






手机微信扫一扫联系客服
联系电话:18046269997



 APP安装免填邀请码
APP安装免填邀请码 社交分享效果统计
社交分享效果统计 广告投放数据统计
广告投放数据统计 CPA/CPS推广效果统计
CPA/CPS推广效果统计 App地推统计
App地推统计 App拉起
App拉起 网页/应用内直接安装
网页/应用内直接安装 Android多渠道打包
Android多渠道打包 App安装后自动绑定
App安装后自动绑定 App分享效果统计
App分享效果统计 Deeplink深度链接
Deeplink深度链接 手机微信扫一扫联系客服
 163
163机器点击过滤如何实现?关键不只是给异常 IP 拉黑,而是要把点击行为模式、设备指纹、CTIT、异常转化节奏和渠道质量对账一起纳入风控系统。对投放团队来说,如果先拆清点击、安装、激活和后链路数据,再结合指纹匹配与规则模型去识别黑产自动化行为,通常更容易及时拦截刷量流量,避免预算持续被无效点击吞噬。
过去两年,广告黑产最明显的变化,不是单次作弊更粗暴了,而是越来越像“正常流量”。它会模拟点击、制造安装、伪造激活,甚至让一部分前链路指标看起来比真实投放还漂亮。对开发、增长和数据团队来说,这也是为什么“机器点击过滤”突然从一个风控侧能力,变成了直接关系预算、归因和渠道判断的核心问题。
广告反作弊最近再次成为行业热点,不是因为某一家平台单独发声,而是因为整个投放生态都在同时面对一个问题:流量越来越碎,入口越来越多,黑产越来越会伪装。Cloudflare 在对点击欺诈的解释里提到,点击机器人本质上是在制造看似正常、实际上不会产生真实业务价值的广告互动,而这类无效点击会直接推高广告主成本。什么是点击欺诈?| 点击机器人如何运作 这类讨论之所以重新升温,背后是效果广告预算越来越依赖自动化分发,但自动化也给异常流量留下了更大的可乘空间。
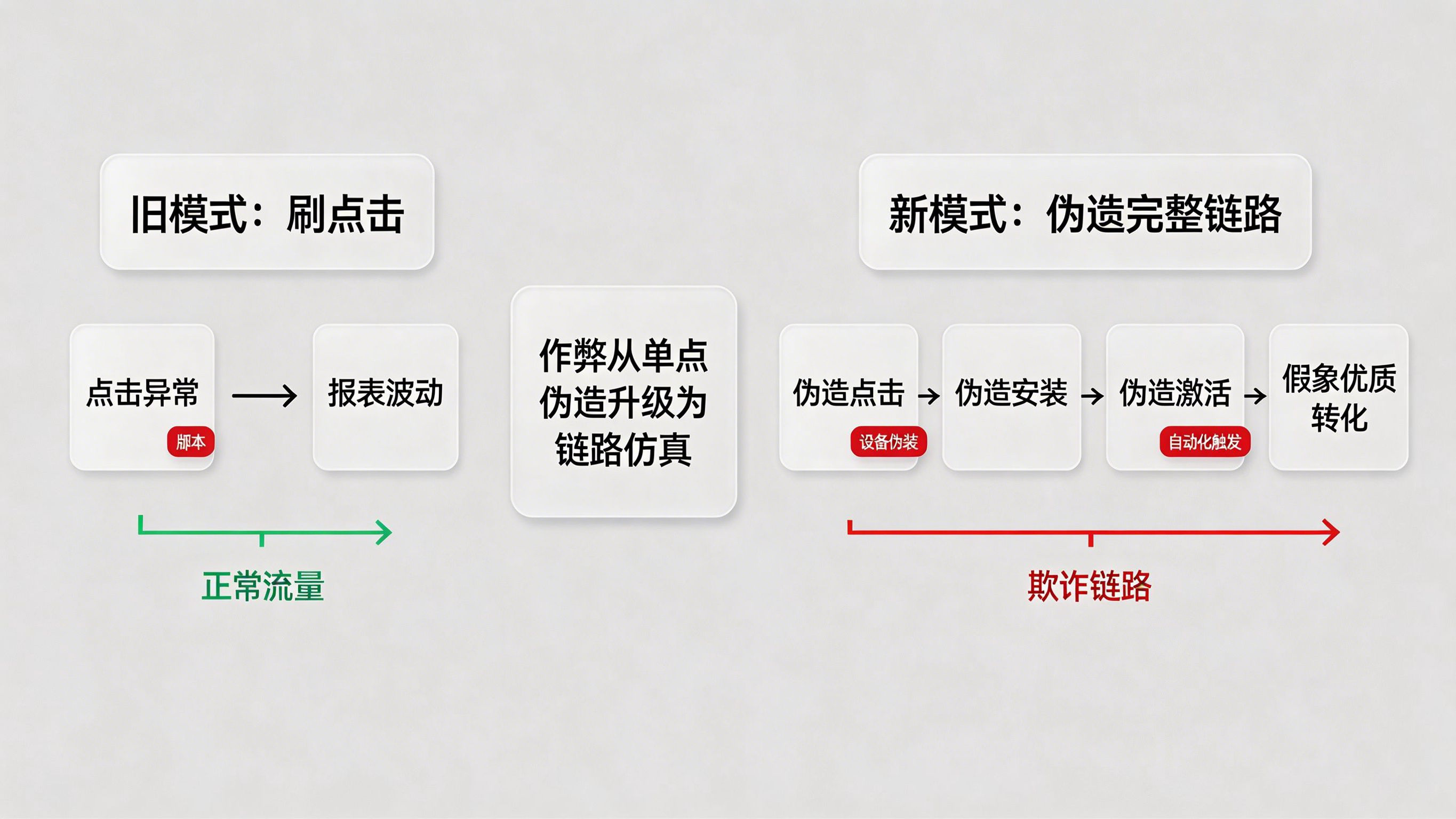
