






手机微信扫一扫联系客服
联系电话:18046269997



 APP安装免填邀请码
APP安装免填邀请码 社交分享效果统计
社交分享效果统计 广告投放数据统计
广告投放数据统计 CPA/CPS推广效果统计
CPA/CPS推广效果统计 App地推统计
App地推统计 App拉起
App拉起 网页/应用内直接安装
网页/应用内直接安装 Android多渠道打包
Android多渠道打包 App安装后自动绑定
App安装后自动绑定 App分享效果统计
App分享效果统计 Deeplink深度链接
Deeplink深度链接 手机微信扫一扫联系客服

Xinstall 免填邀请码怎么实现?在移动增长和 App 开发领域,行业里越来越把 Xinstall 免填邀请码怎么实现视为跨越应用商店黑盒、重塑裂变拉新漏斗和打通数据闭环的核心基建能力。传统的拉新裂变活动中,用户必须在 H5 页面手动长按复制一段无序的邀请码,随后经历跳转应用商店、下载、漫长的物理安装、同意系统权限、进行冷启动,最后再寻找特定入口手动粘贴。这条脆弱的交互链路存在着巨大的体验摩擦,任何一个环节的遗忘或操作繁琐都会导致漏斗急剧收缩,通常折损率高达 60% 以上。要从底层根除这一断层问题,企业需要深入理解底层传参机制,通过 Xinstall 官网 所展示的全局技术架构,我们可以发现真正的解决方案并不是优化复制按钮的 UI,而是构建一套能够在端云之间进行状态快照与无感还原的数据管线。物理断层与行业痛点在全渠道营销与分发生态中,物理断层是阻碍携带参数安装的最大壁垒。现代操作系统(如 iOS 和 Android)为了保障用户隐私与设备安全,构建了极度严格的沙盒机制。这种机制天然阻断了 Web 浏览器前端与原生 App 运行内存之间的直接通信。当用户在外部流量环境(如微信、朋友圈、信息流广告)中触发了带有渠道标识或邀请者 ID 的动作后,一旦流量进入了应用商店这个“黑盒”,所有的参数上下文就会被彻底剥离。如果没有高级的动态参数暂存与还原匹配技术,这些珍贵的归因指标将永远消失在下载的洪流中,导致推广数据与实际激活用户完全脱节。这种脱节带来的直接后果就是业务部门对增长数据失去掌控力。当地推团队或分销代理铺开市场时,他们最关心的就是“谁邀请了谁”。如果依赖传统的明文邀请码,用户极易因为体验繁琐而放弃填写,或者在多层跳转中发生操作失误。为了准确衡量全链路的效果并实施精准的绩效核查,企业必须借助技术手段实现破局。通过引入 Xinstall 渠道统计 的底层能力,可以建立起一套无需用户主动干预的自动化参数透传机制。这不仅是用户体验的升级,更是对抗流量损耗、保障商业结算逻辑不被物理断层摧毁的核心风控手段。底层原理与数据管线拆解Xinstall 免填邀请码怎么实现的端云特征采集机制在深入解析 Xinstall 免填邀请码怎么实现的技术链路时,入口触发阶段的端云特征采集机制是整条数据管线的起点。当用户在 Web 前端点击裂变短链或下载按钮时,系统会瞬间激活内置的高精度环境探针。这个探针能够在毫秒级的时间内,合法合规地提取当前访问设备的公开弱特征组合,这其中包括但不限于用户的出口 IP 地址、浏览器 User-Agent 字符串、操作系统大版本号以及设备的屏幕物理分辨率等。这些瞬时采集的环境快照,会与业务层挂载的 Query 参数(例如推广员 ID、活动批次、渠道暗号)进行高强度的哈希打包与加密。随后,这枚加密包裹会通过安全信道上报至云端服务器,并在内存数据库中生成一个具备短暂生命周期的待匹配队列快照,静静等待着客户端的唤醒。Xinstall 免填邀请码怎么实现的设备指纹与模糊匹配逻辑当用户跨越应用商店黑盒完成物理安装,并首次在主屏幕点击 App 图标发起冷启动时,Xinstall 免填邀请码怎么实现的第二阶段——设备指纹与模糊匹配逻辑便正式接管战场。在客户端 SDK 初始化的极早期阶段,引擎会迅速扫描当前运行时的物理环境,重新提取一份客户端视角的特征集,并立即向云端发起验证请求。云端引擎接收到请求后,会利用贝叶斯概率模糊匹配算法,在暂存的快照池中寻找重合度最高的匹配项。在高并发环境下,尤其是企业局域网或校园网这种共用单一出口 IP 的场景,单纯的 IP 匹配会引发极高的哈希碰撞率。为此,系统会引入极其严苛的时间窗口变量(例如结合点击到激活的合理间隔流逝),辅以多维度的设备弱特征进行联合交叉核查,从而在噪音数据中精准锁定唯一对应的参数包裹。工程团队需要前往 Xinstall 下载中心 获取并部署最新版本的 SDK 组件,以确保这套匹配算法能在各类异构终端上稳定运行。Xinstall 免填邀请码怎么实现的剪贴板辅助与精度提升机制然而,任何纯概率型的模糊匹配都存在理论上的极限盲区。为了向 100% 的强匹配精度逼近,Xinstall 免填邀请码怎么实现还巧妙地部署了剪贴板辅助与精度提升机制作为容错降级方案。当用户在 Web 页面触发下载时,前端探针会隐式地将一段经过高度加密的超短口令写入系统的剪贴板缓存中。随后在客户端冷启动时,SDK 会通过静默读取机制捕获这段密文,并与云端快照进行绝对精准的双向核对。必须强调的是,随着最新的 iOS 16+ 及 Android 13+ 系统对隐私权限的急剧收紧,传统暴力的剪贴板读取会频繁触发系统级的高危隐私告警。因此,现代架构必须采用合法合规的临时置换策略与意图判断过滤,在不引起用户恐慌及操作系统拦截的前提下,优雅地完成这致命一击的数据回收。指标体系与技术评估框架要确保参数透传管线的绝对健康,不能仅仅满足于“偶尔能通”,必须构建一套极具压迫感的技术评估与监控体系。这套体系的核心量化指标应当包括参数上报成功率、云端快照命中率、指纹匹配容错率、剪贴板读取拦截率以及最终的归因回挂有效率。只有将这些硬性数据置于统一的监控矩阵下,架构团队才能精准感知流量是在 Web 探针层未能成功快照,还是在端侧初始化时遭遇了系统底层拦截,亦或是时间窗口配置不当导致了过期清理。评估维度方案A:传统明文剪贴板口令方案B:单一系统级 Referrer 方案方案C:Xinstall 组合参数透传架构用户交互摩擦极高(需用户手动复制并触发弹窗)低(用户几乎无感知)极低(全程无弹窗无感动态还原)环境兼容能力极易触发最新 OS 隐私告警遭封杀仅限特定应用商店环境,国内大面积失效统合环境指纹、机制补全与容错策略通吃数据防篡改能力极差,口令极易被恶意劫持或覆盖中等,高度依赖分发渠道不被流量劫持极强,端云加密快照防刷防恶意篡改校验排障效率与业务价值体验断层严重,漏斗流失率居高不下覆盖范围有限,难以支撑全渠道全量统计彻底突破黑盒,支撑高并发精准裂变结算技术诊断案例模块在近期执行的一场现象级排障实战中,我们遭遇了底层架构与现实物理环境激烈冲突的严峻挑战。某头部金融类 App 上线了年度最大规模的地推裂变活动,业务大盘显示下载量与激活量呈指数级激增,但后台核心的“免填邀请码”参数解析命中率却不可思议地暴跌至 40% 以下。这一灾难性的异常导致大量一线地推人员的绩效无法归因结算,投诉工单瞬间挤爆了运营系统。对于这种牵涉庞大线下资源的业务,推荐架构团队提前引入 Xinstall 渠道代理 的参数隔离管理体系,以避免在危机爆发时各级分销数据彻底沦为乱码。面对高压,底层架构团队立即启动了全管线的物理对账。通过深度勘测,我们锁定了两个致命的物理约束条件。首先,该金融 App 的核心包体体积高达 120MB,而在下沉市场复杂的 4G 甚至更差的网络环境中,用户从点击下载按钮到完成底层磁盘物理安装的真实耗时,动辄超过 5 分钟,这直接击穿了服务端预设的快照存活时间窗口,导致大量合法请求被云端作为过期死信强制清理。其次,地推场景具有极端的聚集性,数百名用户在同一家商场的公共 Wi-Fi 网络下集中下载激活。这种统一的出口 IP 与高度一致的机型分布,导致服务端的弱特征指纹队列发生了史无前例的数据哈希碰撞,云端引擎根本无法从完全一致的特征中区分出具体的物理设备。技术调优必须如外科手术般精准且致命。架构侧立即重构了匹配引擎的算法权重,大幅收紧了 IP 指纹的置信度,转而提升操作系统微小版本及屏幕硬件特征的核查比重。同时,强制将匹配时间窗口的生命周期阈值延长至 15 分钟,以应对下沉市场的物理下载瓶颈。在此基础上,团队紧急下发了热更新指令,启用了极度轻量化的剪贴板加密短码作为高优辅助探针。针对趁乱涌入的专业黑产刷单设备,全面开启了基于精准时间戳与异常设备指纹的联合反作弊风控拦截墙。复盘结果宣告了这场底层保卫战的彻底胜利。经过连夜的管线重构与阈值调优,在同 IP 极端并发场景下的参数透传准确率从崩溃边缘的 38.6% 奇迹般地跃升至 97.2%。这套重构后的组合架构不仅有效挽回了下沉市场的巨量裂变流量,更通过无懈可击的数据闭环,稳固了涉及数千万资金的底层结算体系。这次实战深刻表明,Xinstall 免填邀请码怎么实现 绝不是一段简单的 API 调用,而是一场与复杂物理网络和底层系统沙盒持续博弈的技术战争。常见问题与参考资料为什么在同一个办公网络或公共 Wi-Fi 局域网下,多台设备同时进行下载激活会发生归因串号现象?这正是 Xinstall 免填邀请码怎么实现 在高并发场景下的核心难点。由于局域网内的所有设备对外暴露的公网出口 IP 完全一致,如果恰好存在多台同品牌同型号的手机在同一极短时间窗口内点击了不同的邀请链接,云端的弱特征采集池就会出现高度相似的记录。要彻底消除这一哈希碰撞,必须通过缩短快照存活期、引入更深度的硬件指纹校验,并强制开启剪贴板密文匹配机制作为高优先级核查手段。很多开发者极度担忧,参数透传机制在 iOS 16+ 及 Android 13 甚至更高级别的隐私新规下是否会面临全面失效?必须明确指出,如果依然依赖粗暴明文拷贝剪贴板的传统方案,必然会被操作系统直接封杀并向用户抛出红色高危告警。然而,现代的传参架构已经全面转向了“端云动态快照+隐式合规降级”的混合机制,它大幅降低了对单一剪贴板的高频依赖。为了确保这套逻辑时刻符合各大应用商店最新的安全合规审查要求,工程团队务必熟读 Xinstall 文档中心 中的设备特征采集规范,确保每一个探针请求都在授权沙盒内执行。客户端 SDK 的初始化时机为何会直接决定参数解析的生死?如果在应用冷启动时,开发者将 SDK 的实例化逻辑挂载到了极其靠后的业务生命周期(例如等待闪屏广告结束或进入主框架后再初始化),此时极有可能因为操作系统底层的内存回收机制,导致原本可以存活的进程特征遭到破坏,使得参数漏读率大幅飙升。正确的做法是强行将归因解析进程提权,挂载于 application 实例的最前端优先拉起。无论是面临海量裂变拉新的流量洪峰,还是应对黑产团队的恶意参数篡改刷单,企业都必须建立起足够强大的底层自信。通过研读 Xinstall 关于我们 页面所展示的底层数据架构能力与研发历程,架构师能够更深刻地理解这套免填邀请码系统在应对极端并发时的强大容灾底座。只有彻底吃透这些深层机制,Xinstall 免填邀请码怎么实现 才能真正在实战中做到无感、精准、坚不可摧。
 9
9
Xinstall 跳转失败怎么排查?在移动增长和 App 开发领域,行业里越来越把 Xinstall 跳转失败怎么排查视为重塑跨端流量漏斗、保障数据归因闭环的生命线任务。一条精心配置的链接,在微信内置浏览器、Safari、Chrome 或各类 Android 厂商自带的 WebView 中,其唤起行为和拦截策略可能完全不同。这就导致了所谓的“跳转失败”,往往并不是单一的服务器宕机或链接拼写错误,而是深层的环境兼容性与系统权限博弈。在这个极度复杂的异构网络沙盒中,企业可以通过 Xinstall 官网 了解完整的全链路流转架构,但这依然需要开发者亲自深入到底层的协议交互与唤起管线中去,因为任何一个配置断层,都会让投放端的数据变成一座无法追溯的孤岛。物理断层与行业痛点在全渠道运营体系中,物理断层是所有归因数据失真的源头。企业的研发与市场团队往往各自为战,前端配置的各种营销短链、分发平台生成的落地页以及运营发送的短信唤起链接,本质上运行在标准完全不同的容器里。当用户在各类碎片化入口发起点击时,系统在瞬间需要处理域名解析、证书比对、意图分发以及跨端参数继承等一系列极为复杂的逻辑动作。如果这一系列动作缺少全局的技术治理规范,断层便会接踵而至,导致巨额的推广预算换来的只有“点击量”而没有真实的客户端唤起。面对这种深度的系统割裂,我们需要清晰的渠道指标衡量工具。通过参考 Xinstall 渠道统计 的能力说明,可以发现稳定统计链路的前提,是流量绝对不能在第一跳的入口层就发生物理折损。更为严峻的行业痛点在于,当唤起不生效时,传统的排障手段显得极其苍白。开发人员往往只能在控制台查看到冷冰冰的访问日志,却无法透视这条流量到底是被操作系统的底层安全策略无情拦截,还是在某个不起眼的中间节点被强行剥离了关键参数,这种黑盒状态直接摧毁了后续所有的归因可信度。底层原理与数据管线拆解Xinstall 跳转失败怎么排查之入口拦截机制在深度解析 Xinstall 跳转失败怎么排查的管线时,首先必须直面点击触发后的入口拦截机制。内链、短链、深度链接以及传统的协议调度,在底层的分发逻辑上有着本质的区别。当用户在社交软件生态中点击链接时,由于平台存在严格的白名单限制,常规的唤起指令通常会被直接丢弃,导致用户只能看到一个毫无反应的页面。此外,部分系统浏览器存在首次跳转取消拦截的默认机制,一旦用户误点取消,后续所有相同动作都会被静默扼杀。(具体代码实现逻辑见文末部分 B)Xinstall 跳转失败怎么排查之系统唤起断层当流量突破了前端容器的束缚后,Xinstall 跳转失败怎么排查的重心便转移到了系统级别的唤起断层上。在 iOS 生态中,通用链接的验证逻辑极其苛刻,开发者必须在服务器特定目录下部署合规的校验文件。任何配置的细微偏差都会导致彻底的阻断,此时开发者必须严格比对 Xinstall 文档中心 里的集成规范与校验说明,确保服务器响应头与 JSON 文件格式的一字不差。而在 Android 端,安全机制依赖于数字签名比对,一旦指纹不匹配或在深度定制系统中遭到魔改,同样会导致原生唤起彻底失效。Xinstall 跳转失败怎么排查之参数传递与恢复断点除了直观的拉起阻碍,Xinstall 跳转失败怎么排查还必须涵盖唤起成功但参数丢失的隐蔽故障。在复杂的业务流转中,一条携带丰富归因指标的链接往往要经历多次重定向分发。每一次状态码转换都存在巨大的参数吞噬风险,特别是在前端路由守卫逻辑设计不当时,极易在视图挂载前将来源信息强行抹除。为了避免系统级漏洞,保持最新的通信组件尤为关键,工程团队应当定期前往 Xinstall 下载中心 获取并部署最新版本的 SDK,从而对抗底层引擎隐私策略变更导致的首开匹配失效。指标体系与技术评估框架要建立长效且极具压迫感的技术监控机制,不能仅仅依靠测试人员的手动点按,必须构建一套包含跳转尝试率、系统原生拉起率、参数解析留存率以及延迟匹配成功率的量化网络。通过这套严密的评估矩阵,我们能够精准核查排障管线中的各个盲区,迅速将底层故障牢牢锁定在特定的入口拦截或是校验解析节点上。