






手机微信扫一扫联系客服
联系电话:18046269997



 APP安装免填邀请码
APP安装免填邀请码 社交分享效果统计
社交分享效果统计 广告投放数据统计
广告投放数据统计 CPA/CPS推广效果统计
CPA/CPS推广效果统计 App地推统计
App地推统计 App拉起
App拉起 网页/应用内直接安装
网页/应用内直接安装 Android多渠道打包
Android多渠道打包 App安装后自动绑定
App安装后自动绑定 App分享效果统计
App分享效果统计 Deeplink深度链接
Deeplink深度链接 手机微信扫一扫联系客服
 693
693DeepSeek V4 被曝在发布前未向英伟达开放预发布版本,而是优先给华为等国产芯片测试,折射出算力主场的悄然迁移,也将影响未来多算力环境下的 App 增长规划与数据归因策略。
与此同时,围绕 V4 本身的技术细节也在陆续曝光。多方信息显示,DeepSeek 已启动代号为 “sealion-lite” 的 V4 预览版闭门内测,参与厂商需签署严格保密协议。据透露,V4 Lite 拥有约 100 万 tokens 的上下文窗口,支持原生多模态架构,在复杂代码理解、长文本分析以及矢量图生成等任务上的表现,显著优于当前主流在线模型。业内普遍推测,完整版 V4 极有可能是一款万亿参数级旗舰模型,其训练规模与部署成本都远超前代。
过去很长一段时间里,AI 行业有一条几乎写进默契里的规则:
新一代旗舰模型发布前,开发团队会先向 NVIDIA、AMD 等头部芯片厂商提供预发布版本;
由这些厂商在自家 GPU 平台上完成性能调优和生态适配;
等主流云环境跑顺了,再轮到其他芯片和云平台跟进。