很多团队对作弊的旧印象还停留在“突然多了一堆点击”。但现在更常见的情况是,点击、安装、激活会一起被包装,甚至能在媒体报表里形成短时间内非常好看的转化曲线。阿里云在谈广告黑产反作弊时提到,广告反作弊真正要过滤的不是所有点击,而是广告主不应为之付费的那部分异常行为,这里面既包括点击层面的作弊,也包括设备伪装、环境篡改和自动化脚本造成的异常转化。技术揭秘| 互联网广告黑产盛行,如何反作弊?
这也是为什么今天再谈机器点击过滤,不能只把它理解成一个前端拦截脚本,或者一个简单的黑名单系统。它已经变成一套完整的风控工程:既要识别谁在点击,也要判断这些点击后面有没有合理的安装节奏、设备环境和后续行为。换句话说,黑产现在伪造的是“像人一样的链路”,那机器点击过滤就必须升级为“链路级识别”。
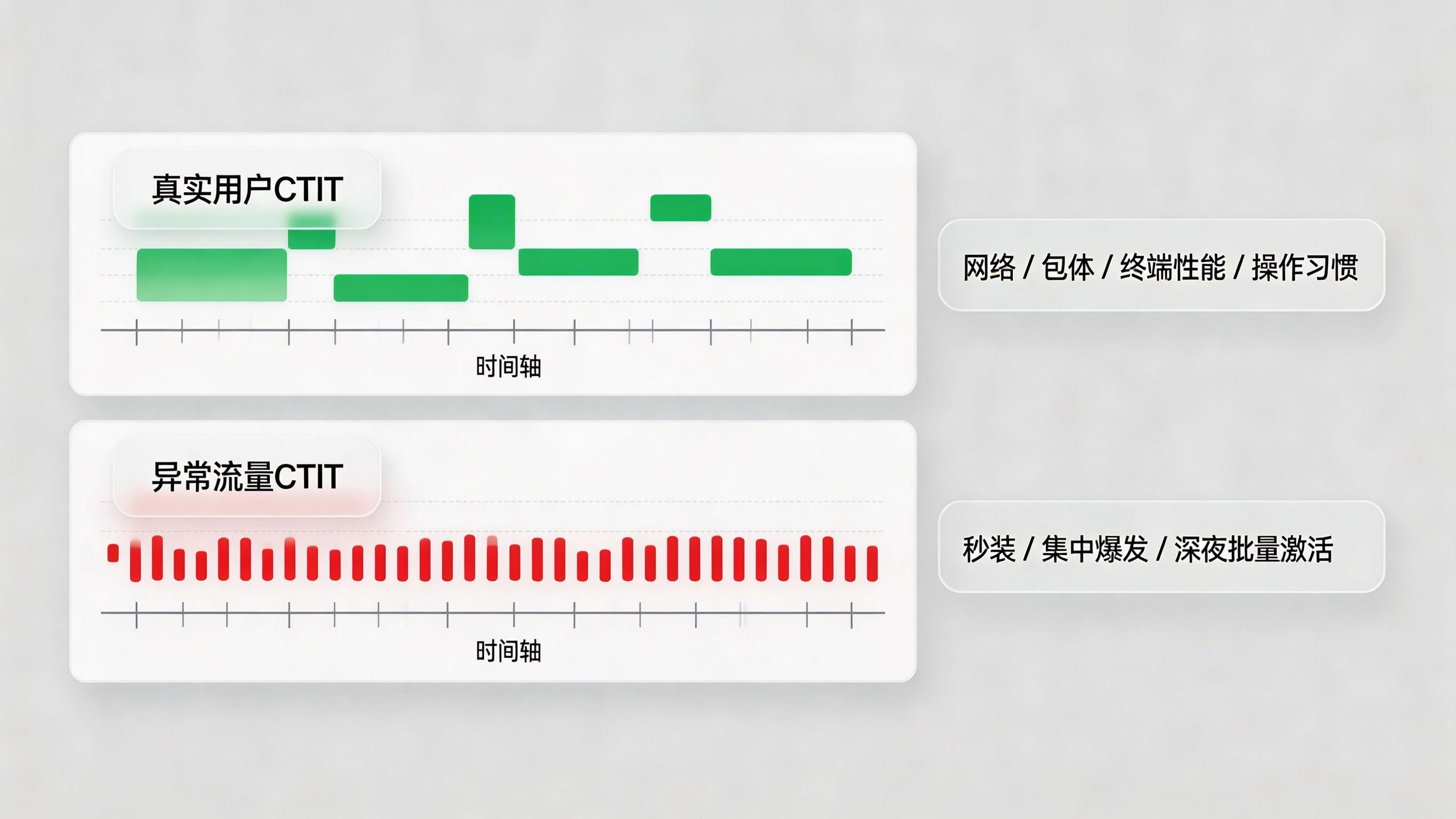
这轮讨论里另一个被频繁提到的词,是 CTIT,也就是 Click To Install Time,点击到安装时间。它之所以重新被重视,不是因为这个指标新,而是因为在越来越复杂的流量环境里,它依然是少数具备强物理约束的信号。像 Click-to-Install Time:A Key Signal to Detect Mobile Ad Fraud 这类行业分析就明确指出,CTIT 应该和点击频率、突发分布、安装后行为一起看,用来区分真实用户与异常流量。
真实用户从看到广告、点击、跳转、下载、安装到首次打开,通常会有一个相对自然的时间分布。这个分布可能因网络、包体和终端性能不同而变化,但不会长期以极端整齐、极端短时的方式出现。只要某个渠道大量出现“秒装”“集中爆发”“深夜批量激活”这类现象,团队就需要高度怀疑:这究竟是优质流量,还是自动化程序制造的高仿真链路。