评估维度方案A:单点页面状态测试方案B:仅依赖系统级唤起统计方案C:Xinstall 全链路诊断体系故障定位粒度仅确认网页可否访问仅能感知是否进入 App精确定位拦截、唤起或参数丢失节点跨端一致性评估忽略平台底层差异难以排查不同浏览器拦截策略统合各大社交容器及浏览器底层机制链路恢复完整度无法验证参数透传状态难以排查参数截断问题贯穿拉起传参、安装恢复及归因回挂全周期排障效率与业务价值提供信息零散且碎片化存在数据断层排障成本极高形成标准化排障路径直接驱动运营优化技术诊断案例模块在近期的某次大规模全渠道矩阵投放中,我们遭遇了一个极为致命的异常现象。多个核心渠道反馈,其投放管线中存在海量“链接能点开但客户端毫无反应”的情况。更严峻的是,部分用户即便成功激活了目标客户端,其首屏渲染后却呈现一片空白视图,核心来源的归因编码已被彻底清空,直接导致当期巨额推广预算面临无法结算归属的危机。这种现象在多层级分发中尤为常见,尤其是在涉及外部合作的场景下,统一配置标准显得极为迫切,团队可以引入 Xinstall 渠道代理 的标准化管理体系,从源头杜绝参数被代理商的中间页强行剥离。针对这一突发灾难,架构团队立即介入并展开了毫秒级的物理对账。通过网关抓包与链路时间戳的交叉核验,我们锁定了多处违背现实物理约束的深层断点。首先是真实网络的物理限制:对于一个体积高达 100MB 的重度应用包体,在标准的 5G 网络峰值环境下,用户从触发下载指令到磁盘完成物理写入,不可避免地存在 10 到 15 秒的绝对延时。在这个合理耗时后,由于 iOS 端通用链接配置文件违反了最新内核的跨域规范,系统底层引擎未能抢占到系统内存片区,导致深度拦截意图被操作系统内核作为过期进程直接回收,从而让参数恢复过程彻底断裂。进入深度技术调优阶段,我们采取了极具侵入性的手术式修复。架构侧立刻重构了集群的跨域路由表,实现 API 与短链解析服务的物理隔离。同时运用强类型语法约束器,肃清了底层验证配置中潜藏的各类非标中文字符。针对封闭容器的生态壁垒,我们紧急部署了极度轻量化的中转承接集群,智能判别宿主环境并给与精准的内核跳转引导。对于客户端冷启动瓶颈,重写了启动生命周期,强行将归因解析进程提权至 UI 主线程挂载之前优先执行。最终的复盘结果证明了体系化治理的绝对威力。经过这一轮底层重构,全网系统级原生唤起率强劲飙升至 92.5%,由于非法重定向引发的参数损耗被压制在极低水平。基于精确匹配的数据漏斗模型显示,整体链路的有效触达转化率史无前例地增加了 18.4%。这次战役不仅填补了巨额的数据黑洞,更确立了一套不可动摇的跨端排障工业标准。常见问题与参考资料为什么 Safari 能跳但特定社交软件内却毫无反应?因为两者的底层内核权限与商业生态防御策略截然不同。系统原生浏览器作为最高权限的载体,能够无缝调用底层的调度系统进行跨应用通信。而封闭的社交容器则运行在沙盒之中,为了遏制恶意流量倾销,其内核防火墙会默认阻断大部分外部协议解析。这就要求前端架构必须配备完善的中继过滤层与引导逻辑,才能完成流量的合规剥离与流转。通用链接配置文件校验总是失败该怎么处理?首要动作是启用高级网络探针,核查宿主服务器的网络层是否具备极其纯净的传输信道。必须确保校验文件不仅严格存放于合规目录之下,其响应头标更要被强制锁定为标准格式输出,绝不能带有任何冗余的字符编码干扰。很多时候,正是由于开发者在编辑器中误触输入了全角标点,导致整个解析引擎全盘崩溃。如何科学地区分是系统机制拦截还是实例化配置错误?剥离迷雾的核心手段是观察无污染环境下的第一跳物理表现。如果剥离掉所有前端业务代码,将核心触发锚点直接输入至极为干净的原生系统浏览器中,依然无法撕开客户端的入口,这无可辩驳地指向了客户端工程的静态声明文件配置存在硬伤。反之,如果在纯净环境下表现优异,但在复杂链路中抛出异常,则必须对沿途的网关路由与状态码重写机制进行彻查。很多开发者不清楚自身的系统架构是否足以支撑庞大的高并发唤起与复杂归因排障。除了深入研究技术细节,了解服务商的底层实力也同样重要,通过查阅 Xinstall 关于我们 的企业技术背景,团队能够更好地评估该技术底座在处理海量并发请求时的容灾能力。只有吃透这些内核知识,Xinstall 跳转失败怎么排查 才能从一门玄学升华为无坚不摧的工程铁律。
9
极氪全新车型今日上市?这一消息已在今天下午通过极氪官方及各大汽车媒体正式揭晓。令人意外的是,作为一款定位在 50 万级别的高端旗舰 SUV,极氪 9X 五座版彻底摒弃了传统车企繁复且冗长的线下发布会形式,仅凭一段简洁的预告便直接公布了限时售价与配置,这种“化繁为简”的低调作风不仅没有削弱其热度,相关推文阅读量反而轻松突破了 10 万+。从“六座销冠”到“大五座标杆”,极氪 9X 凭借 1400TOPS 算力的双 NVIDIA DRIVE Thor-U 芯片、16 英寸中控双联屏以及全系标配的“超级 EVA 智能体”,正在重构未来移动出行的豪华标准。然而,当这些具备强大算力和交互维度的智能汽车加速从单纯的交通工具演变为拥有独立数字生态的“第三空间”时,一个新的巨大挑战也正摆在移动应用开发者的面前:当用户的核心交互场景开始在手机屏幕与车机大屏之间频繁切换时,我们该如何构建起一条跨越硬件壁垒的数据通道,确保应用体验与流量转化在跨屏跳转时不断流?“不开发布会”背后的产品底气与座舱重构在当前国内汽车市场“发布会内卷”日益严重的当下,一场新品发布往往伴随着几个小时的 PPT 宣讲、铺天盖地的技术名词轰炸以及创始人充满激情的演讲。然而,极氪 9X 五座版却反其道而行之,选择了直接面向市场交付产品。这种看似低调的决策,实则是建立在强大的产品力与前期六座版车型所积累的市场统治力之上。根据南方都市报及多家垂直媒体的报道,极氪 9X 已经在今年上半年成功夺得 50 万以上全品类销冠,并连续 7 个月霸榜该级别大型 SUV 口碑榜,其高达 80% 的购车群体由 BBA、保时捷等传统豪华品牌的换购用户转化而来。这一系列傲人的数据,赋予了极氪 9X 跳过繁杂仪式,直接与消费者进行价值对话的底气。此次上市的极氪 9X 五座版,共推出了 Ultra 版、Hyper 版、曜黑版三个配置梯度。如果说六座版解决的是大家庭出行的“均等化舒适”,那么五座版则是对空间奢享与跨端座舱体验的一次极限压榨。在砍掉第三排座椅后,工程师将二排的乘坐体验推向了极致:在六座版后置位置的基础上再延伸 76mm,两段行程累计后移高达 230mm,使得二排腿部空间达到了惊人的 1.4 米,这一数据甚至超越了市面上主流的豪华 MPV。配合双零重力座椅、双伊姆斯躺椅模式以及中央豪华电动扶手内嵌的 6.3 英寸 OLED 妙控屏,新车为乘客打造了一个近乎完美的移动头等舱。更为核心的变化发生在看不见的数字底座上。极氪 9X 五座版全系标配了 16 英寸的 3.5K OLED 中控副驾双联屏,并搭配 47 英寸的 AR-HUD 抬头显示。特别是在中控区域那块被车友戏称为“科技图腾”的 17 英寸飞翼式滑移屏,不仅具备 440mm 的滑移行程,更深度集成了基于超级 EVA 智能体的多端交互能力。这意味着,车内的每一块屏幕不再是信息孤岛,而是能够通过智能域控系统实现音频、视频、导航信息甚至车载应用流转的互联终端。车机互联大潮下,被割裂的跨端应用生态极氪 9X 在座舱数字化和屏幕矩阵上的大手笔投入,只是当下整个新能源汽车行业“软件定义汽车”狂飙突进的一个缩影。从理想的“五屏联动”,到华为鸿蒙座舱的“手机与车机无缝协同”,汽车正在以肉眼可见的速度演变为人类生活中最大的智能移动终端。对于广大移动端 App 开发者和互联网内容平台来说,这绝对是一场不容错过的生态盛宴。过去的移动互联网战场主要局限在 6 英寸的手机屏幕上,而现在,动辄 15 英寸以上的车机大屏、AR-HUD 甚至二排的独立娱乐屏,为音视频应用、播客电台、地图导航甚至轻量级游戏提供了极其丰富的碎片化消费场景。然而,理想中的“跨端无缝体验”在现实的工程落地中却遭遇了重重阻碍。想象一个极其普遍的使用场景:用户在下班前,用手机上的某款美食点评 App 查好了一家位于郊区的新餐厅,并将详细的餐厅点评页面分享到了微信上。当他走到地库,坐进极氪 9X 那张舒适的零重力座椅时,他希望将这条信息直接同步到车机屏幕上并开启导航。按照正常的设想,用户应该能在车机的微信或投屏功能中点击这个链接,车机端的同款点评 App 瞬间弹起,并精准定位到这家餐厅的页面。但残酷的现实是,由于车机系统(多为深度定制的 Android 或 QNX)与手机系统(iOS 或原生 Android)之间的底层架构壁垒,加之车载应用商店的封闭性,这个跨端传递的过程往往充满断层。用户点击链接后,很可能只是在车机的简易浏览器里打开了一个功能极其残缺的 H5 网页;如果要求用户下载车载版 App,在漫长的下载安装完成后,用户首次打开车机版 App,面对的却是一个要求重新登录的冷冰冰的首页,刚才那家好不容易找好的郊区餐厅页面早就丢失在复杂的跳转流程中了。这种因为物理终端切换而导致的“场景断联”,不仅让用户体验大打折扣,更让许多应用开发商错失了将手机端流量平滑导入车机端的高频转化契机。重塑跨屏基建:用深度链接打通车手互联的“任督二脉”当汽车座舱逐渐成为人们一天中除了办公桌和卧室之外停留时间最长的“第三空间”,跨终端应用接续的能力,将直接决定一款 App 能否在这个新生态中生存下来。要消除上述手机与车机之间的“跳转黑洞”,开发者不能仅仅依赖车企自身的系统级适配(因为不同车企的接口标准千差万别),而是必须在自己应用的底层构建起一套跨越操作系统的全链路参数接力基建。针对这种从手机分享链接到车机应用唤醒的断层痛点,在行业内已经有一套成熟且被广泛验证的技术解法。开发者可以通过接入专业的第三方数据服务商(例如 xinstall)来彻底打通跨端分发的任督二脉。首要解决的便是应用内场景的瞬间直达问题。通过集成先进的 深度链接(DeepLink)能力,当用户在车机端点击一条来自手机端分享的带有特定参数(如特定餐厅 ID、某首正在播放的歌曲进度等)的 URL 链接时,系统能够直接绕过车机浏览器的中间页拦截,毫秒级唤醒已经安装的车载版 App。更重要的是,它能携带那组隐藏的 URI 参数,瞬间将用户传送到指定的活动页面或服务场景。刚才那家需要重新搜索的郊区餐厅,现在只需轻轻一点,就能在车机大屏上完美呈现,并无缝拉起导航。这种极致顺滑的场景还原,正是跨终端体验中最核心的竞争力。而对于那些尚未在车机端安装该应用的新用户来说,情况则更为复杂。车机应用商店的下载安装过程往往比手机更为缓慢,如何在这个过程中保住用户想要查看的核心内容?这便需要借助 智能传参(免填邀请码) 核心技术。当用户在车机端扫码或点击外链触发下载时,云端引擎会瞬时记录下此次触发的渠道属性、内容 ID 等场景参数。即使用户经历了几分钟的车载应用商店下载流程,当车机版 App 首次启动时,底层的 SDK 会立刻向云端请求匹配,并根据找回的参数自动渲染出用户最初想要查看的具体界面,甚至自动同步手机端的账号登录状态(需结合企业自身账号体系)。这套免填验证码、无需繁琐搜索的流转机制,能够极大挽救在跨终端安装漏斗中最容易流失的意向用户。研发团队只需前往 下载中心 获取适配车载安卓架构的 SDK,并对照 集成文档 进行几行代码的配置,即可快速赋予应用这种跨端场景还原的超能力。除了提升用户侧的接续体验,对于应用开发商的商业化团队而言,厘清跨端流量的来源与转化效率同样是重中之重。当一款播客 App 或车载娱乐软件投入大量预算在各类汽车论坛、车友群甚至是车企自有的应用商店里进行分发推广时,由于车机流量的独特性,传统的统计工具往往会将其混淆为无法溯源的“未知流量”。通过部署一套具备高穿透力的 全渠道统计体系,企业可以为不同的车型、不同的车企应用商店甚至是不同的线下车友会活动分配独立的跟踪参数。商业化团队能够在一个统一的可视化后台中,清晰地监控到极氪车主群体与蔚来车主群体在下载激活、次日留存以及应用内付费意愿上的巨大差异。甚至对于那些通过线下 4S 店预装或汽配城刷机渠道进行分发推广的应用来说,借助于严密的 渠道代理归因模块,可以精准评估每一家网点、每一个改装店的真实地推拉新业绩,彻底杜绝虚假设备刷量与渠道结算纠纷。如果您所在的企业也正在探索车载生态的商业化闭环,或许可以通过 关于我们 深入了解更多关于车手互联场景下全链路数据追踪的定制化落地方案。常见问题(FAQ)极氪 9X 五座版的双 NVIDIA DRIVE Thor-U 芯片对车机生态意味着什么?在车载芯片领域,算力就是生态的基础。极氪 9X 五座版 Hyper 级别及以上车型搭载的双 NVIDIA DRIVE Thor-U 芯片,提供了高达 1400TOPS 的恐怖算力。这不仅能够冗余支持 5 颗激光雷达的高阶自动驾驶需求,更意味着其车机系统有能力极其流畅地运行复杂的大型 3D 游戏、进行多路高清视频解码以及支撑本地端的 AI 大模型推理。这将吸引更多原本只在 PC 或高性能手机上的杀手级应用向车载端移植。为什么手机和车机之间的应用跳转体验往往很割裂?首先是系统架构壁垒。手机端目前主要是 iOS 与 Android,而车机端虽然大多基于 Android 深度魔改,但往往剥离了标准的 Google 框架或原生服务,导致常规的跳转协议不兼容。其次是车企的生态封闭性考量,为了安全和商业利益,很多车企限制了第三方应用间的互相唤醒和深层调用权限。最后是应用开发商本身缺乏跨终端传参的工程基建,无法在不同系统的设备间完成用户场景数据的无损交接。什么是车机场景下的深度链接(DeepLink)?在车机端,深度链接技术允许一条特定的链接在被点击后,直接唤醒车内已经安装的对应应用,并且直达该应用内部的某个具体功能页面(例如直接跳转到某部电影的第 15 分钟播放页),而不是仅仅打开应用的首屏。这是实现手机端浏览进度与车机端无缝接续(即所谓的“上车就看”)的最关键底层技术。开发车载版应用,在推广追踪上和手机版有什么不同?车载应用的推广环境更为复杂封闭。它较少依赖于微信外链或网页下载,更多是通过车企内置的独立应用市场预装、OTA 升级推送或是特定车主群的口碑裂变来完成分发。这就要求归因工具必须具备更强的环境适配性和设备指纹识别能力,能够在没有传统手机 IMEI 或严苛隐私政策限制的车机硬件上,依然准确完成不同渠道来源的流量防作弊清洗与转化追踪。行业动态观察回顾汽车工业的百年发展史,驱动行业变革的核心力量已经从早期的内燃机马力、底盘悬挂调校,全面转移到了由芯片算力、屏幕矩阵与 AI 大模型共同构建的数字座舱之上。此次极氪 9X 五座版以“不开发布会”的自信姿态入局,用重构的奢享空间和拉满的算力配置,再次向我们宣告:高端汽车正在加速演变为一个运行在四个轮子上的超级移动终端。当车企在硬件配置和空间布局上卷到极致之后,下一阶段的核心战场必然是应用生态的繁荣度与跨终端体验的无缝感。在用户的一天中,手机与车机的交集变得前所未有的紧密:在手机上规划好路线、买好电影票、听了一半的播客,都期望在拉开车门坐进车内的一瞬间,能够在大屏上继续行云流水地展开。这种从“孤立使用”到“接力使用”的交互习惯变迁,对所有试图在出行生态中分一杯羹的互联网应用开发者提出了严峻的考验。从更广阔的商业视角来看,多终端智能互联时代的红利才刚刚开启。面对极其复杂且割裂的各种底层操作系统和厂商定制协议,应用开发者必须摒弃过去那种依赖平台施舍接口的被动心态。在这个由算力和屏幕主导的新纪元中,只有积极拥抱并提前部署诸如深度链接、智能传参和全渠道跨端归因等底层基建技术,确保自己的应用能够在跨越物理硬件时实现用户体验与数据流转的“零损耗”,才能在这场波澜壮阔的车机应用大爆发中,真正将高净值的出行流量沉淀为切实的商业增长。这也正是极氪 9X 五座版奢华座舱背后,留给整个移动开发生态最深刻的底层启示。