DeepSeek 的早期模型同样扎根于 CUDA 生态,与英伟达技术团队有过紧密合作。 而在这一次 V4 的分发策略中,多家媒体都指出了明显不同:预发布阶段不再优先开放给 NVIDIA 和 AMD,而是把提前数周的测试与调优窗口留给了华为等国产算力供应商。
对国内芯片厂商而言,这是一次难得的“提前起跑”; 对整个生态而言,这意味着:
“旗舰模型先跑在哪一类算力上” 这件事,第一次出现了实质性的优先级重排。
从目前披露的信息看,V4 不只是一个“象征性节点”,而是一颗规格非常激进的工程级模型:
预览版 V4 Lite(代号 sealion-lite)已经面向部分合作伙伴开启闭门测试;
支持约 100 万 tokens 的上下文窗口,可以在一次推理中处理完整代码仓库、复杂长文档甚至多轮业务对话;
采用原生多模态架构,对复杂图形、结构化数据与文本混合任务有更强的理解与生成能力;
完整体 V4 被广泛猜测为万亿参数级模型,训练和推理成本都将是上一代的量级升级。
这类模型一旦真正落地到业务场景,最先改变的不是宣传话术,而是几件很具体的能力边界: 团队可以在一次对话中塞进完整的用户旅程、全链路日志和关键业务配置,让模型在更接近真实世界的上下文里做推理和建议,而不再只是“回答孤立的问题”。
在多算力、多平台并存的环境中,“用户从哪来”会变得更难也更关键:
原来只需在单一广告平台或统计工具里看安装量,现在要同时面对不同云、不同芯片、不同端形态的数据差异;
入口从应用商店扩展到微信、小程序、H5 落地页、短信链接、二维码海报等多种形态,传统的“总量维度”已经不足以支撑决策。
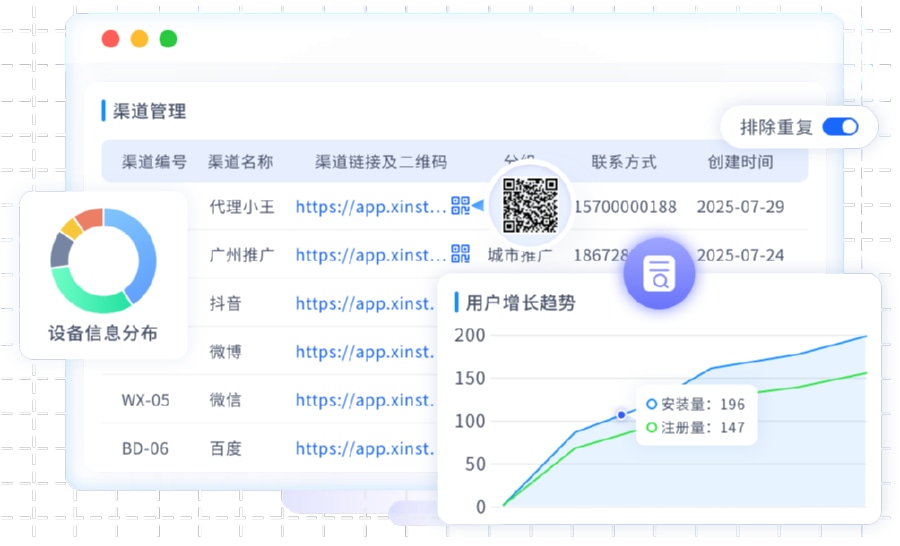