再往前几年,很多团队做反作弊主要依赖单条规则,比如高频 IP、重复 UA、短时间大量点击。今天这些方法仍然有用,但越来越不够。Adobe 在机器人筛选场景中已经把机器学习和查询分析结合起来处理异常活动,说明反作弊思路正在从“单点命中”走向“多信号联合”。使用机器学习的查询服务中的机器人筛选
这背后有两个变化。第一,黑产的设备环境越来越会伪装,单条规则很容易被绕过。第二,平台型投放系统越来越依赖自动出价和自动扩量,如果异常流量能短时间骗过前链路指标,就会拿到更多预算和更多曝光。因此,机器点击过滤今天真正的难点,已经不是“有没有规则”,而是“能不能把物理环境、行为时序、设备特征和后链路一起解释”。
很多人会把广告反作弊当作媒体平台、DSP 或第三方监测工具的事情,但对 App 团队来说,这个边界正在快速消失。原因很简单:只要你在做投放、拉新、私域转化、联盟合作,最终都是你的预算在被扣、你的报表在被污染、你的渠道判断在被带偏。尤其当用户进入安装和激活链路后,很多真实信号其实掌握在 App 自己手里,而不是媒体后台手里。
也正因为如此,机器点击过滤不再只是“广告平台帮你做一点过滤”那么简单。它越来越像一个 App 团队必须自己掌握解释权的基础能力:谁带来了真实用户,谁只是带来了可疑点击;哪些转化能进归因模型,哪些应该在风控层被剔除;哪些渠道值得扩量,哪些渠道其实在消耗预算却没有业务价值。这个问题一旦想清楚,机器点击过滤就不再是技术边角料,而是增长系统的主干之一。
普通用户看这类新闻,看到的往往是“广告作弊又升级了”“黑产越来越厉害了”。但对 App 开发者、增长负责人和投放团队来说,真正棘手的问题不是新闻本身,而是用户路径已经变得比过去更难解释。
一个真实用户从被广告触达到完成安装,今天可能会经过媒体投放平台、落地页、浏览器、应用商店、安装流程、首次打开,再进入 App 内的激活和注册。看起来这是一条标准转化漏斗,但在机器流量介入之后,这条链路里每一段都可能被伪造、劫持或污染。媒体报表只能告诉你有人“点了”,应用商店只负责“装了”,而真正决定预算是否值得花的那部分信息——用户是否真实、来源是否可信、安装是否合理——往往散落在多个系统里。
