






手机微信扫一扫联系客服
联系电话:18046269997



 APP安装免填邀请码
APP安装免填邀请码 社交分享效果统计
社交分享效果统计 广告投放数据统计
广告投放数据统计 CPA/CPS推广效果统计
CPA/CPS推广效果统计 App地推统计
App地推统计 App拉起
App拉起 网页/应用内直接安装
网页/应用内直接安装 Android多渠道打包
Android多渠道打包 App安装后自动绑定
App安装后自动绑定 App分享效果统计
App分享效果统计 Deeplink深度链接
Deeplink深度链接 手机微信扫一扫联系客服
 241
241当金融知识管理从“全量检索”走向“Wiki定调 + RAG补时效”的冷热分流时,真正被重写的不只是知识库架构,还有答案来源、责任链条与数据可解释性;这篇文章面向开发者与增长团队,拆解金融知识系统演进背后的4.6层归因重构。
Wiki定调、RAG补时效,这个提法抓住了金融知识管理里最关键的一对矛盾:一边是合规口径必须稳定、可追溯,另一边是监管文件和业务规则又在高频变化。对金融机构来说,这不只是知识库升级,而是一次关于“答案从哪来、谁来定调、出了问题怎么追责”的系统重构;而对 App 与企业系统团队来说,它进一步指向了一个更底层的问题——如何把【数据归因】从“检索命中”提升到“结论责任链”。
原文没有从“我们用了什么模型”讲起,而是先拆出了金融知识管理的三个核心痛点:口径分裂、时效滞后、跨文档推理缺失。作者举的起点场景非常典型:同一条监管政策,在总行指引和分行整理的“合规要点”里只差三个字,但去年监管检查时,检查组就因为这三个字的偏差开出了整改通知书。Wiki定调RAG补时效:金融知识管理的冷热分流术
这说明在金融场景里,知识问题根本不是“搜不到”那么简单,而是“同一件事存在多个版本、多个部门、多个解释”。作者随后进一步总结:一家大型银行往往有数千份内外规文件,散落在合规、风控、法律和各业务条线中,同一政策不同部门会有不同解读;而 2024 年以来监管新规细则高频发布,又让传统知识库很难及时同步;更复杂的是,很多业务问题天然横跨多份制度文件,传统 RAG 检到几个碎片后并不能可靠拼出完整答案。Wiki定调RAG补时效:金融知识管理的冷热分流术
换句话说,金融知识管理的难点不是知识量不够,而是“口径一致性 + 时效性 + 推理完整性”必须同时成立。而这三个目标,恰好会互相冲突:越追求实时,越容易失去口径统一;越依赖检索拼接,越难保证推理可审计。
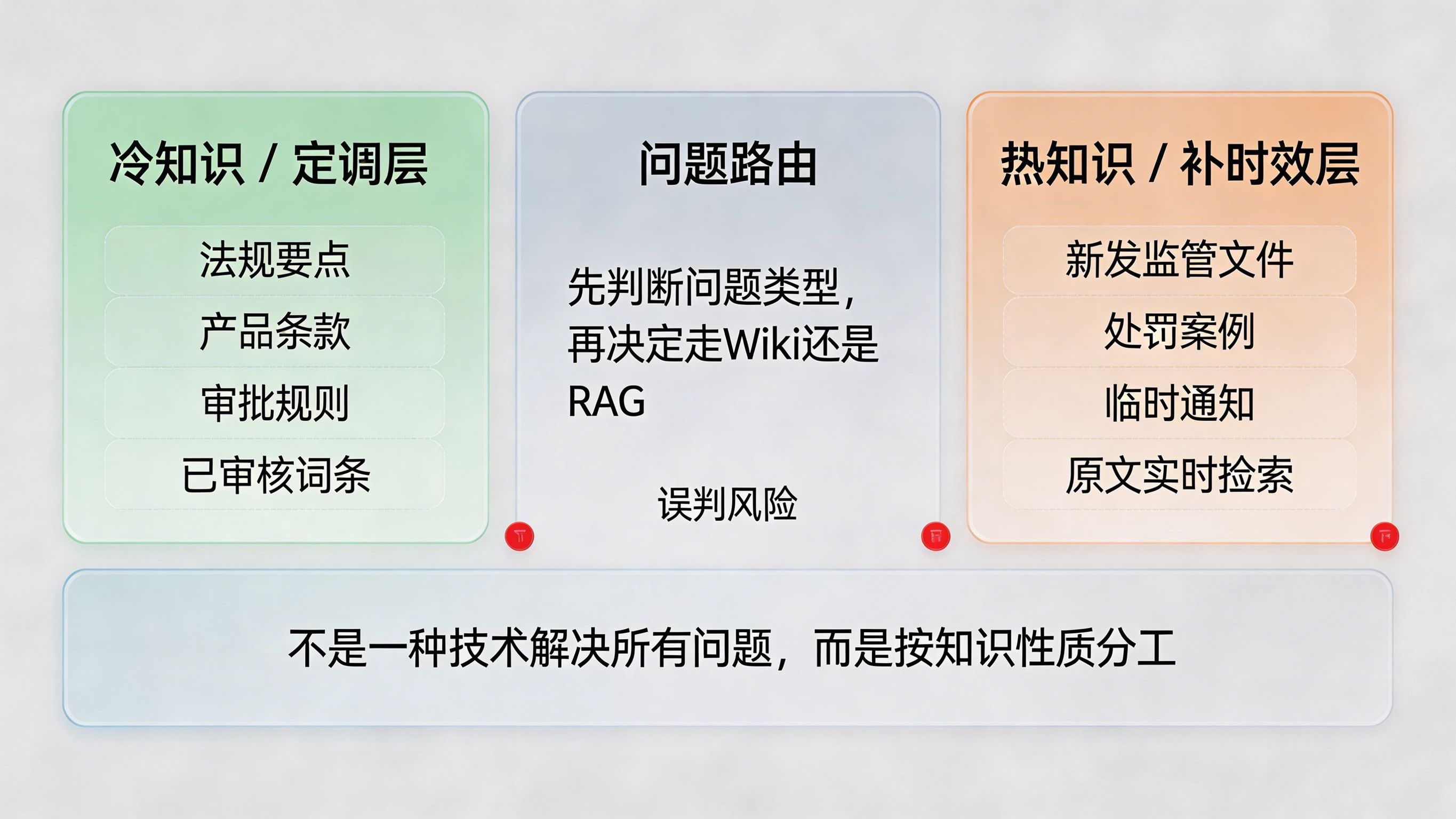