这意味着,团队需要尽早搭建更精细的安装与来源追踪体系,例如:
在客户端和服务端,对“安装来源追踪、用户来源追踪、投放渠道追踪、推广渠道统计”做更细颗粒度的记录;
在数据层面,对不同来源的日志进行清洗与标准化,避免在多平台环境下出现口径撕裂。
在实践中,一个常见做法,是设计一套统一的 渠道编号(ChannelCode) 体系,让每一次点击、每一次拉起、每一次安装都被绑定到一个唯一编号上,后续的归因、对账和效果分析才有可靠的锚点。
当应用的入口从单一 App Store,变成:
微信、小程序、企业微信
H5 落地页、短信链接、邮件链接
线下二维码、门店海报、展会扫码
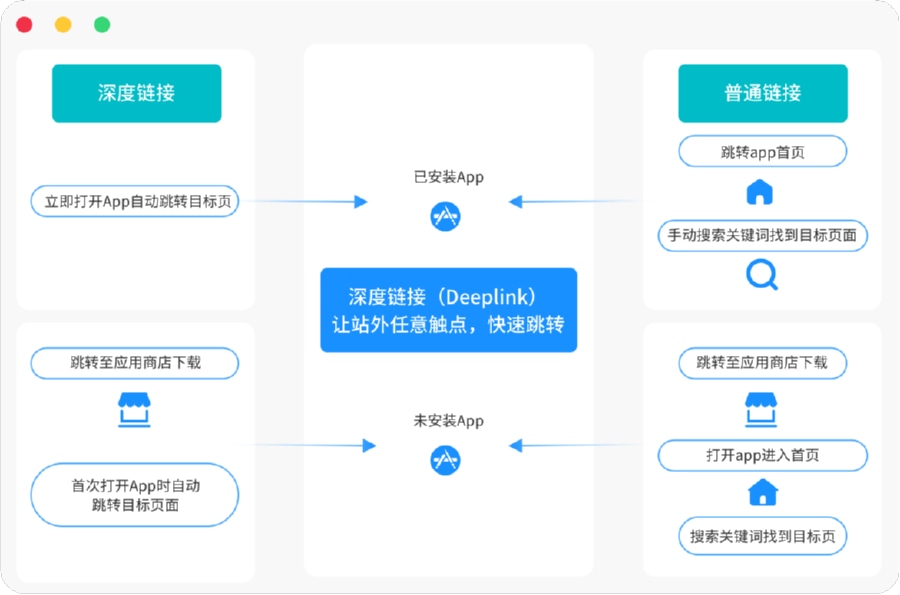
要想还原用户真实路径,只看安装量已经远远不够。 典型的工程组合通常包括:
深度链接、iOS Universal Links、App Links 等跨端跳转机制;
安装时的参数传递和一键拉起能力,用来在“点击 → 打开 → 安装 → 首次启动”这条链路上尽量减少信息丢失;
面向 H5、微信生态、二维码等不同入口的渠道统计和行为追踪。
真正的挑战在于: 要在不同算力栈和不同云环境下,仍然保证这些链路行为都能被准确记录和还原,而不是因为部署位置改变,就导致一半数据丢失或者对不上。
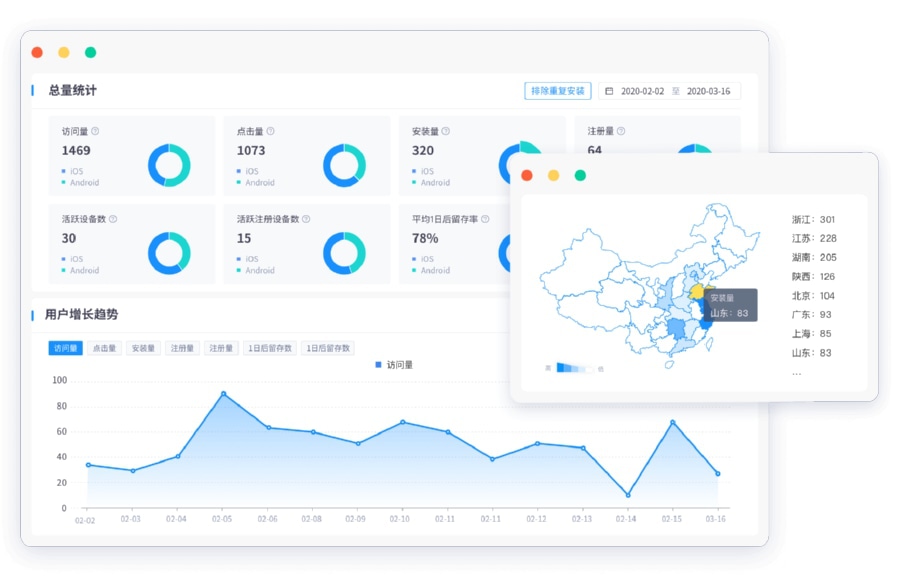
在多平台、多算力并行的架构下,数据的可信度会面对两类噪音:
自然噪音:日志延迟、埋点不一致、渠道上报不齐等;
人为噪音:虚假点击、刷量安装、归因劫持等。
这也是为什么,越来越多团队会在增长与数据系统中:
引入更精细的效果归因和多渠道对比分析,避免单一平台“说了算”;
配置反作弊、广告欺诈检测、异常流量识别、安装作弊识别等机制,对数据进行持续“清洗”;
在关键链路中叠加一定的“参数还原与行为还原”模型,尽可能从多源信号中还原出真实的转化来源。
没有这些“底层清洁工”,再强的大模型和再便宜的算力,最终都只会让报表变得“虚胖”。
| 维度 | 传统模式:美芯+美模 | 新趋势:国产模+国产芯 | 团队应对思路 |
|---|---|---|---|
| 模型适配顺序 | 旗舰模型优先适配 NVIDIA/AMD | V4 等旗舰模型优先适配华为等国产芯片 | 技术规划中引入“多算力栈”思路 |
| 部署位置 | 以海外云为主,本地部署有限 | 国产云、本地集群可行性提升 | 为本地部署和国产云预留架构空间 |
| 数据与归因 | 强依赖平台黑盒数据和单一统计工具 | 有机会在本地构建自有数据与归因系统 | 规划统一统计与归因能力,而非完全依赖平台侧 |
| 拉新链路 | 单一入口为主,跨端链路较少 | 多入口、多端触点成为常态 | 设计跨端的埋点与路径还原机制 |
| 渠道识别与对账 | 渠道命名各自为政,对账依赖表格和人力 | 需要在多平台上统一识别口径 | 通过统一的 渠道编号(ChannelCode) 做底层约束 |
| 风险与合规 | 对出口管制与跨境数据合规高度敏感 | 国产栈在本地合规与可控性上更有空间 | 关键业务尽量落在可控范围内,降低单点政策风险 |
从开发和业务的角度看,这件事至少释放了三层信号:
算力主场在悄悄迁移 旗舰模型不再“默认先适配英伟达”,而是把国产算力平台拉到了第一排,这会直接影响未来 1–3 年在训练、推理和部署上的技术选型和成本结构。
