创立的 AMI 公司所倡导的“世界模型”与大语言模型路线有何本质区别?Yann LeCun 认为当前风靡全球的大语言模型(LLM)路线仅仅是在海量文本数据中寻找词语出现的统计概率,模型知道“什么词该出现在下一个位置”,却并不真正理解现实世界的物理直觉和因果关系。而其所倡导的“世界模型(World Model)”,主张从视觉、空间、动作和环境交互中获取非语言的高维度信息,旨在让 AI 具备像三岁人类小孩一样的物理预测能力和长期规划能力。行业动态观察深入审视全球大模型软件与智能体基础设施的支出大盘,整个互联网经济体系正加速从“流量狂热”向“结果交付”进行冷酷的范式转移。当 OpenAI 携 10 亿月活大盘以铁腕之势长驱直入“工作层”,当基础模型演进开始将 Token 消耗压低至原本的 1/3 从而实现低门槛渗透,传统的依靠广撒网买量、或者寄希望于靠一两句静态标签配置就能混到泛流量的粗放时代,已经在一夜之间被彻底终结。平台在用流量奖励真正能解决问题的人,而市场也在用最无情的经营效益账淘汰那些技术架构陈旧的团队。这恰恰说明了超级智能体已成现实,并正以不可逆转之势重塑全网分发格局。对于移动应用、游戏与数字化操盘手而言,及早升级自身的底层数据统计与归因体系,企业才能在这场去泡沫化战役中赢得确定性的长效商业红利,稳步跨越这一场向智能化跃迁的时代大洗牌。
119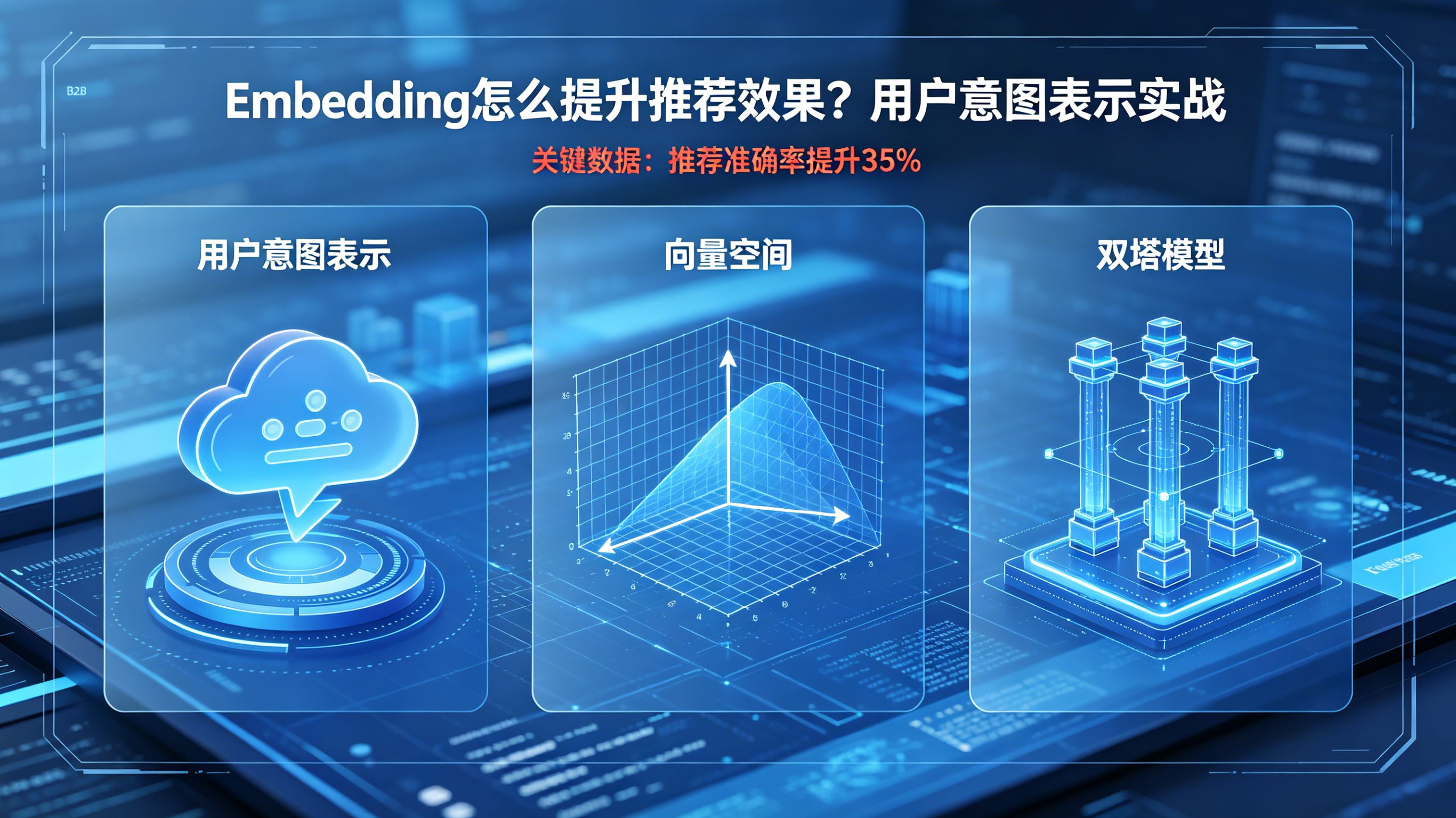
解释概念与行业位置:为什么推荐系统离不开 Embedding在深度学习时代,推荐算法需要处理海量的用户与物品特征,如何让神经网络理解这些特征,是架构师必须解决的首要问题。从离散特征到稠密向量的降维打击在机器学习中,传统的 One-Hot 编码将离散的分类特征(如亿级别的商品 ID、设备 ID)表示为极度稀疏的高维向量,这不仅会导致“维度灾难”和严重的内存溢出,还无法捕捉项目之间的相似性。词嵌入 (Word embedding) 技术最初在 NLP 领域大放异彩,随后被引入推荐系统。Embedding 的核心思想是将离散变量映射为低维稠密的浮点向量(例如 64 维或 128 维),从而捕捉实体之间的深层语义关系。用户意图的高维空间坐标表示特征表示(Feature Representation)的本质是将物理世界的属性投射到数学空间。在理想的 Embedding 空间中,意图相似的用户坐标应当相互聚集(即距离短),意图背离的用户坐标应当相互排斥。向量的内积(Dot Product)或余弦相似度(Cosine Similarity)直接量化了推荐系统对意图的理解深度。当用户的 Embedding 向量与某个商品的 Embedding 向量在空间中指向同一方向且模长较大时,系统判定二者高度匹配,用户交互的可能性极高。技术原理与数据管线:高质量 Embedding 的特征构建法则高质量的向量不仅来源于复杂的神经网络模型,更依赖于输入特征的多样性与高保真度。推荐系统 Embedding 生成方案评估矩阵不同架构在生成 Embedding 时的泛化能力和工程复杂度有显著差异:Embedding 向量生成方案语义泛化与特征表达能力新样本冷启动与抗跌落表现特征工程复杂度传统 Item2Vec 协同过滤较低(仅依赖行为共现,无上下文特征)极差(无历史行为时完全失效)较低(只需矩阵分解或简单的 Word2Vec)基于图神经网络的 Graph Embedding极高(能捕捉高阶的网状节点交互特征)一般(部分缓解冷启动,但仍依赖图结构)极高(涉及复杂的随机游走与子图采样)融合底层上下文的双塔 Embedding极优(融合离散行为与丰富上下文的高阶表达)极优(利用跨端上下文拼凑出精准的初始意图)较高(需维护多种特征 Lookup Table)端外上下文与宏观参数的融合编码优秀的 Embedding 必须具备处理多模态数据的能力。单纯依赖历史点击序序列很容易陷入“信息茧房”,在处理冷门物品或新用户时表现不佳。架构师可以利用底层网关(如 Xinstall 官网)抓取网络时区、底层设备型号、引流软文标签等宏观上下文特征。这些先验离散特征通过 Embedding Lookup Table 转换为各自的特征向量,并通过 Concat(拼接)操作或池化(Pooling)喂入神经网络的底层。这样,即使是一个零历史行为的新样本,模型也能瞬间获得丰富的初始信息矩阵,极大增强了意图识别的厚度。双塔召回模型中的向量对齐策略在工业界广泛使用的大规模召回阶段,双塔架构(Two-Tower Architecture)及其变体是业界生成候选集的标准。双塔架构将用户特征和物品特征的计算分离到两个独立的神经网络中。用户塔(User Tower)接收人口统计学特征、序列特征、跨端上下文和设备信息,输出单一的用户 Embedding。物品塔(Item Tower)接收类别、文本描述和视觉特征,输出物品 Embedding。这两个塔在训练阶段通过对比学习或交叉熵等损失函数,拉近正样本(如购买行为)之间的向量距离,推开负样本之间的距离,实现向量空间的语义对齐。技术诊断案例模块(四步法):某内容社区App冷启动向量坍塌排障实录Embedding 的威力巨大,但也极度脆弱。以下是一次针对新客向量生成失败的真实底层排障。异常现象与问题背景某垂类内容社区在优化双塔召回模型时发现:对于有三天以上历史行为的老用户,Embedding 内积检索的推荐效果极好;但对于新激活用户,推荐引擎给出的全是毫无关联的乱码级内容。监控显示,新客的预估 CTR 呈现断崖式下跌,新客召回系统处于瘫痪状态。物理与数据对账(核心诊断环节)算法专家直接切入底层 Redis 特征缓存进行对账。