






手机微信扫一扫联系客服
联系电话:18046269997



 APP安装免填邀请码
APP安装免填邀请码 社交分享效果统计
社交分享效果统计 广告投放数据统计
广告投放数据统计 CPA/CPS推广效果统计
CPA/CPS推广效果统计 App地推统计
App地推统计 App拉起
App拉起 网页/应用内直接安装
网页/应用内直接安装 Android多渠道打包
Android多渠道打包 App安装后自动绑定
App安装后自动绑定 App分享效果统计
App分享效果统计 Deeplink深度链接
Deeplink深度链接 手机微信扫一扫联系客服
 155
155当算法、产品和运营对同一版模型给出相反结论时,问题往往不在模型本身,而在缺少统一评测集;这篇文章面向开发者与增长团队,拆解评测体系缺失带来的3.2层任务流量与归因失真。
没有评测集,迭代就是拍脑袋,这句话放在 AI 产品里几乎已经成了工程现实。很多团队看似在迭代模型,实际是在不同角色、不同指标、不同场景之间来回拉扯,而一旦缺少统一的评测基准,产品上线与否、模型好坏、流量质量高低都会失去共同语言,这最终会把【任务流量】和业务结果之间的关系一起搞乱。
你给出的文章开头非常典型:智能客服上线一个月后,算法同学说准确率涨了 2 个点,运营同学却说用户投诉更多了。表面看,这是模型效果和业务感受不一致;本质上,是团队缺少统一评测标准,导致每个人都只能用自己的局部指标来解释“这次迭代到底有没有变好”。没有评测集,迭代就是拍脑袋:“三分法”构建AI的导航系统
这类冲突在 AI 产品里特别常见。因为与传统互联网功能不同,AI 系统的输出不是固定逻辑,而是概率性结果。算法同学更容易关注准确率、召回率、F1 这些模型指标,运营更容易感知投诉量、误判量、人工接管率,产品经理则往往盯着用户满意度、转化率、解决时长。每一方看的都不是错的,但它们未必能自动拼成一个统一结论。
于是问题就来了:到底谁说得对?没有评测集时,这个问题没有标准答案。团队会进入一种典型状态——谁掌握话语权,谁就定义“这次迭代有效”。这并不是数据驱动,而是一种披着数据外衣的主观决策。
原文把评测集比作 AI 产品的“导航系统”,这个比喻非常准确。导航系统的价值从来不只是告诉你终点在哪,而是持续回答三个问题:你现在在哪、应该往哪走、你刚才走对了没有。没有评测集,迭代就是拍脑袋:“三分法”构建AI的导航系统
放到 AI 产品里也是一样。一个好的评测集,至少要具备四个特征:
文章给出的这四个条件其实非常务实,因为它们不是学术论文里的“最优评测”,而是产品团队真正能用来决策的“可落地评测”。一旦这套导航系统建起来,算法改模型不必等上线才知道大致方向,产品做 A/B 测试也有了能对齐全团队的基线。