数据与增长架构必须重新设计 当模型和算力开始“双栈并行”(海外平台 + 国产平台),原本高度依赖单一平台统计的做法,很难保证在所有环境下都有稳定、可对账的数据闭环。
通用工程方法比具体产品更重要 无论使用哪家大模型或算力平台,最终都绕不开几件事:用户从哪里来、链路有没有断、数据能不能信。这些问题背后,对应的是安装来源追踪、跨端路径还原和多渠道效果评估等一整套工程方法,而不是某一个单一工具或品牌。
现有信息主要集中在“谁先拿到预发布版本、谁先做底层优化”,并不意味着 V4 会被锁定在某一家云或某一类芯片上。 对大多数团队来说,更现实的变化是:
国产云和本地集群上的 V4 性能与成本,会更早通过实战被打磨成熟;
海外云依然会是重要选项,只是从“唯一主栈”变成“多主栈之一”,需要在架构层面对多平台做更多预案。
短期内很难。高端 GPU 在大规模训练和极端性能场景中依然不可替代。 更现实的变化在于:
旗舰模型不再理所当然地“先适配英伟达”,国产算力在适配顺位上的优先级被抬升;
对企业来说,最理性的做法,是在训练、推理、线上服务这些环节,分别评估不同算力栈的性价比和风险,而不是押注单一平台。
与其急着“全盘换栈”,不如先用这次事件倒推你的技术与数据规划:理清当前对单一算力平台的依赖程度,在小范围内验证国产算力环境下的部署与数据质量,并逐步用统一的 渠道编号(ChannelCode) 和清晰的归因逻辑,把增长数据牢牢掌握在自己手里。
行业动态观察
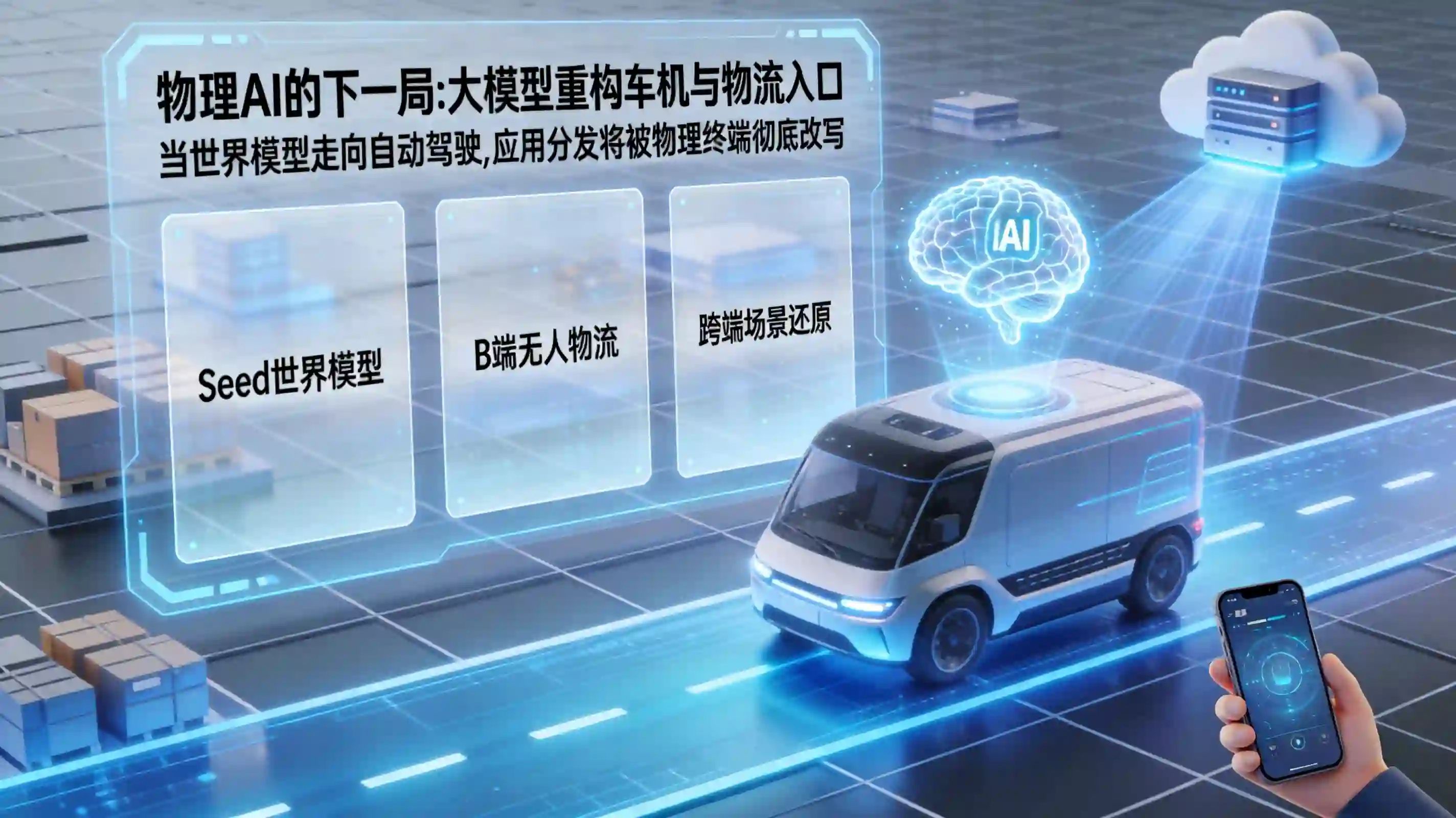
字节跳动入局自动驾驶会打破车机入口壁垒吗?大模型正将车端系统变为新一代应用触点
2026-07-13