文章最核心的方案,是用 LLM Wiki 负责“定调层”,用 RAG 负责“检索层”,中间再加一层路由判断问题该走哪条通道。也就是说,低频变更但高权威性的内容,如法规要点、产品条款、审批规则,先被编译成经过审核的标准词条,进入 Wiki;高频变化、强时效的内容,如新发监管文件、处罚案例、临时通知,则由 RAG 在查询时补充。Wiki定调RAG补时效:金融知识管理的冷热分流术
这个设计很有现实感,因为它没有试图用一种技术统一解决所有问题。相反,它承认了两类知识在治理方式上就是不同的:有些知识适合提前编译、反复复用;有些知识则必须保留原文的实时性和上下文。行业里关于 LLM Wiki 与 RAG 的对比也大致支持这种思路。腾讯云开发者文章指出,普通 RAG 更适合大规模动态文档检索,而 LLM Wiki 更适合将原始知识提炼为结构化 Wiki 页面,适合持续知识沉淀;另一篇对知识管理范式的分析则把 RAG 概括为“每次查询从零检索”的无状态解释器,把 LLM Wiki 描述为更适合深度编译和知识复利积累的方式。从普通RAG、知识图谱RAG 到LLM Wiki,一篇讲清原理、区别与选型 从RAG、LLM Wiki 到GBrain:检索、编译与持续记忆的AI知识管理范式
所以,“Wiki 定调,RAG 补时效”真正高明的地方不在于名字,而在于它顺着知识本身的性质做分工,而不是让一个检索系统既负责权威口径、又负责实时更新、还负责复杂推理。
原文里最值得注意的一句设计原则是:合规查询强制走 Wiki,不允许 RAG 兜底;只有 Wiki 里确实查不到时,才允许降级返回 RAG 检索到的原始法规原文,并明确标注“未经编译,仅供参考”。Wiki定调RAG补时效:金融知识管理的冷热分流术
这句话非常重要,因为它重新定义了金融 AI 系统里的“答案”。在很多通用 RAG 场景中,只要能给出一个大致靠谱、带出处的回答,系统就算可用;但在金融合规场景里,答案不只是信息输出,它还是可执行依据、合规口径和责任链的一部分。因此,“能答出来”远远不够,必须知道“这是谁定的调、基于哪个版本、由谁审核、何时生效”。
这也和金融行业对统一口径的基础要求是一致的。金科创新社关于监管要求的文章就提到,通过统一数据指标体系和采集规范,金融机构需要确保对监管业务口径的理解一致,减少加工差异。一表通监管要求下的数据口径统一
从这里就能看出,作者的方案其实不是在做“更聪明的问答系统”,而是在做“可承担责任的答案系统”。而一旦答案承担责任,就必须有比普通检索更强的来源约束。
文章对 Wiki 词条的设计要求非常细:每条词条必须包含来源法规文号、原文段落锚点、生效时间、版本号、审核人、审核时间、变更记录等 YAML 元数据,确保审计时可以从答案追到词条、从词条追到法规原文、再追到版本历史。Wiki定调RAG补时效:金融知识管理的冷热分流术