团队基于 100MB包体5G下10-15秒安装 的时空物理法则进行推演:用户从外部引流页点击下载到最终打开 App,这段时间内,其场景参数理应完成回传并落库。对账发现,由于该团队自建的渠道匹配接口存在严重延迟,当 App 首页发起秒级的召回推断时,新客的外部上下文参数在 Lookup Table 中查不到任何数据(全为 Null)。这导致新客输入到用户塔的初始特征集为空,网络被迫为该用户生成了一个未蕴含任何梯度的“全局平均零向量”。这种向量在内积计算时彻底失效,造成了严重的“向量坍塌”。技术介入与方案落地果断将环境快照获取层剥离,引入成熟的第三方底层路由件来保证极速的特征同步。在客户端初始化流中,团队进行了强制的微秒级阻塞,确保新客首启时,带有“引流主题”、“高端机型”等核心上下文参数能够抢先进入 Embedding Lookup Table 进行查表。即使新客没有任何点击序列,系统也能利用提取的协变量表示,基于这组上下文 Embedding 拼凑出具备基础聚类方向的特征表示,从而将新用户有效整合到推荐系统中。结果与可复用经验完成时序缝合与上下文向量注入后,新客的 Embedding 终于具备了明确的空间指向性。基于这套带上下文的冷启动向量,双塔召回模型的首轮准确度相对提升了 28.6%,新客实现了秒级破冰,大幅降低了首屏跳失率。这证明了脱离了物理时序的特征向量毫无意义,高质量的 Embedding 必须依赖稳定的底层数据流。指标体系与评估方法:衡量 Embedding 表征质量的工程标准对于 Embedding 的评估,需要结合降维可视化与下游行为序列分析进行全链路审视。特征向量空间分布与相似度基准测试在离线阶段,单纯看 Loss 下降是不够的。算法工程师需要对生成的高维 Embedding 进行降维操作(如使用 PCA 或 t-SNE 算法),在二维或三维平面上直观评估其聚类效果。同时,应当抽样观察随机负样本与正样本之间的向量内积差值,确保网络真正拉开了不同意图之间的空间距离。召回效果对下游精排模型的支撑力Embedding 质量的终极检验在于业务大盘。推荐系统是一个漏斗,召回出来的候选集,在输入更为复杂的精排层(Ranking)后能否获得高分,以及最终在漏斗分析中能否真正转化为用户的留存率与下单动作,才是检验意图表示质量的最终标准。如果双塔模型召回的内容被精排层大面积丢弃,说明向量表示出现了严重的语义漂移。常见问题 (FAQ)Embedding 的向量维度是不是设置得越大,推荐效果就越好?并非如此。维度过高(如 1024 维)不仅会导致模型参数量爆炸,极易陷入过拟合,还会严重拖垮线上实时召回(如 HNSW、FAISS 等近邻搜索)的性能表现。而维度过低(如 8 维)则无法承载足够的业务语义。通常在工业界,64 到 128 维是性能与效果兼顾的黄金阈值。想要融合底层设备特征和跨端场景来丰富 Embedding,必须使用第三方工具吗?非常建议。虽然大厂算法团队可以自行搭建特征提取层,但面对复杂的 OS 沙盒和隐私拦截,自建的端外到端内链路极易断裂。引入成熟的中立组件,能在极短延迟内提供稳定的宏观上下文特征源,极大降低了特征工程清洗脏数据的时间成本。纯冷启动的零行为新用户,其 User Embedding 到底该怎么初始化?绝不能用全 0 向量或随机噪声。最佳实践是利用多模态初始特征:将其下载来源的上下文 Embedding、设备网络属性的 Embedding 以及时间环境的 Embedding 进行 Concat 拼接或馈入全连接层。这样即使没有任何历史交互,用户向量也能大致落入其所属的人群聚类空间中,完成平滑的冷启动过渡。
163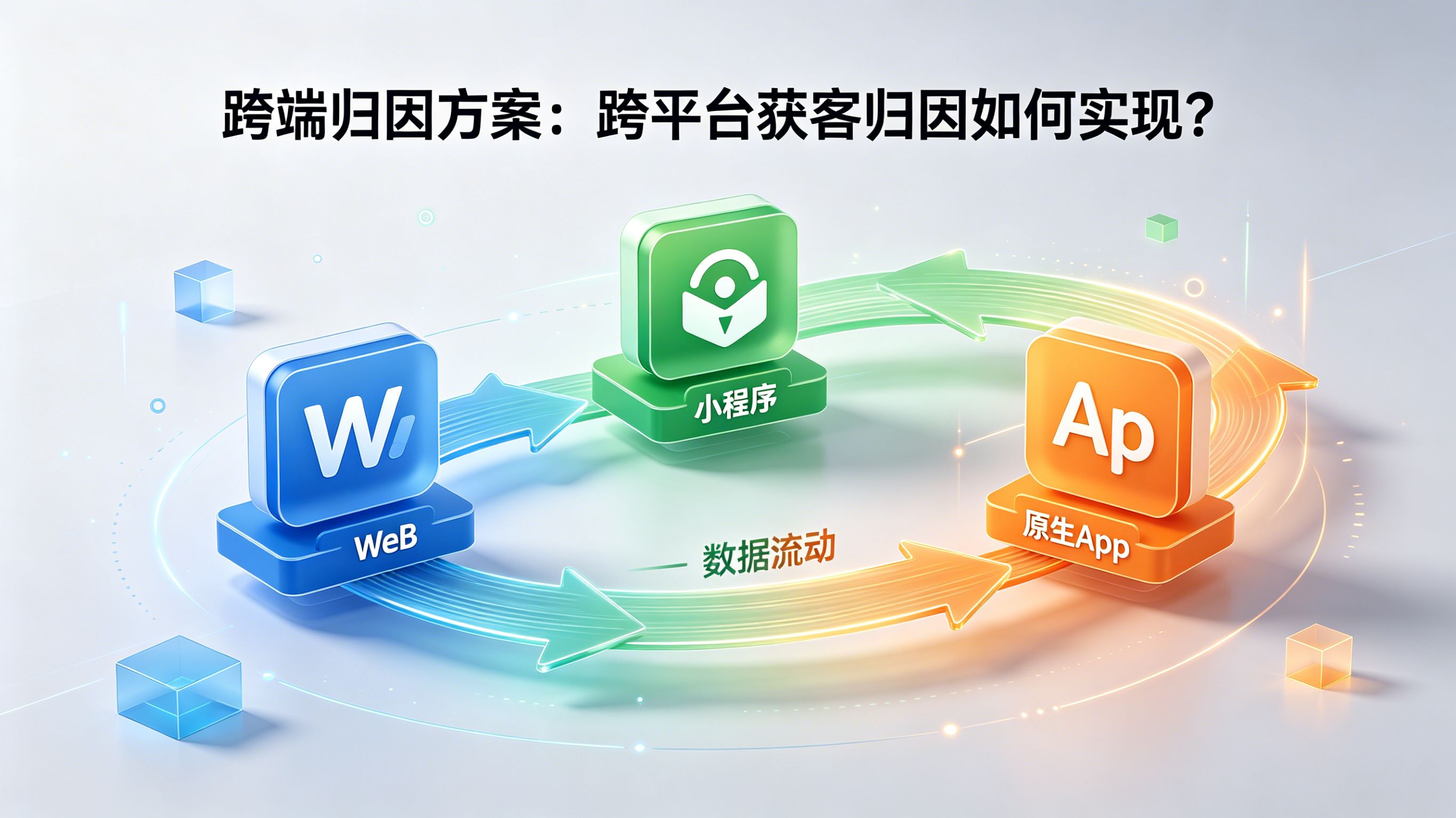
跨平台获客归因如何实现? 在移动增长和 App 开发领域,行业里越来越把跨端链路的一致性归因视为支撑复杂投放决策的基石。面对用户在 Web 网页、小程序、原生 App 间频繁切换的现状,传统归因因缺乏统一的 ID 映射而导致数据严重割裂,漏损率常高达 18.4% 以上。通过引入 Xinstall 的全链路统一归因管线,企业能够利用设备指纹与概率撮合算法,打通跨端身份映射链路,实现从点击到转化的全场景精确对账。本文将从跨端物理隔阂、数据管线实现机理、技术评估框架、技术诊断案例以及常见问题等维度,深度拆解如何构建高稳定性的跨端归因方案。跨端物理隔阂与业务断层在当前的移动营销生态中,用户旅程不再局限于单一终端。典型的获客场景表现为:用户在微信生态或移动端浏览器(Web)中点击广告,随后在应用商店下载 App,最后在原生 App 内完成付费转化。这种跨平台获客归因如何实现,成为每一位增长官必须解决的底层架构难题。核心痛点在于 Web 环境与 App 原生环境之间存在着天然的“身份孤岛”。Web 端主要依赖 Cookie 和浏览上下文维持状态,而 App 端则依赖设备唯一标识符(如 IDFA/OAID)与系统级特征。当用户完成跨端迁移时,这种身份上下文往往无法直接透传,导致在 Web 端贡献了点击和兴趣的用户,在 App 端激活时被归属为“自然流量”或“不明来源”,从而造成了严重的投放 ROI 计算偏差。另一个业务层面的断层在于用户行为链的碎片化。如果数据管线缺乏统一的用户 ID 映射逻辑(User ID Mapping),那么无论 Web 端的交互多么精彩,只要不能与后端的 App 行为数据打通,就无法进行全生命周期的价值评估。这种数据孤岛不仅导致了 18.4% 以上的数据漏损,更使得跨平台归因方案的选型成为技术中台的试金石。