






手机微信扫一扫联系客服
联系电话:18046269997



 APP安装免填邀请码
APP安装免填邀请码 社交分享效果统计
社交分享效果统计 广告投放数据统计
广告投放数据统计 CPA/CPS推广效果统计
CPA/CPS推广效果统计 App地推统计
App地推统计 App拉起
App拉起 网页/应用内直接安装
网页/应用内直接安装 Android多渠道打包
Android多渠道打包 App安装后自动绑定
App安装后自动绑定 App分享效果统计
App分享效果统计 Deeplink深度链接
Deeplink深度链接 手机微信扫一扫联系客服
 733
733OpenTelemetry 于 2026 年发布《揭秘 OpenTelemetry》指南,系统阐释其作为可观测性标准与采集框架的角色,澄清“并非监控平台”的误解,并提示这一标准化趋势将重塑复杂分布式系统与 App 全链路归因的数据底座。
2026 年,开源可观测性项目 OpenTelemetry 正式发布《揭秘 OpenTelemetry》全面指南,试图用一份“标准说明书”,为还在摸索中的可观测性实践踩下刹车、按下重排键。这份指南的核心,是把 OpenTelemetry 清晰地定义为一套供应商中立的可观测性标准与采集框架,负责统一生成、采集和传输日志、指标与追踪数据,而不是一个“又多一个监控平台”的产品。对正在维护复杂分布式系统、并试图构建 App 全链路归因能力的团队来说,这既是一份架构参考手册,也是一面照出现有混乱现状的镜子。
指南首先为 OpenTelemetry 正名: 它关注的是“如何生成和传输高质量的遥测数据”,而不是“在哪里存这些数据”。如果你需要一份更偏规范定义的说明,可以查阅 。
在一个典型的可观测性栈里,OpenTelemetry 的角色可以拆成几块:
API 与 SDK:嵌入应用代码,以标准格式发出链路、指标、日志信号。
自动 / 手动仪表化库:为常见语言、框架和中间件自动插桩,减少改代码成本。
Collector(收集器):作为中转站接收遥测数据,进行处理、采样、过滤后再导出到后端。
OTLP 协议与语义约定:定义数据长什么样、字段叫啥、上下文如何在服务间传播。
它不负责存储、查询和告警,这些依然交给 Jaeger、Prometheus、Grafana 或商业平台去做。 用一句话概括:OpenTelemetry 更像是“高速公路和交通规则”,而不是你开的那辆车。
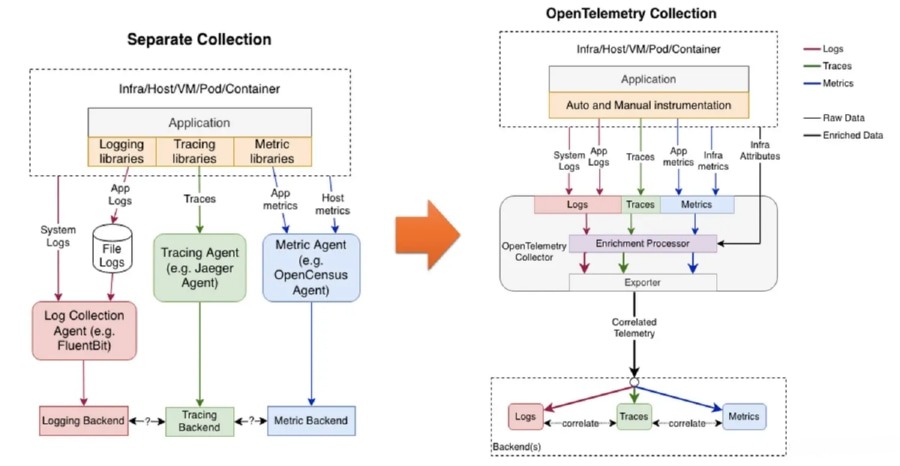