这实际上是在给金融知识系统建立四层追责链:答案层、词条层、原文层、版本层。这样一来,系统输出不再只是“一段自然语言”,而是一个有完整证据路径的合规对象。
从行业角度看,这种“检索-生成-校验”一体化的思路并非空穴来风。潍坊银行的“智慧合规助手”案例就明确强调通过大模型语义理解能力与 RAG 的检索优势,构建“检索-生成-校验”一体化引擎;台湾经济部门关于 RAG 在金融领域的介绍也提到,RAG 可将实时检索、智能生成与专家审查结合起来,以支持透明且合规的人机协作。潍坊银行:基于大模型和RAG驱动的智慧合规助手 RAG技術在金融領域的應用
只是这篇文章比一般案例更进一步,它没有停在“带出处”层面,而是把“出处、版本、审核、变更”都纳入了标准答案结构。这正是金融知识系统和普通企业知识库最大的分水岭。
原文对增量编译流程的描述也很务实。作者设想通过监控监管网站新文件发布、让 LLM 自动识别新旧法规差异、定位受影响的 Wiki 词条,并自动生成更新建议。但它同时强调一条红线:增量编译不等于自动生效,所有变更必须经过合规负责人审核确认后才可入库。Wiki定调RAG补时效:金融知识管理的冷热分流术
这其实是一个非常成熟的产品判断。因为在金融行业,AI 当然可以用来发现变化、准备变更建议、提高审核效率,但它不能替代口径裁定本身。系统可以帮人准备“待批内容”,但最后盖章的只能是人。否则一旦系统自动把错误口径编译进 Wiki,后果会比一次普通检索错误严重得多,因为错误会被当作权威答案反复传播。
这一点和业内对 LLM Wiki 的潜在风险判断也一致。Reddit 上对 LLM Wiki 的讨论就提到,与普通 RAG 相比,LLM Wiki 的错误可能会在知识摄取阶段被传播,因此需要特别关注摘要与原文是否一致,以及关键错误的可定位性。关于LLM Wiki错误传播的讨论
所以,这篇文章真正成熟的地方,不是因为它用了 LLM,而是因为它明确划清了“机器编译”和“人类定调”的边界。
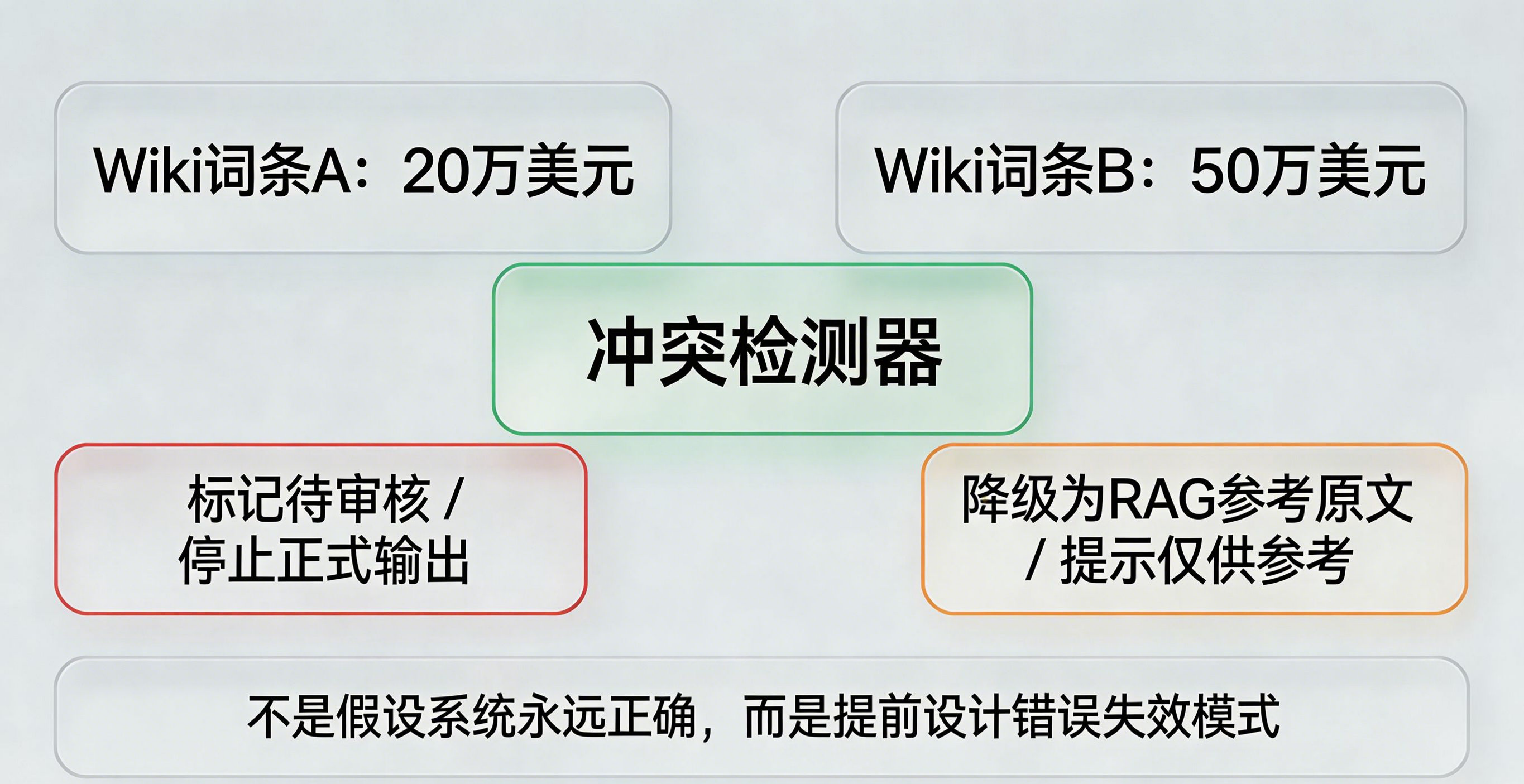
我认为原文里最亮眼的设计,是“结构性熔断”。作者提出,如果 Wiki 内部两条词条口径冲突,例如一条说跨境结算大额交易报告门槛是 20 万美元,另一条因为引用了不同版本法规写成 50 万美元,系统应自动把冲突词条标记为“待审核”状态,并在查询时降级为 RAG 兜底,同时提示“当前知识库存在口径冲突,以下回答仅供参考”。Wiki定调RAG补时效:金融知识管理的冷热分流术
这个设计的价值在于,它承认系统不是不会错,而是一定会错,只是要把错误控制在结构内。和传统 RAG 的偶发性错误不同,Wiki 类系统一旦把错误编织进结构,影响范围会更大,因此必须有主动发现冲突、主动停止扩散的机制。
