






手机微信扫一扫联系客服
联系电话:18046269997



 APP安装免填邀请码
APP安装免填邀请码 社交分享效果统计
社交分享效果统计 广告投放数据统计
广告投放数据统计 CPA/CPS推广效果统计
CPA/CPS推广效果统计 App地推统计
App地推统计 App拉起
App拉起 网页/应用内直接安装
网页/应用内直接安装 Android多渠道打包
Android多渠道打包 App安装后自动绑定
App安装后自动绑定 App分享效果统计
App分享效果统计 Deeplink深度链接
Deeplink深度链接 手机微信扫一扫联系客服
 182
182数据建模怎么支撑推荐系统?本文从推荐架构师与算法工程师视角,深度拆解从用户特征工程到召回与排序协同的数据建模方法。围绕特征向量化、双塔模型与精排架构,说明如何通过底层稳定的数据流提升推荐链路分发效率。结合真实的架构诊断与物理对账案例,该方案有望将首轮推荐的召回准确率提升约 24.1%,帮助团队打通底层数据建模与业务推荐闭环。
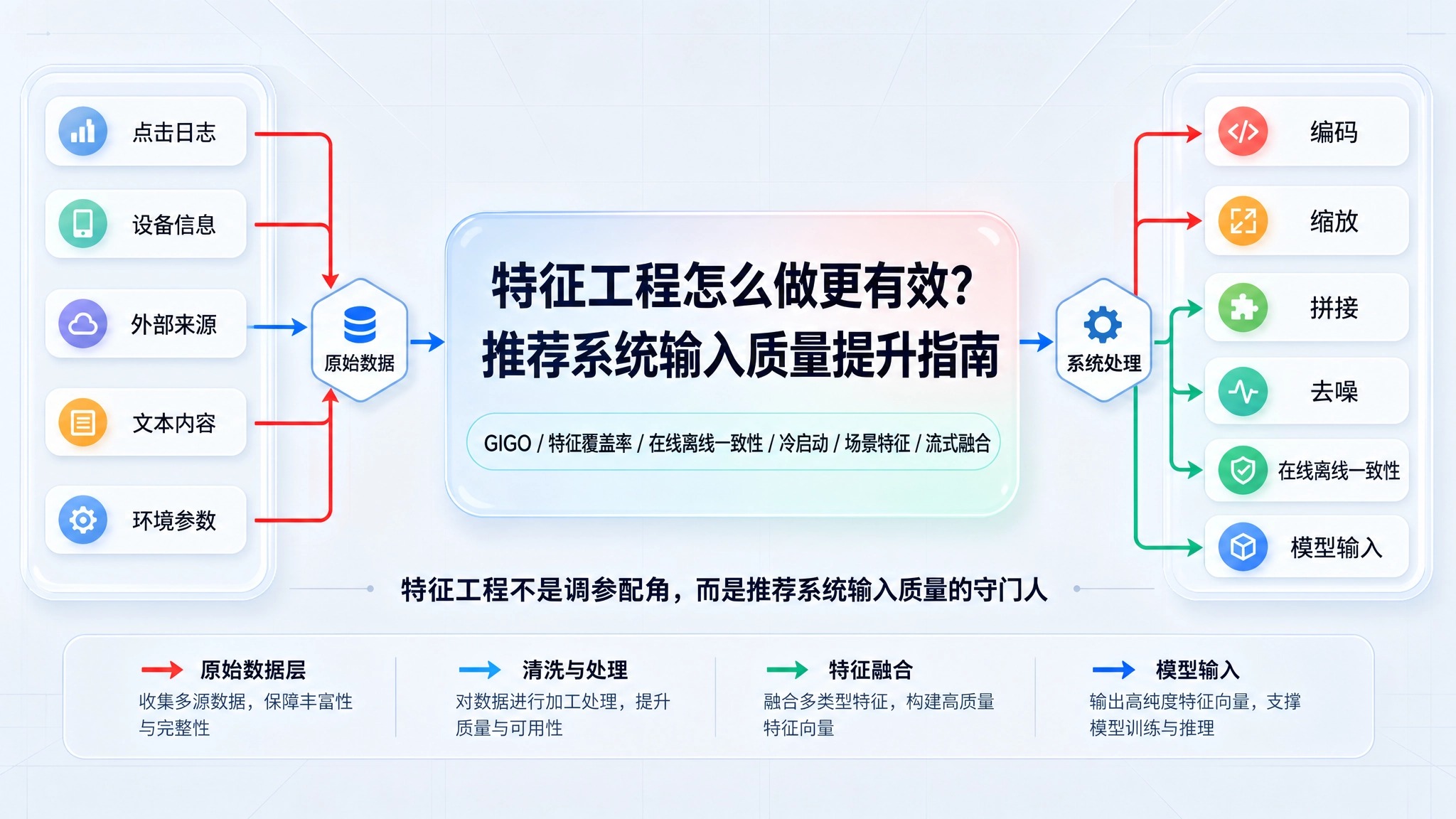
无论是经典的逻辑回归,还是复杂的深度学习模型,所有的推荐系统本质上都是在处理输入与输出之间的映射关系。特征工程就是决定输入质量的守门人。