这就是今天归因和埋点体系最容易失灵的地方。传统埋点关注的是功能行为,传统归因关注的是来源归属,但机器点击过滤要求团队把两者合在一起:既要看来源,也要看行为;既要看入口,也要看后果。否则就会出现一种非常危险的假象:前链路指标亮眼,后链路业务失真,团队还以为只是素材或人群没调好。
旧式归因体系往往默认“点击是真实的、安装是可信的、激活是自然发生的”。一旦这个前提不成立,整个分析结果都会被带偏。尤其在多渠道、多终端和自动化投放环境里,平台报表很容易对异常流量产生局部乐观:CTR 上升、安装暴增、成本下降,表面上看像是系统优化奏效,实际上可能只是某个入口被黑产摸到了放量逻辑。
对 App 团队来说,更麻烦的是很多关键判断都发生在黑盒之外。媒体只给你局部数据,平台只给你部分转化,渠道只会强调自己“量大价优”。如果缺少自己的机器点击过滤和归因解释体系,开发和增长团队就会长期处于“看得到结果,看不到真相”的状态。
如果把今天的 App 流量分开看,一类仍然是传统的人物流量,也就是用户主动浏览、点击、下载、安装。另一类则越来越像任务流量:自动化投放系统、聚合入口、脚本化触发和代理环境共同制造的“任务型链路”。它们并不真的理解内容,也不真的对产品有兴趣,但会为了出量、套利、骗补或薅预算而模拟一整套路径。
问题就在这里:如果团队没有在数据层把这两类流量区分开,它们在看板上可能长得非常像。机器点击过滤的现实意义,正是帮助团队重新拿回这层区分能力。否则最后看到的不是“用户在增长”,而是“任务在执行”;不是“渠道变好了”,而是“自动化脚本更懂怎么骗系统了”。
真正可用的机器点击过滤,不会只部署在某一个 SDK、某一个报表或者某一条规则上。它更像是一次工程侧的重构:把入口标识、安装过程、首启参数、行为事件和风险分层重新接起来。
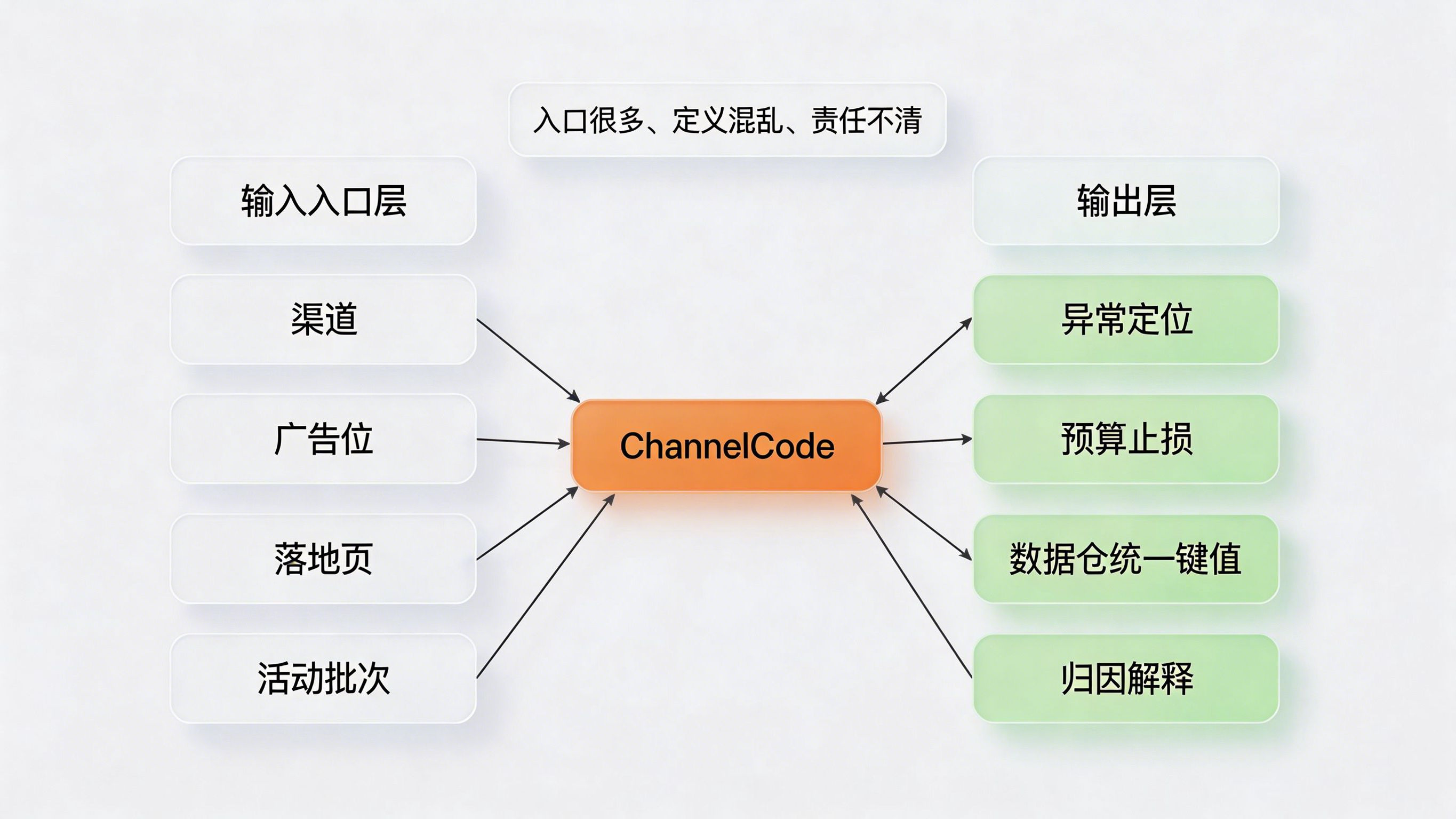