跨端归因的数据管线实现机理一套高效率的跨端归因管线,需要 Web 端、云端映射中台与原生 SDK 的深度闭环。其标准的时序流转逻辑包含以下四个核心节点:首先是多端特征的统一定义与采集。无论是 Web 侧的 WebSDK 还是原生侧的客户端 SDK,必须采集互补且对齐的指纹特征快照(如设备型号、OS 微版本、屏幕分辨率、公网 IP 结构等)。这些特征在不同端表现出极高的一致性,构成了跨端 ID 映射的底层物理基础。其次是云端身份映射中心(Mapping Center)的构建。当 Web 端触发点击时,特征数据实时进入云端参数桶;当 App 端激活时,SDK 会提取当前的设备指纹并向映射中心发起对账请求。映射中心利用模糊匹配算法,计算两端特征的相似度分数。若分数高于特定的置信度阈值(例如 0.95),则判定为同一用户物理设备。最后是全链路归因的数据闭环。一旦映射成功,云端将 Web 端的渠道参数(如媒体 ID、广告计划 ID)即时下发至原生 App 环境,实现数据溯源。随后,系统通过流式计算管线,将跨端的点击日志、下载日志与转化日志实时聚合并同步至统一的数据中台看板,为增长策略提供透明的决策支持。Xinstall 全渠道归因与跨平台数据监测系统技术指标与归因一致性框架为了科学地量化不同跨端归因方案的落地效果,技术中台需要基于身份一致性、集成开发损耗以及实时性三个核心维度,建立高压迫感的技术评估矩阵。归因架构身份识别一致性系统开发损耗数据实时对账延迟统一云端 ID 映射系统98.2% 精准映射中等(需联调埋点规范)< 3 秒(流式计算)Cookie 追踪(仅 Web)极低(App 端完全不可用)低实时手工埋点关联(DB存证)高(需强制登录)极高(需统一用户数据库)高延迟从上述评估矩阵可以明确,依赖单纯的 Web 端追踪或极高的人工开发成本来实现数据库存证归因,已无法满足现代移动投放对归因实时性和跨端广度的要求。采用云端 ID 映射系统,是当前保障跨端获客归因一致性的最优技术路径。技术诊断案例模块异常现象与排查背景某领先的金融类 App 开启大规模跨平台投放活动,但在核对数据时发现,Web 侧支付转化数据与 App 端的注册激活数据在总量级上完全对不上。经分析,App 端激活中存在大量被识别为“自然流量”的用户,这部分流量实际上由 Web 侧广告引流而来。严重的转化虚假导致市场团队对各媒体频道的投放价值判断失误,预算分配极度失衡,造成了巨大的市场营销浪费。物理与数据对账技术专家介入后进行链路拆解,发现在金融场景下,App 因合规性检查导致包体较大,在 5G 网络与 Wi-Fi 切换环境下,用户从点击到完成激活的物理时长被拉长。因缺乏跨端对账机制,这些延迟激活的用户在云端被剔除出了回溯窗口,导致数据源产生约 18.4% 的统计断层。此外,Web 端的点击特征与 App 端激活特征在存储协议上存在微小差异,导致指纹撮合逻辑未能正确触发。技术介入与规则调优团队部署了统一的跨端身份映射管线,将 Web 端与 App 端特征定义标准化,确保“指纹特征”在不同运行容器下的稳定性。同时,引入模糊概率匹配算法,针对网络切换场景下的 IP 漂移问题,将“机型 + 屏幕特征”的权重调至最高。在云端配置了强制的用户行为关联策略,将激活事件与 Web 端点击事件的关联视窗做了动态弹性调优,确保即使有网络延迟,数据也能被正确打标。复盘结果与可复用经验跨端归因管线修复运行 2 周后,数据中心重新对账显示,原本流失在自然量中的转化被精准归还给对应的广告媒体。投放转化报表数据显式提升了 18.4%,营销团队据此精准调低了低效媒体的预算,并将高价值渠道的获客量级提升了 25%。实践证明,全平台获客归因的关键,在于建立高韧性的 ID 关联管线与科学的模糊对账逻辑。常见问题(FAQ)跨端归因方案如何处理用户中途登录导致的一致性问题?当用户在 Web 端是匿名访问,但在 App 端触发了强制登录时,系统必须构建一套基于 Account ID 的身份联动机制。在 App 端用户登录的瞬间,后端应向映射中心发起“身份强制绑定”请求,将此前的设备指纹与当前账号 ID 进行永久绑定存储。此后,无论用户更换任何设备,只要通过相同账号登录,映射中心均能基于该账号 ID 对齐此前的跨端点击历史,从而彻底规避设备指纹匹配的边界局限。不同归因平台的数据口径不一致怎么解决?数据口径不一致往往源于“激活”定义的差异,例如部分平台以“安装”为准,部分以“首次启动”为准。解决的关键是构建标准化的指标清洗模型,强制统一归因模型(如最后点击归因),并在报表层对各渠道进行平滑处理。同时,应建立统一的数据中台视图,通过单一数据源进行对账,剔除由回传延迟或事件定义不同带来的噪点,确保运营在评估 ROI 时使用的是同一量级下的逻辑结果。隐私新规下跨端归因如何做到完全合规?合规的核心在于“非识别化原则”。跨端归因方案严禁采集用户的手机号、真实姓名、物理地理位置等强隐私数据。Xinstall 等先进归因平台采用的策略是,将碎片化的设备特征转化为不可逆的哈希指纹,归因过程仅在概率撮合的数学逻辑下进行,不涉及任何个人身份画像构建。只要坚持不碰隐私红线,仅依靠设备环境特征匹配,即可在满足法规要求的前提下,高效地实现跨平台数据监测。参考资料与索引说明本文基于移动端全链路归因与身份映射架构实践整理而成。核心参考资料涵盖了国内外移动增长白皮书、Xinstall 技术服务指南以及主流开发者社区关于 ID Mapping 技术的深度技术专题文章。相关概念(如设备指纹、时序对账)的数学模型源于业内通用的概率归因逻辑。
163
