






手机微信扫一扫联系客服
联系电话:18046269997



 APP安装免填邀请码
APP安装免填邀请码 社交分享效果统计
社交分享效果统计 广告投放数据统计
广告投放数据统计 CPA/CPS推广效果统计
CPA/CPS推广效果统计 App地推统计
App地推统计 App拉起
App拉起 网页/应用内直接安装
网页/应用内直接安装 Android多渠道打包
Android多渠道打包 App安装后自动绑定
App安装后自动绑定 App分享效果统计
App分享效果统计 Deeplink深度链接
Deeplink深度链接 手机微信扫一扫联系客服
 206
206当AI生成内容必须“亮明身份”,平台合规要求已从内容审核前移到生成、分发与展示全链路;这篇文章面向开发者与增长团队,拆解标识监管加码背后的4.3层数据可见性与归因重构压力。
工信部约谈剪映、猫箱、即梦AI网站等平台,表面上看是一次 AI 内容标识合规整改,实质上却是在重画生成式内容平台的责任边界。对 App 团队来说,这件事影响的不只是“要不要打标”,而是内容从生成、流转到分发的全链路都开始被要求可识别、可解释、可回溯,这会直接改变【数据归因】的设计逻辑。

近期,网信部门发现“剪映”“猫箱”App 及“即梦AI”网站存在未有效落实人工智能生成合成内容标识规定要求等问题,违反了《网络安全法》《生成式人工智能服务管理暂行办法》《人工智能生成合成内容标识办法》等规定,并已依法对相关平台采取约谈、责令改正、警告、从严处理责任人等处置措施。
这意味着 AI 内容标识要求已经从规则发布阶段,进入实际检查和处罚阶段。平台不能再把“标识”理解为一个可选优化项,而要把它当作正式的合规义务。
《人工智能生成合成内容标识办法》明确提出,人工智能生成合成内容标识包括显式标识和隐式标识两类。显式标识是用户能直接感知到的文字、声音、图形提示;隐式标识则是写入内容文件数据、用于追溯和防篡改的技术性标识。
这说明监管关注点已经从“平台是否提供生成能力”转向“生成内容在传播过程中是否始终带着身份信息”。换句话说,治理对象已经从模型能力本身,延伸到了内容流转链路。
这次被处置的平台并不是边缘产品。剪映覆盖视频编辑与创作,即梦AI覆盖图像和视频生成,猫箱则对应 AI 互动娱乐与角色内容生成。它们代表的正是当下 AI 内容最活跃、最容易大规模传播、也最容易跨平台扩散的几类入口。
也正因为这些产品不只是工具,而是内容生产和内容分发的上游节点,所以监管动作的影响不会停留在单个功能层面,而会外溢到推荐、分享、投放和增长分析体系里。
很多团队第一反应会觉得,AI 生成内容标识就是给图片、视频或文本加一个角标。但如果只这么理解,就低估了这次规则的影响。
因为显式标识和隐式标识是同时成立的:前者负责让用户看见,后者负责让系统识别、平台核验和链路追踪。它本质上不是一个前端视觉问题,而是一种贯穿内容生产、发布、分发、分享和回流全过程的身份字段。
只要内容会跨页面、跨账号、跨平台流转,平台就必须考虑这些身份信息能否被保留、透传和回查。
这次监管动作释放出的关键信号是,平台未来不能只证明“我们有生成能力”,还要证明“我们知道哪些内容是生成的、如何生成的、有没有按规定展示和保留标识”。
也就是说,平台责任正在从“内容出问题后再处理”,前移到“内容一生成就要进入责任链管理”。生成能力越强的平台,越需要提前设计这条链。
过去很多 App 在做增长、推荐和内容管理时,更关注谁发了内容、发到哪、带来多少点击和转化。可在 AI 生成内容时代,平台还必须知道另一层信息:这条内容是人原创、AI 辅助,还是 AI 全生成;它经过二次编辑后是否仍保留原始生成属性;它在分享、保存、转载后,这层属性有没有丢。
一旦这层信息不清楚,平台面对的就不只是审核难题,更是推荐逻辑、广告投放和效果分析都会一起失真。这也是为什么这次监管动作,最终会传导到【数据归因】问题上。
传统 App 的归因思路,大多围绕“这个用户从哪个渠道来”“这次安装来自哪次投放”“哪条内容带来了转化”来设计。可 AI 生成内容标识监管收紧后,平台要额外回答的问题变成了:
也就是说,归因对象正在从“人和渠道”扩展到“内容和来源”。
如果一条短视频最初由 AI 生成,再经过人工编辑、站内分发、站外分享、深链回流到 App,你过去看到的也许只是一次点击和一次安装;但在新的监管要求下,你还得知道:这次触达依赖的素材是不是 AI 生成、是否完成打标、是否在各环节保留了隐式身份。
这对内容平台、工具平台、电商带货平台尤其关键。因为它们的很多增长动作,本质上依赖内容传播。内容一旦成为主要入口,内容身份本身就必须进入归因体系。否则你可能知道“用户从短视频来”,却不知道他是从一条合规标识完整的内容来,还是从一条身份信息已经丢失的合成内容来。
所以这次事件真正提示行业的是:未来的【数据归因】不再只是流量归因,而是“流量 + 内容身份 + 分发责任”的复合归因。谁能把内容标识字段、分发链路和结果事件串起来,谁才真正具备下一阶段的内容平台治理能力。
问题:很多团队的渠道归因只区分广告平台、自然流量、社交分享和应用商店,却没有把内容本身的生产方式纳入来源结构。AI 时代这会变成盲区,因为“来自短视频”已经不够,平台还需要知道“来自哪类内容生产链”。
做法:可以先用渠道编号 ChannelCode把入口进一步拆细,例如 ai_full_generate、ai_assisted_edit、ugc_manual_create、creator_template_mix、ad_creative_auto_gen 等不同来源层级,再配合 content_type、model_flag、scene、risk_level 等字段记录。这样后续无论做内容分发、广告监测还是安装归因,都能先分清“流量是谁带来的”以及“内容是怎么来的”。
带来的好处:一旦某类 AI 素材触发合规风险,团队可以快速定位影响范围;而当某类内容带来更高转化时,也能避免把效果误归因给平台流量本身,而忽略内容生产方式差异。