在这种标准化数据管线之上,团队可以更精细地设计自己的 策略,而不是被某一个统计 SDK 的格式和能力限制住。
指南也很直接地拆了几个常见误解:
误解一:“上了 OpenTelemetry 就等于有了可观测性” 事实上,如果没有合理的采样策略、命名规范和服务级目标(SLO),只会换来数据洪水和成本焦虑。
误解二:“导入所有日志/指标/链路就是全面监控” 可观测性的价值不在“多”,而在“有用”,没有筛选和结构的遥测数据,很难支撑真正的决策与定位。
误解三:“采用 OpenTelemetry 必须一次性大改架构” 指南反复强调可以循序渐进:从关键服务开始接入,再逐步扩展到全链路和多环境,而不是一刀切。
换言之,OpenTelemetry 是一套更好的“工具语言”,但要讲出有价值的故事,依然需要团队自己写剧本。
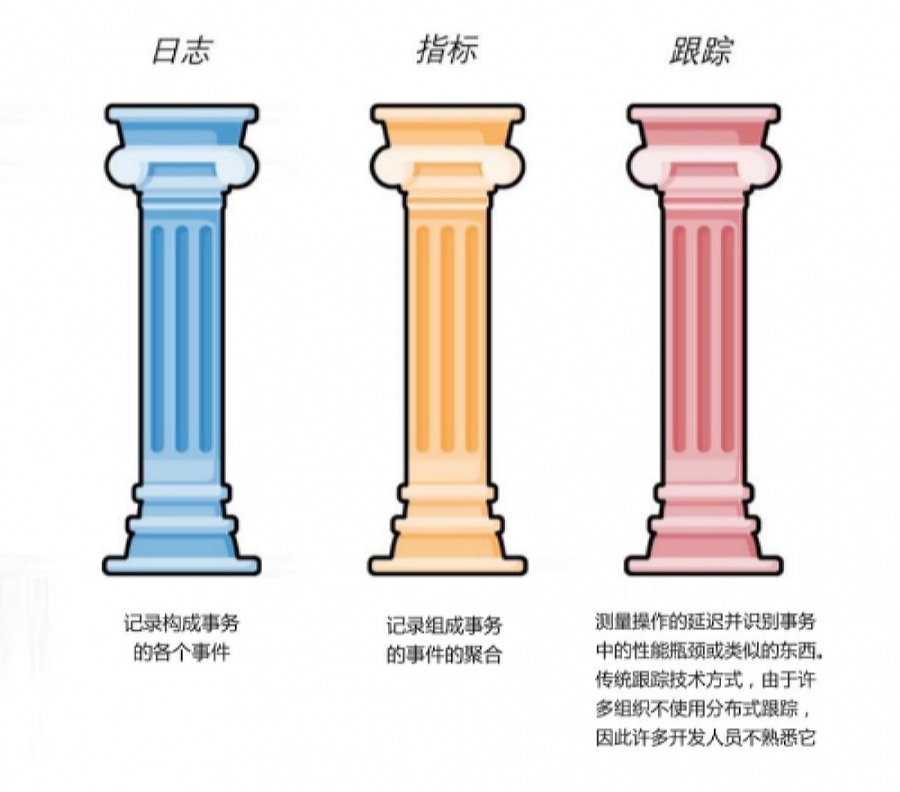
在很多团队的日常里,日志、指标和链路像三个互不往来的世界:
日志是开发和排障时的“回放带”;
指标是运维仪表盘上的“心电图”;
链路是 SRE 高压场景下才会打开的一张“地图”。
OpenTelemetry 的指南希望推动的是一种更完整的“系统叙事”:
日志带上请求上下文和结构化字段,不再只是零散文本;
指标能和具体请求、具体服务的链路挂上钩,而不是孤立的折线图;
链路成为时间轴,把一次请求沿途的日志与指标串起来,讲清楚“发生了什么”。
当这三类信号被同一套标准收束时,你再看系统,就不是在翻滚动的数字,而是在读一个“系统如何应对真实世界流量”的故事。
在 App 侧,这种能力最终会落到 、关键行为追踪和留存路径上:你不只是知道“出问题了”,还知道“是哪一条路径、哪一个人群、哪些动作导致结果变化”。
指南也强调: 真正有效的可观测性,背后一定有一套组织级的共识和流程支撑,而不是“某个团队多装了几个 Agent”。
比如:
团队是否就服务命名、事件命名、错误分类、延迟定义达成过共同标准?
仪表化逻辑是否进入了 CI/CD 流水线,而不是出事之后的“补救工程”?
开发、测试、SRE 是否在同一套遥测数据和视图上对话?
OpenTelemetry 提供的,是一个可以承载这种共识的技术底座: 统一 API、统一协议、统一语义约定,让“怎么看系统”这件事,不再因语言和工具差异而彼此割裂。
对于做 App 的团队来说,这份指南最大的价值不是告诉你“多装一个组件”,而是提醒你: 在多云、多算力、多入口的环境下,要想把增长算清楚,先得把系统看明白。