ASA 广告效果分析怎么看?打通苹果归因实时看板
2026-07-13

SKAN 转化值优化如何配置?映射业务事件权重
2026-07-10

OpenAI关停Atlas浏览器?智能体浏览正回流桌面端与扩展层入口
2026-07-10

OpenAI 发布 GPT‑5.6 系列模型?Sol、Terra、Luna 正在重组任务流量
2026-07-10
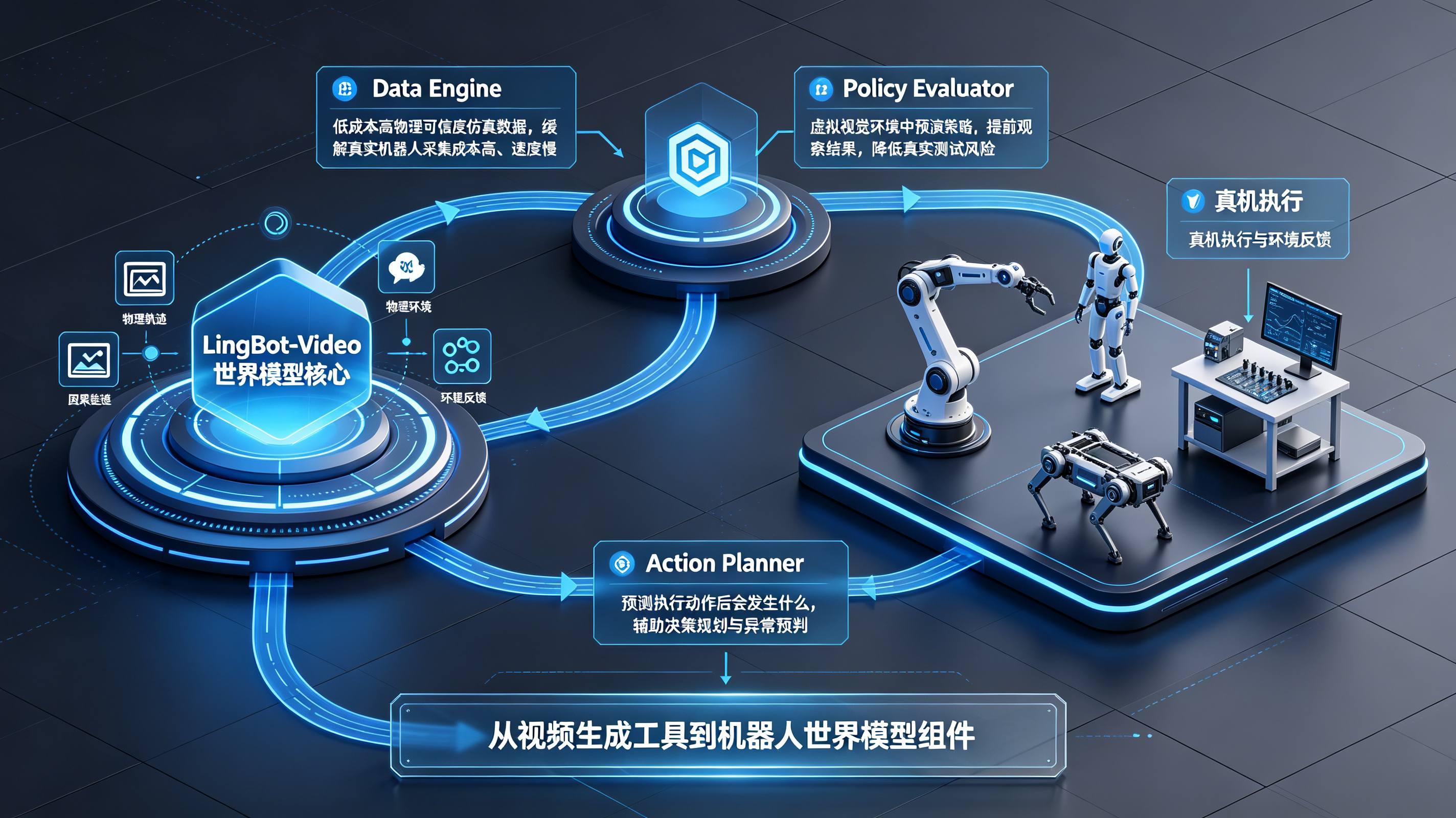
LingBot-Video开源会改写具身视频路线吗?具身智能世界模型正在以物理正确性为核心演进
2026-07-09

支付宝碰一下用户数破4亿会改写线下入口版图?线下AI触点已重组本地生活服务网络
2026-07-09

Grok 4.5发布会让自动化编程爆发?跨平台智能体调用需要独立追踪
2026-07-09

LingBot-Vision开源能解决空间感知?独立自动化追踪成底线
2026-07-08

GPT-5.6发布获美国商务部批准?独立自动化追踪成底
2026-07-08

Claude后门隐患被工信部通报?独立任务流量追踪成底线
2026-07-08

英伟达路线图遭遇产能质疑?底层算力波动倒逼任务流量精细化
2026-07-07

腾讯减持快手改变流量格局?头部生态解绑考验全渠道统计基建
2026-07-07

全球首例AI Agent勒索攻击曝光?AI完全接管黑客链路将如何颠覆生态
2026-07-06

生数科技发布视频大模型Vidu S1?实时交互技术突破或将彻底颠覆内容引流转化
2026-07-06






















