






手机微信扫一扫联系客服
联系电话:18046269997



 APP安装免填邀请码
APP安装免填邀请码 社交分享效果统计
社交分享效果统计 广告投放数据统计
广告投放数据统计 CPA/CPS推广效果统计
CPA/CPS推广效果统计 App地推统计
App地推统计 App拉起
App拉起 网页/应用内直接安装
网页/应用内直接安装 Android多渠道打包
Android多渠道打包 App安装后自动绑定
App安装后自动绑定 App分享效果统计
App分享效果统计 Deeplink深度链接
Deeplink深度链接 手机微信扫一扫联系客服
 199
199智能推荐系统如何平稳度过冷启动期?本文从数据架构师的视角探讨原始端外采集数据在推荐算法中的核心价值。深度解析协同过滤与Embedding的局限,剖析如何通过Xinstall底层归因特征加速构建初始用户画像。此方案能有效重塑冷启动的算法权重,有望在无历史行为的情况下提升首日核心推荐精准度约 18.7%,快速构建商业增长闭环。
在深度学习与大规模分布式计算普及的今天,现代推荐架构(如双塔模型 DSSM、Wide & Deep 等)在处理海量行为日志时表现出了惊人的效率。然而,所有依赖历史序列的模型都面临着一个无法从纯算法层面绕开的数学死结:冷启动(Cold Start)。当一个全新用户首次打开应用,其端内行为日志为空,系统无法构建有效的交互矩阵。
传统的推荐系统高度依赖协同过滤(Collaborative Filtering)机制。无论是基于用户(User-CF)还是基于物品(Item-CF)的矩阵分解技术,其核心逻辑均是通过计算向量点积或余弦相似度来寻找相似偏好。
在无历史行为的冷启动期,新用户的行为向量是一个全零矩阵。从代数角度来看,任何向量与全零向量的内积均为零,这意味着协同过滤算法在这一阶段彻底失效。系统无法计算出该用户与历史池中任何节点或内容的相似度,导致深度神经网络在召回层(Recall)即陷入瘫痪,无法向排序层(Ranking)输送有效候选集。
在协同过滤失效的客观前提下,大多数智能推荐系统的兜底策略是被动修改算法权重,将所有的流量分配给“全局热门内容”或“高转化率基础内容”。
这种策略虽然保证了界面的内容填充,但会导致严重的意图泛化问题。对于那些受特定垂直类广告(如“硬核科幻游戏”、“小众垂类社交”)吸引而来的用户,如果在首次打开时看到的是泛娱乐的热门信息,其心理预期将受到严重挫败。这种初期算法权重失衡,是导致新用户次日留存率断崖式下跌的底层元凶。因此,破局的关键不在于改进端内算法,而在于将数据漏斗向上游延伸,捕获安装前的隐性特征。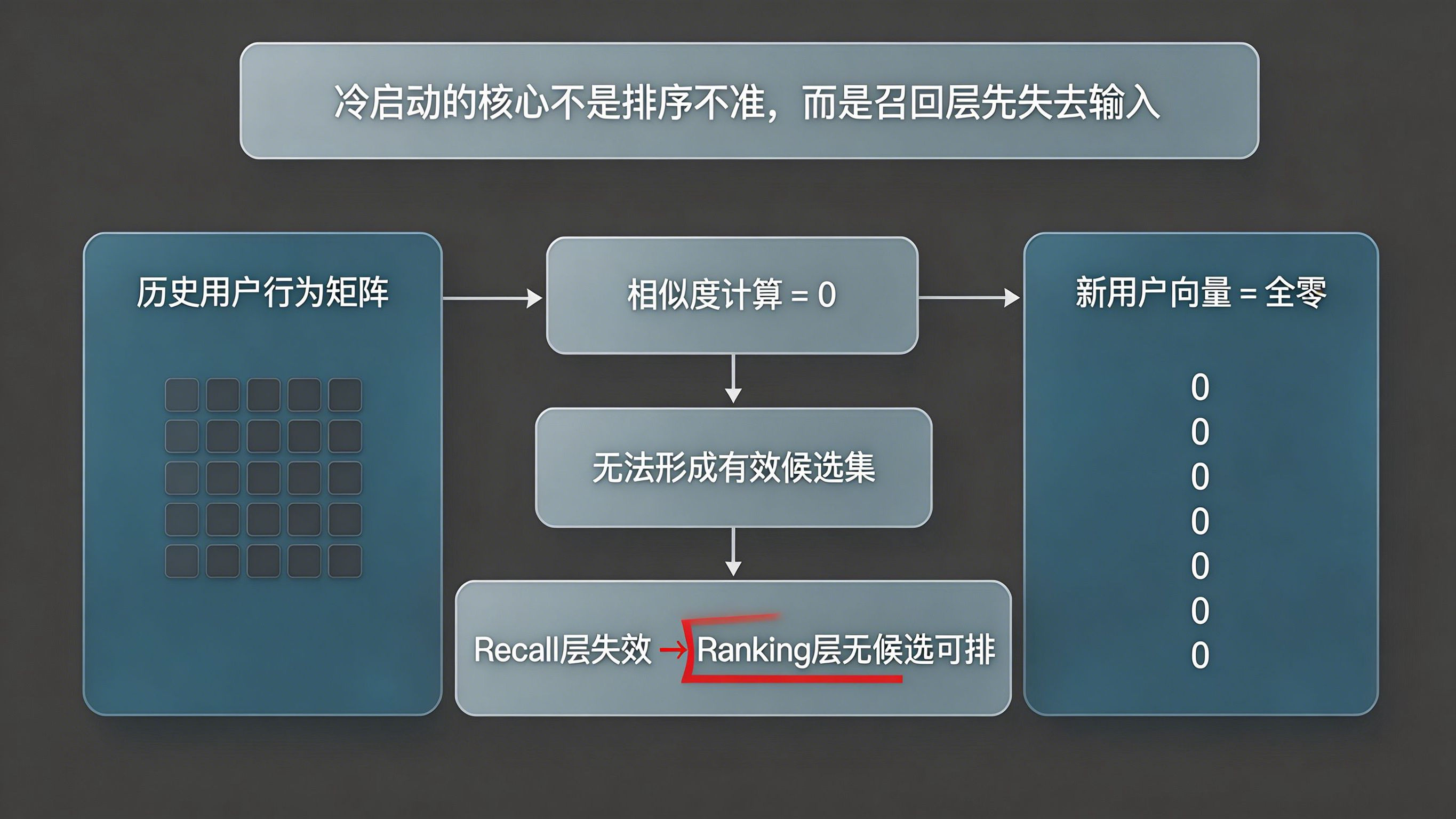
为了解决上述困境,数据架构师需要跳出“端内行为”的局限,将目光投向更上游的数据管线。从广告点击、网页浏览、裂变海报扫码,再到最终的 App 激活,这个漫长的物理链路中蕴含着极高的意图密度。
在实际业务架构选型中,面对智能推荐的冷启动,通常有以下三种策略走向,其在数据管线与召回延迟上的表现差异显著:
| 策略方向 | 数据依赖程度 | 召回延迟表现 | 实现成本与系统开销 |
|---|---|---|---|
| 纯协同过滤 (CF) / 序列模型 | 极高(需大量端内深度交互行为) | 较高(需累积特征后重新入库计算) | 较低(算法层通用,已有基建成熟) |
| 全局热门兜底策略 | 极低(完全无需用户级个性化特征) | 极低(直接读取 Redis 热门缓存队列) | 极低(几乎无特征工程成本) |
| 引入端外归因特征赋能 | 适中(依赖跨端免填码与归因数据采集) | 极低(首次启动时毫秒级实时计算与召回) | 中等(需部署多触点链路,融合异构数据) |