问题在于,异常流量最喜欢出现在“入口很多、定义混乱、责任不清”的地方。一个活动可能有十几个渠道、几十个广告位、多个跳转落地页,最后都汇进同一个安装口径。这样一来,团队只能看到总量异常,却很难迅速定位是哪一个入口出问题。
做法上,可以把每个投放入口统一纳入 渠道编号 ChannelCode 管理,把渠道、广告位、落地页、活动批次甚至投放策略映射成稳定的入口标识。这样机器点击过滤就不再只是按媒体或渠道商看,而是能细化到具体入口粒度。
带来的好处很直接。第一,异常流量一旦出现,团队能更快定位是哪个入口在放大问题。第二,后续不管做风控复盘还是预算止损,都能把“入口定义权”重新拿回自己手里。第三,ChannelCode 还能成为后续数据仓建模和归因解释的统一键值,不至于前链路、安装链路和后链路各说各话。
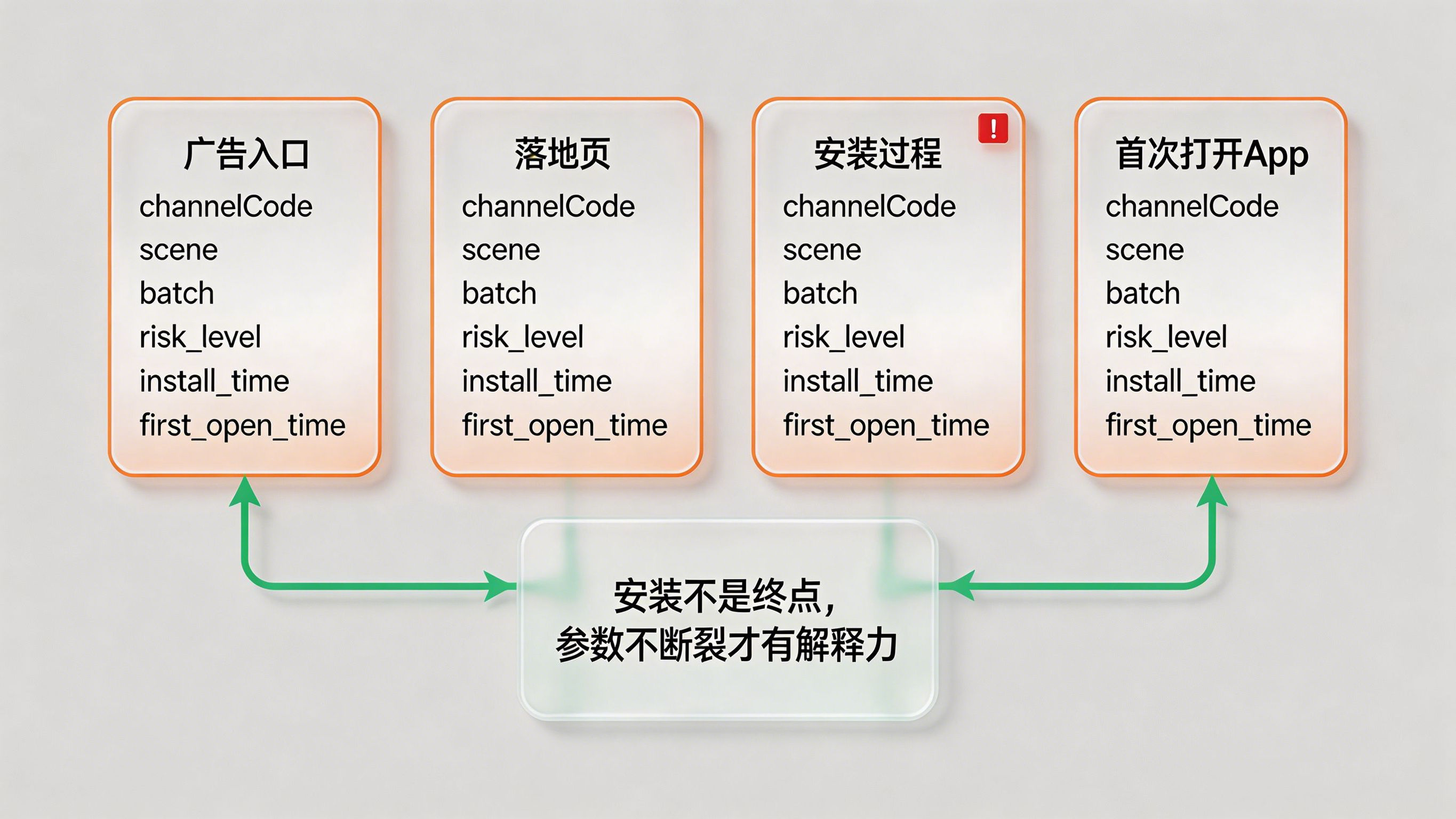
问题在于,很多异常流量不是只骗点击,它还会试图穿过安装链路,把自己伪装成“正常进来的用户”。如果安装前后的参数和场景信息丢失,团队就很难判断这次安装到底从哪个真实入口来,或者根本是不是正常入口来的。
做法上,可以在入口侧引入 智能传参 和 携参安装 方案,把渠道、场景、批次、风险等级等关键参数稳定带入安装与首启过程。这样在用户第一次打开 App 时,系统不只知道“有人装了”,还知道“这个人是从哪个入口、什么场景、哪类活动链路进入的”。
带来的好处是,机器点击过滤终于不再只看点击层,而能把“入口上下文”延续到安装后。这样一来,一些表面上来自正常媒体、实际上来自高风险入口的异常安装就更容易被识别出来;同时,真实用户路径也不会因为参数断裂而被误判成异常流量。
问题在于,很多团队即便有了点击、安装、激活和注册数据,仍然很难把它们真正连成一张图。原因不是字段不够多,而是字段没有统一语义:入口系统有一套命名,App 埋点有一套命名,风控系统又是另一套风险标签,最后谁也没法完整解释一条链路。
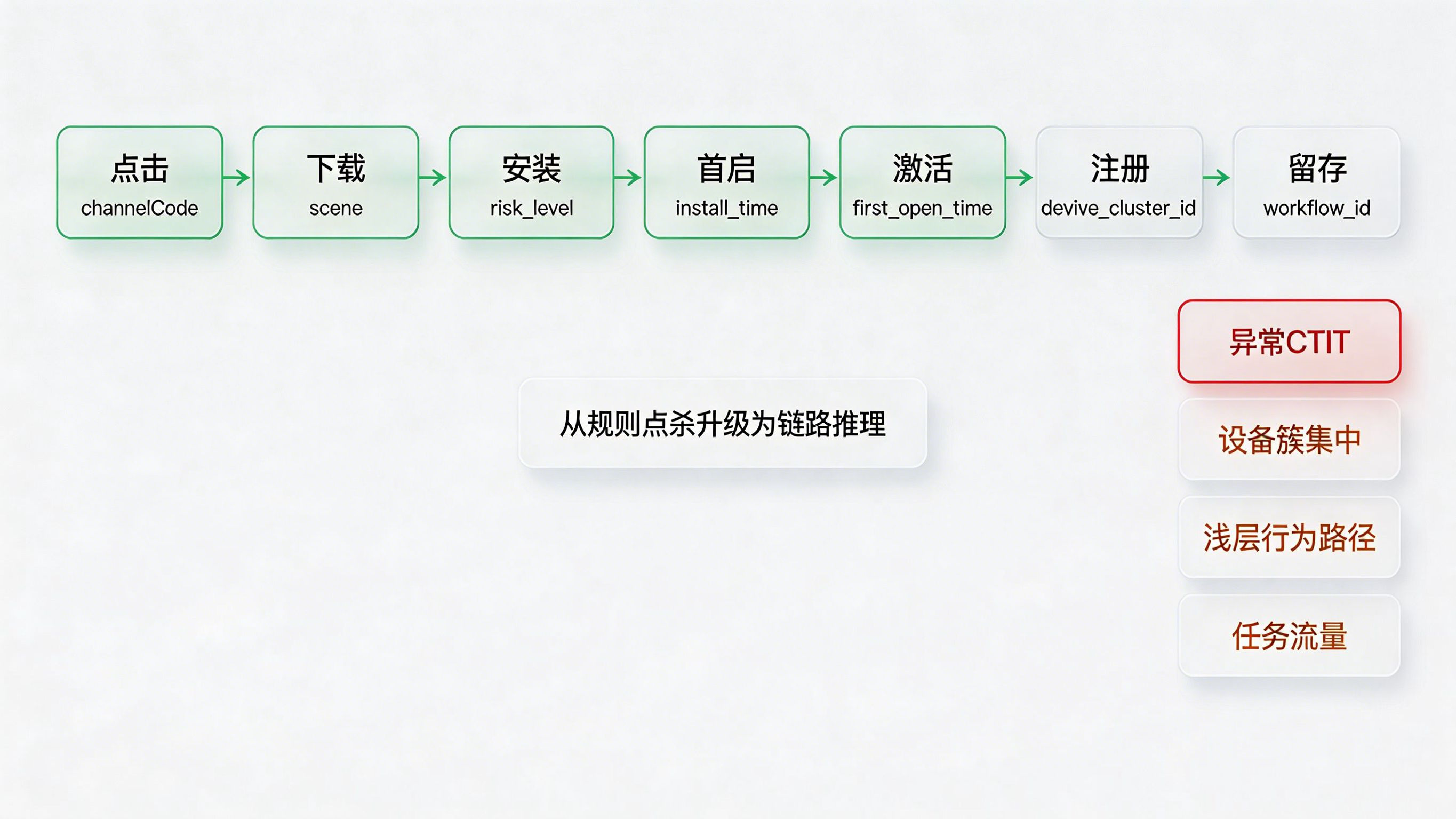