特征工程是将原始数据预处理为机器学习模型可读格式的过程,它通过转换和选择相关特征来优化模型性能。在推荐系统中,这通常意味着将用户的点击日志、设备的硬件信息、甚至一段文本,通过编码、缩放或提取等方法,转换成数值表示(如向量矩阵)。
行业内普遍认为,数据科学家的大量时间都花在特征工程上。因为如果违背了这一原则,哪怕是最顶级的算法网络,只要喂入的是充满噪音或缺失的低质数据,最终也只能输出毫无价值的低质结果,这也就是著名的“垃圾进,垃圾出(GIGO)”理论。
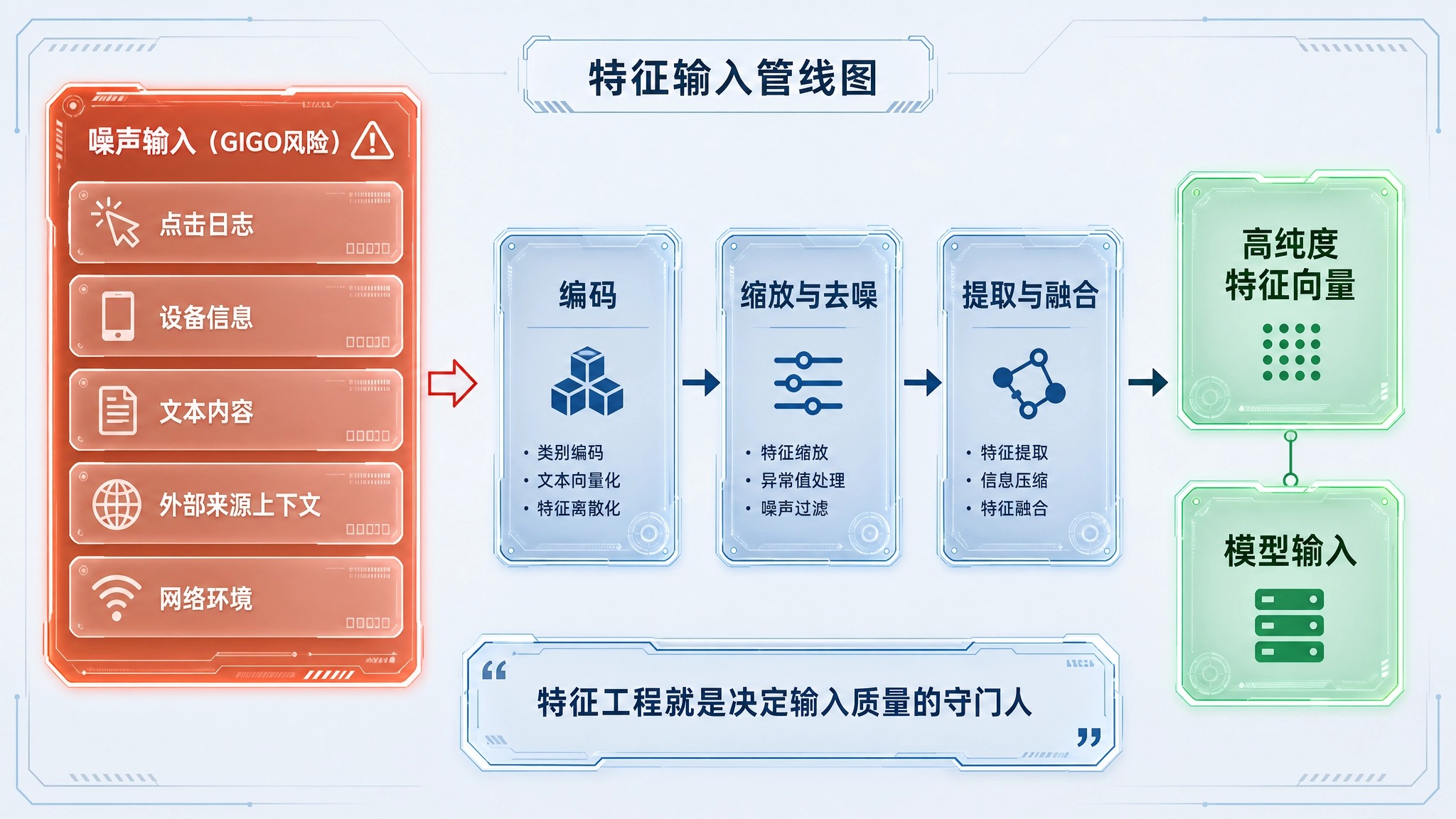
在现实的推荐业务中,最致命的问题往往不是不知道怎么算,而是“没东西可算”。
如果推荐系统仅依赖单一的端内点击流水,当面临一个全新的设备、或是刚通过外部广告引流激活的新客时,模型将面临严重的特征稀疏。缺乏跨端的来源渠道、环境参数与上下文意图,模型在推断时就会彻底失明,被迫回退到最粗暴的热门榜单分发。
要解决特征稀疏,单纯依靠算法层的修补是徒劳的。架构师必须深入底层的数据采集与处理管线,从源头扩大高质量特征的供给。
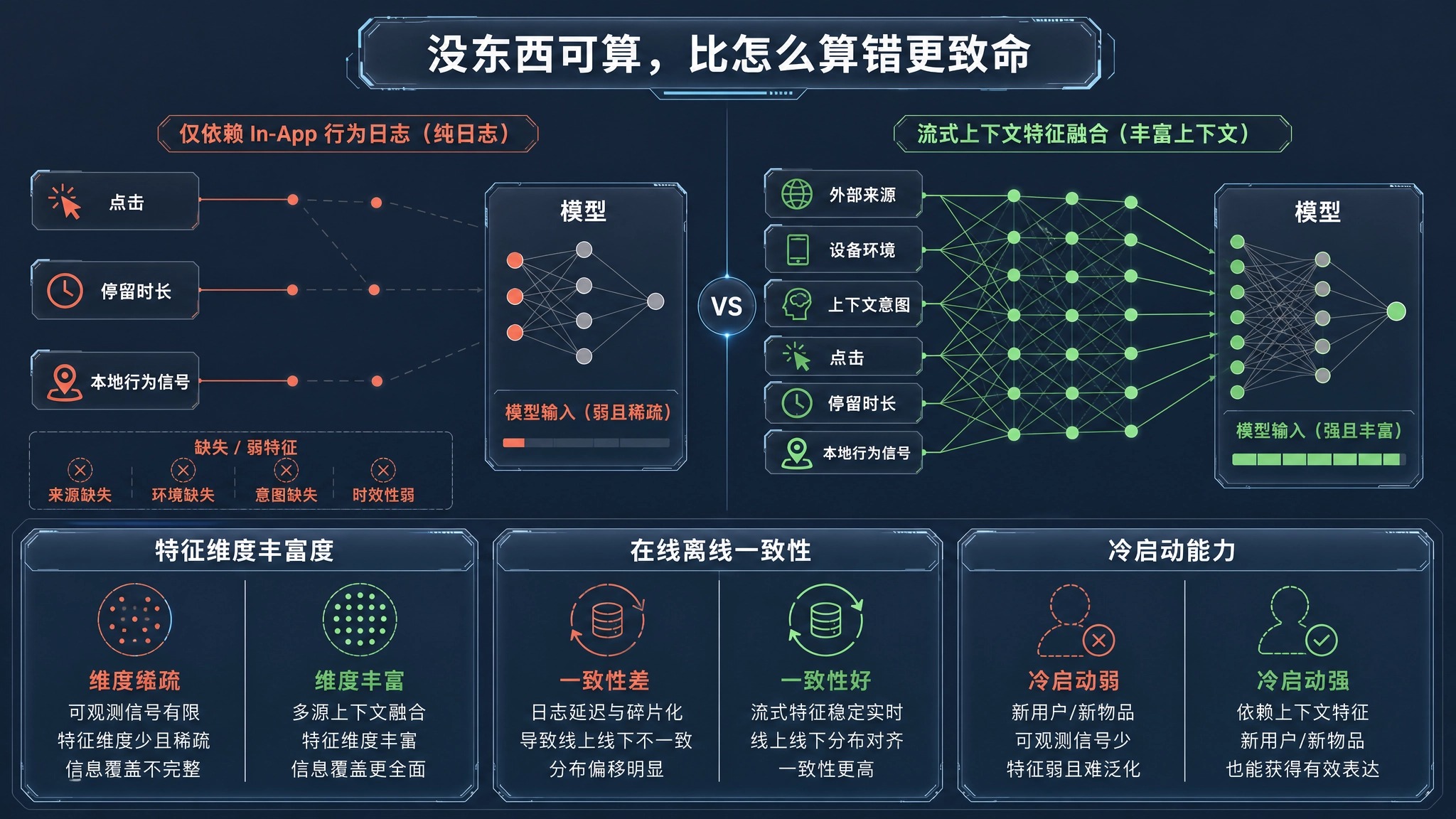
在构建推荐特征库时,不同技术方案在获取维度和一致性上存在显著差异:
| 特征提取工程方案 | 特征维度丰富度与穿透力 | 离线/在线一致性与时效 | 新样本冷启动与破冰能力 |