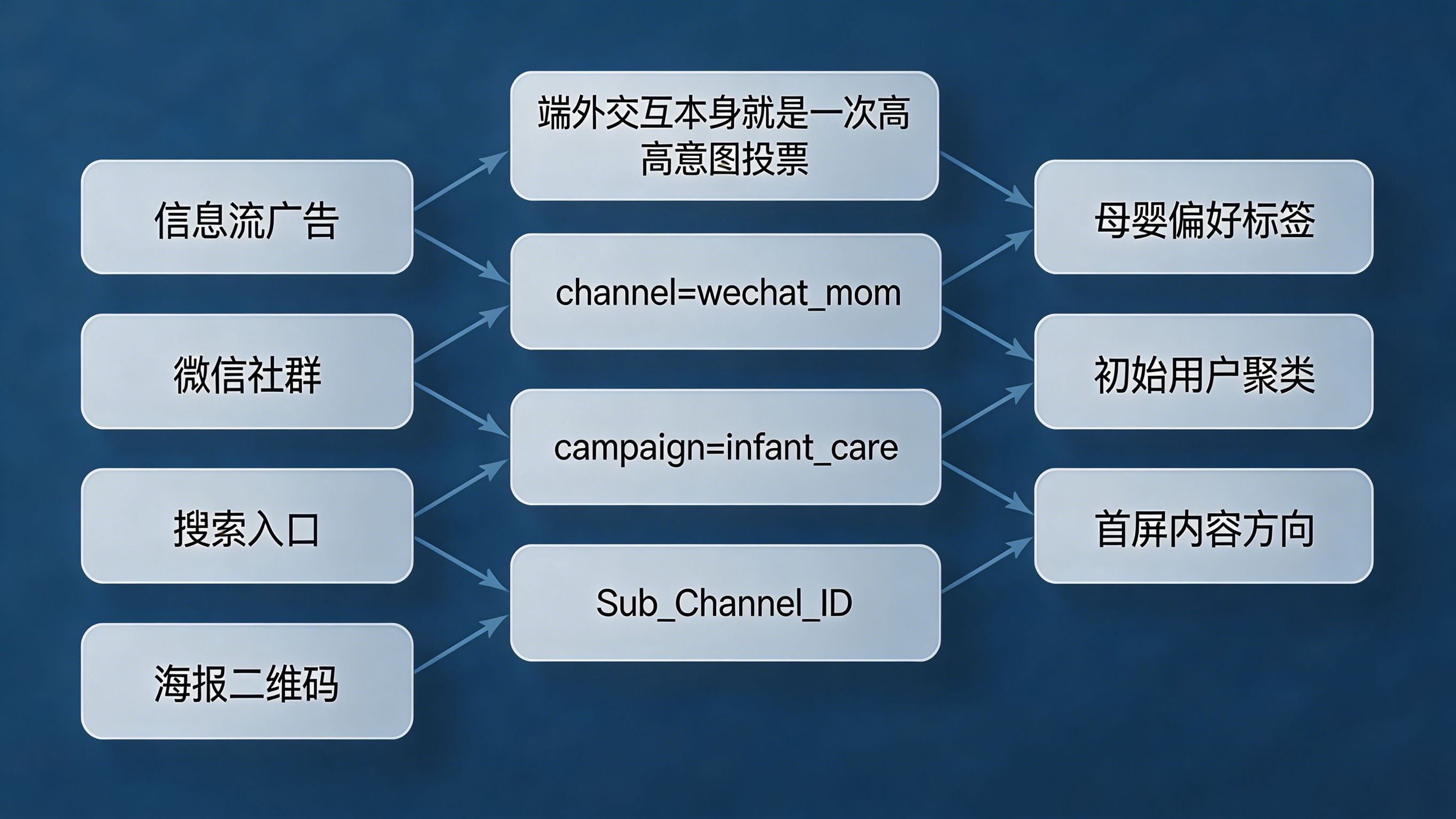
用户在各大公域生态(如信息流广告、微信社群、搜索引擎)中的交互,本身就是一次精准的意图投票。通过 Xinstall 这种底层归因与深度链接基建,开发者可以无损地捕获这些端外触点参数。
例如,一个通过“母婴知识分享”长图二维码扫码下载 App 的用户,其安装链路中携带了 channel=wechat_mom 和 campaign=infant_care 等自定义参数。这些看似简单的字符串,在智能推荐系统眼中,就是高置信度的类目偏好标签。通过将端外广告系统的素材标签与端内的内容标签进行知识图谱映射,推荐引擎可以在用户发生第一次点击前,就明确其所属的宏观聚类。
原始的渠道来源参数往往是离散的稀疏变量(Sparse Features),无法直接被现代深度学习推荐模型(如 DCN、DIN 模型)消化。数据管线的核心任务,是对这些归因日志进行特征工程处理:
为了更直观地展现端外特征在智能推荐系统中的威力,以下通过某头部资讯类 App 的冷启动改造实战,进行深度技术剖析。
该内容 App 近期在各大信息流平台开展了规模庞大的买量活动,通过 50 余种不同垂类(如财经、体育、数码、萌宠等)的广告素材精准触达目标群体。然而,数据团队在分析增长指标时发现严重异常:大量被垂类素材吸引进来的高成本新客,其首日文章点击率(CTR)不到大盘平均水平的 30%。排查发现,由于引擎无法在首日获取用户日志,导致这些垂直圈层用户在首页刷到的全都是“社会热点”和“八卦娱乐”,产生严重的预期违背,进而秒级流失。