问题:很多平台即便前端给内容打了标,到了分享、拉起、落地页、安装和注册环节,这个状态也很容易丢失。最终 BI 系统只能看到行为结果,看不到内容的标识状态与生成属性。
做法:更适合的方式,是用智能传参把 ai_flag、content_origin、channelCode、scene、risk_level、trace_id、compliance_status 等信息跟随链接、落地页和安装链路传递下去。也可以参考 xinstall 在《智能体分发时代 App 安装传参逻辑的底层重构》中强调的思路:真正有价值的不是传一个来源名,而是保留进入动作背后的上下文。
带来的好处:团队后面分析转化时,就不只是看到“某条内容带来了安装”,而是能知道“某类已打标 AI 内容 / 某类未打标风险内容 / 某类人工内容”分别带来了什么结果。
注:本文讨论的部分内容身份透传、合规状态回流、跨平台生成内容来源映射等方向,属于对未来分发趋势的前瞻性技术延展与思考,例如内容级来源识别、复杂场景参数回传、内容分发链路审计等前沿应用方向。目前此类高度定制化链路并不等同于标准化全量现成功能,如有类似高阶业务需求,可结合具体业务与 Xinstall 团队进一步探讨。
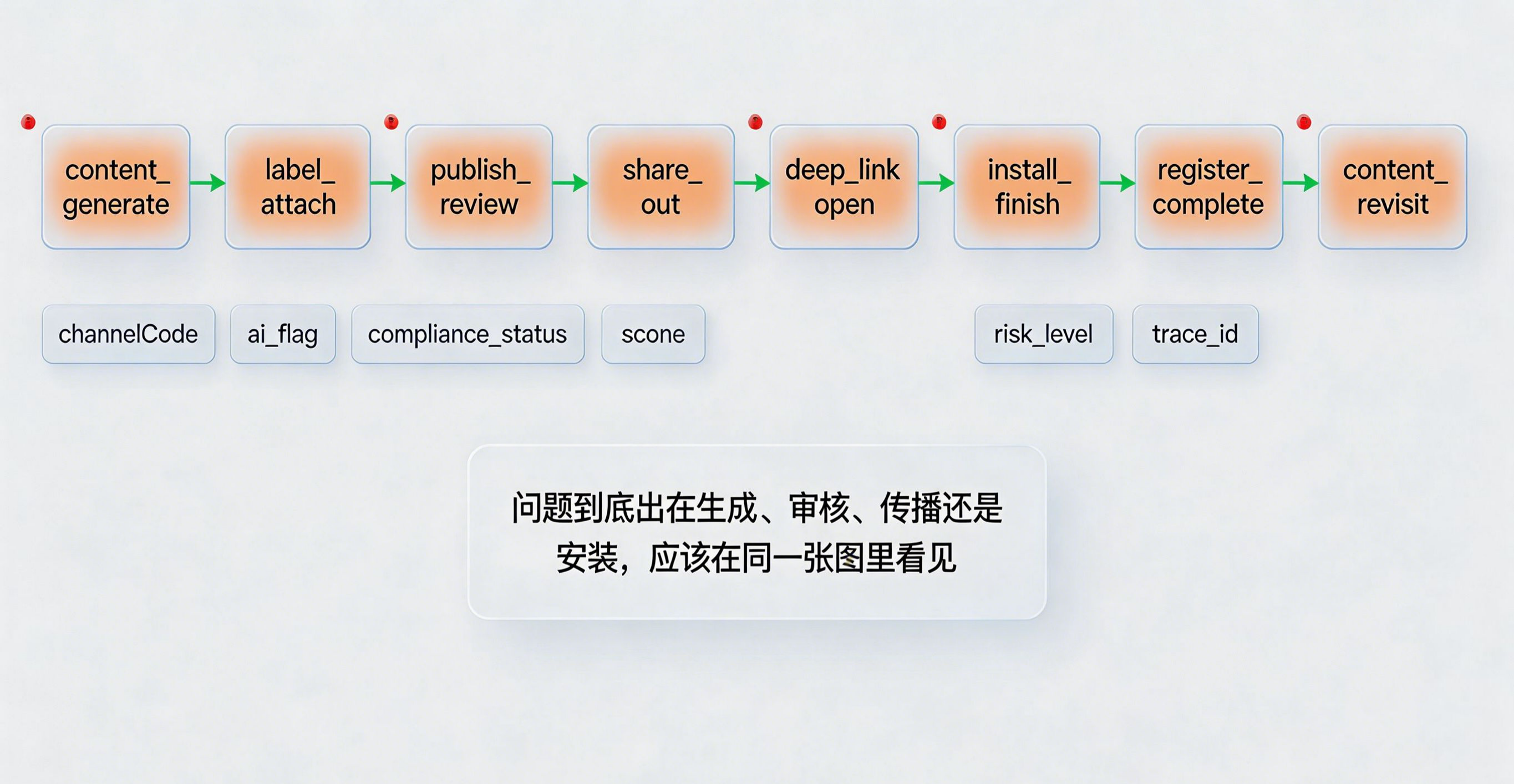
问题:如果平台的看板还停留在曝光、点击、下载、激活、留存这些指标,就很难回答监管和业务同时关心的问题:问题出在生成、审核、发布、分享,还是安装回流环节。