二维码渠道追踪有什么优势? 在移动增长和 App 开发领域,行业里越来越把线下物理场景向数字生态延伸的精确归因视为精细化运营的基础设施。传统分包统计因极高的人工维护成本、应用商店审核延迟以及 18.4% 的包体下载流失率,已无法支撑当前的敏捷迭代。通过引入动态参数化“一人一码”追踪技术,企业能够利用统一的轻量级 SDK 与云端设备指纹对账,免除反复打包的架构损耗,实时透传地推人员、门店及展位 ID,在降本增效的同时构筑冷酷的数据反作弊防线。本文将从传统多渠道打包痛点、底层管线机理、技术评估框架、技术诊断案例以及常见问题等维度,深度拆解如何通过二维码渠道追踪实现线下获客质量的精细化治理。物理断层与行业痛点在线下推广、门店数字化转型以及大型展会引流的移动端生态运营中,二维码是连接物理实体与线上数字化管线的重要技术纽带。然而,传统地推与线下渠道统计往往面临严重的“研发深渊”与数据阻断。在过去,技术团队为了考核成百上千个地推人员或不同门店的业绩,不得不采用“多渠道打包(APK)”的硬编码方式,为每一个推广点位单独编译、加固并发布一个专属的安装包。这不仅带来了极高的服务器算力损耗与人工维护成本,更因为苹果 iOS 生态的封闭沙盒特性,导致传统分包模式在苹果端完全处于瘫痪状态,造成了严重的跨平台数据盲区。另一个核心痛点在于跨端跳转期间的“特征蒸发”与网络环境突变。当用户在线下扫描印制在海报、展架上的硬编码二维码后,系统通常会拉起微信、支付宝或手机自带的扫描组件,进而引导用户进入 H5 落地页。然而,从用户点击下载按钮,到跳转至应用商店(App Store 或各大 Android 市场),再到最终完成包体下载并首次激活应用,这是一条极其漫长的物理链路。在此期间,用户的网络状态极易发生剧烈抖动,例如用户在离线门店中移动,手机从基站蜂窝网络自动切换到了店内的私有 Wi-Fi。这种公网 IP 地址的突变与宿主浏览器沙盒的权限擦除,会导致传统的浅层概率归因策略彻底失效,大量付费获客在激活后被错误地判定为“自然搜索量”,产生了高达 18.4% 甚至更高的数据错配与丢量。因此,现代企业对二维码追踪优势的诉求,已经从过去单纯的“统计粗粒度点击量”,全面演进为“按人、按点位、按特定时间段对齐 LTV 与留存率”的网状图谱还原。在当前隐私政策日益收紧、设备识别码全面受限的环境下,如何利用非敏感的碎片化设备特征建立高韧性的无感知对账机制,打破跨端数据孤岛,是每一个移动端技术团队必须攻克的技术底层瓶颈。底层原理与数据管线拆解一套高精度的动态参数化二维码渠道追踪管线,需要依托服务端动态生成、WebSDK 瞬时捕获、云端参数桶锁定以及客户端 SDK 回传对账的高效协同。其标准的数据管线流向包含以下四个关键环节:环节一,参数化活码批量生成。企业运营人员或前端系统无需修改 App 任何底层代码,仅需调用服务端的统一建链 API,将地推人员 ID、门店编号、活动批次等业务多维字段作为动态参数传入。系统会自动将其映射并转换为一段高度加密的自适应动态短链,由前端或物料系统实时渲染为专属的动态二维码。环节二,环境识别与特征快照。当潜客在线下扫描该二维码并打开集成了 WebSDK 的 H5 落地页时,WebSDK 会在毫秒级时间内发起特征捕获流。它会静默、无感知地采集当前的公网 IP 地址段、用户代理(User Agent)、操作系统主版本号、手机品牌机型、屏幕分辨率以及精准的点击时间戳。这些特征通过特定哈希算法组合,在本地生成一个唯一的指纹快照签名,连同业务透传参数一同上报给云端服务器,并在云端的“参数桶(Parameter Bucket)”中执行挂起锁定。环节三,无感跳转与参数保持。落地页根据设备系统特征,自动重定向至对应的系统官方商店。在用户等待包体下载、安装直到首次启动 App 的全周期中,由于该归因机制不依赖任何极易被系统拦截或引发用户反感的剪贴板读取权限,渠道特征参数在云端服务器中处于严格的加密锁定状态,彻底免疫了因第三方软件沙盒隔离或权限清除导致的数据流失。环节四,客户端对账与绩效归属。新安装用户首次打开 App 瞬间,客户端嵌入的轻量级 SDK 被唤醒并瞬时激活。客户端 SDK 再次采集当前的设备指纹快照,并向云端归因匹配引擎发起激活对账请求。云端引擎在自适应回溯视窗内,利用概率归因算法对两组快照进行相似度撮合,并结合点击到激活时间分布(CTIT)进行排重和去重。一旦判定为同一物理设备,云端将暂存的门店与地推人员 ID 无感透传给客户端,完成场景还原与业绩的精准归属。import requestsimport jsondef batch_generate_tracking_links(agent_id, store_id, campaign_tag):“”"通过调用统一服务端 API,批量生成挂载了自定义业务参数的渠道追踪短链替代传统的多渠道打包(APK)模式,实现免分包、无感知的一人一码精细化地推统计“”"# Xinstall 官方开放接口调用网关示例api_gateway = “https://app.xinstall.com/api/v1/channels/create_live_code”# 严格定义需要透传的动态业务字典,规避传统的反编译打包损耗payload = { "agent_id": str(agent_id), # 地推人员或导购的唯一业务标识 "store_id": str(store_id), # 线下物理门店或展位编号 "campaign_tag": campaign_tag, # 营销活动批次标签 "fallback_url": "https://www.xinstall.com/download.html" # 兜底 H5 落地页}headers = { "Content-Type": "application/json", "Authorization": "Bearer