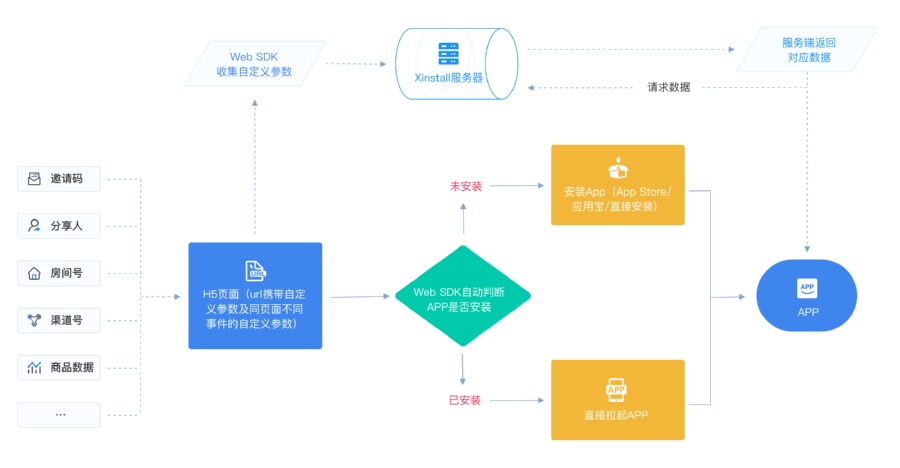
以一条典型的 App 用户路径为例:
用户在某个广告位看到素材 → 点击推广链接 → 落到 H5 或小程序 → 被引导到应用商店或直接一键拉起 App → 完成安装和首次启动 → 触发一系列关键行为事件。
在这条路径上,至少有三类问题需要数据来回答:
入口侧:哪一个广告位、哪种素材、哪个渠道给你带来了这一次访问?
路径中:用户在哪一环节流失,是链接跳转、一键拉起失败,还是安装完成后没有成功打开?
业务端:哪些行为可以被视为“有效转化”,它们和前面的渠道与路径之间是什么关系?
这时,可观测性和归因其实是在同一条链上:
在系统侧,通过 OpenTelemetry 一类标准管线,让每一次调用、每一段延迟、每一个错误都被清晰记录;
在业务侧,通过对事件和渠道命名的统一,比如设计一套稳定的 渠道编号(ChannelCode) 体系,把每一次点击、拉起和安装都绑到一个可追溯的标识上;
然后再在数据产品或归因系统层面,把这些信号转成“从入口到留存”的全链路视图,而不是只看单点报表。
在实践中,安装来源追踪、多端路径还原和多渠道效果评估,会越来越依赖这样的标准化底层;相关方法可以参考你们现有的 方案设计思路。
| 维度 | 传统模式:各自为战的监控堆栈 | 新趋势:以 OpenTelemetry 为核心的统一标准层 | 团队可以怎么做 |
|---|---|---|---|
| 数据采集 | 各系统各用一套 SDK 和 Agent | 用统一 API / SDK / Collector 采集所有遥测信号 | 梳理现有采集方式,规划逐步迁移到统一标准 |
| 数据格式 | 日志、指标、链路字段命名不一致,难以关联 | 通过语义约定统一命名和结构 | 建立跨团队命名规范和字段字典 |
| 工具选型 | 先选工具,再被工具的格式和限制“反锁” | 先定标准,再在标准之上自由组合后端 | 在引入新工具前,先确认是否兼容 OpenTelemetry 生态 |
| App 侧数据闭环 | 埋点、日志、归因、监控各自分离,口径不一 | 有机会在统一遥测标准之上叠加全链路归因与行为分析 | 用更细粒度的 模型统一视角 |
| 渠道识别与对账 | 渠道命名各自为政,对账依赖表格和人力 | 需要在多平台上统一识别口径 | 通过统一的 渠道编号(ChannelCode) 做底层约束 |
| 风险与合规 | 对出口管制与跨境数据合规高度敏感 | 国产栈在本地合规与可控性上更有空间 | 关键业务尽量落在可控范围内,降低单点政策风险 |