原文提出的“三分法”,核心包括三步:定义范围与标准、收集与标注数据、分层与切片。这套方法之所以值得写,不是因为它有多新,而是因为它非常适合大多数 AI 产品团队从 0 到 1 起步。没有评测集,迭代就是拍脑袋:“三分法”构建AI的导航系统
第一步是定义范围与标准,也就是先确定“考什么”。作者提到,他们会和业务方一起先定义必须覆盖的用户意图,比如查询订单状态、申请退款、咨询商品信息、投诉破损、查询积分等,并优先覆盖高频意图。这里的关键不是把所有问题一口气覆盖,而是先把 80% 流量集中发生的高频意图圈出来。
第二步是收集与标注数据,也就是准备考题和标准答案。作者建议优先使用脱敏后的真实用户日志,并在冷启动阶段辅以人工撰写和大模型生成同义问法。这个策略很现实,因为大多数团队一开始没有足够的优质真实日志,但如果完全依赖人工想象,评测集又会和真实用户表达脱节。
第三步是分层与切片。原文强调,一个笼统评测集只能给你一个模糊总分,而经过切片后的评测集,能告诉你模型到底是在哪一类场景上退化了。这一点尤其重要,因为 AI 产品很少是“整体一起好或整体一起坏”,它更常见的状态是:某些核心意图稳定,某些口语化表达崩掉,某些多轮场景退化。
很多讲 AI 评测的文章停留在理念层面,但这篇材料之所以有实操价值,是因为它写到了大量工程细节。比如:
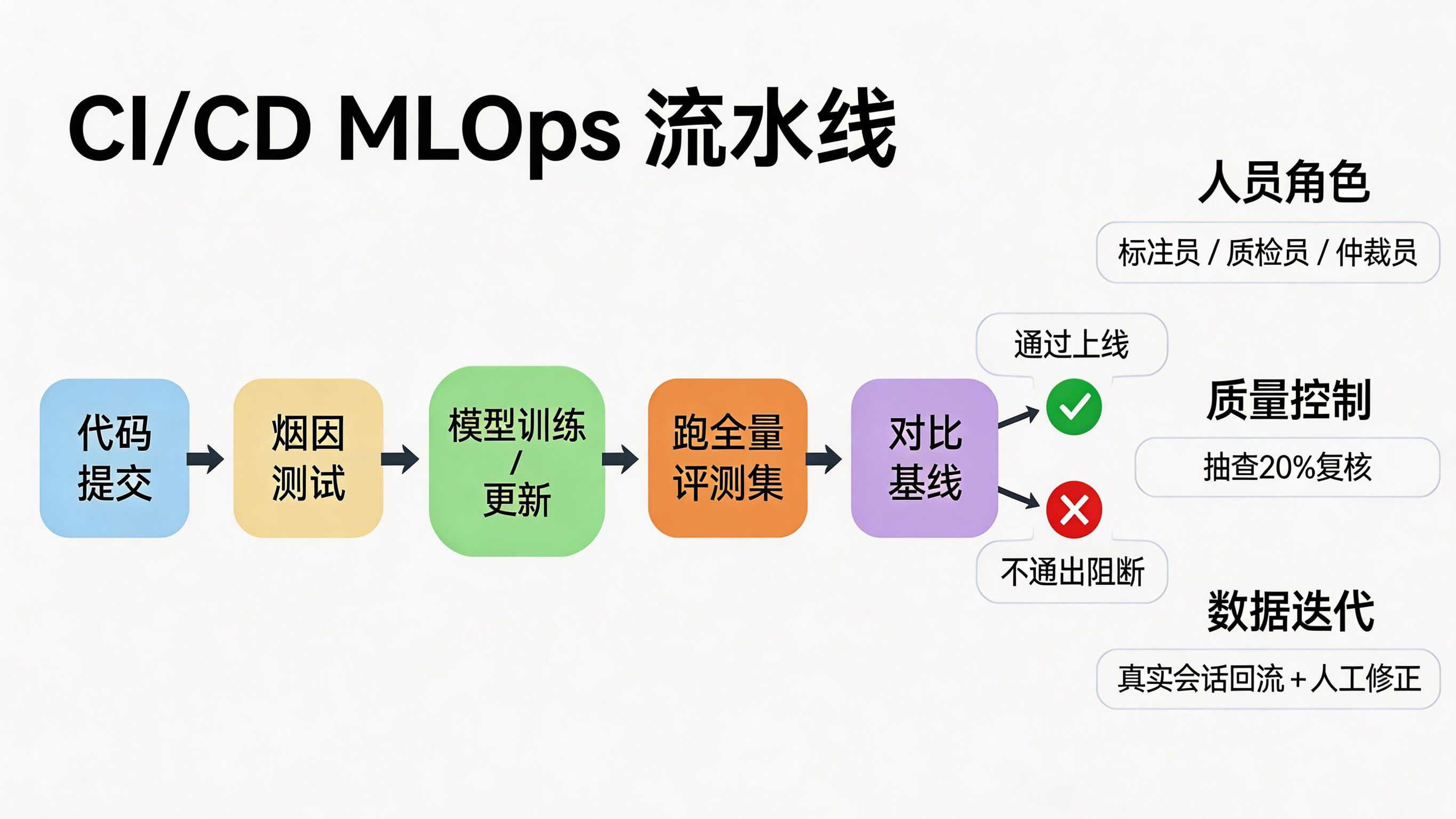
这些细节让评测集从“一个概念”变成“一个系统”。特别是文章里提到的自动化流程:代码提交 → 烟囱测试 → 模型训练 → 跑全量评测集 → 对比基线 → 不通过则阻断上线。这个过程说明,评测集不是为了写报告,而是为了改变上线决策方式。没有评测集,迭代就是拍脑袋:“三分法”构建AI的导航系统
从行业实践看,这种思路与云平台给出的最佳实践也是一致的。阿里云的大模型评测最佳实践强调,自定义评测集要明确 question 和 answer 字段,并结合通用指标评测或裁判员模型评测输出结构化结果;华为云的评测集设计实践也强调从真实会话中提取数据,并允许对评判结果人工修正。大模型评测最佳实践 评测集设计实践 - 华为云
如果只从技术上理解这篇文章,会把它看成一篇“如何做评测集”的实操文;但从产品和组织层面看,它讨论的是另一件更根本的事:AI 团队如何建立共同语言。
文章最后给出的成果并不是什么“模型冲榜”数据,而是:一套统一测试集、自动化评测流水线、算法产品运营共用同一套指标。这个结论很重要,因为很多 AI 项目并不是败在模型能力不够,而是败在团队内部没有一个共同评判标准,导致算法、运营、产品一直在不同坐标轴上说话。没有评测集,迭代就是拍脑袋:“三分法”构建AI的导航系统
一旦没有共同标准,增长侧就会觉得流量质量差,算法侧会觉得模型在进步,产品侧会觉得版本难以说明,老板则会觉得“为什么每次迭代都像赌博”。从这个意义上看,评测集不只是导航系统,也是组织协同系统。
而这也正是它和 xinstall 视角能接上的原因:评测集表面上解决的是模型评估问题,底层解决的却是“任务到底来自哪、任务为什么成功或失败、哪个入口带来的任务更有价值”这样一类【任务流量】问题。
这篇文章讲的是评测集,但如果从 App 开发、增长和数据视角往下拆,会发现它真正碰到的其实是一个更大的问题:AI 产品里,很多团队在评估的根本不是“用户路径”,而只是“模型输出”。
这就会造成一个经典错位。比如,一个智能客服模型在离线评测里准确率变高了,但线上投诉却变多。为什么?因为用户真正经历的链路不只是“模型答得准不准”,而是:
如果没有统一评测集,团队只能看到局部切面;如果没有更细的任务链路观测,团队甚至不知道局部切面对应的是哪类真实用户路径。于是,“模型变好了”和“业务变差了”会同时成立。
这正是 AI 产品中【任务流量】最容易失真的地方。传统互联网更多围绕“人物流量”建模:谁来了、从哪来、点了什么、买了什么。但 AI 产品越来越多的是“任务先发生,人物感知滞后”。用户扔进来一句话,背后发生的是分类、检索、调用、生成、兜底、转人工等多步任务链。最终用户只感知结果,团队却需要判断整条任务链。
如果没有评测集,产品团队会不知道是入口问题、意图问题、检索问题还是生成问题;如果没有归因能力,增长团队也不知道到底是哪类入口带来的坏任务更多、哪类任务更适合做自动化承接。
所以,这篇文章真正值得展开的地方,不是“评测集很重要”这句正确废话,而是:在 AI 产品里,评测集和归因体系其实是在解决同一个问题——如何让任务链路变得可解释。
问题:很多客服、AI 助手、知识问答产品,习惯把进入系统的请求都看成同一类流量。但现实里,不同入口带来的任务质量完全不同:有的来自 App 内主动求助,有的来自站外广告落地,有的来自历史工单回访,有的来自系统自动提醒触发。入口一旦混在一起,评测结果就很难解释。
做法:先用渠道编号 ChannelCode把任务入口拆开。不要只记 source,而是尽量拆到 app_help_center、order_after_sale、ad_landing_support、crm_callback、member_center、system_popup 等层级,再叠加 scene、intent_type、risk_level、user_stage 等字段。这样评测结果就不再是一个总分,而能知道“到底是哪类入口的问题更多”。
带来的好处:当你发现某次模型迭代后投诉增加时,可以先判断是模型真的退化了,还是某个新入口导入了大量噪音任务。对于【任务流量】型产品来说,先分入口再评测,远比单看总准确率更有业务解释力。
问题:很多团队做评测时只保存用户问题文本和标准标签,但没有记录“这个问题是在什么场景下产生的”。结果是评测看上去不错,线上却不稳定,因为线上真实问题天然带着上下文,而离线评测却把上下文切掉了。
做法:这时更适合用智能传参的思路来看待评测体系。参数不应只存在于拉新环节,也应存在于任务分析环节。比如把 scene、channelCode、user_stage、intent_type、entry_type、workflow_id 等上下文信息和样本一起沉淀下来,让评测集不仅知道“问了什么”,也知道“为什么会在这里问”。如果想把这套链路设计得更完整,可以参考 xinstall 在《智能体分发时代 App 安装传参逻辑的底层重构》里讨论的方法,把来源信息一路保留到后续事件分析中。
带来的好处:一旦模型在某类问题上失败,你不只是知道“它答错了”,还知道“它在什么入口、什么阶段、什么意图场景下更容易失败”。
注:本文讨论的部分任务级上下文承接、复杂场景参数回流、跨系统工作流样本恢复等方向,属于对未来分发趋势的前瞻性技术延展与思考,例如 AI 应用的任务级来源识别、复杂入口语义承接、智能体工作流归因等前沿应用方向。目前此类高度定制化链路并不等同于标准化全量现成功能,如有类似高阶业务需求,可结合具体业务与 Xinstall 团队进一步探讨。
问题:准确率、召回率、F1 很重要,但它们只能告诉你模型好坏,不能完整告诉你业务为什么变好或变坏。尤其在 AI 客服和智能体场景里,真正影响体验的往往是整条任务链,而不是某一个分类结果。