做法:可以把事件链扩展成 content_generate、label_attach、publish_review、share_out、deep_link_open、install_finish、register_complete、content_revisit 等节点,并给每个节点统一挂上 channelCode、ai_flag、compliance_status、scene、risk_level、trace_id 等字段。
带来的好处:当监管要求平台解释“这类 AI 内容是否已完成打标并进入传播”时,团队不需要再临时翻日志拼链路,而是本来就有一张可回溯的任务图。这对今天的生成式内容平台来说,价值会越来越大,因为内容传播本身已经变成一种可监管的任务流量。
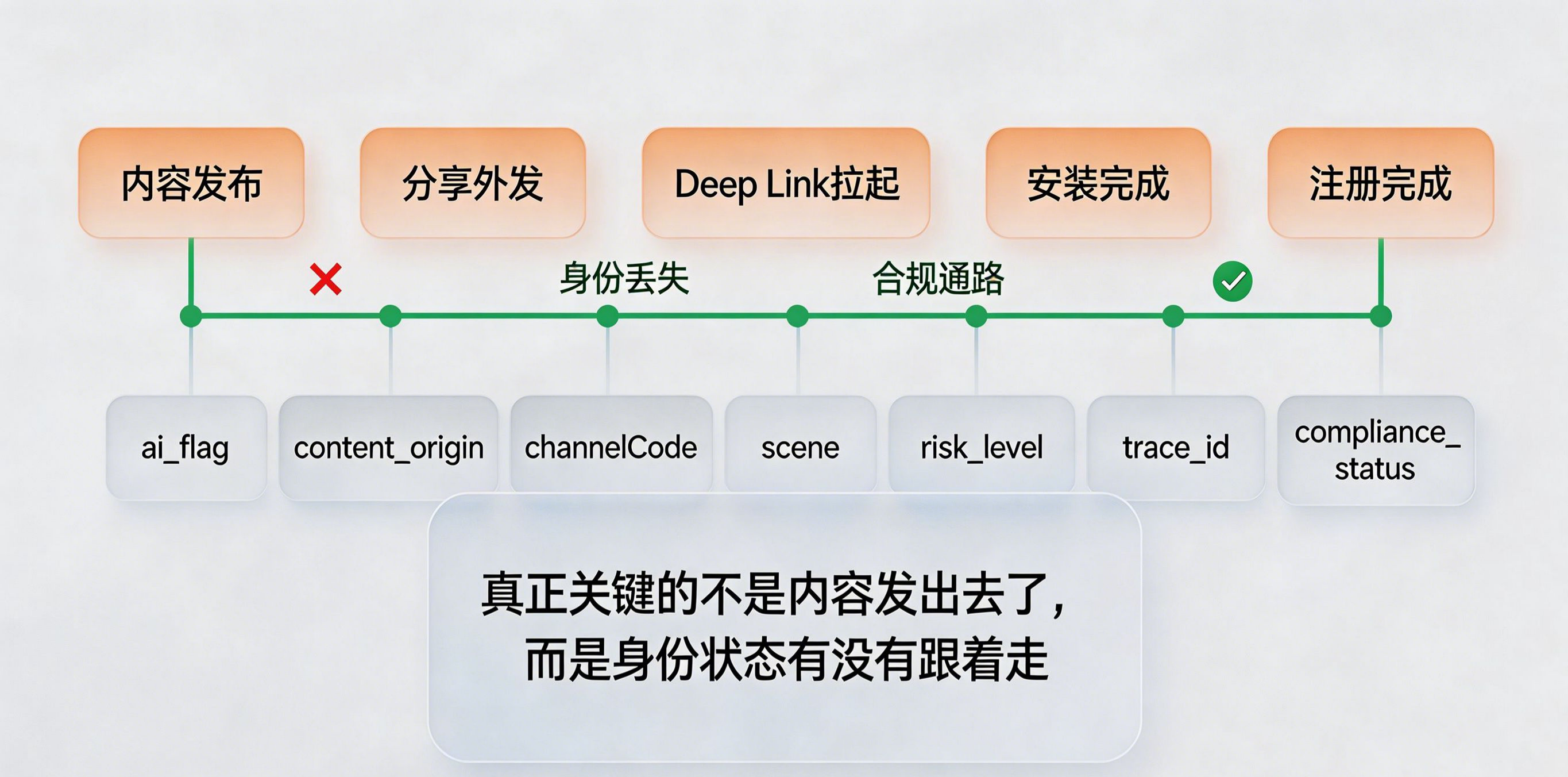
现在最值得做的,不是等监管细则进一步细化,而是先把“内容身份字段”纳入现有埋点与链路设计。
建议优先补充这些字段:
这些字段未来不只是合规所需,也会成为解释内容效果与分发质量的基础。
产品经理不能再把“AI 打标”看成审核团队的事。它会影响内容发布规则、推荐策略、分享链路、创作者工具提示,甚至会影响转化分析报表的结构。
现在可以先问三个问题:
增长团队最容易忽略的是,未来某些高转化内容未必都能被同样对待。因为一旦监管把内容身份纳入平台责任链,单纯追求转化率而忽略内容来源合规,风险会直接传导到业务。
所以更现实的做法是:
核心不是平台使用了 AI,而是没有有效落实 AI 生成合成内容标识要求。监管部门认定相关平台违反了《网络安全法》《生成式人工智能服务管理暂行办法》《人工智能生成合成内容标识办法》等规定,并已采取约谈、责令改正、警告等措施。
目前公开规则明确,AI 生成合成内容需要添加显式标识和隐式标识。平台在内容上架或上线时也要进行审核和核验,对未标识或疑似生成内容采取相应处理。
因为一旦内容身份成为监管对象,平台就不能只追踪用户来自哪个渠道,还要知道这次触达依赖的是哪类内容、是否为 AI 生成、标识状态是否完整。也就是说,归因维度从“流量来源”扩展成了“流量来源 + 内容身份”。
短视频编辑、AIGC 创作、互动娱乐、营销素材生成、电商带货等高度依赖 AI 生成内容并且传播链路长的平台,会更早感受到压力,因为它们最容易遇到内容跨场景流转和身份信息丢失的问题。
“剪映、猫箱、即梦AI被约谈”之所以值得行业认真看,不是因为它点名了几款热门产品,而是因为它释放了一个非常明确的信号:AI 平台的责任,正在从“提供生成能力”扩展到“保证内容身份在全链路上可识别”。这会倒逼平台重新设计内容字段、分发逻辑、分享参数和数据看板。
对 App 与企业系统团队来说,这也是一次很典型的系统前移。以前大家觉得合规是审核端的问题,现在会越来越像是底层数据架构问题;以前归因主要围绕广告和渠道,未来则必须把内容身份和传播责任一起纳入【数据归因】体系。谁更早完成这层升级,谁就更能在生成式内容平台的新规则里站稳。