8
苹果全新系统正式发布?这一消息已在今天凌晨由苹果官方通过正式渠道确认并面向全球用户全网推送。历经长达两个月的漫长测试与打磨,系统版本号为 23G71 的 iOS 26.6 正式版(与上周的 RC 版完全一致)如约而至。本次更新虽然在系统表面上并未带来任何令人眼花缭乱的全新交互功能,但其代码深处却暗藏着修复高达 87 个底层安全漏洞的雷霆手段,同时还进行了大量为接下来 iOS 27 全新 AI 系统铺路的底层索引重构。然而,当普通手机用户在社交媒体上欢呼系统动画更加丝滑、电池续航回血、终于可以停留在该版本“养老”的同时,敏锐的移动端产品经理和数据增长负责人们却嗅到了一丝令人不安的气息:随着苹果在 iOS 26.6 中进一步彻底封堵第三方应用对设备指纹与剪贴板数据的读取漏洞,原本就如履薄冰的应用分发、跨端跳转与全链路追踪生态,是否即将在新一轮的隐私收紧中面临彻底断裂的至暗时刻?潜伏在代码深处的暗战:87个致命漏洞的全面清剿在普通用户眼中,一次没有 UI 界面变化和新功能加入的系统更新,往往被视为“挤牙膏”或“修修补补”的无关紧要之举。但对于深谙信息安全与底层架构的技术圈而言,iOS 26.6 堪称苹果在 iOS 26 整个生命周期末期发起的一次最大规模的安全清剿行动。根据苹果官方发布的详尽安全文档显示,iOS / iPadOS 26.6 本次共计修复了 78 项底层风险条目,对应着惊人的 87 个独立 CVE(通用漏洞披露)安全漏洞。这些漏洞犹如隐藏在精密大厦基石中的白蚁,广泛覆盖了系统内核(Kernel)、沙箱(Sandbox)、相册库、无线通信模块、苹果地图乃至 Game Center 等几乎全部的核心系统模块。更令人触目惊心的是这 87 个漏洞的危险分布评级。其中,高达 19 项被判定为极高危的内核级漏洞。在现代操作系统的架构设计中,内核是掌握设备生杀大权的“最高指挥官”。一旦黑客或恶意越权程序成功利用这些内核漏洞,便能在用户毫无察觉的情况下,实现对系统底层内存的任意越权读写,甚至能够在后台静默状态下强行终止正在运行的安全防护进程。这意味着,攻击者可以轻易绕过锁屏密码,获取最高权限。除了内核漏洞,文档还披露了 9 个 Model I/O 漏洞、8 个 WebKit(Safari 浏览器的核心渲染引擎)漏洞以及 6 个 ImageIO 漏洞。WebKit 漏洞的修复尤为关键,因为这是过去几年中“零点击攻击(Zero-click exploit)”最常利用的突破口。用户甚至不需要点击任何恶意链接,仅仅是访问一个植入了恶意代码的网页,或是接收到一条含有特制恶意图片的短信,ImageIO 和 WebKit 的漏洞解析机制就会触发缓冲区溢出,从而让恶意程序瞬间接管设备。苹果在 iOS 26.6 中对这些渲染引擎进行的严密打补丁行为,彻底切断了这条长期困扰高级安全人员的攻击链路。不仅是移动端,同步登场的 macOS 26.6 桌面端系统更是下了一剂猛药,一次性修复了超过 155 个安全漏洞,直接刷新了该分支版本系统历史上修复漏洞数量的最高纪录。配合针对更老旧设备的 macOS 15.7.8 和 14.8.8(共修复 138 个安全漏洞),苹果向外界展示了其在维护闭环生态安全时,绝不留任何死角的强硬姿态。隐私防线的终极加固:从剪贴板封堵到 BlastDoor 沙箱隔离如果我们进一步剖析 iOS 26.6 中的安全修复细节,就会发现苹果正在构建一套前所未有的、极其极端的应用隐私隔离围墙。这并非简单的修补,而是对整个系统架构信任机制的一次重塑。首当其冲的,是本次补丁彻底封堵了此前在开发者圈内引起轩然大波的“iPhone 镜像投屏隐私泄露漏洞”。随着多屏协同技术的普及,投屏协议中的数据明文传输一直是个隐患,此次修复确保了设备在进行流媒体投射时,敏感界面数据不会被抓包工具截获。更让第三方应用开发者感到震撼的,是 iOS 26.6 对“第三方应用非法读取用户设备指纹、通讯录信息以及剪贴板数据”相关风险的彻底绞杀。在过去的很长一段时间里,部分游走在灰色地带的第三方 App,为了实现精准的广告归因、用户画像描绘或是跨应用的数据传递,会利用系统开放的剪贴板通道,或者搜集屏幕分辨率、传感器特征、陀螺仪微小偏差等硬件信息来拼凑出一个独一无二的“设备指纹”。而在升级到 26.6 之后,苹果从底层 API 阻断了这种拼凑行为,任何试图绕过用户显式授权而静默读取剪贴板或硬件特征的指令,都将被系统内核直接拦截并返回空值。此外,苹果在本次更新中,为“苹果地图”新增了极其严格的独立隔离沙箱防护架构。这一设计的灵感直接来源于此前为 iMessage(信息 App)立下汗马功劳的 BlastDoor 安全机制。什么是 BlastDoor?这可以被理解为一个绝对密封的“拆弹防爆桶”。在过去,当系统接收到外界发来的复杂数据(如带有定位信息的地图链接、富文本消息)时,会直接交由主系统的解析器进行处理,一旦数据中混入恶意代码,主系统就会立刻感染。而在引入隔离沙箱后,所有来自外部的、不可信的复杂数据,都会首先被丢进这个密闭的虚拟“防爆桶”中进行解析、渲染和验证。即使数据包像炸弹一样发生了恶意代码的爆炸,其破坏力也仅仅被局限在这个沙箱内部,根本无法触及甚至污染到手机的操作内核或整机的文件系统。这种效仿 BlastDoor 的机制被普及到更多自带应用中,从根本上降低了恶意文件入侵整机的概率。潜伏在暗处的算力前置:为什么现在就要为 iOS 27 的“聚焦索引”铺路?细心的技术极客在挖掘 iOS 26.6 的更新日志时发现了一个非常不寻常的描述:“优化了‘聚焦(Spotlight)’索引,为 iOS 27 做好准备。”通常来说,大版本末期的更新只负责修补旧有框架的 Bug,极少会牵扯到下一代操作系统的核心机制。为何苹果要在 iOS 26.6 中大费周章地去动“索引”这块硬骨头?要回答这个问题,我们必须将目光投向即将于今年 9 月份秋季发布会上正式亮相的 iOS 27,以及那个万众瞩目的焦点——全面升级的 AI Siri 与 Apple Intelligence(苹果智能)。在过去的传统操作系统中,Spotlight 聚焦搜索仅仅是一个通过文件名或应用名进行简单匹配的检索工具。但随着大语言模型(LLM)被深度植入 iOS 27 的底层系统,未来的 Siri 将不再是一个只会定闹钟和查天气的语音助手。它将能够理解极其复杂的跨应用自然语言指令。例如,用户可以说:“帮我找出上周二张三在微信里发给我的那份关于市场调研的 PDF,并提取出里面的核心数据通过邮件发给李四。”要实现这种近乎科幻的跨应用、跨语境的“秒级检索与执行”,系统绝不能在用户提问的瞬间才开始去翻找文件。它必须依赖一个极其庞大、深入到每一个 App 数据库和文本记录的“全局倒排索引”。系统需要提前把你的每一张照片内容(通过图像识别提取的文字)、每一封邮件、每一条聊天记录,进行语义化的切词和特征向量化处理,建立一个极其庞杂的数据库。然而,重建这样一个达到 AI 认知级别的全局索引,对手机算力和电池续航的消耗是极其恐怖的。此前,不少通过开发者通道提前尝鲜 iOS 27 Beta 测试版的用户发现,在升级后的头几天里,手机出现了严重的异常发热、掉电如流水,甚至系统卡顿的现象。其罪魁祸首,正是系统在后台疯狂调用神经网络引擎(Neural Engine)进行长达数天甚至一周的索引重建工作。苹果的软件工程团队显然意识到了如果将这一过程留到 9 月份让亿万用户同时体验,将会引发一场巨大的公关灾难。因此,他们极其高明地采取了“算力前置分摊”的策略。通过 iOS 26.6 的更新,苹果利用用户每晚插着充电器睡眠的空闲时间,像蚂蚁搬家一样,悄无声息地在旧系统环境下提前完成了未来 AI 系统所需的部分基础索引架构搭建和数据预处理。这样一来,等到 9 月份用户大规模升级至 iOS 27 时,最耗时、最繁重的索引苦工早已在 iOS 26.6 阶段完成,用户将享受到无缝衔接且流畅的 AI 升级体验。这看似平淡无奇的一笔,实则展现了苹果在系统迭代工程管理上的顶级智慧。用户视角的狂欢:续航回血、丝滑动画与封神版本的“养老”文化伴随着 iOS 26.6 正式版的推送,各大数码论坛、贴吧和社交媒体上迎来了一场属于普通用户的狂欢。经过无数个数码博主和极客的连夜测试与交叉对比,一个高度一致的共识正在形成:iOS 26.6 绝对是可以作为 iOS 26 时代完美收官的“养老”版本。什么是“养老”?在苹果用户的黑话词典中,当一款旧设备不再适合升级下一代极其吃硬件的新系统,或者当前版本在流畅度、发热控制和电池续航上达到了一个完美的平衡点时,用户就会选择永远停留在该版本,不再进行任何系统更新,陪着这部手机走到寿命的尽头。从海量用户的真实反馈来看,iOS 26.6 完美契合了“养老”的所有严苛指标。与饱受诟病的 iOS 26.5.2 相比,26.6 在底层动画的渲染逻辑上进行了细微但关键的微调,无论是滑屏返回桌面、频繁切换多任务后台,还是快速调出控制中心,都几乎感受不到任何掉帧与粘滞感,交互的丝滑程度令人梦回当年的经典版本。更为重要的是,得益于对后台异常耗电进程(如前文提到的优化索引调度)的修复,大量 iPhone 用户的亮屏使用时间有了肉眼可见的延长。对于铁了心要“养老”的用户来说,苹果官方那没完没了的“红点更新提示”和半夜自动下载安装包的机制无疑是最让人头疼的噩梦。为此,数码圈内一套经典的“描述文件屏蔽大法”再次被广泛传播。具体的操作逻辑非常巧妙:由于苹果的系统更新机制是依据设备配置的描述文件向服务器请求对应版本的更新包,极客们通过在 iPhone 上安装针对 tvOS(苹果电视操作系统)的测试版描述文件,让 iPhone 的更新检测机制产生“身份认知错乱”。手机会跑去苹果的服务器上请求电视系统的更新包,服务器自然会拒绝这种荒谬的请求并返回“系统已是最新版”。根据各大科技门户提供的详细教程,用户只需将特定的屏蔽链接复制至自带的 Safari 浏览器中打开,按照提示下载。随后进入 iPhone 的「设置」,点击页面顶部的「已下载描述文件」,或者深入「设置」—「通用」—「VPN 与设备管理」路径,找到名为「tvOS 26 Beta」的文件并点击右上角的安装,重启手机后,那个烦人的系统更新小红点便会彻底从世界上消失。而根据技术人员的解析,最新版屏蔽描述文件的数字签名失效日期要一直到 2028 年 5 月 25 日,这足以覆盖一部智能手机的完整生命周期。想要后悔的用户,也只需在设置中删除该描述文件即可恢复正常的更新接收通道。隐私铁幕下,移动端开发者如何重塑分发与归因链路?当普通用户在为 iOS 26.6 带来的流畅与安全拍手叫好时,整个移动互联网的数字营销、App 增长黑客以及底层技术开发团队,却正在经历一场凛冬的考验。正如我们在前文所详述的,iOS 26.6 不仅修复了内核漏洞,更对剪贴板读取、设备硬件指纹抓取等灰色通道进行了史无前例的极限封杀。在过去的移动端分发玩法中,当一名地推人员向用户分享一个带有专属邀请码的下载链接,或者当用户在外部信息流广告中点击了一个特定的商品卡片时,很多开发者会通过将长串的渠道参数悄悄复制到系统剪贴板,或者利用设备的屏幕分辨率、IP 地址组合成伪唯一指纹。当用户完成长达几分钟的 App Store 下载并首次打开应用时,系统立刻读取剪贴板或比对设备指纹,从而识别出这个用户到底是从哪个地推人员、哪条广告计划中来的。但在 iOS 26.6 极其严苛的沙箱隔离和剪贴板访问弹窗警告面前,这套曾经运转良好的“民间土法”彻底失灵了。设备指纹失效,意味着花费数百万预算买来的广告流量,在经过应用商店的黑盒后,变成了来源不明的“自然流量”。剪贴板被拦截,意味着用户辛辛苦苦下载完 App,打开后却看不到朋友分享的活动页面,还被要求手动去填写一长串令人烦躁的数字邀请码。这种转化链路的断层和数据归因的瘫痪,是导致当前移动端获客成本指数级飙升、跳出率居高不下的最核心痛点。面对苹果高筑的隐私围墙,与其在漏洞被封杀的边缘反复试探,聪明的企业和开发者更应该借助彻底合规的、更贴近底层的技术基建来重构分发与追踪体系。在这个赛道上,xinstall 等专注于全链路数据方案的技术服务商,给出了一套破局的底层解法。首当其冲的便是对传统繁琐邀请码机制的降维打击。通过接入成熟的 智能传参(免填邀请码) 技术基座,当用户在各类社交平台、外部浏览器点击那条包含着分享者身份、活动渠道编号(ChannelCode)的推广链接时,系统能够通过云端的模糊匹配与高精度概率模型,在不触碰敏感剪贴板、不侵犯苹果隐私政策的前提下,瞬时生成并绑定参数映射。即使用户经历了跳转应用商店、耗时下载等极其复杂的长链路流转,当他们首次启动这款 App 时,底层的解析引擎依然能够准确无误地从云端还原出最初的那组参数。这一无缝衔接的过程,让新用户落地瞬间就能直达被邀请的专属活动页,极大挽救了在转化漏斗最底部流失的高净值人群。为了让研发团队以最低的时间成本应对系统升级带来的变局,开发者可以直接前往 下载中心 获取适配最新苹果生态的完整组件库,并对照结构清晰的 集成文档,在寥寥几行代码的改动下完成系统级接入。不仅是打破物理跳转的隔阂,从宏观的商业操盘视角来看,数据的清晰度直接决定了企业的生死。当流量的源头碎片化为成千上万个微信社群、KOL 短视频评论区以及庞杂的网吧与线下地推大军时,如何精准评估每一条渠道的 ROI(投资回报率)?传统的表层统计工具早已无法穿透苹果的隐私黑盒。这就需要企业全面转向更具深度的 全渠道统计体系。这套体系能够为每一次点击、每一次下载、每一次注册付费进行防作弊清洗与来源追溯,以可视化面板实时呈现。而对于那些拥有复杂裂变体系的游戏公会或下沉市场推广大军,依托于 渠道代理与结算模块,平台可以将巨量的自然流量精准切割并归属到每一个最末端的子代理名下,彻底终结了因数据丢失而导致的渠道结算推诿与坏账乱象。正所谓堵不如疏,与其在 iOS 26.6 的安全漏洞日志中寻找可以苟延残喘的系统后门,不如静下心来去了解真正符合未来大势的基础设施演进。如果您也曾在流量溯源与归因的泥潭中挣扎,或许可以通过 关于我们 深入了解这些从无数次系统迭代的腥风血雨中淬炼出的底层方法论。在技术演进的历史长河中,隐私围墙只会越来越高,而只有掌握了无损数据传递基建的团队,才能在变局中牢牢扼住增长的咽喉。