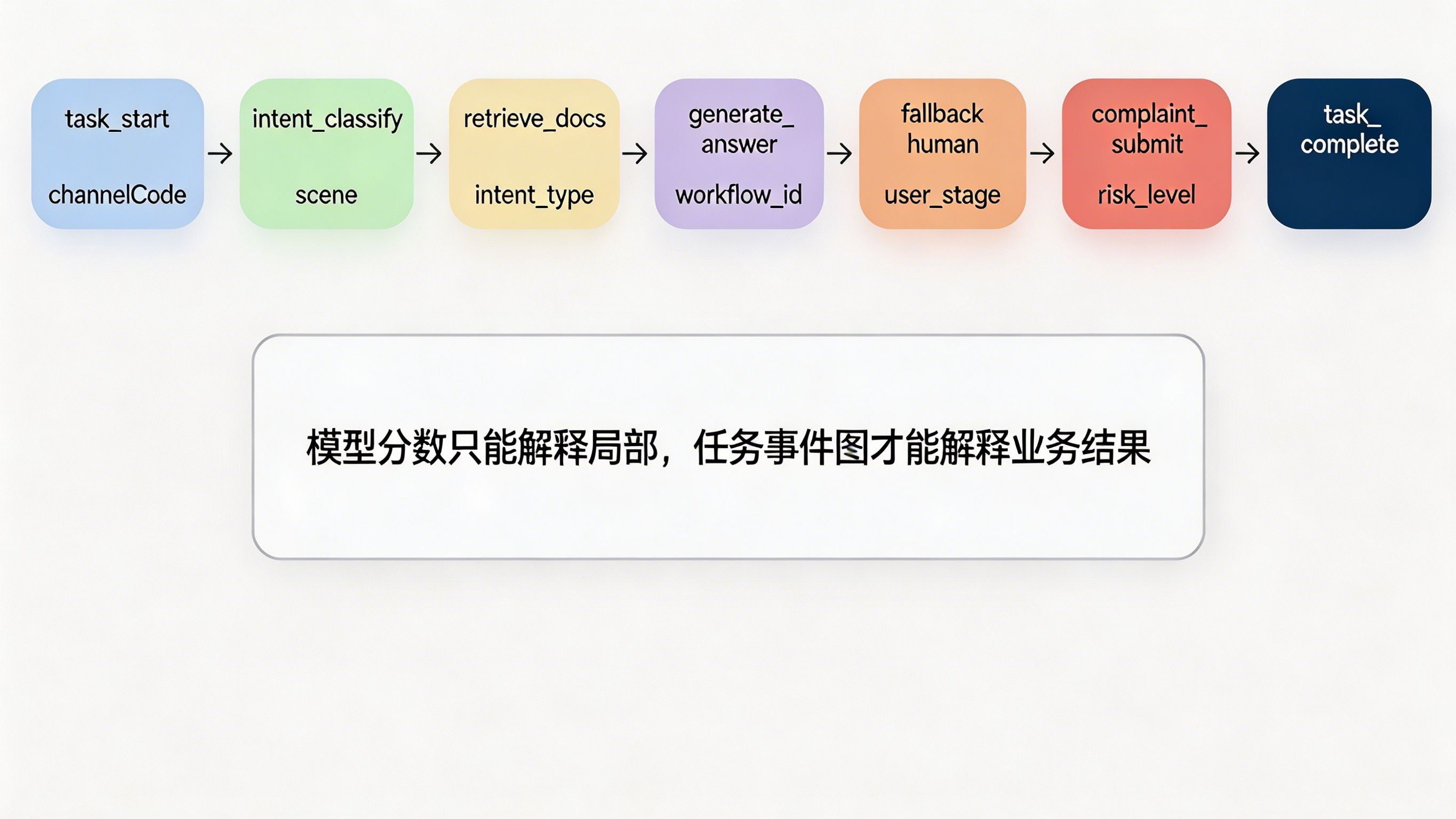
做法:可以把数据仓事件从 click、open、submit 扩展为 task_start、intent_classify、retrieve_docs、generate_answer、fallback_human、task_complete、complaint_submit 等节点,并把 channelCode、scene、intent_type、risk_level、user_stage、workflow_id 一起接进来。这样,评测集和线上事件流就能形成闭环:离线知道模型在哪类任务上不稳,线上知道这些任务是否真的影响了结果。
这个思路也能与 xinstall 在《OpenClaw 引爆智能体分发:AI 个人助理重构 App 参数传参安装范式》和《智能体指令集 Skills.sh 发布:AI Agent 分发生态下的 App 归因新范式》里谈到的做法对齐:真正重要的不是“把模型分数做高”,而是把任务入口、上下文参数和结果事件连成一张能解释业务的图。
带来的好处:你终于可以回答一个团队最常吵但最难答的问题——这次版本到底是“模型更好了”,还是“只是指标更好看了”。而这正是【任务流量】体系下最重要的能力。
现在最值得做的,不是先上更复杂的评测框架,而是先把数据结构设计对。
建议优先保留这些字段:
这些字段会决定你之后能不能把评测结果和真实线上任务串起来。
产品经理最容易犯的错,是把评测集当成算法团队的事情。其实评测集本质上是产品定义的一部分,因为它决定了“什么叫好、什么叫差、什么叫可上线”。
现在可以先做三件事:
增长和运营团队也不能只把评测当成模型事。因为很多线上问题,根本不是模型“绝对不行”,而是某些入口引进了不适配任务,或者某些任务不该自动处理却被自动处理了。
现在更应该盯住的是:
因为没有统一评测集时,算法、产品、运营看到的是不同切面。算法会看模型分数,运营会看投诉和转人工,产品会看整体体验,但三者之间没有共同标尺,就很难判断一次迭代到底是好还是坏。
因为真实用户的问题表达往往比标准问法复杂得多,包含口语化、模糊表达和上下文依赖。只用人工想象的问题做评测,容易让模型在测试时表现不错,但上线后碰到真实流量就失真。
因为总分只能告诉你“整体大概怎样”,却不能告诉你“到底哪里出问题”。一个模型可能在高频核心意图上很稳,但在口语化问法或多轮对话上明显退化,不切片就看不见。
因为它们不再只有一个标准答案。多轮对话还要看上下文承接是否自然、是否在合理轮次解决问题;生成式回答则往往需要结合人工盲测或裁判模型来辅助判断,不能像分类题一样直接做唯一对错判断。再看大模型多轮对话性能如何评测:MT-bench多轮对话评测基准思想 自动评测-大模型服务平台百炼(Model Studio)
“没有评测集,迭代就是拍脑袋”之所以会成为热点,不只是因为大家都在做 AI,而是因为 AI 产品开始进入真正的工程化阶段。工程化阶段的关键不再是“模型能不能跑”,而是“版本能不能解释、质量能不能对齐、结果能不能复现”。评测集只是表面抓手,更深层的,是整个团队开始重新认识任务本身。
对 App 和 B 端团队来说,现在也是重构数据体系的好时机。因为一旦产品越来越像智能体、客服、助手或任务系统,传统只围绕人物流量的看板会越来越不够用。更现实的做法,是把评测体系、入口识别、场景参数和线上事件图一起设计,让每次迭代都不只是“分数变了”,而是能解释【任务流量】到底从哪来、为什么成功、为什么失败。