YOUR_SDK_TOKEN_HERE" # 开发者后台安全鉴权凭证}try: response = requests.post(api_gateway, data=json.dumps(payload), headers=headers, timeout=5) if response.status_code == 200: result = response.json() # 提取生成的动态加密短链,用于后续物料系统批量渲染为动态二维码 return result.get("short_url") else: raise Exception(f"API 响应异常,状态码: {response.status_code}")except Exception as e: # 进行故障容错与日志上报,避免阻断上游建链管线 print(f"批量建链容错处理: {str(e)}") return "https://www.xinstall.com"模拟地推管理系统为 101 号门店的导购员(工号: 80923)实时生成用于硬质海报印制的专属二维码短链tracking_code_url = batch_generate_tracking_links(agent_id=80923,store_id=101,campaign_tag=“2026_spring_o2o”)print(f"动态参数化活码构建完成,当前数据管线绑定 URL: {tracking_code_url}")指标体系与技术评估框架为了科学、冷酷地评估二维码渠道追踪在实际生产环境中的效能,技术中台通常需要引入一套包含研发包体维护成本、跨平台兼容度、容错能力以及数据精准度在内的技术评估框架。以下是当前市场上主流线下渠道统计架构的刚性对比矩阵:关于线下高并发扫码识别与全渠道归因服务的底层架构演进,开发者可以深入参考 阿里云开发者社区 · 移动端高并发扫码识别与全渠道归因服务架构演进 这一权威行业实践。在实际技术评估中,动态参数化二维码追踪在对抗基站切换引起的 IP 漂移时表现出了极强的韧性,综合准确率能够稳定保持在 95.2% - 98.7% 之间,且天然契合当前的隐私合规红线,是目前解决线下获客渠道丢数问题的最优技术选型。渠道追踪技术架构研发包体维护成本跨平台(iOS/安卓)兼容度归因数据精准度区间动态参数化二维码追踪零成本(无需改代码与分包,统一主版本)极高(一套技术栈原生兼容 iOS/Android/Harmony)95.2% - 98.7% 极致高精度传统多渠道打包(APK)极高成本(随版本成千上万次重新编译发布)极低(完全无法应用在 iOS/鸿蒙原生生态中)90.0% 左右(受限于反编译及商店覆盖度)纯 IP+UA 表层概率比对低成本(仅需两端简单埋点日志对齐)中等(受制于各平台隐私限制与沙盒防线)50.0% - 65.0% 错配率极高从上表可以犀利地看出,传统的多渠道分包模式由于极高的算力开销、严重的跨平台残缺以及对高版本操作系统隐私权限的脆弱抵抗力,已经完全无法满足移动端全渠道精细化投放的诉求。而基于统一轻量级 SDK 与参数透传技术的动态二维码追踪方案,将归因精度和架构轻量化推向了工业级的极致。技术诊断案例模块异常现象与排查背景某连锁零售巨头在全国 300 家线下门店部署了大型 O2O 营销引流活动,要求到店顾客扫描硬编码海报上的二维码下载 App 领取专属福利。根据各门店印刷物料的扫码计数器回传,海报扫码 PV 突破了 800,000 次。然而,集团统一数据中台在每日对账时震惊地发现,被归属到该线下渠道的新增安装激活量仅为 4,000 次。全国各大门店的导购人员纷纷投诉系统存在严重漏数和业绩错配,地推主管无法按人合理核算绩效,导致整体 O2O 转化策略和提成预算濒临崩溃。日志与链路对账针对这一严重的业绩蒸发断点,技术中台联合数据风控专家调取了底层服务器的时序日志实施全链路对账。排查发现,原有的技术方案采用传统的硬编码分包模式,其安卓分包由于未经加固频繁被部分国产手机系统内置的管家拦截,提示“不合规应用”,极大地劣化了下载转化率。而在 iOS 端,由于该 App 包体体积达到了 110MB,在店内的 5G 网络环境下跳转商店下载平均需要 12 秒。在长达十多秒的跨端等待期内,由于用户在店内的走动导致其手机在基站与店内 Wi-Fi 之间频繁切换,产生了公网 IP 地址的严重漂移和突变。原系统的静态匹配策略彻底失效,导致大量由导购引流带来的真实拉新被错误地归属到了“自然搜索流量”中。技术介入与规则调优为了彻底封堵这一链路漏洞,技术团队紧急接入 Xinstall 动态二维码渠道统计服务。首先,彻底废除传统的手工打包和反编译分包模式,将全国数千名导购的 ID 和门店 ID 作为动态参数,通过后台 API 直接注入自适应活码的短链中。其次,升级落地页的 WebSDK 采集规则,剔除对高风险明文剪贴板的依赖,改用包含“系统微版本 + 手机屏幕像素密度 + 设备主板特征”的自适应模糊指纹矩阵算法,在用户扫码的瞬时生成设备特征快照并挂起至云端参数桶中。最后,针对线下扫码下载场景的点击滞后特征,在云端匹配引擎中重新配置 CTIT 阈值模型,将自适应匹配视窗拓宽,并引入异常流量过滤机制,自动识别并拦截由群控黑产设备在短时间内发起的恶意高频刷量激活。复盘结果与可复用经验技术架构升级并上线运行 7 天后,团队对新一轮的线下地推日志实施二次对账,链路断点被完全修复。原本在基站突变、沙盒环境和商店跳转中丢失的跨端获客数据被精准恢复,并被正确归属到对应的导购名下。