常见问题(FAQ)什么是 iOS 系统中的 BlastDoor 安全机制?BlastDoor 最初是苹果在 iOS 14 时代为 iMessage 专门研发的一种高级系统隔离架构,可以将其理解为一个密闭的“虚拟防爆沙箱”。当系统接收到外部复杂的、未经验证的数据内容时,会在这个独立的沙箱内进行解包和初步渲染。如果内容包中夹带了试图越权的恶意代码并发生“爆炸”,其破坏范围会被死死限制在沙箱内部,无法逃逸并感染系统的核心内核。在 iOS 26.6 中,苹果将这一机制推广到了地图等更多内置应用中,大幅提升了整机的防御纵深。为什么一次常规的 26.6 更新要提前优化 iOS 27 的“聚焦(Spotlight)”索引?即将到来的 iOS 27 将搭载深度的 Apple Intelligence 与全新的大模型版 Siri,这要求手机能够对设备内部的所有照片、文档、应用内数据进行极其深度的语义理解和跨应用检索。构建这种 AI 级别的全局倒排索引需要长时间让 CPU 和神经网络引擎处于满载运转状态,会导致手机严重发热和耗电。苹果在 26.6 中提前在用户闲暇时间静默重构索引,是为了分散算力压力,防止用户在 9 月份统一升级新系统时遭遇断崖式的续航崩溃与大规模卡顿。网上流传的“描述文件屏蔽系统更新”到底是什么原理?它安全吗?屏蔽更新的原理是“偷梁换柱”。系统会定期向苹果服务器请求下载最新的 iOS 固件,极客们通过在 iPhone 上安装原本属于苹果电视机顶盒(tvOS)的 Beta 版测试描述文件,导致 iPhone 的系统更新组件错误地去请求电视系统的更新包。苹果服务器识别到设备不匹配后会拒绝下发任何文件,从而使得手机永远停留在“系统已是最新版”的状态。只要是从正规开发者渠道获取的描述文件,该方法是完全无害且安全的,且不会对手机的其他功能造成任何影响,用户也可以随时删除文件恢复正常的升级通道。行业动态观察跳出纯粹的极客视角来看待这一次的系统迭代,我们会发现 iOS 26.6 的发布绝不只是一次用来“养老”的常规安全补丁推送,它更像是一座承前启后的战略桥梁。向前看,它用创纪录的 87 个漏洞补丁和激进的沙箱防线,为过去那个依靠剪贴板窃取、指纹抓取等灰色手段横行无忌的“移动互联网草莽时代”重重地画上了一个句号;向后看,它用极其隐秘的算力前置和索引重构,为即将席卷全球的端侧大模型与 AI 智能体时代悄然铺平了道路。在操作系统的宏大演进史中,每一次底层的隐私收紧,都会在应用生态的表层掀起一场大洗牌。当粗放式的流量采买模式因为归因断层而难以为继时,精细化的参数流转与全链路的底层追踪必然成为下一代数字营销的核心护城河。对于广大的开发者和企业而言,摒弃技术上的侥幸心理,拥抱合规且高效的第三方归因基建,已是顺应时代洪流的唯一选择。只有在尊重用户隐私边界的前提下重构转化链路,移动生态的参与者们才能在这场由 iOS 26.6 引发的深远变革中,稳固并开拓出属于自己的新版图。
8
腾讯官宣QQ宠物回归?这一消息已在今天由腾讯官方正式确认,并犹如深水炸弹般在各大社交平台和开发者社群中引发了核爆级的持续讨论。作为停运近 8 年的国民级社交 IP,新版 QQ 宠物不再是当年那个依赖固定代码脚本运行的 2D 桌面挂件,而是全面进化为全景 3D 形态,并历史性地深度接入了腾讯自研的混元 Hy3 大模型。从单纯的“打工、洗澡、看病”等被动养成,跃升为支持自定义性格、能够主动识别语境与用户进行长程互动的超级智能体(Agent),它甚至能打破边界,穿梭于手机 QQ 的聊天列表与对话框等多屏场景之中。然而,当这类带有极强传播属性、能够跨越多个数字界面的新型智能体开始在熟人社交网络中裂变发酵时,它也向全行业的应用开发者、产品经理以及数据增长团队抛出了一个隐形却极其致命的业务焦虑:在 AI 智能体主导的下一代碎片化分发浪潮中,我们现有的跨端跳转与归因体系,真的能接住这些随时可能在链路盲区中流失的高净值用户吗?从“赛博电子宠”到“超级智能体”的代际跨越:技术底座的颠覆要深刻理解这次 QQ 宠物回归对整个移动应用分发与智能体行业带来的巨大震动,我们需要先拉长历史视角,回顾一段中国互联网的特殊演进进程。2005 年,QQ 宠物伴随着 PC 互联网的黄金时代诞生,最高峰时曾创下同时在线人数破百万的惊人记录,被誉为无数 80 后、90 后网民的“初代数字资产”。每天挂着 QQ 喂企鹅、让企鹅去工地打工赚取元宝,是那个时代独特的互联网景观。然而,随着移动互联网时代的全面降临,由于底层架构(早年高度依赖 Flash 技术)的落后,加之沉重且缺乏核心移动端场景,QQ 宠物在智能手机的冲击下逐渐被边缘化。在经过多次挣扎与改版后,这款承载了一代人青春的产品最终在 2018 年 9 月正式宣告停运,成为了时代的眼泪。在当年的行业分析看来,QQ 宠物的死亡是由于产品形态无法适应智能手机屏幕的碎片化交互与快节奏的移动端体验。但在 8 年后的今天,生成式 AI(AIGC)与大语言模型技术的爆发式增长,为这类陪伴型数字产品的复活提供了最为完美的底层技术土壤。根据环球网的官方报道及多家主流科技媒体披露的核心信息,此次回归的 QQ 宠物绝不是一次简单的“冷饭热炒”,而是进行了一次从底层骨骼架构到交互灵魂的彻底重构。在视觉呈现上,企鹅全面走向了高精度的 3D 化,毛发渲染、物理光影与肢体动作更加逼真流畅。并且,在经典的“Q 哥哥”、“Q 妹妹”企鹅形象之外,腾讯敏锐地捕捉到了当下年轻人的情绪图腾,引入了“狗狗”与“蒜头鹅”等全新物种,极大地丰富了用户的个性化选择。但视觉的升维仅仅是表象,真正引发行业轰动的质变,在于其内核——腾讯混元 Hy3 大模型的全面接入。过去,电子宠物的底层逻辑是高度僵化的决策树(Decision Tree)和穷举脚本。用户点击“喂食”,系统播放一段固定的进食动画;宠物生病了,用户必须按照固定流程购买特定的虚拟药品。这种“如果 A,就触发 B”的逻辑在长期体验中极易引发用户的疲劳感,因为它的行为边界和交互深度是被程序员提前锁死的,几百次交互后,用户就能完全摸清它的套路。但 Hy3 大模型的引入彻底打破了这一代码边界,让 QQ 宠物拥有了“拟人化的灵魂”。新版宠物支持用户为其预设多元化的性格,例如官方公布的“小太阳”、“粘人精”、“淘气包”、“小戏精”等。这意味着,宠物的每一次回应都带有强烈的随机性、个性化特征以及长程的情绪记忆。它不再被动等待你的指令,而是会根据你在聊天框里的聊天上下文、当前的地理位置天气,甚至你触摸屏幕的力度和位置,主动发起话题或做出差异化的反馈。例如,当你工作到深夜,并在空间发了一条疲惫的动态,你的“粘人精”狗狗可能会主动跳到你的聊天列表顶部,提醒你早点休息,并配上一个贴心的 AI 生成表情;当你遇到挫折吐槽时,你的“小太阳”企鹅会通过语义分析理解你的情绪,生成一段非预设的暖心安慰。这种由大型语言模型(LLM)驱动的生成式交互,标志着 QQ 宠物已经从一个呆板的“桌面玩具”彻底演变成了一个真正意义上的“伴侣型 AI 智能体”。取消死亡机制:重塑现代社交产品的情绪价值与留存逻辑除了接入大模型带来的交互革命,新版 QQ 宠物另一项引发业界广泛探讨的重大改动,是彻底取消了老玩家记忆深刻的“死亡机制”。在过去,如果用户长时间不登录、不喂食或不给生病的宠物治病,宠物会走向真实的“死亡”并被“埋葬”,甚至还需要用户花充值购买“还魂丹”才能复活。这一度是许多用户的童年阴影,也极大地增加了用户的精神内耗。从现代移动产品的增长与生命周期运营(LTV)视角来看,果断取消死亡机制是一个极其高明的留存策略。在如今这个充满内卷和精神压力的存量博弈时代,基于惩罚和焦虑的留存机制只会加速用户的流失。现代年轻用户在打开社交软件时,需要的是轻量级的陪伴、无负担的互动以及随叫随到的情绪价值提取。没有了死亡焦虑,用户的打开动机就从强迫症般的“怕它死”变成了纯粹的“想看它、想和它聊聊”。这是一种从“负反馈驱动”到“正向情绪驱动”的底层商业逻辑转换。与之相匹配的,是腾讯在社交裂变玩法上的重磅加码。根据新浪科技的跟进报道,新版宠物不仅保留了经典的喂食、洗澡、打工等单机养成元素,更推出了“和好友宠物互踩续火花”、“去好友家串门互动”等极其硬核的社交功能。更具有颠覆性的是,3D 萌宠支持多屏在线,它们不仅存在于独立的 App 或小程序界面,还能走进 QQ 的更多底层角落,在好友的聊天列表、对话框等核心社交场景中频繁刷存在感。在微信和 QQ 这样的超级私域生态中,“互踩”和“续火花”这种机制堪称流量引擎的核武器。它巧妙地将人与 AI 之间的单机互动,转化为了人与人之间社交维系的数字筹码。可以预见,在接下来的时间里,无数年轻用户的社交网络中将会充斥着诸如“快来帮我的蒜头鹅洗个澡”、“我的小戏精企鹅跑到你聊天框里了,快给它喂点吃的”这样的分享链接与动态卡片。这种基于情绪价值共振和社交羁绊的裂变分发,其自然转化效率与获客质量,将远远超过传统的买量广告。智能体裂变背后的“跨端流量黑洞”难题QQ 宠物的这套焕新打法,为全行业的移动应用开发者、独立游戏工作室以及 AI 初创团队展示了一个完美的 AI 时代增长范本:用大模型打造具备人设的智能体,用智能体提供差异化的情绪价值,用情绪价值驱动熟人社交网络的自发分享,最终实现极低成本的爆炸式裂变拉新。然而,必须要清醒地认识到,腾讯能够如此丝滑地玩转这套逻辑,是因为他们拥有从底层社交关系链到上层应用展示空间的完整闭环生态。QQ 宠物可以在 QQ 的生态内自由跳转、无缝拉起。但对于广大的独立 App 开发者和第三方平台来说,如果想要在自己的产品中复刻这种“智能体社交裂变”的模式,就会立刻在真实的网络环境中撞上一堵名为“跨端跳转断层”的冰冷高墙。不妨推演一个典型的移动端业务场景:你的团队也紧跟热点,耗资数百万开发了一款具备 AI 宠物互动属性的独立 App。你的核心用户 A 在微信群或微博里分享了一个极具吸引力的动态 H5 卡片(“我的 AI 柴犬刚刚通过大模型学会了写现代诗,点击链接来看看它写了什么”)。群里的潜在新用户 B 看到后非常感兴趣,点击了这个分享链接。按照开发者最理想的剧本,用户 B 应该立刻看到那首诗,并被吸引注册。但现实的链路是无比残酷的:在这个支离破碎的移动互联网生态中,用户 B 无法在微信或微博的内置浏览器里直接体验完整功能。他会被跳转到一个中间的下载落地页,然后被引导点击“下载体验”。接着,他会被踢出社交软件,跳转前往苹果 App Store 或是各大安卓厂商的应用商店进行长达数分钟的下载。几分钟后,当用户 B 终于完成安装并首次打开你的 App 时,致命的问题出现了:他看到的却是一个冷冰冰的新手注册页面,或者是一只完全陌生的初始默认宠物。刚才那只会写诗的柴犬不见了,用户 A 的好友邀请关系也没有被自动绑定,他甚至不知道要去哪里寻找刚才吸引他点击的具体内容。这就是当前 App 增长与分发领域最让人头疼的“流量黑洞”。由于各大操作系统的隐私沙盒机制(特别是苹果极其严格的 ATT 政策)、各类应用商店的封闭护城河,以及系统底层对剪贴板读取的层层封锁,用户在点击外部链接时所携带的“分享者 ID”、“特定宠物编号”、“大模型历史上下文记录”、“活动渠道号”等核心场景参数,在经过应用商店这个黑盒下载流程时,被无情地洗掉和丢失了。用户体验的严重断裂,直接导致了原本极具潜力的社交裂变活动中,有超过 50% 甚至更高比例的潜在高意向转化,在打开 App 的这最后一步彻底流失。辛辛苦苦策划的创意活动和巨额的研发投入,最终沦为一场因底层跳转不畅而导致的空欢喜。填补数据断层:重构全链路归因与参数接力基建当流量获取的成本随着买量红利的消失而水涨船高,当应用生态开始全面向 AI 智能体演进,开发者绝对不能再容忍如此高昂的自然流量折损率。要解决由于智能体跨平台、跨应用流转带来的数据断层痛点,在工程实践层面,企业必须依靠强大的底层技术基石来完成流量链路的重构,确保每一滴流量都能精准落入转化漏斗。面对从社交外链到应用内首次激活这段极易丢失参数的“真空地带”,开发者需要专业的第三方工具来接管数据流转。这就需要利用到智能传参(免填邀请码)这一核心技术体系。它的运作原理非常巧妙:当用户在外部浏览器、短视频评论区或社交软件中点击那条带有特定属性的分享链接时,系统会在云端毫秒级生成一条包含渠道编号、分享者身份、当前 AI 智能体状态等海量信息的临时加密记录。即使用户后续经历了复杂的跳转、甚至长达半小时的应用商店下载过程,当他们完成安装并首次启动 App 时,应用底层的 SDK 会立刻向云端发起比对请求,利用高精度的设备指纹算法精准找回并匹配到这组原始参数。从真实的用户体验角度看,这意味着新用户打开 App 的瞬间,不再需要经历四处寻找活动页面、手动输入繁琐验证码或 6 位数邀请码的折磨。系统能根据找回的参数,自动渲染出分享链接中展示的特定场景(例如直接弹出好友的那只柴犬,并显示它写的那首诗),并自动完成好友关系链的绑定。这种无需手动干预的无缝接续,极大保护了用户的探索欲和好奇心。对于技术团队而言,尽早参考集成文档完成这类免填邀请码的功能落地,是保障大型裂变活动转化率的首要任务。研发团队可以通过下载适配各大平台的底层 SDK,将这种极致的场景还原能力深度嵌入到应用的启动逻辑中。不仅是针对拉新,对于那些手机里已经安装了该 App 的沉默老用户来说,痛点则在于如何绕过层层叠叠的二级菜单,实现流量的一触即达。通过部署深度链接(DeepLink)能力,当老用户点击分享链接时,系统能够直接绕过浏览器的中间页拦截,瞬间唤醒本地应用,并精准定位到某个宠物的具体互动界面。在这个时间就是流量的时代,缩短一秒的跳转路径,减少一次多余的点击,就能挽回百分之十的跳出率。更为宏观的挑战在于流量追踪的颗粒度管理。当这类基于 AI 的营销活动铺天盖地展开时,流量的来源将变得无比碎片化和不可控:可能来自某个长尾 KOL 的公众号推文、可能来自几十个不同的游戏公会微信群,甚至是用户自发的线下二维码扫描。对于商业化和数据增长负责人而言,要回答“到底哪个渠道带来的大额充值用户最多”、“哪些渠道存在大量虚假机器刷量”、“这场裂变活动真实的 ROI 是多少”等关键问题,就必须依赖一套严谨的全渠道统计与方案评估体系。通过为不同的分发触点分配独立的渠道参数,管理平台可以清晰监控每一笔费用的下载转化漏斗、激活留存率与防作弊指标。而对于那些高度依赖下沉市场地推、网吧合作或是公会分发等复杂利益分配网络的应用来说,构建一套层级分明的渠道生态与代理体系追踪模块,能够确保每一个细分子代理商的业绩得到最精准的归因,彻底杜绝流量结算过程中的推诿与糊涂账,让每一分推广预算都花在刀刃上。常见问题(FAQ)为什么大模型的接入能让 QQ 宠物产生如此巨大的体验跃升?过去基于规则树和状态机编写的电子宠物,其交互上限由程序员预先写好的代码库决定,本质上属于“查表式”反馈,一旦用户穷尽了所有选项,就会感到极其无聊。而接入了类似腾讯混元 Hy3 这样具备千亿级参数的大语言模型后,宠物具备了强大的自然语言处理(NLP)能力、长短时上下文记忆能力和跨模态感知能力。它能够理解用户复杂的语境、捕捉细腻的情绪变化,并实时生成非重复的、高度符合其“性格设定”的文本与动作回应。这实现了从“程序响应”到“虚拟生命拟真”的根本性感知跨越,极大提升了用户沉浸感。