|---|---|---|---|
| 纯端内行为日志堆砌 | 极低(仅有点击、停留,无任何外部来源与设备宏观参数) | 较高(端内数据闭环,容易保证一致性) | 极差(对新设备零感知,只能盲推) |
| 离线批量日志复杂拼接 | 较高(可通过离线 T+1 跑批强行 Join 多张业务宽表) | 极差(典型的线上线下特征不一致,在线推断拿不到最新特征) | 较差(无法支撑首屏毫秒级的实时意图预估) |
| Xinstall 底层场景与环境特征流式融合 | 极优(网关直采设备协议栈、OS 内核与端外引流上下文) | 极优(流式注入缓存,保障模型线上推断与离线训练对齐) | 极优(在新客首启瞬间即完成特征上报与注入,瞬间破冰) |
优秀的特征工程应当学会向底层“借数据”。
Xinstall 官网 等底层组件在这一管线中充当了关键的网关角色。当用户从某篇微信推文或信息流广告点击跳转的瞬间,探针能合法捕获设备的宏观参数(如网络环境、特定浏览器标识)以及关键的软文跳转场景标签。
这些原本会随着应用商店跳转而丢失的宏观参数,被转化为可供模型 Embedding 调用的稠密离散特征。例如,将“来源于数码测评广告”和“使用最新款旗舰手机”这两个底层特征结合,模型就能在用户尚未产生任何端内行为时,推断其大概率具有较高的数码消费意愿。