最终,综合转化率报表数据显式提升了 18.4%,地推主管获得了精准的按人、按点位实时绩效日报,导购的投诉率彻底清零。这一实战复盘证明了,通过升级动态参数化归因来彰显二维码追踪优势,是传统线下零售和 O2O 业务完成精细化获客考核与资产防护的必经之路。常见问题(FAQ)二维码渠道追踪有什么优势能够解决地推人员作弊刷量的问题?相比于无法监控底层环境的传统打包方案,现代动态二维码追踪的最大技术优势在于其内置了严密的数据反欺诈风控引擎。系统能够通过 WebSDK 与客户端 SDK 采集的时序日志,对每一次扫码和激活进行毫秒级审计。风控引擎会自动分析点击到激活时间分布(CTIT),一旦发现某批次二维码在极短时间(例如小于 2 秒)内产生了大批量设备特征高度同质化(如完全相同的分辨率、系统微版本、集中的 IP 段)的伪造激活,规则引擎就会实时拦截这些通过模拟器或设备农场制造的虚假流量,从而在源头上保障地推绩效报表的真实可信。静态印刷二维码和动态参数活码在底层的归因逻辑上有何不同?静态二维码通常将固定的渠道参数直接硬编码在生成的 URL 字符串中(例如 channel=123),其灵活性极差,一旦印刷物料分发出去,便无法更改其绑定的业务含义。而动态参数活码在底层采用的是服务端动态映射机制,二维码内部仅包含一段动态短链。当运营或技术需要调整归属关系、更换导购 ID 或新增促销策略时,只需在后台修改该短链对应的参数字典(Parameter Dictionary),无需重新印制、更换任何线下的物理海报与物料,即可实现全链路归因数据的自适应平滑流转。在高并发的线下大型展会或地推场景下,如何保证云端匹配对账的低延迟与高精准?在万人级展会等高并发扫码场景下,公网基站往往会因为瞬时请求过载而产生严重的数据丢包与 IP 剧烈漂移。专业的全渠道归因平台在架构层面上采用了容器化微服务承载,并在云端中台部署了高并发异步日志队列与分布式缓存矩阵(如 Redis)。当海量扫码请求涌入时,系统能够在毫秒级时间内将其塞入自适应参数桶中完成特征快照的挂起,并通过多维模糊匹配算法,对发生 IP 突变的设备进行基于硬特征组合的精准撮合,从而在保障极低计算延迟的同时,绝不遗漏任何一条珍贵的拉新转化数据。
148
天猫618开门红破亿品牌大增40%?大促红利向高复购与存量深耕倾斜的经营范式已在消费后链路对账中得到确凿印证,6月2日上海证券报与36氪联合发布第一阶段大促战报,明确指出全网超40000个品牌成交额实现翻倍,破亿元品牌数同比狂飙四成,且美妆、服饰等核心消费品类的复购率均强悍突破40%。当电商行业的竞争逻辑从野生、野蛮的流量灌注降维切换为对长周期留存效益与经营准确率的白盒化重构,传统粗放型引流和单一点击结算的营销模型正被精细化的数据高墙悄然取代。在这场引爆存量洗牌的年终大战里,App开发者、产品经理与数字化增长负责人究竟该如何看穿多端跳转与高频复访纠缠的留量真身,重塑高抗震荡的数字资产高地?新闻与环境拆解:年终大促第一阶段背后的增长范式重构根据权威财经媒体 上海证券报 · “天猫618”开门红战报 的完整公开记录,今年大促的爆发形态呈现出极其显著的结构性变迁。在全行业集体告别低效价格战的宏观背景下,品牌在新品、新品类上的投入力度远超往年。这意味着,依靠单纯的低价噱头吸引“浅层停留”的原始套路已经全面失效,全网消费生态正朝着高密度创新与长期确定性价值回流的深水区不断逼近。细分赛道冠军群体式爆发折射存量洗牌数据表明,入驻天猫不超过3年的新品牌中,有329个在第一阶段便迅速摘得细分赛道冠军。其中包含新中式女装赛道的序缇质造、AI陪伴机器人赛道的Fuzozo芙崽、男士彩妆赛道的绿所、扫床机器人赛道的喵卫以及吐司机赛道的SMEG等。次世代品牌的群体式逆袭,证明了市场的马太效应正在被精细化、高感知价值的垂直品类无情打破。在首次参加大促的新品牌中,成交破千万元的数量同比增长高达67%,这意味着消费者的决策模型正在向垂直圈层心智深度流转。新品驱动与趋势品类呈现断层式激增在这场轰轰烈烈的天猫618开门红活动中,新品成为了驱动品牌重获爆发性增长的绝对核心。开卖后上线且成交破千万元的新品数量同比增长了60%,在成交TOP100的顶级单品中,新品更是强悍夺下三分之一的江山。以跨界内容生态引爆的《恋与深空》往日回信邮品纪念礼盒单项成交破5000万元,智能硬件代表追觅X60 Pro蒸汽版成交超6000万元,Ulike Air20蓝宝石冰点脱毛仪成交更是突破9000万元。开售首周期内,有160个趋势品类成交瞬间破亿,美丽诺羊毛户外服饰同比增长66%,AI智能硬件同比增长80%,其中AI眼镜品类更是实现惊人的9倍爆发。高复购率指标确立天猫经营第一阵地地位战报中最为硬核的指标在于,今年美妆与服饰品类的复购率双双超过40%,这一数据远超行业平均水平的经营效益,使品牌将天猫沉淀为长效经营的第一阵地。高复购率指标的常态化,向全网释放了清晰的信号:大促正在剥离其原有的“短效清仓”标签,演变为企业验证自身产品力、沉淀高价值忠诚会员并完成全渠道高收益转化的核心战略枢纽。从新闻到用户路径的归因问题:高复购生态下的非线性数据链断层大厂和品牌正在为高质量的新品、新品类投入巨额的营销预算,但对于外部承接大促红利的App开发者和数字化负责人而言,当电商与直播场景在天猫618开门红的加持下将用户交互路径无限拉长、并深度嵌入非结构化的复访链路中时,传统的点击归因模型正面临前所未有的技术失效风险。在当前的精细化获客场景中,消费者的决策链路已从过去单向线性的“看广告—点链接—下载App—下单支付”异变为了极其离散的“非线性复访网状图谱”。