从产品哲学上说,这个设计非常金融:不是假设系统永远正确,而是假设错误必然出现,因此提前设计失效模式和责任切换机制。这也是为什么它不只是技术方案,而是治理方案。
很多人看到这篇文章,第一反应会停留在“金融知识库怎么做”。但如果从更底层的产品和数据视角看,这篇文章真正解决的是另一个问题:系统输出的结论,到底应该归因给谁。
在普通 App 场景里,我们讲【数据归因】时,通常想到的是用户来自哪个渠道、哪次投放、哪个页面入口。但在金融知识系统里,真正需要归因的对象变成了“答案”。用户问一个合规问题,系统返回一条结论,后面其实有很多潜在来源:
只要这些信息不清楚,所谓“带出处”就不算真正可用。因为对于金融机构而言,答案不是内容资产,而是责任资产。一个结论一旦被客户经理、合规专员或业务人员执行,系统就必须能说明:为什么是这个答案、依据哪份规则、哪个版本、谁批准的。
从这个角度看,这篇文章其实是在把金融知识系统从“检索增强生成”推进到“结论责任链生成”。而这恰恰是 xinstall 视角下可以进一步延伸的地方:不只要知道“用户从哪来”,还要知道“任务从哪来、结论从哪来、责任从哪来”。当 AI 系统越来越像业务决策入口,归因对象就从“流量”扩展到了“结论”。
这也是为什么金融场景比普通企业知识库更能说明问题。因为在这里,归因失真不只是转化率分析错误,而可能直接变成合规风险、审计风险和整改风险。所以“Wiki 定调 + RAG 补时效”的真正价值,正是把模糊的知识输出,转成可解释、可追责、可回放的答案路径。
问题:很多企业系统里,归因还停留在用户入口层,比如 web、app、工单系统、知识助手入口等。但对金融知识型应用来说,这远远不够,因为真正关键的不只是“谁来问”,而是“系统是用哪套知识路线答的”。
做法:可以用渠道编号 ChannelCode的思路,把答案路径也纳入编号体系。比如 wiki_compiled_core、wiki_compiled_policy、rag_realtime_notice、rag_case_reference、conflict_fallback、manual_review_override 等,都可以作为不同“知识来源通道”的 channelCode 管理,再叠加 regulation_version、review_status、conflict_flag、risk_level、business_line 等字段,形成一套面向答案责任链的来源标记。
带来的好处:一旦业务部门反馈“这个答案有问题”,团队可以快速定位是 Wiki 定调层出了问题、RAG 实时层出了问题,还是熔断降级逻辑触发了。对金融场景来说,这种来源编号比传统流量来源编号更关键,因为它直接关系到后续的审计、整改和责任追溯。