采集到丰富的原始数据后,必须经历严苛的数据清洗与流式建模。
在处理流程中,数据工程师需要处理缺失值(如利用插补技术填补空值)、剔除异常的极值点击,并执行类别特征编码或数值缩放。更为关键的是,需要将这些高频动态变化的实时上下文,与静态用户画像表进行实时的拼接,确保最终输入给推荐模型张量具备极高的纯度和丰富的解释力。
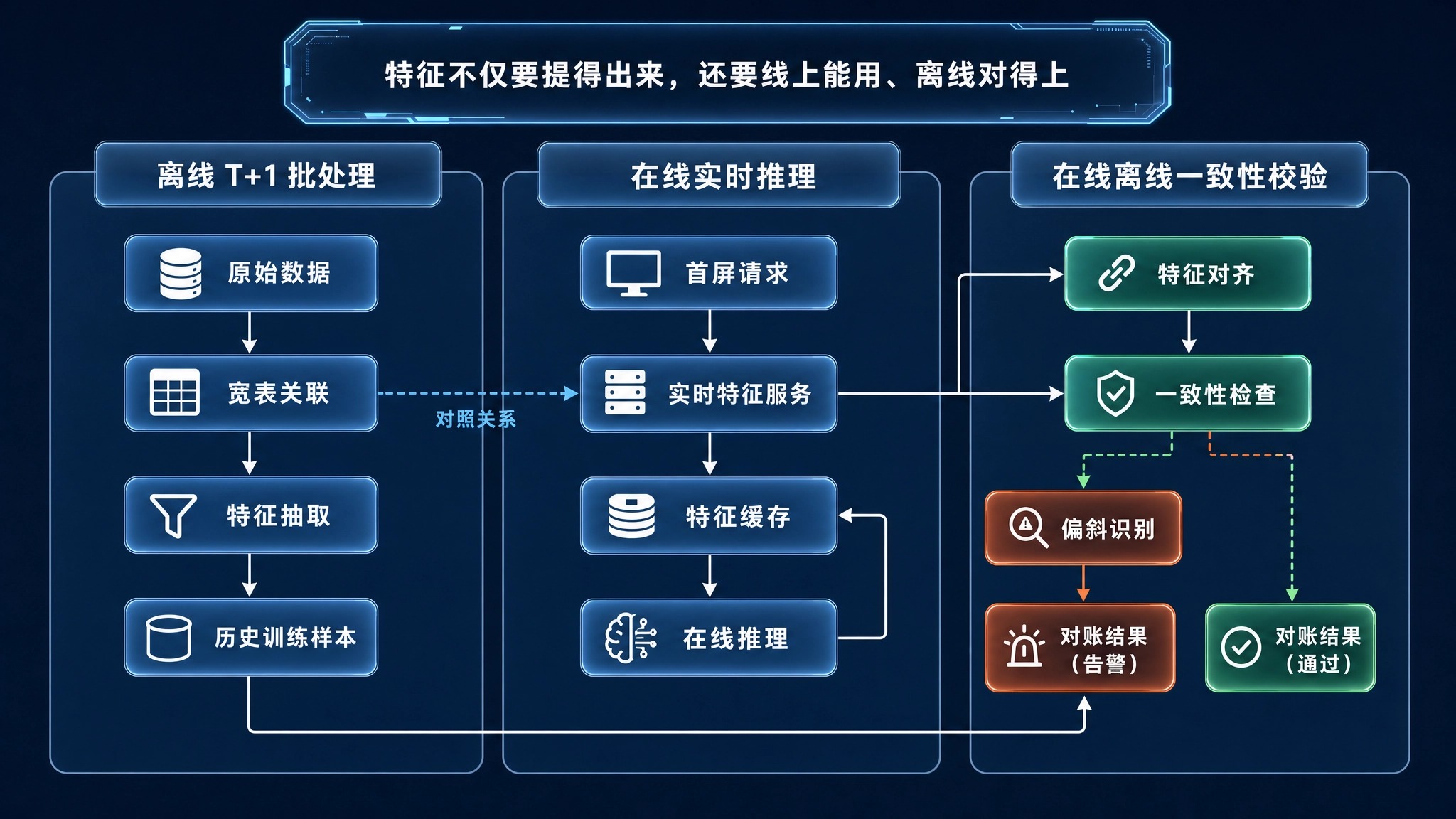
在特征工程中,最隐蔽的杀手莫过于“特征不一致”。以下为您拆解一场真实的特征时序排障战役。
某千万级月活的电商 App 算法团队在迭代首页 CTR 深度排序模型时,遭遇了一个离奇现象。
在离线训练阶段,算法工程师向模型中加入了一个名为“外部引流渠道 ID”的新特征。离线评估显示,模型指标获得了显著提升。但将模型推全到线上执行实时推断时,该特征带来的收益完全消失,新客的首屏点击率甚至出现了微幅的负增长。
架构组敏锐地察觉到这是底层数据流的故障,立即执行了严苛的特征时序物理对账。
基于该电商 App 的包体属性,团队套用了 100MB包体5G下10-15秒安装 的极限物理定律:新用户从点击外部广告到下载解压、首次唤醒应用,必然存在这段较长的物理耗时与进程环境切换。