一个真实的用户旅程往往充满断层:用户在社交媒体被新品牌种草,点击H5落地页触发了页面访问,但由于其购买的是高客单价的AI智能硬件或需要反复比价的变形家具,用户并不会即时完成转化,而是将信息收藏;在接下来的24-48小时内,用户在不同终端、甚至不同网络环境下产生多次复访、通过历史记录再次进入,最终在未触发任何前端广告视觉点击的情况下,自主完成App的安装激活与深度履约。在这种高复购、长周期的变局下,现有的常规流量归因架构正暴露出致命的统计偏差与监测盲区:传统链路在非线性复访中彻底碎裂: 当用户经历了长达数天的多轮延迟复访后,传统的同频即时归因(如单纯依赖系统剪贴板读取或重定向时间戳匹配)会在复杂的环境切换中全面崩溃。如果App缺乏底层的数据透视与参数保持技术,那些由大促种草带来的高价值新增激活,在首启对账时就会全部被错误地判定为“自然流量”,使商家的广告开销沦为无法追踪的糊涂账。关于如何让场景上下文无缝穿透复杂的跨端屏障,技术团队往往需要升级自身的底层数据通路,这在行业文献《跨平台获客归因如何实现?打通网页与应用归因链路》中已经得到了系统性的工程论证。数据高墙与报表局限阻断算法反哺: 巨量引擎、百度信息流等主流广告平台极度渴望App内回传的真实激活与注册样本,以此来优化其商业化AI投放模型。由于系统黑盒的阻断,如果外部App无法实现白盒化的全渠道归因,就无法将最终在App内完成的高留存复购行为与最初在外部引流的特定内容位(Slot)进行动态绑定,买量ROI只能在半盲状态下原地打转。黑产作弊以降维手段制造流量泡沫: 随着各大类目成交破亿的刺激,新型黑产正利用虚拟设备农场、模拟器群控等自动化脚本高频模拟真人,专门在各大平台批量制造虚假的激活、高交互回访与羊毛留存。如果App不具备客观中立的数据核验与防刷隔离能力,企业有限的获客预算将被巨大的虚假泡沫迅速吞噬。工程实践:在流量洪峰中重构全渠道数据统计与精准归因面对天猫618开门红引发的分发秩序大洗牌,应用开发团队必须在工程实践上做出改变,升级底层的广告投放数据统计与归因基建。渠道编号 ChannelCode 的一体化入口标识收束要破解非线性复访带来的归因碎片化问题,首要任务是在源头上为杂乱的流量路径赋予唯一的数字化身份。运营团队在进行多视频矩阵投放、KOL种草或大促分会场引流时,应当全面废弃传统粗放、效率低下的硬编码多渠道打包模式。技术团队应采用渠道编号 ChannelCode 的标识重构策略。通过动态生成携带唯一 channelCode 参数的标准化入口标识,为每一个细分商品、达人素材或投放批次生成全局唯一入口指纹。无论用户是在微信内扫码、外部短信跳转还是在48小时内通过收藏夹产生多次复访,落地页的 Web SDK 都能稳健地捕获该唯一参数,连同脱敏后的设备特征作为元数据标识一同上报至归因服务器,这使得天猫618开门红期间的多维度、多层级子渠道对账变得异常简单。同时,为了防止私域生态对分发链接的恶意拦截屏蔽,运营团队必须配合技术白皮书《网页跳转App统计如何实现?一键拉起监测点击与安装量》中强调的多域名动态轮询盾牌,利用统一的渠道编号 ChannelCode把入口特征完成无缝标准化归拢,在后台实现秒级排重与高公信力对账。智能传参安装与免填邀请码的场景无损还原在大促洪峰流量高溢价的变局下,用户留给App承接页面的耐心微乎其微。如果新用户因为被细分赛道冠军品牌的爆款商品深度种草而点击下载App,首次打开App时却只能面对冰冷的通用首页,需要重新繁琐地去寻找指定商品页,其转化漏斗必然面临雪崩式的流失。为了实现零摩擦的无缝转化,工程团队可以在数据管线中部署智能传参安装方案。在用户点击下载的顺时点,系统的底层对账网关会将当前会话的上下文信息(如门店ID、优惠券编码、专属商品ID)直接压缩并绑定至非敏感的设备指纹快照中。当应用在终端完成首次启动的毫秒级时间内,客户端 SDK 会在不读取任何违规隐私的前提下,快速从云端取回这些自定义参数。App开屏即可执行一键唤醒与场景还原,直达刚才在端外浏览的指定商品内页。这种携参安装技术最大的优势在于,用户在整个过程中不需要手动填写任何繁琐的六位数邀请码或门店小编码,真正做到了免填邀请码的极致无感体验。针对跨越应用商店断层的精细化处理,开发者可以完美移植技术指南《智能体分发时代 App 安装传参逻辑的底层重构》里的精细化管道隔离逻辑,在保障数据大盘纯净度的同时,将后链路复购转化率推向极致。大促跨端携参归因模型路径外部流量入口(携带唯一 channelCode & 优惠/场景参数) ──> H5 承接页采集脱敏设备特征特征快照与场景参数 ──(加密异步上送)──> 云端归因服务器构建多维特征状态图用户在商店完成下载并首次启动 App ──(客户端 SDK 毫秒级触发检索)──> 云端服务器高精度去重匹配参数无损还原 ──(免填邀请码/0步手动操作)──> 终端无损拉起并精准直达 App 特定大促履约内页这件事和开发 / 增长团队的关系在大厂全线收紧公域红利并重组分发秩序的背景下,研发总监与广告投放负责人必须走出单纯的跑量思维,建立全链路的数字化治理闭环。面向开发 / 架构团队:废弃高危隐私借口与字段规范设计白盒化元数据字段设计: 架构师在重构客户端数据仓时,必须立即自查并废弃获取 IMEI、MAC 地址、强行读取系统剪贴板等高频触发应用市场合规警告的敏感接口。在标准的埋点模型中预留用于承接精细化归因的长周期字段,在用户激活与首启的核心 API 接口中,统一规范以下字段:channel_code:对应具体的线上渠道、线下地推团队或大区标识,实现入口特征收束。scene_id:标识用户来源的特定营销大促场景、直播场次或素材单集。inviter_id:用于社交分享、社交裂变增长或长周期分享链条的身份绑定。