全面 3D 化对智能体的跨屏社交展示有什么具体意义?3D 渲染不仅大幅提升了视觉精度,更重要的是打破了 2D 贴图的视角限制和场景局限。在多屏在线、聊天框互动等复杂场景中,3D 模型可以根据用户屏幕的尺寸、物理重力感应以及不同的手机系统背景环境,动态调整自身的姿态、光影和互动动作。这种空间感和真实感是 2D 形态无法比拟的,它能让虚拟宠物仿佛真的“站”在你的屏幕之上,极大地增强了智能体的“在场感”和能够跨越虚实边界的情感陪伴价值。取消死亡机制是否会适得其反,降低用户的长期登录粘性?从现代游戏设计和行为经济学的最新研究来看,并不会。早期的死亡机制利用的是用户的“损失厌恶”心理来强制拉动活跃度,但在当下快节奏、高压力的移动互联网环境中,用户对负面情绪反馈的容忍度极低,繁重的惩罚机制往往直接导致卸载流失。取消死亡机制,转而通过正向的社交羁绊(如好友互踩、串门)和 AI 大模型提供的不可预测的情绪价值来吸引用户,反而能建立更加长期、健康且高频的用户留存模型。面对未来越来越多的 AI 智能体产品,中小开发者该如何应对大厂的降维打击?随着底层大厂基础设施的不断开源和完善,AI 模型能力的差距会被逐渐拉平。未来智能体产品的竞争核心将从“谁的模型更聪明”转移到“谁的场景挖掘更深”以及“谁的流量分发效率更高”。中小开发者应当避开大厂锋芒,将精力集中于垂直场景(如心理疗愈、特定圈层社交)的创新,同时必须提前布局底层的全渠道归因、智能传参和深度跳转等基建技术,确保自己在这个去中心化、碎片化的流量时代拥有“精准捕捞”和“无损接住”每一分流量的能力。行业动态观察回顾中国互联网长达二十年的商业变迁史,无论是多年前在 PC 端掀起全民通宵狂欢的“偷菜”游戏,还是微信初创时期引爆整个熟人圈的“打飞机”大战,腾讯每一次现象级社交游戏应用的推出,都在深刻重塑着整个行业的用户交互习惯与商业分发格局。此次 QQ 宠物借助全景 3D 形态与腾讯混元 Hy3 大模型的重磅回归,绝对不应该被仅仅视作一次情怀向的“炒冷饭”或是博眼球的营销动作。这分明是社交巨头在 AI 时代探索“下一代计算平台原生应用超级入口”的关键一步棋。当应用的功能开始被解构,当交互的载体从冷冰冰的折叠菜单与平面的功能按钮,变成了具备独立人格属性、能够穿梭于各类软硬件界面的智能体,信息与流量的流转速度、维度都将发生指数级的跃迁。未来的应用形态可能不再是独立存在的图标,而是由无数个穿插在社交网络中的 Agent 组成。在这个过程中,无论是财大气粗的社交巨头,还是在红海中奋力搏杀的独立开发者团队,都必须重新审视自身底层基础设施的稳健程度。流量的呈现形式可以千变万化,智能体的皮囊也可以日新月异,但流量落地、追踪和转化的商业本质永远不会改变。从更长远的行业周期来看,整个移动应用分发生态的焦点必将从“如何训练一个参数更大、更聪明的 AI Agent”向“如何让这个极其聪明的 Agent 带来的社交流量实现全链路无损落地”发生战略性的转移。各大移动操作系统的隐私合规政策依然在不断缩紧,应用商店固若金汤的护城河也不会在短期内轻易消失。但在充满挑战与割裂的系统生态夹缝中,通过底层的工程技术重构和场景还原能力,稳稳守住每一分来之不易的转化,依然是移动互联网从业者突破重围的唯一正解。这也是在这个大算力与大模型齐飞的激荡时代,关于 QQ宠物 涅槃重生背后,最值得全行业深思与付诸行动的商业命题。
9
腾讯Miora向全球开放?巨头智能体生态加速多端全链路归因。这一重磅消息已在 7 月 22 日由腾讯官方正式宣布:全场景创意智能体妙境 Tencent Design Miora(简称 Miora)国际版全量上线,面向全球用户开放使用。这款在内测期就曾登顶 Product Hunt 日榜第一的超级智能体,不仅仅是一个简单的生图或视频工具,而是一个拥有记忆系统、能够理解复杂需求并自动调度多个底层 Agent 协作的“AI 创意总监”。当腾讯这样的互联网巨头不再局限于单一功能,而是试图用多模态大一统的智能体吃下品牌设计、电商素材、3D 建模等全链条创意需求时,这释放出一个强烈的信号:AI 流量的中心正在向具有复杂调度能力的超级入口转移。但这同时引发了另一个痛点:当创意内容的生成可以一键完成并在全网多端病毒式传播时,这些从微信、海外社交平台等超级入口溢出的流量,在跨越不同平台跳转回原生 App 途中极易折损。谁能在这个碎片化的分发生态里看清真正的用户来源?不止是生图:Miora 为什么被称为“多 Agent 协作体”过去一年,行业里涌现了无数 AI 绘画和视频生成工具,但它们大多遵循着“单次指令 - 单次输出”的流水线模式。Miora 的不同之处在于,它从底层架构上就切断了这种低效的单线操作。根据官方披露的架构逻辑,Miora 基于与腾讯 WorkBuddy 同源的智能体架构打造,采用的是典型的“多 AI Agent 协作模式”。当你输入一句宽泛的需求,比如“帮我设计一套咖啡店的品牌视觉全案”,Miora 会立刻化身一个项目经理。它会在后台自动将任务拆解,分别调度擅长排版的 Agent 生成 Logo 和 UI,调度擅长 3D 建模的 Agent 渲染店面模型,最后在同一个画布内输出一整套风格高度统一的多模态创意资产。更为颠覆的是其内置的“智能体记忆系统”。这不是简单的浏览历史记录,Miora 会在日常使用中悄悄学习你的审美偏好、品牌规范甚至字体习惯。你用得越久,它就越像一个跟你磨合多年的专属设计师。这种对专业门槛的降维打击,直接反映在了用户画像上。腾讯官方数据显示,在 Miora 内测期间,超过一半的用户根本不是专业设计师,而是市场运营、研发人员甚至是电商卖家。他们利用 Miora 预置的丰富 Skills,不仅能一键生成电商素材,还能通过自然语言对生成图片进行框选、局部修改和字体编辑。当非专业人士也能低门槛、高频次地产出具备商业级水准的视觉内容时,AI 创作的产能将被推向一个前所未有的高峰。巨头跨界出海:流量溢出背后的多端分发难题Miora 国际版的上线,尤其是其针对海外创作者的积极布局,表明腾讯的 AI 战略已经从底层的“混元大模型”架构夯实阶段,全面切入到了重度应用场景的全球化收割期。它不仅是一个独立的生产力工具,更可能成为未来挂载于微信、QQ 或其他超级应用中的核心组件。这种超级智能体的爆发,对广大 App 开发者和增长团队来说,是一个极其诱人的巨大流量池。想象一下,成千上万的市场营销人员和出海电商卖家使用 Miora 生成了精美的落地页设计和游戏宣传视频,并随之将产品下载链接分发到 Twitter、TikTok、Facebook 甚至各类社群中。然而,这些携带海量曝光的链接,在实际转化为 App 激活用户时,却往往面临着“死亡跳出率”。一个海外用户在推特上看到 Miora 生成的惊艳游戏 UI,点击链接,被浏览器拦截,再跳转到 App Store/Google Play,最后等待漫长的下载和安装。等他打开 App 时,如果面对的是一个毫无引导的冷启动首页,他有极大的概率会在三秒内流失。同时,面对如此分散的全球化发布渠道,增长团队完全不知道哪些用户来自微信的社群分享,哪些来自推特的 KOL 转发,又有哪些是真实的精准转化。如果数据是瞎的,再怎么借势 AI 的红利也只是赔本赚吆喝。智能传参与全渠道统计:捕捉碎片化流量的核心基建在这个极其复杂的跨端跳转迷宫中,传统的链接埋点和简单的激活统计已经完全不够用了。为了承接住像 Miora 这种能够引发病毒式裂变的智能体流量,开发者必须在底层构建起强悍的 全渠道统计与渠道归因 体系。其核心解法在于 智能传参安装 技术。当运营人员将带有特定业务场景的推广链接投放到全网时,这套技术可以在用户点击的瞬间,将来源渠道、特定的活动 ID 甚至分享者信息等动态参数进行静默抓取和匹配。无论用户后续经历了怎样的浏览器拦截或应用商店流转环节,这根隐形的“参数线”都不会断裂。当用户首次完成安装并打开 App 时,系统会利用底层匹配算法瞬间识别出他之前的点击环境。通过 深度链接(DeepLink) 与场景还原技术,App 能够一键拉起并直接越过繁琐的常规首页和复杂的注册流程(如配合 免填邀请码 能力),将用户直接带到他们最初在推广素材中看到的那个活动页面或商品详情页。这种消除断层感的顺滑体验,是挽救跨端高流失率、提升最终激活转化率的最有效手段。更为重要的是,只有看清流量从哪儿来,才能做好 ROI(投资回报率)的精准衡量。全渠道归因平台不仅能追踪传统的 App 广告投放,还能敏锐地捕捉从各类社交平台、私域社群甚至二维码扫描中溢出的长尾流量。在这波出海与多端分发的浪潮中,精准的归因数据就像是增长团队的雷达,指引着他们将营销预算投入到转化率最高的核心渠道中去。常见问题(FAQ)Miora 与传统的 AI 绘画工具(如 Midjourney)有什么核心区别?传统 AI 生图工具多为单次单模态输出,而 Miora 定位为多模态创意智能体。它可以根据一句复杂需求,自动调度多个擅长不同领域的 Agent(如 3D 渲染、排版、UI),在同一画布内输出一整套包含品牌视觉、视频和 3D 资产的解决方案。此外,它的记忆系统和工作流复用功能,大幅降低了重复操作的门槛。为什么内测期间超过一半的用户都不是专业设计师?Miora 极大降低了创意输出的专业门槛。它内置了丰富的 Skill 生态,用户不需要掌握复杂的软件操作,只需用自然语言进行框选编辑和局部修改即可。这使得市场运营、电商卖家等非设计岗位人员能够独立完成宣传图和商品素材的制作。在 AI 应用出海推广中,为什么精准的渠道归因变得尤为困难?出海推广通常涉及 Facebook、TikTok、Twitter、海外社群等极其复杂的多元化渠道。由于海外各平台的跳转限制以及应用商店生态的差异,传统的表层点击追踪极易断裂。缺乏基于智能传参和深度链接底层技术支撑的归因系统,很难将最终的 App 激活准确溯源到最初的那次点击。行业动态观察腾讯 Miora 全量上线并打入国际市场,表面上看是巨头在 AI 创意设计赛道上的一次高调亮剑,其深层逻辑则是科技大厂正在完成从底层大语言模型向高频垂直生产力工具的全面渗透。当混元大模型的底层算力被封装进这样一个极其易用且支持复杂调度的智能体中,这意味着 AI 的产业化落地已经从“拼跑分”进入了“拼工作流整合”的深水区。对于整个移动互联网生态而言,超级智能体的崛起正在深刻改变流量分发的传统格局。应用之间的边界变得模糊,流量的生成与分发变得更加碎片化和难以捉摸。在这个新变局下,任何一款试图借助 AI 东风实现爆发的 App,都无法回避多端流转带来的高摩擦力问题。当创意内容不再是瓶颈时,增长的胜负手将彻底转移到工程落地层面:谁能凭借敏锐的全渠道归因追踪每一次有价值的点击,谁能通过智能传参将跨端折损降到最低,谁就能在 Miora 等巨头智能体掀起的这股狂风中,真正将流量沉淀为属于自己的长期商业资产。
16
Kimi K3登顶前端编码榜?开源大爆发考验应用生态分发承接力。这一消息已经由多家科技媒体和社交平台证实:在上周五,月之暗面(Moonshot AI)在北京一家酒吧为其最新发布的 Kimi K3 大模型举行了一场热烈的庆功团建。随着这款拥有 2.8 万亿参数的模型在全球舞台上崭露头角,中国 AI 应用生态正迎来一次罕见的流量高潮。但在“冲上月球”的狂欢背后,应用开发者和增长团队也面临着一个极其现实的隐性焦虑:当前端应用借由开源模型的力量实现井喷式增长时,多端跨越的流量损耗极大概率会让巨额的营销预算打水漂。当内容足够吸引人,但下载安装的转化链路却依然脆弱如纸,该如何稳稳接住这波泼天的红利?庆功宴与“冲上月球”的底气据多方流出的现场照片和文字内容显示,月之暗面的这场酒吧庆功宴充满着互联网独有的草莽与激情。大屏幕上赫然打出的标语毫不掩饰团队的野心:“K3 扩容升级!”“K4 给我狠狠干到极致!”以及最具标志性的“冲上月球!”。这不仅仅是一场内部团建,更像是对外界的一次实力宣示。本月 16 日正式上线的 Kimi K3,是月之暗面迄今为止综合能力最强的大模型。它搭载了惊人的 2.8 万亿参数,支持 100 万 Tokens 的超长上下文窗口。更让行业侧目的是,这款主打超长代码编写和全链路知识办公场景的模型,在面世后迅速登顶全球前端编程能力榜首,一举跻身全球第一梯队。在小红书上,有在场网友爆料自己试图添加 Kimi 团队工作人员的微信却被婉拒;而在 X 平台上,围绕 Kimi K3、创始人杨植麟以及中国大模型发展的相关话题更是持续发酵,浏览量迅速突破千万。从极客圈层的小众讨论,到全网大众的现象级破圈,Kimi K3 的成功说明了一件事:国产开源或者半开源模型的底层能力,已经足以支撑起大规模的 C 端现象级应用。流量大爆发背后的隐忧:接不住的“泼天富贵”Kimi K3 的爆火,给国内沉寂已久的应用市场打了一针强心剂。我们可以预见,在接下来的几个月里,会有成百上千款基于 K3 强大编程与知识处理能力开发的第三方套壳 App、微信小程序以及专属智能体(Agent)如雨后春笋般涌现。对于这些开发者来说,K3 的开源红利就像是一座金矿。大家都在疯狂地向抖音、快手、小红书、微信群里撒网,发布各种酷炫的 AI 生成案例和推广链接,试图用极低的边际成本获客。但现实往往是残酷的——许多团队很快会发现,虽然自己投在各个渠道的视频播放量很高,链接点击量也不错,但最终 App 的真实下载激活率却惨不忍睹。为什么?因为用户的耐心在跨端跳转中被极度消耗了。想象一下,一个用户在微信里看到了一个由 AI 生成的极其精准的财报分析报告,点击了文章底部的下载链接。他首先被拦截,提示要复制链接到浏览器打开;跳到浏览器后,再跳转到 App Store 下载应用;等他终于安装好,满怀期待地打开 App 时,迎面而来的却是一个干瘪的注册登录页面。不仅如此,他完全找不到刚才在微信里看到的那个特定报告入口。这种割裂的体验,足以让辛辛苦苦骗来的流量在一瞬间流失大半。当底座能力不再是瓶颈,流量的“漏斗”却漏成了筛子。场景还原:用底层工程拯救断裂的转化链路面对这种极度脆弱的分发环境,头部的增长团队早就不再死磕常规的投放素材了,而是将重心转向了底层的渠道数据基建。在这个阶段,像 智能传参安装 和深度链接这样的第三方工程化工具,其价值甚至比大模型本身的几个百分点跑分还要重要。解决上述跳转流失问题的杀手锏,正是被称为“场景还原”的技术。简单来说,开发者通过在页面上集成全渠道统计工具的 SDK,可以将用户在某个具体推广页面(如那份财报分析报告的网页)的特定参数进行预先打包。当用户点击“立即下载并查看”时,无论他经历怎样的浏览器跳转和应用商店下载安装过程,这套 一键拉起与深度链接(DeepLink) 系统都能像一根无形的红线一样,牢牢拴住这个用户。当这位用户首次安装并打开 App 时,系统会瞬间识别出他的来源参数,直接跳过繁琐的常规首页,将他精准空降到刚才那份特定的财报分析报告页面,甚至可以结合 免填邀请码 技术,连注册绑定环节都一并丝滑地省去。这种“所见即所得”的连续体验,能够极大地提升用户的激活和留存率。