在重构智能推荐特征池之前,风控与数据架构团队必须验证数据归因链路的连贯性与真实性,排除虚假流量的干扰。
系统在对新增用户的安装特征进行排查时,严格执行了物理规律校验:正常情况下,该 App 100MB 包体 5G 下 10–15 秒安装属于标准的物理带宽极值。通过对点击时间(Click Time)到激活时间(Install Time)即 CTIT 分布特征进行对账,剔除了 CTIT 小于 5 秒的异常指纹池设备,确保输送给推荐引擎的端外素材标签全部来自真实的物理转化链路。
确认归因数据的高纯净度后,算法工程师正式接入 Xinstall 的底层归因参数接口,进行特征加速落地:
Sub_Channel_ID,推荐引擎根据该 ID 直接查表获取对应的初始 Embedding 并完成首屏 10 条内容的召回与精排。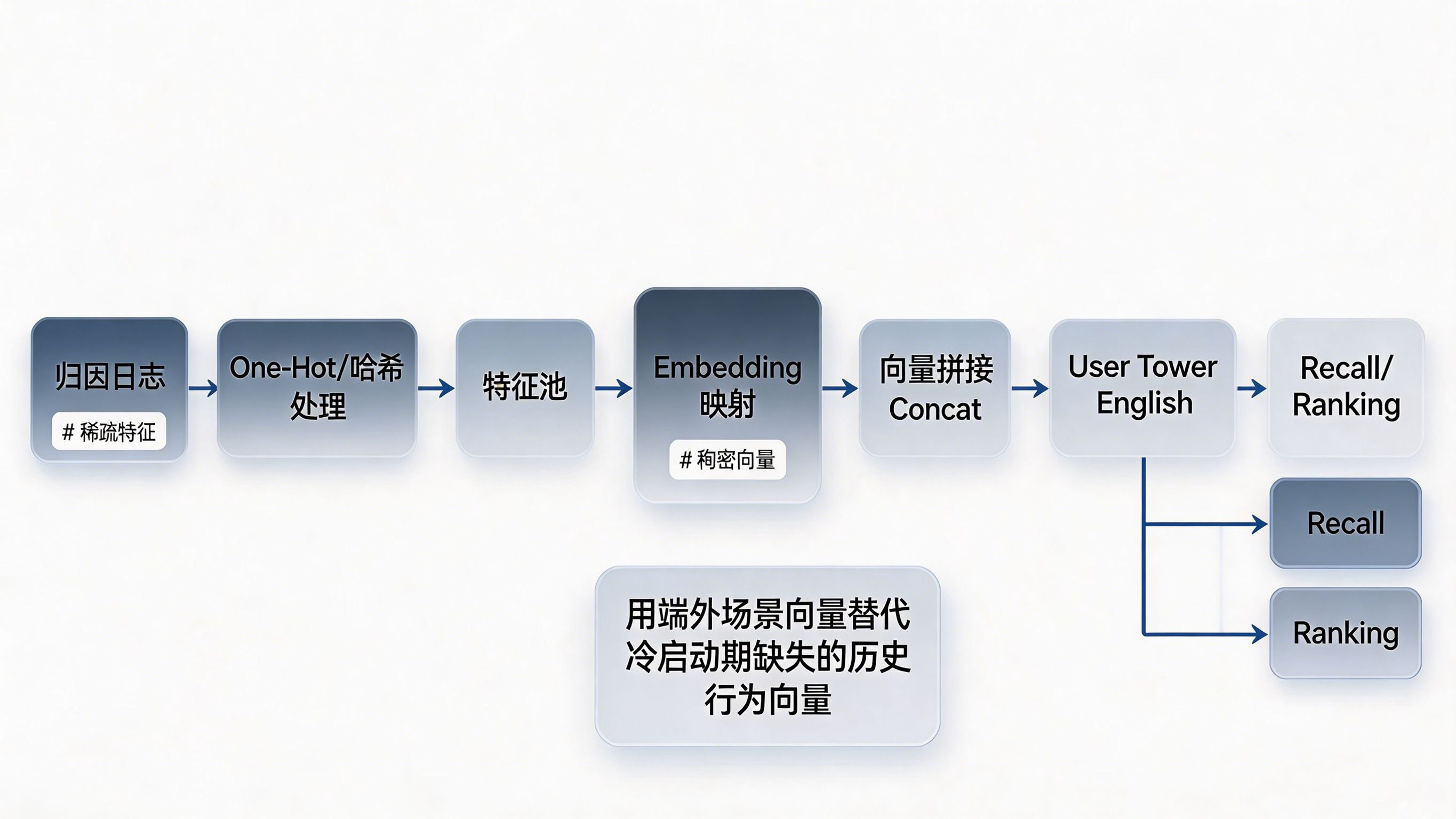
这套基于底层归因特征的冷启动干预机制上线后,效果立竿见影。在为期两周的 A/B 测试中,引入端外特征的实验组,其首日内容推荐的 CTR 飙升,相对提升了 14.3%;更关键的是,首日精准内容的曝光直接拉动了用户的次留表现,首日用户留存率相对提升了 8.6%。
这一实战经验证明,打破系统边界、将外部数据作为内部智能推荐的“起动机”,是移动应用突破冷启动转化瓶颈的最高效手段。
特征工程并非一劳永逸,端外参数提供的初始画像具有一定的“时效性”。为了确保智能推荐系统能够长效运转,必须建立严谨的监控指标体系与权重动态交接机制。