问题:很多知识系统能在答案页面展示出处,但一旦用户把结论继续带到下游业务流程里,例如审批、报送、客户处理或工单流转,这些来源上下文就丢了。最后系统只留下一个“用户看过答案”的事件,却保不住“用户依据什么版本、什么词条、什么审核状态做了后续动作”。
做法:这时更适合用智能传参思路,把知识来源参数一路传递下去。除了常见的 source 维度,更要保留 channelCode、regulation_version、wiki_entry_id、review_status、conflict_flag、workflow_id、business_line 等关键字段,让知识检索系统输出的结论能和后续执行动作对上号。方法论上,也可以参考 xinstall 在《智能体分发时代 App 安装传参逻辑的底层重构》里讨论的路径,把“进入来源”从流量概念扩展为“任务与决策来源”。
带来的好处:后续一旦出现业务偏差,团队不只是知道“谁执行了什么”,还知道“他是根据哪条词条、哪个版本、哪种风险状态做的”。
注:本文讨论的部分知识结论责任链承接、复杂审核状态参数回流、跨系统合规答案来源映射等方向,属于对未来分发趋势的前瞻性技术延展与思考,例如决策级来源识别、复杂业务结论归因、知识驱动任务链回溯等前沿应用方向。目前此类高度定制化链路并不等同于标准化全量现成功能,如有类似高阶业务需求,可结合具体业务与 Xinstall 团队进一步探讨。
问题:很多金融知识项目上线后,前端体验看上去很先进,但后台只能看到检索命中率、问题数、点击量等浅层指标。这些指标说明系统被用了,却不能说明系统有没有真正降低口径偏差或审计风险。
做法:可以把事件链扩展为 query_submit、intent_classify、wiki_hit、rag_fallback、conflict_detected、manual_review_trigger、answer_rendered、decision_execute、audit_traceback 等节点,并为每个事件挂上 channelCode、review_status、regulation_version、business_line、risk_level、workflow_id 等字段。这样一来,系统就不再只是“一个问答界面”,而变成一个完整的责任链系统。
这个思路与 xinstall 在《OpenClaw 引爆智能体分发:AI 个人助理重构 App 参数传参安装范式》和《智能体指令集 Skills.sh 发布:AI Agent 分发生态下的 App 归因新范式》中强调的任务链视角是相通的:当系统不再只是页面响应,而是参与复杂业务任务时,就必须把来源、路径和结果放到同一张可解释图里。