做法上,应该把点击、下载、安装、首启、激活、注册、留存这些事件统一映射到一个跨链路事件图里,核心字段至少包括:channelCode、scene、risk_level、install_time、first_open_time、device_cluster_id、agent_platform(若涉及自动化任务流量)、workflow_id 等。这样无论是人物流量还是任务流量,都能放在同一套事件模型中观察。
带来的好处,是机器点击过滤第一次从“规则点杀”升级为“链路推理”。你不再只是看某个 IP 可疑,而是能看到某个入口下的某类设备簇、在某一时间段、通过某种不自然 CTIT 模式、进入某个浅层行为路径。那时风控结果才真正变成增长团队能用的判断结果。
注:本文探讨的部分跨系统、跨平台、任务化流量识别场景,属于对未来分发趋势的前瞻性技术延展与思考,例如渠道精细化归因、跨平台一键拉起、任务流量识别与私域链路优化等方向。目前此类高度定制化链路并非都以标准化功能全量实现,如 App 团队有更复杂的高阶需求,适合结合具体业务场景做技术方案设计或定向扩展。
机器点击过滤看起来像风控问题,但真正落地时,最先需要动作的往往是开发、产品和增长团队。
开发团队现在最该做的,不是先写一大堆拦截规则,而是先确认“系统到底能不能看见关键链路”。建议至少预留几类字段:
这些字段的意义不在于一次性全用上,而在于给后续排查和归因留出解释空间。没有字段,机器点击过滤就只能靠猜;字段设计合理,很多问题会在第一轮对账时自己暴露出来。
很多团队真正吃亏,不是因为不会投,而是因为入口定义完全被外部平台牵着走。今天说按渠道看,明天说按广告组看,后天又只剩媒体回传口径,最后内部谁也说不清一个“新增”到底来自哪一层。
产品和增长团队现在可以做的,是把入口标准化。统一活动命名、统一渠道粒度、统一归因周期、统一风险回流口径。只要这几件事做起来,机器点击过滤的结果才不会停在技术后台,而能真正影响投放策略。比如某个入口短期点击很好,但 risk_level 持续走高、后链路质量持续偏低,就不该继续机械放量。