冷启动期的核心目标是“快速移交控制权”。端外特征构建的画像本质上是一种宏观聚类,随着用户在端内产生真实的点击、播放、停留时长等细粒度行为,端内交互矩阵的精确度将迅速超越端外初始特征。
因此,必须在推荐算法中引入时间衰减函数(Time Decay Function)或行为深度衰减策略。设定一个动态的算法权重公式:当用户的有效交互事件超过一定阈值(如阅读超过 5 篇文章),归因特征带来的初始权重即以指数级下降,将推荐主导权平滑过渡给双塔模型计算出的真实兴趣 Embedding。
评估特征画像是否有效,不能仅停留在算法侧的 AUC 或 NDCG 等离线评估指标上。必须将智能推荐系统的表现与APP 全渠道数据分析:深入挖掘用户行为模式进行对齐。
通过对比“冷启动期内容互动率”与后续的“电商下单/会员订阅转化率”,校验前端推荐的内容是否真的切中了高价值漏斗。如果发现某渠道进来的用户初始 CTR 极高但后端 ROI 极低,则需要回溯排查是否是广告素材存在“标题党”导致初始归因特征受污染,从而引发引擎推荐了低质诱导内容。
A: 传统的协同过滤算法高度依赖用户与项目(User-Item)的交叉历史行为矩阵。在冷启动期,新用户没有任何交互历史,此时的输入向量为全零,模型无法通过点积计算得出任何相似度分布。这种客观存在的“矩阵过度稀疏”问题,导致纯基于历史行为的推荐算法在首日完全无法工作。
A: 从技术上讲,若企业拥有顶尖的数据架构团队,可自建高并发采集与设备指纹处理系统。但在商业落地中,自研往往面临高昂的基建成本与各大 OS 平台的沙盒限制。接入专业第三方工具(如 Xinstall)能直接复用其成熟的多触点归因与免填码链路,保障数据的完整性与高纯度,让算法团队更聚焦于特征工程的调优。
A: 规范的技术方案不会涉及隐私越界。现代归因链路主要依赖系统基础环境变量的不可逆哈希(Hash)模糊匹配,提取的仅是“渠道场景”、“素材类别”等宏观统计级参数,并不触碰用户的 PII(个人敏感信息)。这些脱敏后的连续特征输入神经网络不仅安全,且符合各大应用商店的数据合规要求。