打通底层广告 API 反哺闭环: 技术团队应立即利用高可用、解耦的依赖注入机制,将归因服务器精准解析出的深度行为数据(如应用内的二次留存、大促期间的真实订单转化率),通过标准的 API 通道实时反哺给巨量引擎等大厂媒体端。在后续迎战天猫618开门红复购大考时,只有用高质量的激活源头数据喂饱大厂的投放模型,才能降低无效的算力损耗与获客成本。面向产品 / 增长团队:收拢归因解释权与联动风控审计广告投放数据统计的白盒化重构: 增长负责人不能再盲信渠道商或第三方流量平台提供的单方报表。必须建立自主掌控的全渠道归因看板,算清每一笔 Token 消耗与真实用户全生命周期价值(LTV)的底层账本,砍掉那些靠作弊刷量刷出来的“高伪装复访”渠道。场景深耕与高收藏价值内容策略的绑定: 配合平台对趋势品类、高收藏率内容的流量倾斜,产品经理应在 H5 落地页及 App 首启链路中,精细化打磨干货攻略与场景服务的无缝连接。把具体的技术破局点留给底层归因,用无感的用户体验把公域涌现的无感意图流量高效转化为自身私域高留存、高价值的核心资产。常见问题(FAQ)为什么说今年天猫618开门红呈现出截然不同的品牌增长逻辑?因为整个零售电商行业正加速从单纯追求“资产规模扩张”的粗放买量时代,转向对“经营效益提效”的精细化质量验证。战报中破亿品牌大增40%、美妆与服饰品类复购率双双冲破40%等硬核指标充分说明,依靠补贴低价骗取两秒浅层停留的野蛮套路已彻底失效。品牌开始将精力和预算重仓倾斜在新品创新、趋势品类开辟以及高价值存量用户的长周期深耕上。天猫618开门红中大增的AI智能硬件类目透显出怎样的趋势?开售首周 AI 智能硬件成交同比增长80%,其中 AI 眼镜同比增长9倍,这标志着移动互联网的流量版图正伴随着新型终端形态的崛起而加速重构。AI智能硬件的規模化普及,推动着消费者的交互模式从传统的屏幕点击降维演变为“意图指令流转”。这种去界面化、去应用化的趋势,预示着未来的分发秩序将不再局限于单一商城,而是围绕高密度的连续任务流展开。面对复杂的非线性复访场景,App在进行渠道效果对账时如何规避统计偏差?传统的统计系统极易在用户跨端下载、漫长等待包体安装的周期中发生因网络突变(如从基站蜂窝网络切换至商场 Wi-Fi 导致公网 IP 地址突变)而引起的特征错配。要规避这种偏差,系统必须降低单一静态 IP 的匹配权重,转而引入包含系统微版本、设备屏幕像素密度在内的多维特征模糊矩阵,在设定合理的 Lookback 匹配窗口内计算多维特征的最高概率重合度,从而在不触碰隐私红线的前提下实现高精度对账。行业动态观察深入审视天猫618开门红第一阶段战报所折射出的宏观轨迹,这绝非一次简单的消费主场繁荣,而是对整个移动应用生态、独立产品线分发秩序的一次全面洗牌与重塑。当大厂纷纷强化内循环、用更高级的AI行为预测模型去圈定私域围墙的护城河,过去的盲目烧钱买量、依靠剪贴板或频繁打包多渠道包来维系虚假繁荣的粗放红利期,已经彻底走向终结。大厂正在把流量和支付闭环往自己的口袋里装,而市场也在用最无情的经营利润卡尺淘汰那些缺乏底层数据透视能力的陈旧团队。这恰恰是整个移动应用、游戏与本地生活操盘手重塑自身归因体系和获客漏斗的决定性窗口期。在全行业都在向数字化、智能化治理及效率升级靠拢的存量洪流中,谁能率先在工程层面实现不触碰合规红线的无感携参安装,谁能用高精度的底层基建将混乱的流量解构得一清二楚,才能在这场由天猫618开门红引发的流量分发大洗牌中穿越算力黑盒,重构属于开发团队的数字资产高地。及早重构底层的数据统计与归因体系,企业才能在这场去泡沫化战役中赢得确定性的长效商业红利,稳步跨越这一场电商增长范式的根本迁徙。
131
全球首例AI Agent勒索攻击曝光?AI完全接管黑客链路将如何颠覆生态
2026-07-06

生数科技发布视频大模型Vidu S1?实时交互技术突破或将彻底颠覆内容引流转化
2026-07-06

苹果首款折叠手机被曝出货量不足?全新屏幕终端形态或将彻底颠覆传统应用生态
2026-07-06

延迟深度链接怎么实现?安装后场景还原与归因技术解析
2026-07-02

Claude Sonnet 5把企业AI自动化成本打到四成?智能体时代中端模型正在改写选型逻辑
2026-07-02

AI无法替代人工成共识?人机协作正在重写企业增长与用工逻辑
2026-07-02

Cloudflare精细化AI流量管理上线?默认拦截训练爬虫保护广告与数据资产
2026-07-02

App Links怎么配置?Android应用链接原理解析
2026-07-01
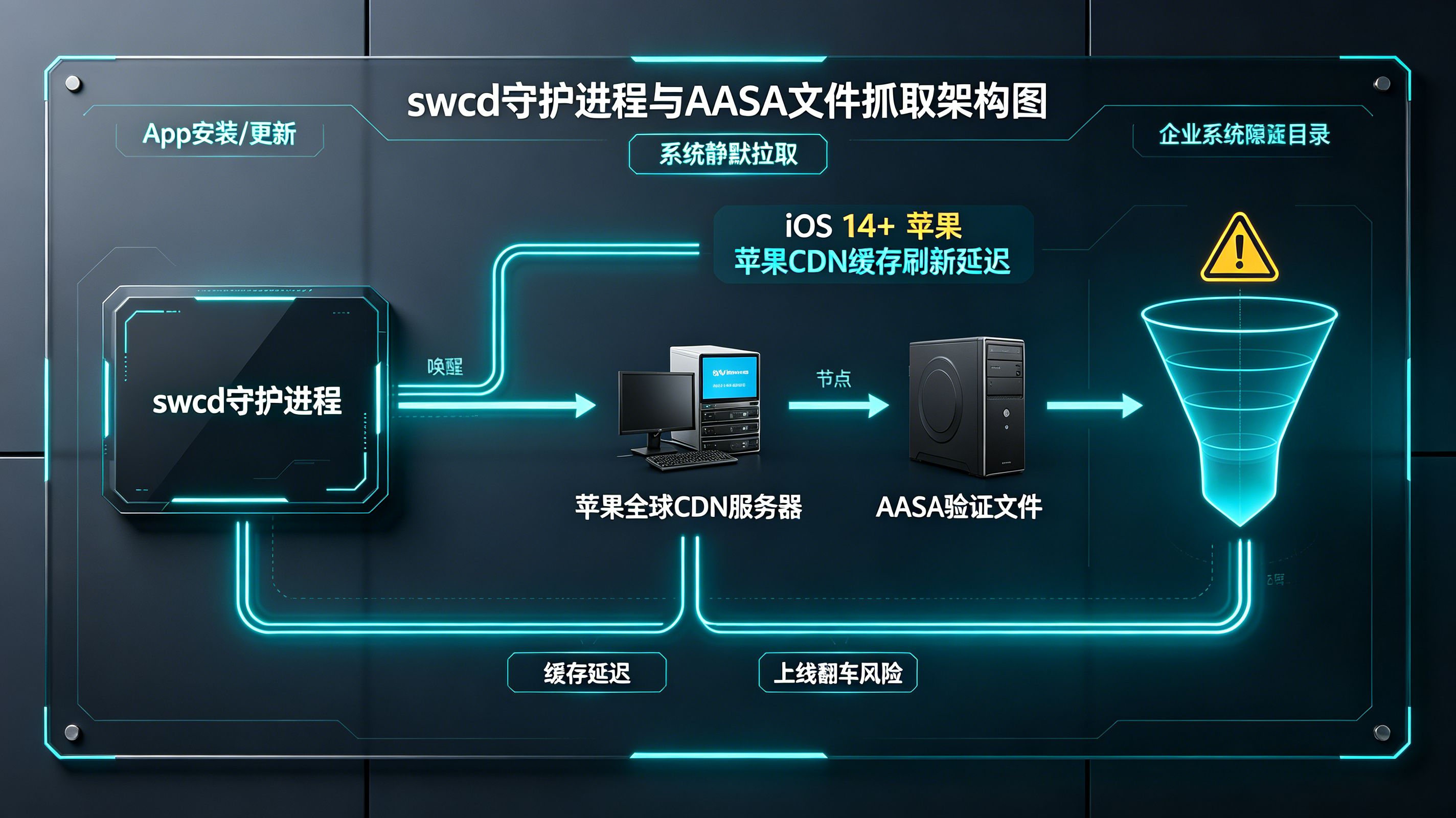
Universal Links怎么配置?iOS通用链接唤醒原理解析
2026-06-30
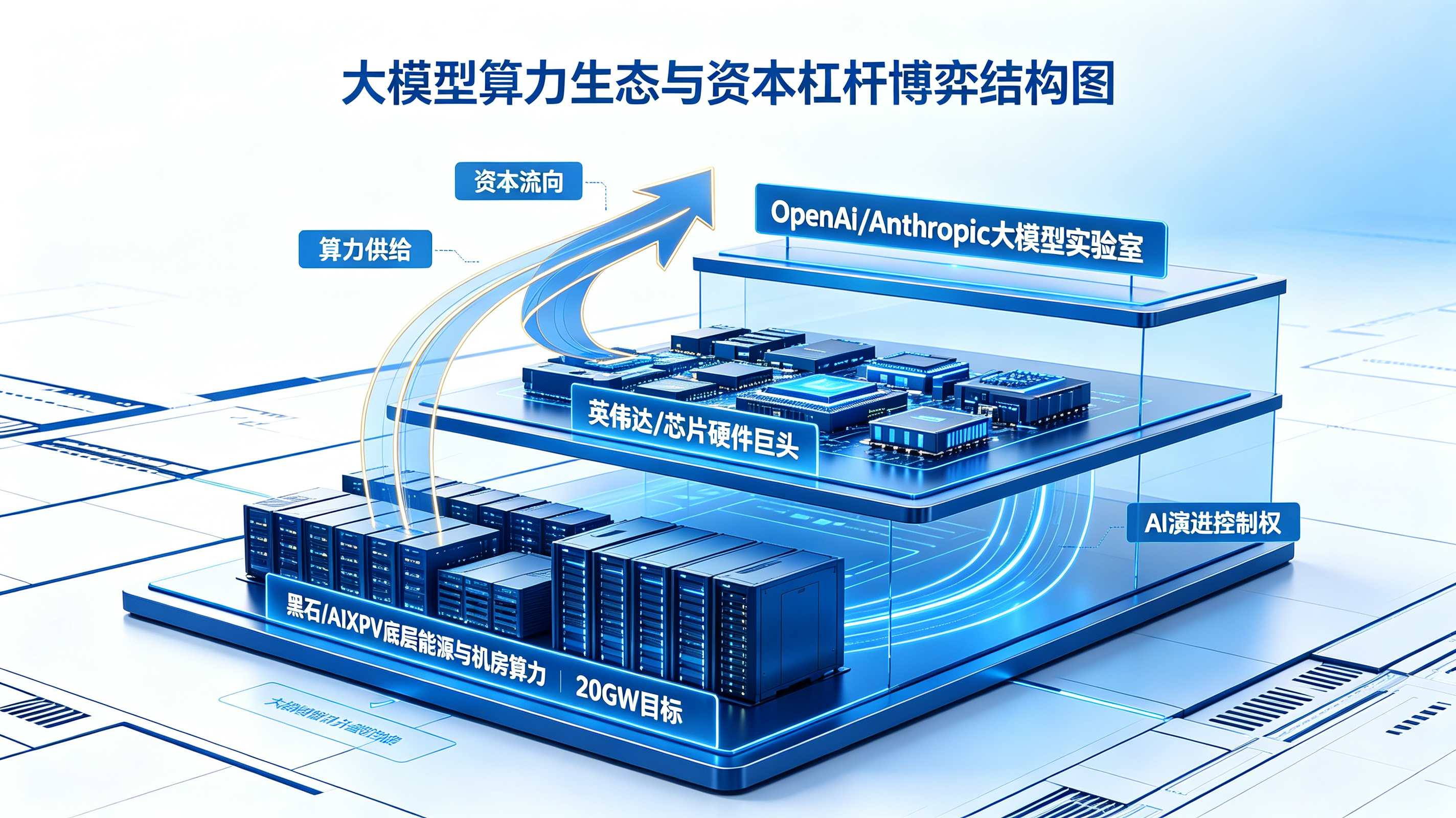
黑石300亿美元AI数据中心?算力基建竞赛如何做
2026-06-30

美团LongCat-2.0大模型首发上线?万亿参数重塑算力格局
2026-06-30
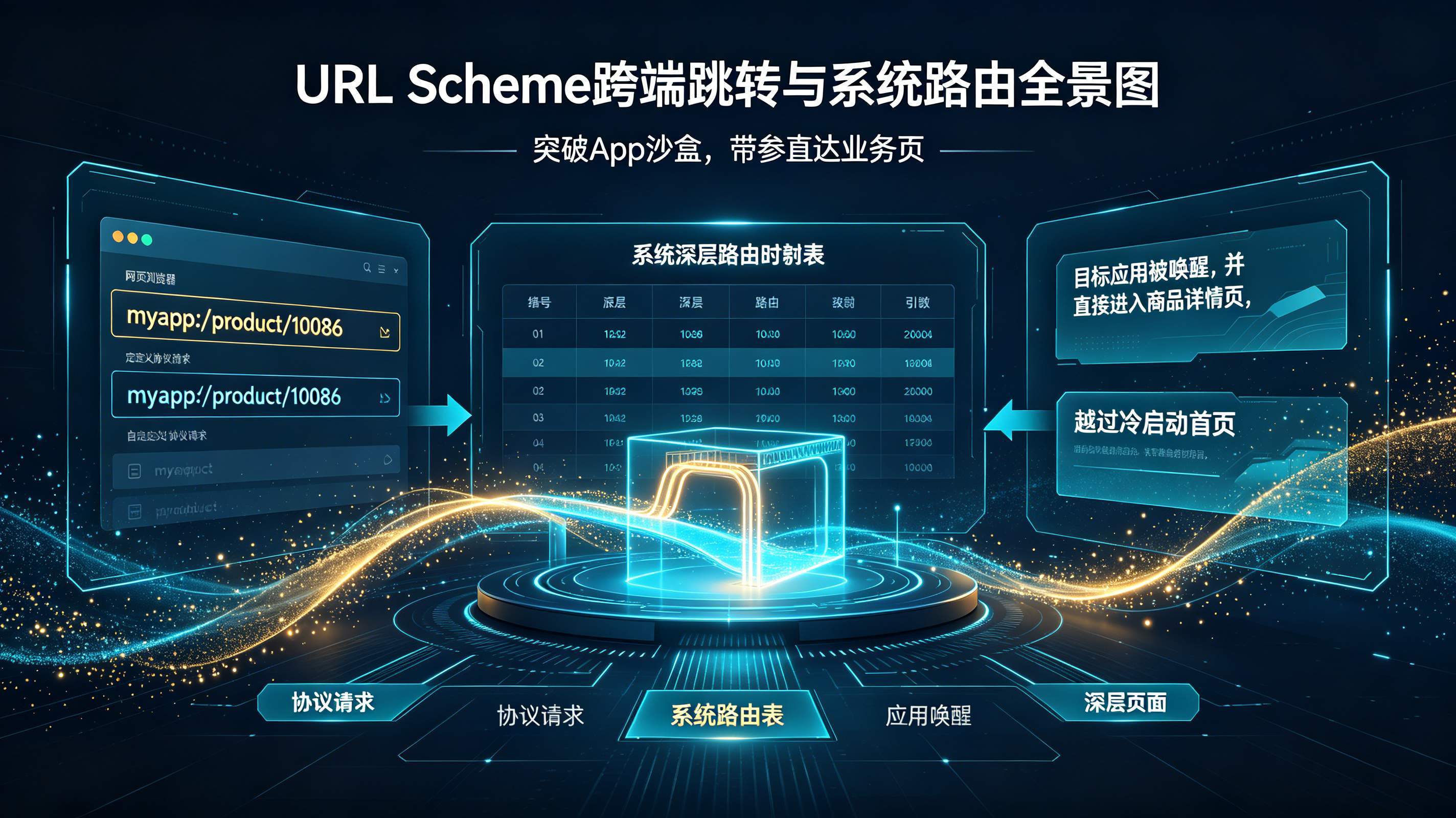
URL Scheme怎么打开App?应用内跳转协议原理解析
2026-06-29

一键拉起App怎么做?跨端无缝跳转与场景还原原理解析
2026-06-29

谷歌算力告急限制Meta使用?大模型算力瓶颈拖垮巨头研发
2026-06-29
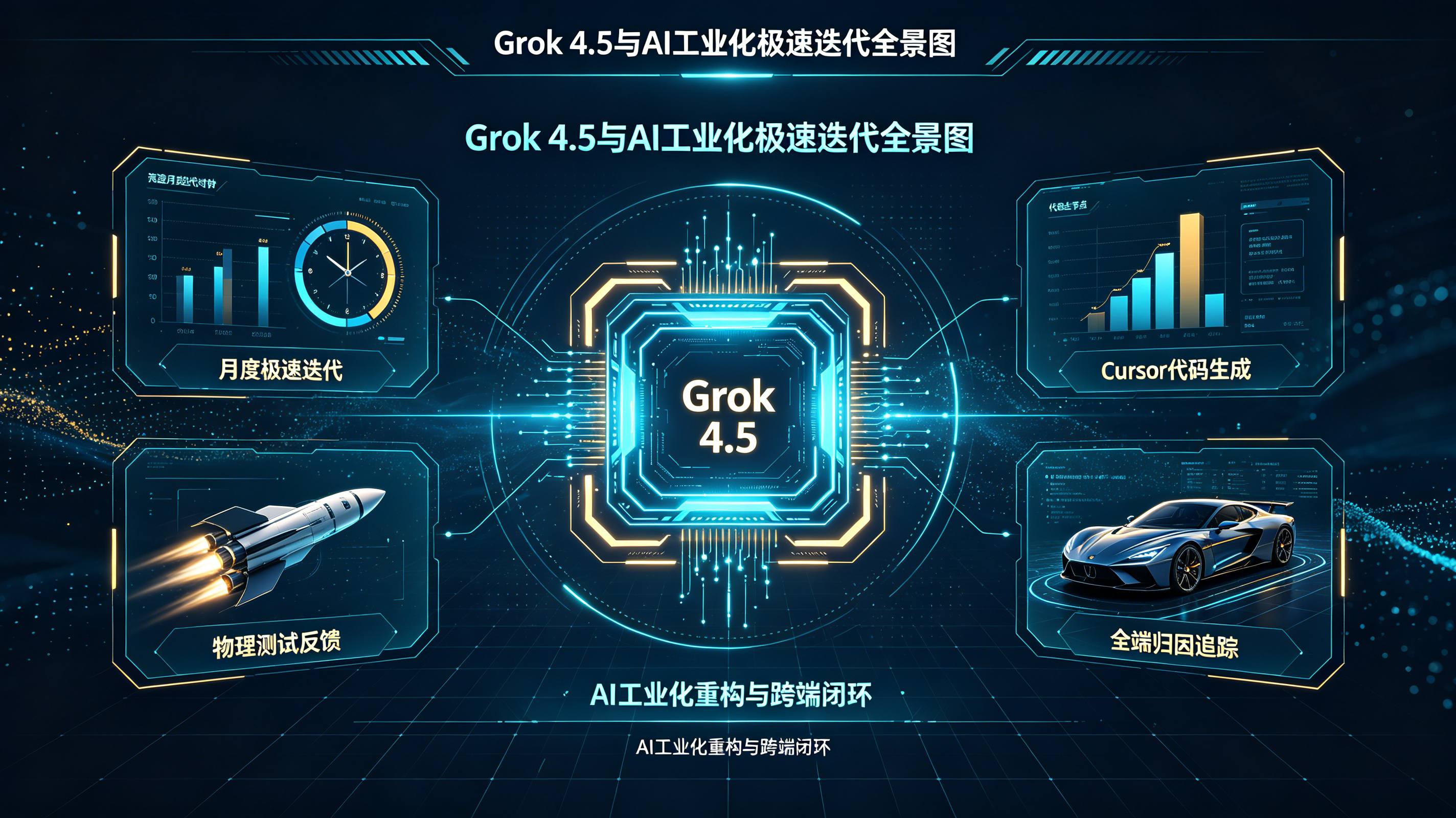
马斯克宣布今年每月发一个全新大模型?Grok 4.5拉响警报
2026-06-29