因为 CTIT 具备较强的物理约束。真实用户从点击广告到完成安装,通常会受到网络、下载速度、包体大小和操作习惯影响,因此时间分布会有自然波动。若某个渠道长期出现极短、极整齐、极集中的安装节奏,就很可能不是正常用户行为,而是脚本或注入行为在批量触发。
远远不够。IP 只能算低层信号,今天的黑产很容易通过代理、云环境和设备池切换网络特征。真正有效的机器点击过滤,往往要把设备指纹、CTIT、行为序列、安装后深度和入口场景一起看,才能减少误伤和漏判。
因为点击高不代表真实价值高。某些渠道可以通过异常流量把前链路指标做得很好看,但一到安装、激活、注册或留存阶段就开始坍塌。这种“前链路繁荣、后链路失真”的情况,正是机器点击过滤要优先识别的对象。
广告反作弊这轮重新升温,表面看是在讨论黑产,实质上是在倒逼整个分发体系重构“什么才算有效流量”。过去行业可以默认点击大致可信、安装大致可信、平台报表大致可信;现在这些前提都在松动。只要入口越来越多、自动化投放越来越深、任务化流量越来越常见,App 团队就必须建立自己的解释系统,而不能只依赖外部平台给出的结果。
对 B 端团队来说,这件事的中长期影响不只在于止损。它还会决定你的归因模型是否可信、投放策略是否稳定、渠道结构是否健康,以及数据团队能不能真正对增长结果给出解释。很多团队过去把反作弊当成本中心,但接下来它更像一个增长底座:你先过滤掉错误信号,后面的优化才有意义。
也正因为如此,现在是重构数据和归因体系的窗口期。谁先把入口标识、安装场景、首启参数、风险标签和后链路事件接起来,谁就更早拥有判断真流量与假增长的能力。对今天的 App 团队来说,机器点击过滤已经不只是“防刷量”的补丁,而是在新分发生态里重新拿回流量解释权的起点,这也是为什么机器点击过滤会从一个边缘能力,变成增长系统的主干能力。