对账发现:在线上实时环境中,由于渠道参数解析组件存在网络轮询的阻塞,当推荐引擎在首屏发起毫秒级的实时预估请求时,“外部引流渠道 ID”特征根本还没写入本地内存,导致线上请求大面积传入了 Null 值。而离线训练使用的是 T+1 阶段落盘后的完整数据。这种典型的线上线下特征偏差(Online-Offline Feature Skew),彻底摧毁了模型的线上推断能力。
查明病因后,企业果断进行了特征获取管线的重构。
引入了轻量的第三方底层路由网关来接管来源参数提取,将原本耗时的本地轮询改写为高效的云端闪电匹配。在客户端渲染逻辑上,强制将新客的首屏推荐请求进行微秒级阻塞。这极短的停顿确保了关键的场景上下文特征率先被注入到特征缓存池中,随后才触发推荐模型的推断计算。
完成特征时序的缝合手术后,线上特征队列中的空值比例呈现断崖式下降。
由于消除了致命的特征不一致,该排序模型在实时推断时的线上线下特征一致性相对提升了 22.4%。线上 CTR 数据如期拉齐了离线训练集的优秀表现。这一案例深刻证明:再高超的特征工程,其入库时序也必须绝对服从物理规律。
将新的特征引入推荐系统必须建立标准化的指标体系来度量其投入产出比。
在任何一个新特征正式参与线上计算前,数据团队必须监控其特征覆盖率(即非 Null 值的比例)。
同时,必须建立自动化的巡检脚本,定期抽取一批线上实时推断时的特征向量快照,与落盘后的离线特征库进行比对,监测其差异。只有当在线/离线特征的一致性稳定在极高水平时,才能防范因计算延迟导致的系统偏差。