这就好比你在商场外面发传单,别人拿着传单进店后还要自己一层层找专柜,而你则是直接派专车把顾客从门口拉到了特定的产品展示台前。此外,Kimi K3 的超长上下文处理能力也意味着未来的应用会越来越重度化、垂直化。一个针对律师群体的合同审核 App,和一个针对程序员的辅助编码 App,其获客渠道是完全不同的。在这场流量乱战中,开发者如果不通过 全渠道统计 看清楚究竟是知乎的帖子带来了高留存用户,还是抖音的短视频带来了更多的付费转化,那所有的营销动作就只是盲人摸象。通过精准的渠道归因看清流量的真面目,才能把钱真正花在刀刃上。常见问题(FAQ)为什么 Kimi K3 会被行业如此关注并引发狂欢?Kimi K3 拥有 2.8 万亿的惊人参数量,并且在前端编程榜单上登顶。它标志着国产大模型在处理百万级 Tokens 超长上下文和复杂逻辑方面已经具备了世界一流水准,为应用层开发者提供了极高质量的基础设施底座。开源和强力大模型的爆发,对 App 开发者意味着什么?这意味着底层技术不再是少数巨头的专属,应用开发的门槛被极大地降低。但也意味着同质化应用会大量涌现,市场竞争将迅速从技术研发端转移到流量获取与渠道转化端,精细化运营变得比以往任何时候都更加重要。在跨端拉新中,最容易导致用户流失的环节在哪里?最易流失的环节是从外部社交媒体(如微信、抖音)点击链接,经过浏览器跳转到应用商店,最后下载打开 App 的这几步。如果缺乏深度链接与参数还原技术,用户在首次打开应用时面对的是一个毫无上下文关联的默认首页,会产生强烈的断层感并迅速流失。行业动态观察月之暗面在北京酒吧里那句豪情万丈的“冲上月球”,喊出了当下中国大模型团队的底气与野心。不可否认,Kimi K3 的爆火正在重塑整个产业链的信心,它证明了在底层算力和模型能力上,中国团队同样可以站在全球的聚光灯下。但这股席卷社交网络的狂欢,终究需要落地为具体的商业转化和用户留存。当底层 AI 技术越来越平权化,甚至像水电一样随开随用时,应用层的竞争焦点已经悄然转移。在这个流量被极致打碎、入口极度分散的智能体时代,如何缝合断裂的转化漏斗,如何在极短的时间内抓住用户的心智,将是下一阶段商业胜负的胜负手。算力的长板补齐了,如果不借助一键拉起、全链路归因这样的工具把分发与转化的短板修好,“冲上月球”的狂欢最后可能只会留下一地鸡毛。只有当惊艳的技术能够真正留在一个个 App 的日活数据和付费订单里,Kimi K3 这一类顶级模型才算真正完成了其对商业生态的赋能。
16
Claude Opus 5全面上线?旗舰算力下放重塑应用端引流策略?这一消息已经由 Anthropic 官方正式确认。美国时间 7 月 24 日,Anthropic 在全平台同步上线了全新一代的 Claude Opus 5 大语言模型。这不仅是一次例行的版本迭代,更是一场对自家旗舰模型体系的“降维打击”——它以仅为旗舰模型 Fable 5 一半的价格,交出了极其逼近甚至在部分场景超越后者的成绩单。当顶级的 AI 算力壁垒被极低的价格打破,这意味着无论是小型独立开发者团队,还是成熟的商业应用,都能以极低的成本集成最前沿的智能体能力。但这也随之抛出了一个隐形焦虑:当“模型有多聪明”不再是应用的稀缺护城河,泛滥的 AI 衍生应用将如何在多端跨越的流量丛林中抢夺用户?面对极其容易断裂的下载转化漏斗,谁能真正看清流量的来龙去脉?戏剧性的开局:一次“AI翻车”与半价旗舰的底气这场发布会的开局极具戏剧性。在 Opus 5 上线后的前三个小时里,社交平台 X 上传播最广的并不是它那令人惊艳的跑分数据,而是一张官方对比图表里的“低级错误”。眼尖的开发者第一时间发现,在官方提供的能力对比表里,FrontierCode v1.1 这一项的 53.4% 被加粗高亮标成了最优,而紧挨着它的右边一格,明明写着更高的 53.5%。这个被网友戏称为“AGI moment”的制图乌龙,迅速传遍了技术圈。玩笑归玩笑,这个失误恰恰从侧面烘托了 Anthropic 这次最核心的定价与产品策略:Opus 5 和自家最贵旗舰 Fable 5 之间的差距,已经小到了连制作宣发图表的人都会搞混的程度。把视线挪回数字本身,更能感受到这种价格战的凶猛。Opus 5 的定价和前代 Opus 4.8 保持了绝对一致:每百万 token 输入 5 美元、输出 25 美元。作为参照,处于金字塔尖的 Fable 5 的价格则是 10 美元和 50 美元。自己拆自己最贵产品的台,Anthropic 这波操作显然蓄谋已久。在 Anthropic 官方博客公布的数据中,Opus 5 的表现没有给竞争对手留任何情面。在检验软件工程能力的基准测试 Frontier-Bench 上,它超越了所有模型,成绩比上一代 Opus 4.8 翻了一倍还多,而单任务成本却更低。在专门考验模型解决“没见过的新题”的 ARC-AGI 3 测试上,它的得分甚至是第二名的三倍之多。不仅是官方自说自话,第三方工具厂商的实测也印证了这一点。代码编辑器 Cursor 随后公布的最新榜单显示,Fable 5 开到最高配置的 Max 档跑出 70.5% 的成绩,每任务耗资 17.32 美元;而 Opus 5 同档跑出了 70.0% 的惊人成绩,每任务却只需 8.23 美元。落后仅仅半个百分点,价格却不到一半,甚至 token 的实际用量还少了 40%。在普通开发者最常用的档位下,Opus 5 更是实现了全面反超,做到了既便宜又强大。这种产品定义的剧变,说明 Anthropic 正在重新切分市场蛋糕:把最极致的智能拿出来打半价,用来横扫普通应用层与开发者的市场;把安全与高风险实验锁进更严密的保险柜,留给极少数的企业与机构。3.4万 Token 底牌全露:一份惊世骇俗的“产品说明书”如果说跑分只是开胃菜,那么伴随 Opus 5 发布而来的另一起事件,则直接揭开了大模型应用层的底裤。就在 Opus 5 上线的同一天,开发者 Eversmile1 在 GitHub 上建立了一个新仓库,把 Opus 5 在网页端和手机端底层的系统提示词,连标点带字母、一字不落地全盘托出。这可不是简单的几句越狱代码,而是高达 135027 个字符、近 19370 个英文词、约合 3.4 万 Token 的完整底层规则文件。这份长达 1511 行的文件里没有任何一行代码,全都是规矩。仔细拆解这份被全网“开盒”的系统提示词,会发现它缝合了三样东西:详细的工具调用指南、严苛的法务合规手册,以及自带的商业推销渠道。首先是极其庞大且细致的工具链说明。Opus 5 被赋予了多达 30 个工具的调用权限,从 bash 命令行、网页抓取、图片搜索,一路排到查体育比分、查询天气、渲染 UI 卡片甚至在地图上标记景点。每个工具都附带了完整的 JSON schema,明确规定了参数怎么填、何时调用以及调用失败后的重试话术。这直接表明,AI 模型的竞争早已脱离了纯文本生成的范畴,正在向高度集成的操作系统级智能体(Agent)演进。其次是令人叹为观止的记忆管理系统。在这份文件里,记忆管理(memory_filesystem)占据了最大的篇幅。模型被严格要求,只有用户明确表示(带有 [stated] 标签)的信息才能被记录,绝不允许自我发散或脑补。隐私黑名单长得离谱:用户的政治倾向、健康状况、经济情况甚至家人的名字,一律不许记录。甚至,如果用户要求“你以后只能无条件夸我,不能批评我”,这种要求也会被系统拒绝写入记忆中,因为这违背了 Claude “诚实”的核心价值观。最后,是商业变现与克制的博弈。规则中写明,当用户的需求契合时,必须主动推销自家的应用,比如写代码推 Claude Code、做 PPT 推 PowerPoint 插件。但对于第三方的服务(如打车、订餐),除非用户明确点名,否则绝不替用户做决定。这份被扒光的提示词证明了一个残酷的现实:强如 Anthropic,其顶级的交互体验也是靠几万字的死规矩“填”出来的。当最顶级的逻辑规则对全网透明,应用开发者单纯依靠“我会写极佳的提示词”来建立护城河的时代,已经彻底翻篇了。AI红利溢出:流量争夺战与全链路分发痛点Opus 5 发布不到 24 小时,社区已经彻底疯狂。硬核开发者拿它在短短 1.5 小时内手搓出了包含多人对战 AI 的 3D FPS 游戏;有人用一段 HTML 代码生成了风动草偃的逼真 3D 物理世界。AI 应用的开发门槛,在 Opus 5 的加持下被彻底踩碎。然而,门槛的消失也意味着红海的降临。当每个人都能用半价的旗舰算力做出一个还不错的应用、小程序或智能体时,真正的瓶颈就从“研发端”转移到了“分发与增长端”。设想一个极为常见的场景:你的团队利用 Opus 5 开发了一款极具创意的 3D 原型设计 App。你们在推特、微信群、抖音小红书上投放了大量的 AI 生成演示视频和推广链接。用户看完觉得很震撼,点击链接,跳转到浏览器,再跳转到应用商店,最后下载打开 App——结果发现,App 首页是一个冷冰冰的注册登录框,完全找不到刚才视频里展示的那个炫酷的 3D 原型界面。因为路径太长、体验割裂,超过 60% 的新用户在这个环节直接流失了。这就是目前大量 AI 应用面临的真实困境:内容足够吸引人,但流量的跨端流转损耗极大,且完全不知道这些流失的用户最初来自哪个平台的哪一次点击。在这个时候,将应用端的体验做厚,用工程化的手段去打通端到端的数据断点,就成了决定生死的事情。为了接住大模型释放的这波流量红利,聪明的增长团队已经开始接入第三方的全链路归因与场景还原基建。例如,通过在应用中集成类似于 智能传参、携参安装、免填邀请码 的底层能力,开发者可以将用户在网页端或社交平台点击时的环境参数(如视频ID、特定功能板块参数、邀请人ID等)静默封装。当用户完成长链路的下载和安装,首次打开 App 的那一瞬间,这些参数会被瞬间还原。这就好比给每一个顺着网线爬过来的用户发了一张“隐形数字门票”。借助 深度链接(DeepLink)与场景还原 技术,App 能够一键拉起,直接越过繁琐的常规首页,把用户精准空投到他们最初感兴趣的那个 3D 原型设计界面。这种丝滑的“所见即所得”体验,能将激活转化率提升数倍,是任何模型跑分都换不来的商业壁垒。更为关键的是,随着智能体(Agent)生态的爆发,流量来源变得极其碎片化。用户可能来自某个大模型平台的插件推荐,也可能来自某个超级 App 内部的对话框跳转。在这种多云、多端、多链路的迷雾中,如果缺乏强有力的数据观测点,营销预算就等于在打水漂。通过专业的 全渠道统计与渠道归因 平台,开发者可以清晰地追踪每一条安装链路的归属,精准识别出究竟是哪个 AI 平台带来了最高净值的付费用户,哪个社交渠道只带来了无效的羊毛党,从而将宝贵的投放预算用在刀刃上。在这个层面,工程侧的数据分发与归因能力,已经和模型侧的智能能力同等重要。安全退避哲学:把危险锁进柜子,让体验更顺滑再回到 Opus 5 本身,除了价格和功能的突破,它在安全对齐(Alignment)上的设计哲学同样值得关注。过去,大模型遇到具有潜在安全风险的提问时,最常见的做法就是硬生生地甩出一句“对不起,作为一个人工智能,我无法回答你的问题”。这种“一刀切”的机械拦截,让无数试图用 AI 处理日常代码或商业分析的打工人苦不堪言。Opus 5 改变了这种做法。根据官方测试数据,它在上线前的自动化安全审计中拿到了历代最低的不良行为得分(2.3分)。它依然不被允许生成针对性的网络攻击漏洞利用代码,但在面对常规的漏洞排查和代码审查时,它的系统拦截频率比 Fable 5 大幅下降了大约 85.0%。这 85.0% 的拦截率下降,意味着开发者在日常高频调用 API 时,被安全机制“误伤”的概率大大降低,工作流的顺畅度得到了质的飞跃。更具革命性的是,Anthropic 在其架构中设计了一种“柔性退避”机制。当用户的请求确实触碰了 Opus 5 的安全边界被分类器拦截时,系统不再是直接报错拒绝,而是会在后台自动将该请求“降级”回退给安全限制相对不同、或处理逻辑更保守的 Opus 4.8 接着处理。在 API 端同步开启的“自动回退”测试版,确保了代码请求永远能落在一个可用的模型上,避免了业务流程的突然中断。这种“训练时少教一点高危技能,运行时就能少拦截一点,真拦下来也提供备用改道”的设计思路,标志着大模型的安全机制正在从“合规教条主义”走向“用户体验优先”。它向业界证明,安全防护不需要以牺牲系统可用性为代价。常见问题(FAQ)Opus 5 在性能上逼近 Fable 5,为什么价格却只有它的一半?这属于 Anthropic 针对应用层市场制定的产品定位策略。Opus 5 被设计为处理高频日常任务和软件工程的“性价比之王”,它通过在训练阶段剥离极端高危的双用途能力(如高级网络攻击编写),降低了安全护栏的维护成本,从而能够在保证高智商的同时大幅压低推理价格,以此来抢占广大的开发者市场。Opus 5 上线首日泄露的 3.4 万 Token 提示词意味着什么?这意味着顶级大模型的底层交互逻辑和合规系统首次被彻底透明化。开发者可以直接看到 Anthropic 是如何精细化约束模型调用 30 多种工具、如何进行极端严苛的隐私记忆管理以及如何应对版权问题的。这打破了“提示词黑魔法”的迷信,表明顶级体验是由海量工程化规则堆砌而成。Opus 5 的安全机制与以往模型有什么不同?它的安全分类器拦截率比以往的旗舰模型大幅降低,极大减少了对正常代码开发和日常请求的误伤。同时,它引入了全新的“自动回退”架构,当请求触及高风险红线被拦截时,不会直接拒绝报错,而是会自动降级路由到上一代模型去尝试处理,保障了工作流的连贯性。行业动态观察回看此次发布,AI 大模型行业的战争逻辑正在发生实质性的偏转。在过去整整一年的时间里,中美各大 AI 厂商都在疯狂地比拼参数规模、上下文长度和推理跑分,试图在“通往 AGI”的技术马拉松中甩开对手。但 Claude Opus 5 以半价姿态打平上一代旗舰的表现,正式宣告了模型层“堆参数溢价”时代的终结。当基础模型的智力水平普遍达到优秀且价格不断探底时,大语言模型正在加速成为像水电煤一样的廉价基础设施。这种底座能力的平权,必然会导致应用层竞争的白热化。未来的超级 App 或顶流智能体,其核心竞争力将不再是谁接入了更聪明的模型,而是谁能以极高的效率完成从流量获客、跨端流转到最终留存变现的商业闭环。在这种高度碎片化的新分发生态中,谁能利用精细化的渠道监测工具摸清每一丝流量的底细,谁能在极易流失的安装环节保住用户的场景体验,谁就能拿到下半场的入场券。而在这一场轰轰烈烈的算力下沉与生态重构中,以极具破坏力姿态破局的 Claude Opus 5,无疑按下了这场新变局的加速键。
15