Xinstall 免填邀请码怎么实现 ?携带参数安装底层架构解析
2026-07-28

Xinstall 跳转失败怎么排查? 内链失效与唤起链路治理指南
2026-07-28

极氪全新车型今日上市?车机生态繁荣催生跨屏应用深度链接基建
2026-07-28

苹果全新系统正式发布?底层隐私收紧倒逼移动端应用归因策略突围
2026-07-28

腾讯官宣QQ宠物回归?经典IP变身大模型智能体考验全链路追踪
2026-07-28

腾讯Miora向全球开放?巨头智能体生态加速多端全链路归因
2026-07-27

Kimi K3登顶前端编码榜?开源大爆发考验应用生态分发承接力
2026-07-27

Claude Opus 5全面上线?旗舰算力下放重塑应用端引流策略
2026-07-27

AMD 机架级AI系统全面投产,智能体时代算力再洗牌?
2026-07-24
Xinstall 全链路归因怎么做? 统一口径与闭环分析指南
2026-07-24
Xinstall 内链为什么无法跳转 ?跳转失败原因与排查路径解析
2026-07-24

Xinstall 跨渠道怎么归因?全链路追踪与统一口径
2026-07-23

Xinstall 安装来源怎么统计?归因恢复与链路设计
2026-07-23

上海科创板新政落地?未盈利硬科技的上市窗口怎么变
2026-07-23

iPhone18系列已量产?供应链装机归因进入重构期
2026-07-22






