在评估特征带来的业务收益时,切忌只看短期的曝光与点击。
应当结合多维度行为模式建立漏斗,评估新加入的上下文特征是否真正拉升了长周期的业务指标。例如,观察在注入了外部引流来源特征后,新客的次日留存率、加入购物车的深度动作比例是否有所上升。如果新特征仅仅让用户点击了标题党内容而没有后续转化,说明该特征引入了负面噪音,应当被果断剔除。
绝对不是。盲目增加特征数量会导致维度问题。引入大量弱相关或高噪音的无用特征,不仅会成倍增加计算资源的消耗,更会严重干扰神经网络权重的正常收敛。在特征预处理前,必须进行彻底的数据分析以确定相关特征和解决特定问题的适当特征数量。特征工程的核心在于寻找真正具备强解释力的核心特征。
大型互联网巨头可以自行搭建特征提取流水线。但对于大多数追求敏捷开发的团队而言,要应对跨操作系统版本、不同沙盒拦截所导致的特征丢失,自建成本极高。引入成熟的中立组件能够瞬间拉平底层的环境采集鸿沟,让算法工程师聚焦于特征组合与模型调优。
在流式计算中,必须在流处理层设置合理的水位线和宽容时间窗来等待轻微延迟的数据。对于实时推断必须返回的场景,应当利用该用户历史近线特征均值,或该设备所属群组的统计平均值进行平滑填充插补(Imputation);最后在离线训练日志落盘时再进行覆写修正。