促进平台经济大中小企业协同发展行动方案?智能体成核心
2026-06-19

苹果Xcode27深度集成AI智能体?原生革新引爆场景还原归因
2026-06-19

小米MiMoClaw适配全新框架?终端洗牌确立智能传参获客标准
2026-06-18

寒武纪大涨超14%创新高?硬科技板块爆发倒逼全渠道统计
2026-06-18

上交所发布大模型上市指引?底层应用如何重塑流量归因
2026-06-17

OpenAI硬件全家桶曝光?从无屏音箱到AI伴侣,下一个流量分发中心会是谁
2026-06-16

支付宝测试AI版支付宝?支付巨头打响智能体生态战,开发者如何破解流量黑盒
2026-06-16

阿里发布首个具身大模型?机器人抢走入口,流量洗牌在即
2026-06-16

抖音生活服务文旅生态大会?你投在大屏的拉新二维码还在狂丢参数吗
2026-06-15

智谱推出最新一代旗舰模型GLM-5.2?算力彻底下沉,买量预算或将遭遇高智商假量洗劫
2026-06-15

华为HDC2026开发者大会举办?鸿蒙会把手机变成什么
2026-06-12

欧洲央行宣布重启加息?全球打工人又要勒紧裤腰带熬苦日子了
2026-06-12

瑞幸推出 CLI?指令界面前置暴露了未来应用的无头获客危机
2026-06-11

微信要掀千问的桌?生态级智能体对决重组服务流转与应用归因
2026-06-11

美团AI浏览器来了?浏览器入口会不会重写分发链路
2026-06-10






