这张表想强调的是: OpenTelemetry 不是要推翻你现有的监控和分析系统,而是给你一个“放在所有工具之下”的统一底座,把每一次观察和每一个增长决策,都放在同一套语言与信号之上。
从开发和业务的角度看,这件事至少释放了三层信号:
算力和工具栈会变,但标准越早统一越好 无论未来你是使用自建后端、开源工具,还是某家商业平台,只要底层遥测格式和语义统一,迁移成本和试错成本都会明显降低。
数据与增长架构必须重新设计,而不是“继续堆工具” 当系统跨多云、多算力、多终端运行,原本依赖单一平台统计和粗粒度日志的做法,已经很难支撑精细化增长决策和跨团队协作。
通用工程方法比短期产品选择更重要 无论选用哪种后端,团队都绕不开几件共通的事情:
统一事件和渠道的命名口径(例如用 渠道编号(ChannelCode) 做底层锚点);
把安装来源追踪、路径还原和效果评估看作一条完整的工程管线,而不是三个孤立的功能模块;
在可观测性和增长之间搭起桥梁,让“系统看得见”真正服务于“增长算得清”。
相关概念可以结合 的基础定义一起理解,会更容易把“系统视角”和“营销视角”对齐。
会,但更多是在“顺序和方法”上产生影响。 过去很多团队习惯先选监控工具,再根据工具暴露出来的指标去“拼”可观测性和归因; 现在更合理的路径是:
先用 OpenTelemetry 一类标准统一采集与语义;
再根据这些标准化信号去组合或替换后端工具;
最后在这些信号之上,构建面向业务的归因和增长分析体系。
不会。指南本身就强调: OpenTelemetry 是一套标准与管线,而不是一个后端产品。 它更像是“高速路网”和“交通规则”,你依然可以选择不同的车、不同的导航,只是大家都跑在同一张路网之上。
对你来说,这反而意味着未来切换监控平台、归因平台甚至算力平台的自由度更高,而不是被某个供应商牢牢拴住。
与其急着“全盘重写可观测性和归因系统”,不如先用这份指南倒推你的技术与数据规划:
看看当前系统中,有哪些地方已经在使用 OpenTelemetry 或类似标准,哪些还停留在各自为战的状态;
梳理几条关键业务路径(尤其是 App 从曝光到留存的闭环),评估在“事件命名、渠道标识、上下文传播”这些环节是否已经有统一约定;
在小范围内试点:用统一的 渠道编号(ChannelCode) 和更规范的遥测采集方式,把某条典型业务链路的行为“照亮”,再据此决定下一步投入。
行业动态观察
字节跳动入局自动驾驶会打破车机入口壁垒吗?大模型正将车端系统变为新一代应用触点
2026-07-13