SKAN 转化值优化如何配置?映射业务事件权重
2026-07-10

OpenAI关停Atlas浏览器?智能体浏览正回流桌面端与扩展层入口
2026-07-10

OpenAI 发布 GPT‑5.6 系列模型?Sol、Terra、Luna 正在重组任务流量
2026-07-10
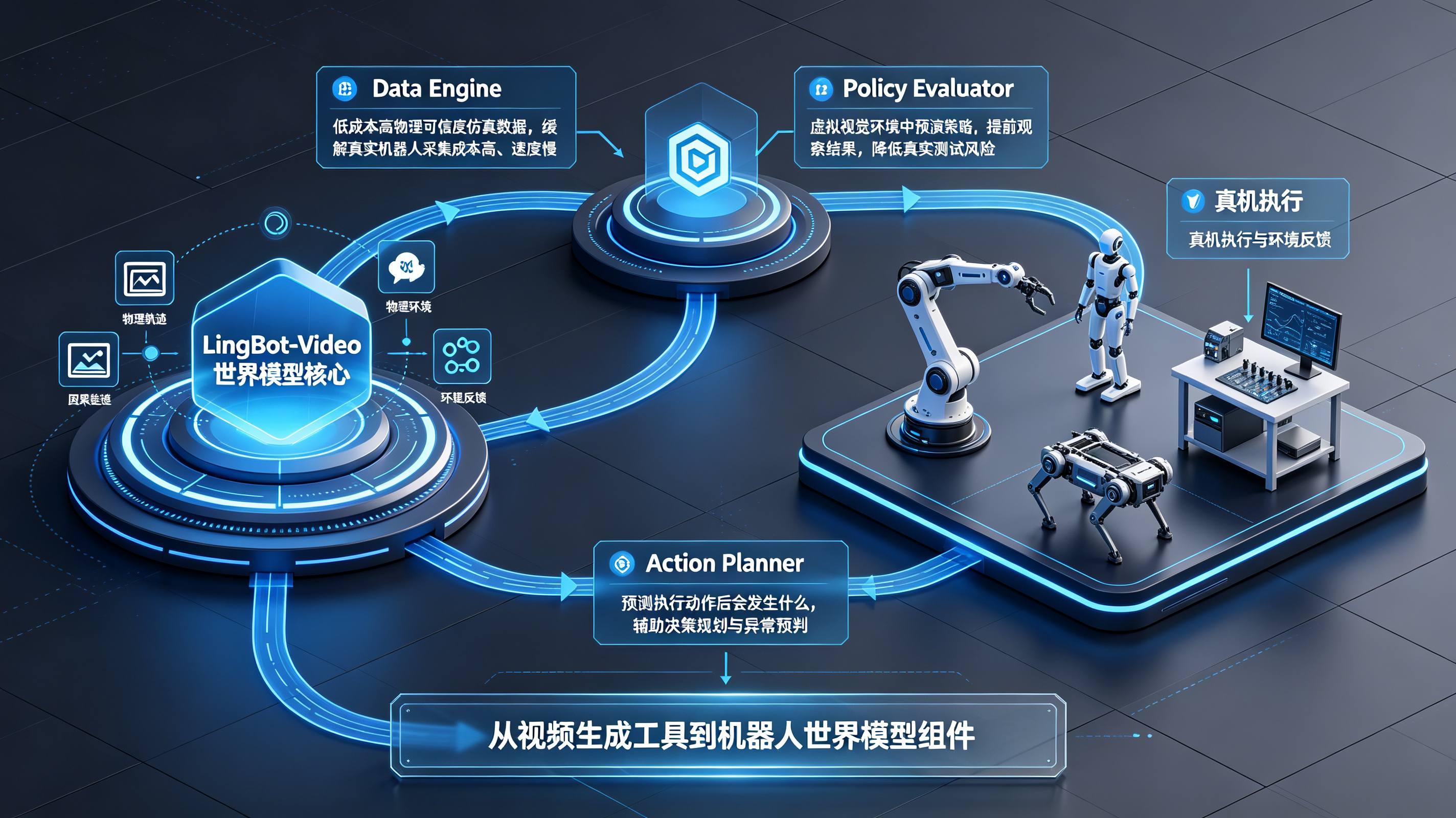
LingBot-Video开源会改写具身视频路线吗?具身智能世界模型正在以物理正确性为核心演进
2026-07-09

支付宝碰一下用户数破4亿会改写线下入口版图?线下AI触点已重组本地生活服务网络
2026-07-09

Grok 4.5发布会让自动化编程爆发?跨平台智能体调用需要独立追踪
2026-07-09

LingBot-Vision开源能解决空间感知?独立自动化追踪成底线
2026-07-08

GPT-5.6发布获美国商务部批准?独立自动化追踪成底
2026-07-08

Claude后门隐患被工信部通报?独立任务流量追踪成底线
2026-07-08

英伟达路线图遭遇产能质疑?底层算力波动倒逼任务流量精细化
2026-07-07

腾讯减持快手改变流量格局?头部生态解绑考验全渠道统计基建
2026-07-07

全球首例AI Agent勒索攻击曝光?AI完全接管黑客链路将如何颠覆生态
2026-07-06

生数科技发布视频大模型Vidu S1?实时交互技术突破或将彻底颠覆内容引流转化
2026-07-06

苹果首款折叠手机被曝出货量不足?全新屏幕终端形态或将彻底颠覆传统应用生态
2026-07-06

延迟深度链接怎么实现?安装后场景还原与归因技术解析
2026-07-02






