Xinstall 免填邀请码怎么实现 ?携带参数安装底层架构解析
2026-07-28

Xinstall 跳转失败怎么排查? 内链失效与唤起链路治理指南
2026-07-28

极氪全新车型今日上市?车机生态繁荣催生跨屏应用深度链接基建
2026-07-28

苹果全新系统正式发布?底层隐私收紧倒逼移动端应用归因策略突围
2026-07-28

腾讯官宣QQ宠物回归?经典IP变身大模型智能体考验全链路追踪
2026-07-28

腾讯Miora向全球开放?巨头智能体生态加速多端全链路归因
2026-07-27

Kimi K3登顶前端编码榜?开源大爆发考验应用生态分发承接力
2026-07-27

Claude Opus 5全面上线?旗舰算力下放重塑应用端引流策略
2026-07-27

AMD 机架级AI系统全面投产,智能体时代算力再洗牌?
2026-07-24
Xinstall 全链路归因怎么做? 统一口径与闭环分析指南
2026-07-24
Xinstall 内链为什么无法跳转 ?跳转失败原因与排查路径解析
2026-07-24

Xinstall 跨渠道怎么归因?全链路追踪与统一口径
2026-07-23

Xinstall 安装来源怎么统计?归因恢复与链路设计
2026-07-23

上海科创板新政落地?未盈利硬科技的上市窗口怎么变
2026-07-23

iPhone18系列已量产?供应链装机归因进入重构期
2026-07-22






