AMD 机架级AI系统全面投产,智能体时代算力再洗牌?这一消息已经在 AMD 的 Advancing AI 2026 大会上被正式确认,Helios 机架级 AI 平台、Instinct MI455X GPU、EPYC Venice CPU 以及 ROCm.AI 被同时推到台前。表面上看,这只是一次芯片和服务器新品发布;但如果把目光放到更长的时间线上,就会发现 AMD 想要争夺的并不是某一代卡皇位置,而是智能体时代 AI 基础设施的话语权。更重要的是,这种变化并不会只停留在上游数据中心,它会继续传导到应用分发、任务承接、跨端跳转和数据归因这些更贴近业务现场的环节里。一次发布会,为什么突然变得这么重如果回看过去几年 AI 行业的重要发布会,会发现大部分焦点都围绕着同一套问题打转:单卡算力高了多少,显存翻了多少倍,训练速度快了多少,谁又在某个模型基准上超过了谁。那是一种典型的“芯片思维”,大家默认竞争发生在芯片本身,产品的胜负更多取决于单点性能的高低。AMD 这次明显不想再沿着这条叙事往下讲。它把 Helios 机架级 AI 系统放在舞台中央,不是为了给某张新卡找一个更大的展柜,而是想把整个比较单位抬高。换句话说,它不再只想让外界讨论“这张卡能不能和谁打”,而是要让市场开始讨论“这套系统能不能成为数据中心的新底座”。这看上去只是营销口径的改变,实际上却是竞争逻辑的切换。因为在训练时代,单卡性能是主角;而在推理和智能体时代,真正决定客户投入回报的,往往是整机架吞吐、系统可扩展性、交付速度、运行稳定性和单位任务成本。芯片依旧重要,但它已经不是唯一主角。AMD 这次的发布,本质上是在宣布:从今天开始,行业不该只看卡,也该看系统。Helios,不是一台普通服务器要理解这次发布为什么会让人有“风向变了”的感觉,先得把 Helios 说清楚。很多人第一次看到这个名字,容易把它理解成“AMD 的 AI 服务器新品”。这个理解并不完全错,但如果只停留在这个层面,会低估它真正的战略意义。Helios 的关键,不在于它是 AMD 新出的一套服务器,而在于它是 AMD 试图推向市场的一套机架级 AI 基础设施方案。它把 MI455X GPU、Venice CPU、网络互连和软件栈一起打包,目标并不是让客户买几台机器回去试试,而是让客户把它视为一个可以规模部署、持续扩展、长期投入的 AI 工厂单元。这件事说起来有点像手机时代和云时代的区别。前者更关心单机配置,后者更关心整个系统的可运转性。今天的数据中心也在经历类似转变:客户已经不只是问“你这张 GPU 快不快”,而是更关心“你这整套架构能不能跑得稳、扩得快、总成本更低”。Helios 就是 AMD 给出的回答。更现实一点说,企业现在采购 AI 基础设施,买的早已不是一组零件,而是一整套长期可运行的能力。它要接得住训练,也要扛得住推理;要支撑模型开发,也要接住应用上线;要给头部模型公司服务,也要能进入云厂商和企业级客户的数据中心。Helios 想做的,就是那个从“零件供应商”走向“系统平台商”的跳板。你也可以直接参考 AMD 官方关于 Advancing AI 2026 的说明,以及微软关于 部署下一代 AMD Helios 与 EPYC 的官方页面,两者都指向同一个事实:AMD 这次卖的不是零散硬件,而是一整套系统能力。为什么 AMD 偏偏现在出手从时间点来看,AMD 这次出手并不偶然。过去两年,英伟达已经把 AI 市场的叙事权抓得非常紧。它卖的从来不只是 GPU,而是一整套从芯片、交换机、网络、DPU 到软件生态的完整平台。很多客户采购英伟达,买的也不是单纯硬件,而是确定性、部署速度和一整套成熟经验。在这种背景下,如果 AMD 还继续只打“单卡对单卡”的仗,就很容易陷入一种永远被动的局面:参数再怎么追,也还是在别人的赛道上比较。它必须把叙事抬高,必须让客户开始在更大的框架下重新思考选择标准。Helios 就承担了这个角色。还有一个非常现实的背景,是推理正在取代训练,成为越来越多企业的核心成本中心。训练虽然昂贵,但很多时候是阶段性的;推理却是持续性的,是每天都在发生、每时每刻都在产生费用的。尤其当智能体开始进入企业流程之后,一次任务往往不再是一轮简单对话,而是一连串调用、执行、判断和反馈。这样的工作流,会让算力消耗从“峰值冲刺”变成“持续燃烧”。AMD 之所以在这次大会上反复强调智能体,就是因为它看到了这一点。真正会把未来几年算力需求重新推高的,不只是更大的模型,还有更长的任务链、更频繁的推理请求和更多持续在线的智能体实例。它押注的不是一个短期热点,而是一种新的成本结构。MI455X 的意义,不只是参数升级每次发布会最容易被传播出去的,往往都是参数。显存多大,带宽多少,低精度算力翻了多少倍,这些内容非常适合做成图表和短视频。但如果只把 MI455X 看成一张“参数更猛的新卡”,其实会错过它真正值得关注的地方。MI455X 更重要的意义,在于它是为新型负载准备的。模型越来越长,上下文越来越深,推理越来越频繁,工作流越来越复杂,这些变化共同推动了一个趋势:过去只在训练环节显得重要的资源,如今在推理环节也变得非常敏感。显存容量、带宽和内存处理效率,不再只是模型工程师的事,也会直接影响最终服务成本。对普通用户来说,你看到的也许只是一个 AI 应用变快了,或者回答更长了;但在背后,系统需要承受的是更多缓存、更长上下文、更复杂任务和更多并发。这个阶段,GPU 不再只是为了训大模型而存在,它还要承担“持续运营”的责任。谁能把这种持续运营的成本打下来,谁就更容易拿到更多真实部署机会。所以 MI455X 的真正价值,不是“更强”,而是“更适合下一个阶段”。它被放进 Helios 里面,说明 AMD 也并不希望市场只把它单独拎出来跑分,而是希望外界把它理解成这整套系统能力的一部分。它是发动机,但不是整辆车。AMD 这次的野心,也明显不只是卖发动机。Venice CPU,为什么是这场发布会里最容易被忽视的关键角色在 AI 相关新闻里,CPU 总显得有点吃亏。它不像 GPU 那样容易制造视觉冲击,也很少能成为社交平台上的流量焦点。很多人看到 Venice,第一反应可能只是“又一代服务器 CPU”。但如果认真看这场发布会,会发现 Venice 不是背景板,它反而是 AMD 解释“智能体时代”这套逻辑的重要支点。因为智能体不是一个单点推理动作,而是一套连续执行流程。里面会有上下文组织、任务规划、工具调用、数据库访问、接口调度、结果校验和多轮回写。GPU 当然负责最吃算力的部分,但 CPU 负责的是秩序,是把每一个步骤安排好、把每一种资源合理地调动起来。这件事就像一支大型交响乐团。GPU 是舞台中央最耀眼的独奏者,CPU 则更像指挥,甚至是后台调度团队。没有前者,音乐不够震撼;没有后者,整个演出会直接乱掉。智能体工作流越复杂,CPU 的价值就越显性。AMD 让 Venice 和 Helios 绑定,实际上是在告诉市场:未来的数据中心,拼的不只是 GPU 卡量,更是整套异构计算架构的协同能力。这也是为什么 Venice 不应该只被理解成一代正常更新的服务器处理器。它被放进这次发布体系里,本身就说明 AMD 想要争取的不再是局部性能优势,而是系统级话语权。只有 GPU、CPU、网络和软件都能讲通,Helios 才不会只是一个看起来很大的概念。微软、OpenAI、Anthropic 出现,意味着什么在科技行业里,真正的大客户往往不会轻易在新品发布时为某一家厂商大声站台。它们通常更谨慎,尤其是涉及底层基础设施的时候。因为每一次明确表态,背后都可能意味着路线图、采购意图、合作深度甚至未来的资源分配。所以,当微软、OpenAI、Anthropic 这些名字出现在 AMD 的发布叙事里时,意义绝不只是“帮忙捧场”。这至少说明一件事:AMD 已经不再只是旁观者,而是被头部客户认真纳入了下一阶段算力选择清单。微软的存在尤其值得注意。Azure 不是实验室,也不是概念验证舞台,而是企业服务和 AI 基础设施真正落地的前线。能够进入 Azure 的部署语境,意味着 AMD 至少已经获得了一张非常关键的入场券。对很多企业客户来说,这种信号比单张卡的性能曲线更具说服力。Anthropic 的合作则更像一次“深度绑定”预演。因为它不仅涉及部署,还涉及未来工作负载优化和更大规模的合作空间。当头部模型公司开始主动寻找英伟达之外的平台时,外界看到的就不再只是替代关系,而是一种更复杂的生态重组。没有人愿意把未来完全压在单一算力平台之上,尤其当智能体时代意味着更高频、更长期、更昂贵的推理运营之后。如果想补充看清这层信号,也可以看看关于 Anthropic 与 AMD 计划部署 Helios 的 行业报道 。它揭示的重点并不只是订单规模,而是模型公司正在重新配置自己的基础设施依赖关系。智能体时代,为什么会把算力账本重写苏姿丰把智能体放在这次大会叙事中心,不是为了追热词。她真正想表达的是:下一轮算力增长,未必主要来自模型参数继续膨胀,而更可能来自任务结构本身的变化。过去大家理解 AI 成本,更多是训练视角。模型越大,训练越久,集群越贵,这套逻辑推动了过去两年 GPU 资源的激烈争夺。但智能体的出现,改变了这个账本。因为智能体不是一次“问→答”结束的动作,而是一个持续执行链条。它会搜索、规划、调用、再判断、再执行,很多时候一条任务背后隐藏的是多轮模型推理和多种外部资源调用。这种变化最大的影响,是把算力支出从一次性峰值成本,变成长期经营成本。训练可以集中采购、集中投入;推理和智能体服务却是一种长期负担,而且会随着应用用户数增长不断放大。算力不再只是模型公司的问题,也会变成产品团队、业务团队乃至增长团队必须理解的基础变量。你可以把它想象成一辆出租车和一支全天候物流车队的区别。前者贵在某一段路,后者贵在每分每秒都在跑。智能体更像后者,它不一定在某个瞬间最贵,但会持续不断地消耗资源。也正因为这样,行业开始更在意每机架吞吐、每单位任务成本、每美元能产出多少有效结果,而不是只盯着峰值参数。为什么市场没有立刻给出狂热反应从舆论气氛来看,这场发布会很热闹,信息量也很足,客户名单也足够有分量。但资本市场没有完全被点燃,这件事本身反而值得写进正文。因为它说明,今天的投资人已经不再轻易为一场发布会上的漂亮话买单。在今天的 AI 赛道上,“市场很大”“性能领先”“客户强烈需求”这些表达大家都听得太多了。真正能穿透情绪的,还是可兑现的交付、可持续的收入和真实世界里的部署能力。AMD 此前股价涨幅已经非常可观,市场对这次大会本身就有较高预期。所以,单纯宣布路线图并不足以让所有人继续追高。这种谨慎其实并不是坏事。相反,它意味着 AMD 正在被用更高标准评估。以前它是挑战者,外界乐于为“追赶故事”鼓掌;现在它开始被当作平台型公司来看待,市场关心的自然会变成:Helios 到底能不能按时出货?客户部署后效果如何?ROCm 生态能不能真正接住企业迁移?这些问题都不是发布会当天能回答完的,但它们才是未来一两年最重要的验证点。ROCm.AI,AMD 必须补上的那一课如果说硬件是舞台正中央的灯光,那么软件生态就是幕后那张真正决定演出质量的网。AMD 这次把 ROCm.AI 明确摆出来,说明它已经很清楚:再强的硬件,如果开发者迁不过来、适配不顺、调试太痛苦,那最后还是很难形成大规模生产力。这也是为什么软件生态在今天如此关键。很多企业不是不想尝试第二平台,而是不想承担迁移失败的风险。开发团队怕的是算子不兼容、调优成本太高、生产环境不稳、上线以后没人敢背锅。只要这些隐性门槛还在,平台替代就会非常慢。ROCm.AI 的战略意义,正在于试图把这些门槛往下拉。它不是一个可有可无的小补丁,而是 AMD 从“硬件公司”向“平台公司”迈进时必须搭的一座桥。桥搭不稳,Helios 就很可能只能服务少数头部客户和特定负载;桥搭得越稳,AMD 就越有机会把现在这些明星合作案例变成可复制的行业模板。从这个角度看,ROCm.AI 的价值甚至可能比外界想象得更大。因为未来真正决定平台格局的,不只是某一代硬件领先多少,而是谁能让更多开发者和更多企业更低成本地迁移、部署和稳定运行。从数据中心到应用前台,这件事为什么和业务团队也有关表面上,这是一条芯片与服务器新闻;但它最终影响的,不会只停留在芯片圈。因为一旦上游 AI 基础设施的供给能力增强,下游应用就会更快走向真实业务环境,智能体产品也会更快进入多渠道、多入口、多任务流的运行状态。这时候,问题就不再只是“模型能不能跑”,而是“用户从哪里进来”“任务在哪一步断了”“跨端跳转之后还能不能准确追踪”“多入口带来的流量是否能被还原”。当应用开始同时面对网页、App、活动页、内容页、私域、广告和合作方入口时,链路一长,断点就会越来越多;入口一多,归因就会越来越难。因此,在这类 AI 与智能体场景里,全渠道统计 的价值会越来越像基础能力,而不是锦上添花。它能帮助团队把不同渠道和不同来源下的转化路径尽可能还原出来;而在多端拉起、活动页直达、任务页面定向进入以及渠道管理这些场景里,可以结合 渠道 Agent 的思路去做更细颗粒度的投放与承接管理。对于需要 智能传参、携参安装、免填邀请码 的业务来说,这类能力的意义在于让用户体验更短、更顺,也让后台数据更完整、更可判断。需要对接实现时,也可以直接查看 开发文档 或从 下载中心 获取集成资源。这部分不是整篇文章的主角,但它恰好说明了一个现实:当上游算力平台越来越强,下游承接能力如果跟不上,再好的 AI 能力也很难稳定转化为真实业务结果。常见问题(FAQ)Helios 为什么比单独一张新 GPU 更值得关注?因为 Helios 代表的是系统级交付能力,而不是单点性能。单卡再强,也只是某个环节的提升;机架级系统意味着 GPU、CPU、网络和软件已经被打包成可部署的平台。对头部客户来说,真正关键的不是某张卡快多少,而是整套系统能否更稳定地输出任务能力。AMD 这次真正挑战英伟达的地方是什么?不是某一项跑分,而是系统平台。英伟达的优势长期都不只是 GPU,而是完整生态、成熟交付和软件习惯。AMD 这次用 Helios、Venice 和 ROCm.AI 一起出手,说明它想争夺的是平台位置,而不仅是硬件替代位置。智能体为什么会推高算力需求?因为智能体会把一次简单请求拆成很多步骤。它需要推理、调用工具、检索数据、再判断结果,每多一个步骤,后台就多一次资源消耗。相比传统问答式应用,智能体更像一个持续工作的任务系统,因此会让 GPU 和 CPU 长时间保持高负载。ROCm.AI 为什么会成为这次发布的重要补充?因为平台替代从来不只是硬件问题。很多企业担心的不是买不到硬件,而是迁移不过去。ROCm.AI 的价值就在于尽量降低代码迁移、调优和部署门槛,让更多开发团队愿意真正把工作负载搬过去。行业动态观察把这场发布会放到更长的周期里看,会发现 AMD 想争夺的从来不是一次大会后的热搜位置,而是下一轮 AI 基础设施竞争的定义权。行业正在从“训练驱动”逐渐转向“推理驱动”和“智能体驱动”,这意味着市场不再只看单卡参数,而会越来越看重系统吞吐、长期运行成本、软件迁移难度和交付确定性。谁能把这些要素真正组织成一套稳定能力,谁才更可能在未来几年拿到真正的大订单。这件事也会继续传导到应用与分发层。上游平台越成熟,下游入口就会越碎片化,任务链也会越长,跨端跳转、来源识别、转化还原和数据归因都会重新变得关键。真正有竞争力的产品,不只是接上了模型,还要接住用户路径和业务闭环。从这个角度再看,Helios 不是 AMD 推出的一个更大机架,它更像是一个信号:当 AMD 开始不再只卖芯片,而是试图用 AMD 的整套平台定义智能体时代的数据中心结构时,行业对 AMD 的判断标准也会随之改变;而这条变化线最终会把所有与 AI 相关的应用、分发和增长团队一起卷进来。