带来的好处:团队第一次可以衡量的就不只是“检索命中率提高了多少”,而是“多少结论通过 Wiki 定调输出、多少问题进入熔断兜底、多少执行动作最终可被完整追溯”。这才更接近金融机构真正关心的价值。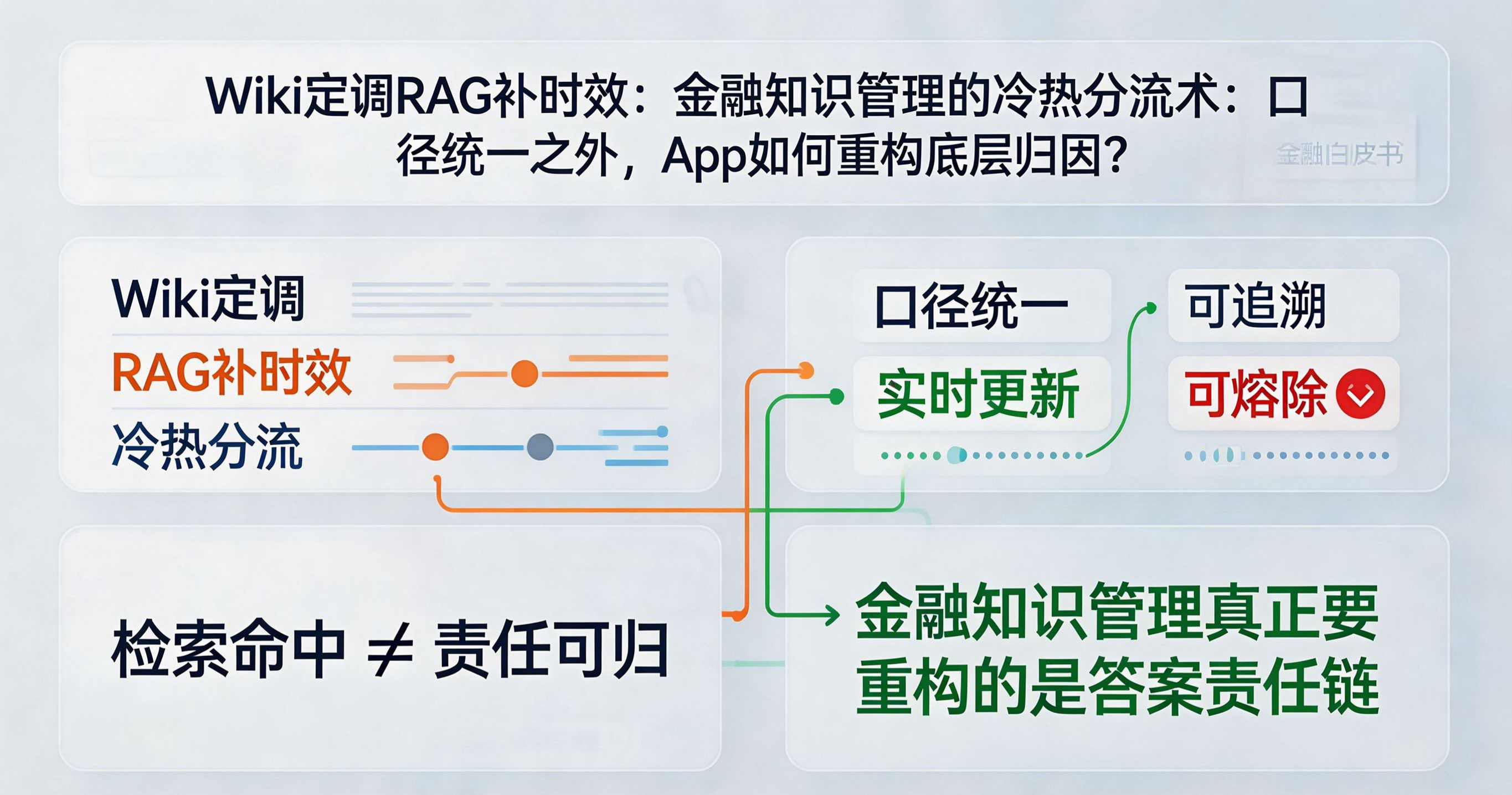
现在最值得做的,不是急着把更多文档接进 RAG,而是先定义清楚“答案责任链”的基础字段。
建议优先保留这些字段:
这些字段决定了你后续能不能把答案、版本、审核和执行动作串起来。
产品经理最容易低估的一点是:金融知识管理不是“把文档问答做好”就够了,而是要先定义什么能自动回答、什么必须人工裁定、什么在冲突时要主动降级。
现在可以先做三件事:
金融场景里的“增长”不一定表现为拉新,它更多表现为使用深度、覆盖范围和人工效率改善。但这些指标也不能只看表面使用量,而要看答案质量与责任链质量。
现在更应该盯住的是:
因为普通 RAG 擅长在查询时动态检索相关片段,但金融合规场景要求口径稳定、可审核、可追溯。只靠检索拼接虽然能提高回答覆盖率,却很难保证答案是统一口径,更难承担审计和责任追溯要求。从普通RAG、知识图谱RAG 到LLM Wiki,一篇讲清原理、区别与选型 Wiki定调RAG补时效:金融知识管理的冷热分流术
核心价值是把高权威、低频变更的知识提前编译成结构化词条,让答案建立在已审核、可维护、可复用的知识对象上,而不是每次临时从碎片里拼装。这样更适合需要长期沉淀和统一口径的场景。从RAG、LLM Wiki 到GBrain:检索、编译与持续记忆的AI知识管理范式
因为金融场景里总有大量高频变化、强时效的内容,比如新发通知、处罚案例和临时性要求,这些内容不适合完全依赖提前编译。RAG 的价值就在于补足实时性,但它更适合作为补充层,而不是定调层。Wiki定调RAG补时效:金融知识管理的冷热分流术
因为 Wiki 类系统一旦把错误口径编进结构,就会在多个查询和页面中持续扩散。结构性熔断的价值在于,一旦发现口径冲突,系统能主动停止把冲突内容当成正式答案输出,把风险控制在最早阶段。Wiki定调RAG补时效:金融知识管理的冷热分流术
“Wiki定调,RAG补时效”之所以值得展开,不是因为它发明了一个全新技术组合,而是因为它把金融知识系统的目标从“提高回答能力”推进到了“管理责任链”。过去很多团队建设知识库时,重点是让系统能答;现在,越来越多金融机构真正需要的是让系统答得可追溯、可审计、可纠错、可熔断。
对 App 和企业系统团队来说,这正是重构数据体系的一个典型信号。因为 AI 系统一旦介入知识查询、规则解释和业务决策,原有只围绕用户入口的【数据归因】就不够用了。更现实的做法,是把知识来源、审核状态、版本切换、冲突标记和后续执行结果放在同一条链上管理。只有这样,你才能真正知道:系统给出的不仅是一个答案,更是一条可以承担责任的结论路径。