ASA 广告效果分析怎么看?打通苹果归因实时看板
2026-07-13

SKAN 转化值优化如何配置?映射业务事件权重
2026-07-10

OpenAI关停Atlas浏览器?智能体浏览正回流桌面端与扩展层入口
2026-07-10

OpenAI 发布 GPT‑5.6 系列模型?Sol、Terra、Luna 正在重组任务流量
2026-07-10
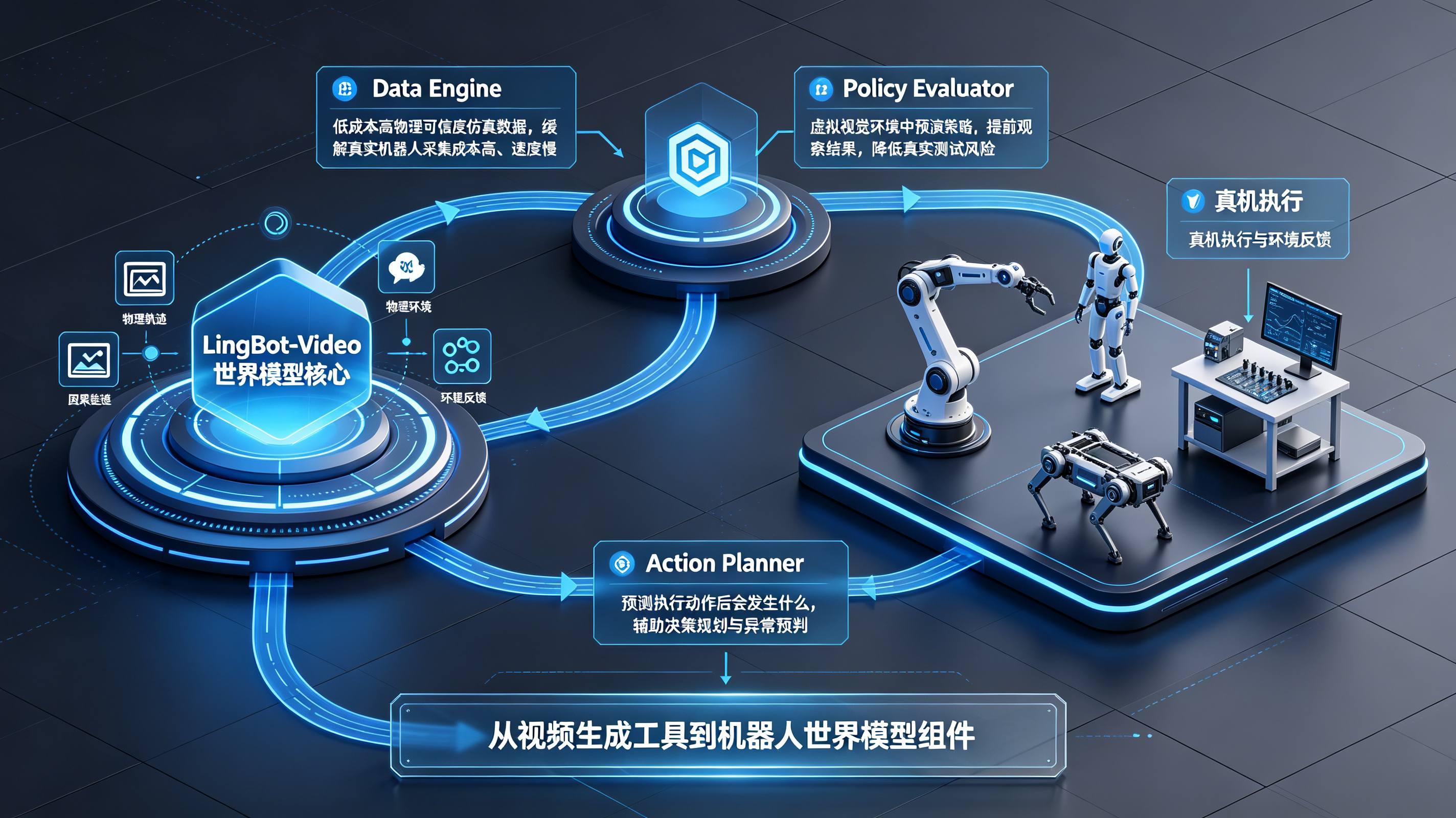
LingBot-Video开源会改写具身视频路线吗?具身智能世界模型正在以物理正确性为核心演进
2026-07-09

支付宝碰一下用户数破4亿会改写线下入口版图?线下AI触点已重组本地生活服务网络
2026-07-09

Grok 4.5发布会让自动化编程爆发?跨平台智能体调用需要独立追踪
2026-07-09

LingBot-Vision开源能解决空间感知?独立自动化追踪成底线
2026-07-08

GPT-5.6发布获美国商务部批准?独立自动化追踪成底
2026-07-08

Claude后门隐患被工信部通报?独立任务流量追踪成底线
2026-07-08

英伟达路线图遭遇产能质疑?底层算力波动倒逼任务流量精细化
2026-07-07

腾讯减持快手改变流量格局?头部生态解绑考验全渠道统计基建
2026-07-07

全球首例AI Agent勒索攻击曝光?AI完全接管黑客链路将如何颠覆生态
2026-07-06

生数科技发布视频大模型Vidu S1?实时交互技术突破或将彻底颠覆内容引流转化
2026-07-06






