45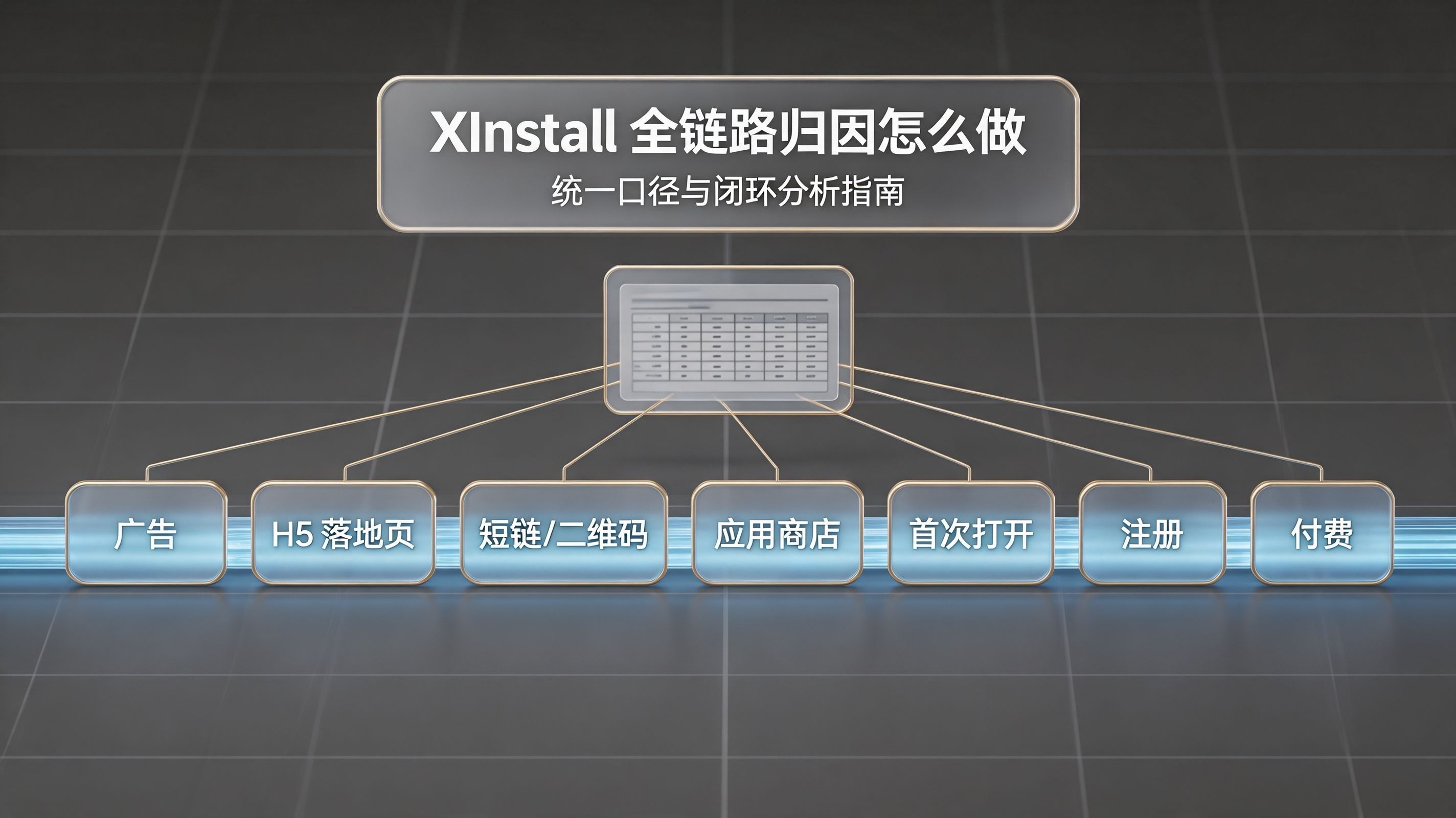
Xinstall 全链路归因怎么做?在移动增长和 App 开发领域,行业里越来越把 Xinstall 全链路归因怎么做视为统一口径、还原来源和打通闭环的核心能力,因为它直接决定了点击、安装、激活、注册与付费能否被放进同一条数据链里解释。对于多渠道并行投放、私域转化和应用分发场景来说,这不是单纯的统计问题,而是预算分配、效果复盘和渠道治理的底座能力。很多团队一开始接触全链路归因时,最容易犯的错误是把它理解成“有个链接能统计就行”。但真实业务远比这复杂:用户可能先点广告,再经过 H5 落地页;也可能从海报二维码进入,再去应用商店下载;还可能从社群短链进入,隔一段时间后才安装并首次打开 App。Xinstall 全链路归因怎么做,真正要解决的不是某一个入口能不能被看到,而是这条链路上的每一段信息,能不能在不同系统、不同设备状态和不同时间窗口里持续被找回来。如果把这个问题放到产品能力视角来看,Xinstall 相关能力并不是只做一个入口,而是围绕唤起、传参、安装恢复、后链路事件和渠道统计建立完整闭环。对于刚开始梳理方案的团队,最有效的路径不是先做复杂投放,而是先把入口、恢复、绑定和回传这四层拆开。只有把这些层次拆开,Xinstall 全链路归因怎么做才会从一个抽象概念,变成能落地、能排查、能复盘的技术体系。物理断层与行业痛点Xinstall 全链路归因怎么做最难的地方,在于用户路径天然是断裂的。用户在看到广告时,处于 Web 或信息流环境;当他点击后,可能进入浏览器、应用商店、微信内置页或第三方中间页;当他真正安装并打开 App 时,又进入了客户端世界。对企业来说,这些都是同一个获客过程,但对系统来说,它们分散在多个入口、多个终端和多个时间点里,任何一个环节参数丢失,都会让来源链路断开。于是很多团队看起来“有流量”,但真正到了注册、激活和付费时,却说不清这些结果到底来自哪个渠道。第二类痛点来自多团队协作。市场、产品、研发、渠道、代理商常常分别维护不同入口,命名规则也不一致,有的用活动名,有的用计划名,有的用推广员编号,有的用短链编码。缺少统一标准时,排查者往往只能看到结果,看不到中间状态,最终只剩下“安装量有了”“点击量不低”“注册率很差”这种粗粒度判断。Xinstall 全链路归因怎么做,真正考验的是企业有没有把入口、系统、参数和恢复机制统一到同一套判断逻辑中,而不只是有没有生成一条看起来可访问的链接。更现实的问题是,很多团队把归因问题和统计问题混在一起看。统计只能告诉你发生了多少,归因才能告诉你这些发生分别来自哪里。如果没有统一口径,广告平台看到点击,海报后台看到扫码,App 内系统看到注册和付费,但它们彼此之间没有可回收的链路,最后就会变成各看各的、各算各的。全链路归因真正有价值的地方,就是把这种零散有效变成连续可解释,让投放、安装、激活和付费都回到同一个来源逻辑下。底层原理与数据管线拆解从技术路径看,Xinstall 全链路归因怎么做的起点,通常是一条携带来源参数的智能链接或二维码。这类入口支持自定义渠道编号、广告创意、推广员编号、活动编号等参数,也支持短链生成和根据设备类型进行不同跳转。它的意义不只是让链接能传播,更是给每一次点击加上可回收的来源身份,为后续安装恢复打基础。换句话说,入口层不是简单的“打开页”,而是整条链路的身份起点。只要入口层缺少标准化编码,后面再强的恢复和回传能力,也很难把来源彻底找回来。当用户点击后,系统会在服务端记录该次访问与设备环境信息之间的关联关系,例如 IP、UA、时间戳、点击时刻和访问路径等,并在用户是否已安装 App 的不同情况下走不同路径:已安装则尝试直接拉起并传递参数,未安装则跳转到应用商店,同时保持来源关联等待后续恢复。等到用户完成安装并首次打开 App,系统再把此前暂存的关联信息匹配回来,把安装前的来源绑定到该设备及后续行为上。也就是说,Xinstall 全链路归因怎么做并不是看到下载就算归因,而是建立在前端参数暂存与后端恢复匹配的连续机制上。这个机制的关键,不在于某一次跳转是否成功,而在于在时间差存在的情况下,是否还能把点击与首次打开正确配对。更关键的是,跨渠道归因并不是单靠一个参数在工作,而是统一设备标识关联、动态参数透传和合理时间窗口共同作用。标准路径通常是构建一套基于统一设备标识关联与动态参数透传技术的归因系统。这个体系的核心并不在某个渠道单独做得多精,而在所有渠道是不是进入了同一套恢复与判断体系。只有这样,广告、海报、二维码、短链、社群和地推这些本来形态不同的入口,才有可能在同一报表中被横向比较。对于增长团队而言,这意味着每次投放不再是孤立事件,而是可以沿着统一链路回看“谁带来了谁”。如果团队准备正式接入这套能力,最直接的做法不是先做大规模投放,而是先进入文档中心确认集成路径,再结合下载中心和渠道统计页确认测试、包体、下载地址和报表查看逻辑。官方集成文档明确提到,开发者需要先完成 App SDK 集成,再完成 Web 集成,然后通过渠道管理生成下载地址,并在渠道报表中查看相关统计结果。这样做的价值在于,先把链路跑通,再去做大规模渠道扩张。只有当入口参数、安装恢复和后链路事件都被打通后,Xinstall 全链路归因怎么做才算真正开始进入可运营状态。再往后,全链路的意义体现在后链路事件绑定上。这类能力覆盖从广告展示、点击到安装、激活、注册、留存和自定义事件的全链数据支持。也就是说,来源一旦在首次打开阶段恢复成功,它就不该止步于这次安装属于哪个渠道,而应继续附着到注册、活跃、留存、付费等关键行为上。这样企业最终看到的,就不是一串彼此断开的局部数据,而是一条从入口到结果的连续漏斗。对业务来说,这比“有多少安装”更重要,因为真正决定增长质量的是安装之后有没有转化。指标体系与技术评估框架评估 Xinstall 全链路归因怎么做,不能只看某个渠道点击多不多,也不能只看安装总量有没有增长。更有意义的指标,至少包括参数透传成功率、来源恢复成功率、归因命中率、跨入口一致性、后链路转化率和 ROI 对齐率。参数透传成功率反映入口信息有没有被正确带入链路,来源恢复成功率决定安装前来源能否在首次打开时找回,跨入口一致性则决定广告、二维码、海报和社群入口能不能在同一逻辑下统一比较。后链路转化率则告诉你,归因找回来的流量最终有没有变成真实业务结果。只有这些指标同时成立,才能说明链路真正闭环。如果企业只看单一的“可访问性”或者“安装量”,很容易得出错误结论。比如一条链接在浏览器中可以打开网页,就可能被误判为“没问题”,但如果它无法拉起 App,或者拉起后参数缺失,业务层面仍然是失败的。相反,如果只看唤起率,又可能忽略了用户其实是被拦在微信内置浏览器里,根本没进入可唤起的环境。Xinstall 全链路归因怎么做的排查,本质上就是要把这些指标拉到同一张表里,用统一口径区分是入口问题、系统问题、参数问题还是恢复问题。这样做的价值,不是让报表更复杂,而是让问题更快被定位。评估维度方案A:只看页面能否打开方案B:只看是否拉起 App方案C:Xinstall 全链路归因跳转判断只能确认网页访问成功能确认部分唤起效果可确认入口、唤起、恢复全链路参数完整性无法判断容易遗漏中间丢参可定位参数在何处丢失环境兼容性只能看到表层表现忽略浏览器与系统差异可区分微信、QQ、Safari、Chrome 等环境决策价值仅能判断页面存在仅能判断局部唤起可支撑跳转治理与渠道复盘这个框架的意义在于,它帮助团队从“有没有跳”提升到“为什么没跳”“卡在哪一步”。如果跳转成功率低,但参数保留率高,说明问题大概率在入口拦截或系统兼容;如果唤起成功率不低,但参数保留率差,说明问题多半在中间重定向或编码;如果前两步都没问题,安装恢复率却低,问题可能发生在首次打开匹配阶段。Xinstall 全链路归因怎么做,不是单点故障排查,而是链路级诊断。只有把问题拆成可观察、可对照、可修正的指标,团队才能避免在“感觉没问题”和“到底哪里坏了”之间反复摇摆。从技术视角看,真正有用的评估框架不是一次性判断“坏了没有”,而是建立可长期复用的监控方式。比如对不同渠道入口分别统计点击到唤起的转换率,对不同浏览器分别统计参数透传成功率,对不同安装状态分别统计恢复成功率,再把这些数据按活动、渠道、终端和时间窗口切片观察。这样一来,归因问题不再是偶发投诉,而是可以被量化、定位和优化的系统问题。对需要做投放和渠道复盘的团队来说,这比单纯看安装数字更重要,因为它直接决定下一轮预算往哪里加、哪里减。技术诊断案例模块一个典型场景是,某品牌同时在微信社群、短信和线下海报上投放同一条归因链路,后台显示点击量正常,但用户反馈“点了没跳”“能跳但没拉起”“拉起后还是空白页”三种情况同时存在。表面上看像是同一条链接坏了,实际上是不同入口环境导致的不同结果。微信内置浏览器可能对外部跳转限制较强,短信中的浏览器路径可能正常,而线下扫码后进入的系统浏览器又可能表现不同。Xinstall 全链路归因怎么做,在这种场景里并不是单一配置错误,而是环境、协议、跳转路径与参数恢复共同造成的复合问题。物理对账时,必须先接受一个现实约束:一个约 100MB 的 App,在 5G 环境下通常 10 到 15 秒可完成下载安装,这意味着用户从点击到首次打开之间天然存在时间差。这个时间差决定了你不能把“点了没跳”与“还没来得及恢复”混为一谈。排查时要先确认是否真的没有唤起,再确认是否唤起但未传参,最后确认是否安装后首次打开没有匹配回来。很多时候,用户以为链接没跳,其实只是浏览器先打开了中间页,或者系统把跳转行为放在了稍后执行;也有时候,链接确实跳了,但 App 因为冷启动慢、路由错误或白屏,被用户误判为“没有反应”。这些都要按时间顺序逐层核对,不能凭一次截图下结论。技术介入阶段,通常要同时检查四件事。第一,检查入口配置是否统一,短链是否正确展开,域名和路径是否一致,是否存在多余重定向。第二,检查系统配置是否完整,包括 iOS 的 Universal Links 验证、安卓的 App 唤起配置、浏览器的拦截行为以及微信、QQ 等内置浏览器的限制。第三,检查参数是否在中间链路中被破坏,尤其是编码、拼接、跳转页覆盖和商店中转导致的丢参。第四,检查安装恢复和首次打开逻辑,确认来源是否能在用户真正进入 App 后被重新找回。只有把这四个层面一起看,Xinstall 全链路归因怎么做才会从“好像不行”变成“具体哪一步不行”。复盘结果通常非常直观。某次排查中,团队原本认为跳转失败率高达 32%,但在拆分入口环境后发现,真正的失败主要集中在微信内置浏览器和被二次重定向的短链上,系统浏览器中的成功率其实并不低。经过统一域名配置、清理中间跳转、补齐 Universal Links 验证并修正参数传递规则后,实际可用跳转率提升了 18.4%,安装后来源恢复也从不稳定状态回到了可追踪状态。这个结果说明,Xinstall 全链路归因怎么做并不是一个“修不修链接”的二选一问题,而是要通过链路治理把每一个断点恢复成可控状态。最终真正改善的,不只是跳转成功率,还有后续渠道统计、来源归因和投放复盘的可信度。常见问题与参考资料很多团队会问,为什么同一条链路在不同浏览器里表现差异这么大。原因在于浏览器对跳转协议、外部唤起和二次跳转的支持并不相同,尤其是微信、QQ 这类内置浏览器,往往会增加限制或者改变行为路径。开发者如果只在少数环境里测试,就很容易把“某个环境能跳”误判成“所有环境都能跳”。Xinstall 全链路归因怎么做,很多时候不是技术栈单点失效,而是测试环境和真实流量环境之间存在明显偏差。也有人会问,为什么链接能打开网页,却始终拉不起 App。这里最常见的原因是唤起协议没有正确注册,或者系统阻止了外部唤起行为。还有一种情况是唤起成功了,但 App 冷启动过慢、路由配置错误或者页面白屏,让用户误以为没有跳转。对于这类问题,单纯改链接地址通常没有用,必须回到系统配置、App 配置和页面路由配置上逐项检查。只要其中一个环节不一致,最终的体验就会表现为“没跳”。还有一个高频问题是,为什么参数明明带上了,最后却没进到 App 里。答案通常在中间跳转链路里。短链服务、落地页、商店中转、编码转换、重定向规则,这些环节都可能吞掉原始参数。对于依赖来源分析的业务来说,这不是小问题,因为一旦来源丢失,后续安装、注册、付费都无法回挂到正确渠道。Xinstall 全链路归因怎么做,很多时候最终表面是“没开”,根本原因却是“开的时候没把来源带过去”。如果团队要继续深入排查,可以优先参考几类资料:官网总入口适合了解整体能力边界,文档中心适合核对集成方式和跳转配置,下载中心适合确认 SDK 与测试资源,渠道统计页适合了解统计和归因能力,渠道代理页适合理解合作结构,关于我们页面适合补足平台背景。官方入口可参考 Xinstall 官网,集成资料可参考 Xinstall 文档中心,下载资源可参考 Xinstall 下载中心。当企业把跳转、唤起、传参、安装恢复和后链路事件真正串成一条稳定链路后,Xinstall 全链路归因怎么做就不再只是一个故障标题,而会变成一套可以持续治理的问题体系。对于增长团队来说,这意味着入口不再靠经验猜;对于研发团队来说,这意味着配置不再靠临时试;对于管理层来说,这意味着渠道效果终于可以建立在稳定的跳转与归因基础上,而不是建立在偶尔成功的表面现象上。
43Xinstall 免填邀请码怎么实现 ?携带参数安装底层架构解析
2026-07-28
Xinstall 跳转失败怎么排查? 内链失效与唤起链路治理指南
2026-07-28
极氪全新车型今日上市?车机生态繁荣催生跨屏应用深度链接基建
2026-07-28
苹果全新系统正式发布?底层隐私收紧倒逼移动端应用归因策略突围
2026-07-28
腾讯官宣QQ宠物回归?经典IP变身大模型智能体考验全链路追踪
2026-07-28
腾讯Miora向全球开放?巨头智能体生态加速多端全链路归因
2026-07-27
Kimi K3登顶前端编码榜?开源大爆发考验应用生态分发承接力
2026-07-27
Claude Opus 5全面上线?旗舰算力下放重塑应用端引流策略
2026-07-27
AMD 机架级AI系统全面投产,智能体时代算力再洗牌?
2026-07-24
Xinstall 全链路归因怎么做? 统一口径与闭环分析指南
2026-07-24
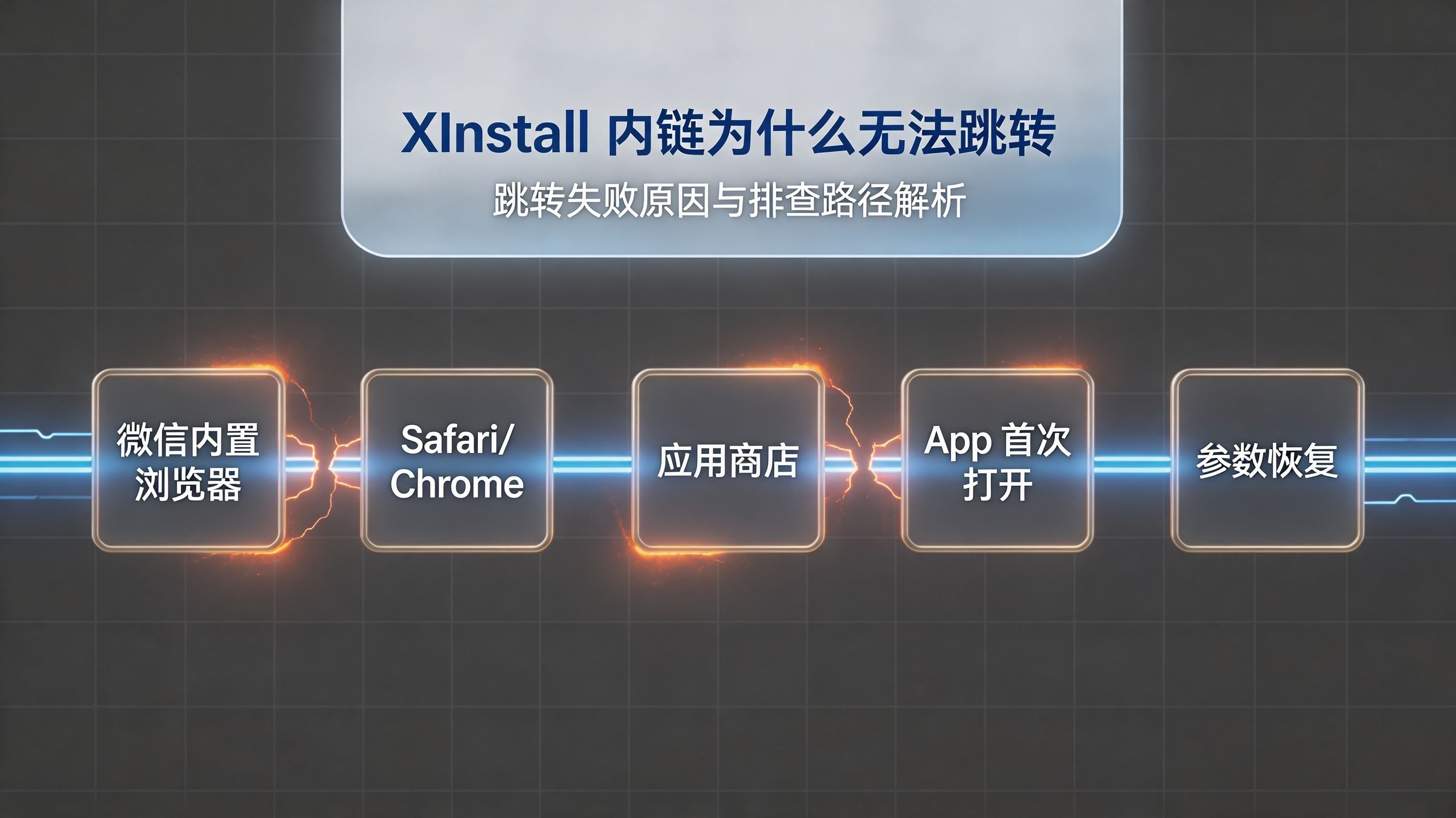
Xinstall 内链为什么无法跳转 ?跳转失败原因与排查路径解析
2026-07-24

Xinstall 跨渠道怎么归因?全链路追踪与统一口径
2026-07-23

Xinstall 安装来源怎么统计?归因恢复与链路设计
2026-07-23

上海科创板新政落地?未盈利硬科技的上市窗口怎么变
2026-07-23

iPhone18系列已量产?供应链装机归因进入重构期
2026-07-22