Xinstall 跳转失败怎么排查? 内链失效与唤起链路治理指南
2026-07-28

极氪全新车型今日上市?车机生态繁荣催生跨屏应用深度链接基建
2026-07-28

苹果全新系统正式发布?底层隐私收紧倒逼移动端应用归因策略突围
2026-07-28

腾讯官宣QQ宠物回归?经典IP变身大模型智能体考验全链路追踪
2026-07-28

腾讯Miora向全球开放?巨头智能体生态加速多端全链路归因
2026-07-27

Kimi K3登顶前端编码榜?开源大爆发考验应用生态分发承接力
2026-07-27

Claude Opus 5全面上线?旗舰算力下放重塑应用端引流策略
2026-07-27

AMD 机架级AI系统全面投产,智能体时代算力再洗牌?
2026-07-24
Xinstall 全链路归因怎么做? 统一口径与闭环分析指南
2026-07-24
Xinstall 内链为什么无法跳转 ?跳转失败原因与排查路径解析
2026-07-24

Xinstall 跨渠道怎么归因?全链路追踪与统一口径
2026-07-23

Xinstall 安装来源怎么统计?归因恢复与链路设计
2026-07-23

上海科创板新政落地?未盈利硬科技的上市窗口怎么变
2026-07-23

iPhone18系列已量产?供应链装机归因进入重构期
2026-07-22

数据建模怎么支撑推荐?从用户特征到召回排序
2026-07-21






