极氪全新车型今日上市?车机生态繁荣催生跨屏应用深度链接基建
2026-07-28

苹果全新系统正式发布?底层隐私收紧倒逼移动端应用归因策略突围
2026-07-28

腾讯官宣QQ宠物回归?经典IP变身大模型智能体考验全链路追踪
2026-07-28

腾讯Miora向全球开放?巨头智能体生态加速多端全链路归因
2026-07-27

Kimi K3登顶前端编码榜?开源大爆发考验应用生态分发承接力
2026-07-27

Claude Opus 5全面上线?旗舰算力下放重塑应用端引流策略
2026-07-27

AMD 机架级AI系统全面投产,智能体时代算力再洗牌?
2026-07-24
Xinstall 全链路归因怎么做? 统一口径与闭环分析指南
2026-07-24
Xinstall 内链为什么无法跳转 ?跳转失败原因与排查路径解析
2026-07-24

Xinstall 跨渠道怎么归因?全链路追踪与统一口径
2026-07-23

Xinstall 安装来源怎么统计?归因恢复与链路设计
2026-07-23

上海科创板新政落地?未盈利硬科技的上市窗口怎么变
2026-07-23

iPhone18系列已量产?供应链装机归因进入重构期
2026-07-22

数据建模怎么支撑推荐?从用户特征到召回排序
2026-07-21

Xinstall 裂变拉新怎么统计?邀请关系与转化追踪
2026-07-21






















