






手机微信扫一扫联系客服
联系电话:18046269997



 APP安装免填邀请码
APP安装免填邀请码 社交分享效果统计
社交分享效果统计 广告投放数据统计
广告投放数据统计 CPA/CPS推广效果统计
CPA/CPS推广效果统计 App地推统计
App地推统计 App拉起
App拉起 网页/应用内直接安装
网页/应用内直接安装 Android多渠道打包
Android多渠道打包 App安装后自动绑定
App安装后自动绑定 App分享效果统计
App分享效果统计 Deeplink深度链接
Deeplink深度链接 手机微信扫一扫联系客服
 421
421斯坦福《2026年AI指数报告》显示中美顶级模型差距缩至2.7%,AI 组织采用率已达88%。对开发者与增长团队来说,这意味着多模型、多Agent、多终端入口正在重塑分发链路,也让全渠道归因变得比过去重要4.7倍。
斯坦福 HAI 刚刚发布的《2026年AI指数报告》,把全球 AI 竞争的一条关键暗线直接摆到了台面上:中美顶级模型性能差距已经收敛到 2.7%,AI Agent 在真实计算机任务上的成功率也从 12% 跃升到 66%。对大众来说,这是一份关于“AI 继续变强”的年度成绩单;但对 App 开发者、产品经理和增长负责人来说,更现实的问题是——当模型能力越来越接近、Agent 越来越多、入口越来越分散时,全渠道归因 到底该怎么跟上这场变化?
这份由斯坦福大学以人为本人工智能研究所发布的《2026年AI指数报告》,延续了过去几年“用大样本数据审视 AI 产业演化”的方法论。根据斯坦福 HAI 官方发布页,这一版报告强调的核心主题是:AI 的能力仍在快速提升,但人类对 AI 的衡量、治理与管理能力,并没有同步进化,二者之间的落差正在扩大。《The 2026 AI Index Report》
从公开摘要与媒体整理来看,这份报告最受关注的,不只是“模型又变强了”,而是几个足够有结构变化意味的结论同时出现:第一,2025 年产业界贡献了超过 90% 的前沿模型;第二,SWE-bench Verified 这类编码基准在一年内出现了从 60% 接近 100% 的大幅跳升;第三,中美模型能力差距已经收敛到接近“肉眼难辨”的程度;第四,AI Agent 在真实任务里的可用性显著提升,但在结构化任务上仍存在大量失败样本。《Inside the AI Index: 12 Takeaways from the 2026 Report》 量子位《斯坦福年度结论:中美大模型已没差距》
如果只看单一指标,这份报告并不稀奇;真正值得关注的是,这些指标被放在同一页上以后,清晰地指向了一个事实:AI 正在从“少数模型公司之间的竞速”,进入“能力扩散、入口重组、竞争平权”的阶段。
过去几年,行业一直习惯用“美国领先、中国追赶”的线性叙事去理解模型竞争。但在这份报告里,斯坦福给出的判断已经不是“仍有差距但在缩小”,而是更接近“effectively closed”,也就是中美顶级模型性能差距已基本消失。量子位《斯坦福年度结论:中美大模型已没差距》
报告提到,自 2025 年初以来,中美模型已经多次在性能排名顶端交替领先。到 2026 年 3 月,美国顶级模型仅领先中国模型 2.7%。这个数字背后的含义非常直接:今后决定产品竞争力的变量,不会再只是“你接的是哪家模型”,而会越来越多转移到“你怎么把模型接进产品”“你通过什么入口被用户触达”“你能不能把模型输出转化为真正可观测、可复用的业务链路”。《The 2026 AI Index Report》 TechWeb 转载稿
换句话说,模型能力差距缩小,反而会把“分发能力”“产品连接能力”“流量识别能力”推到台前。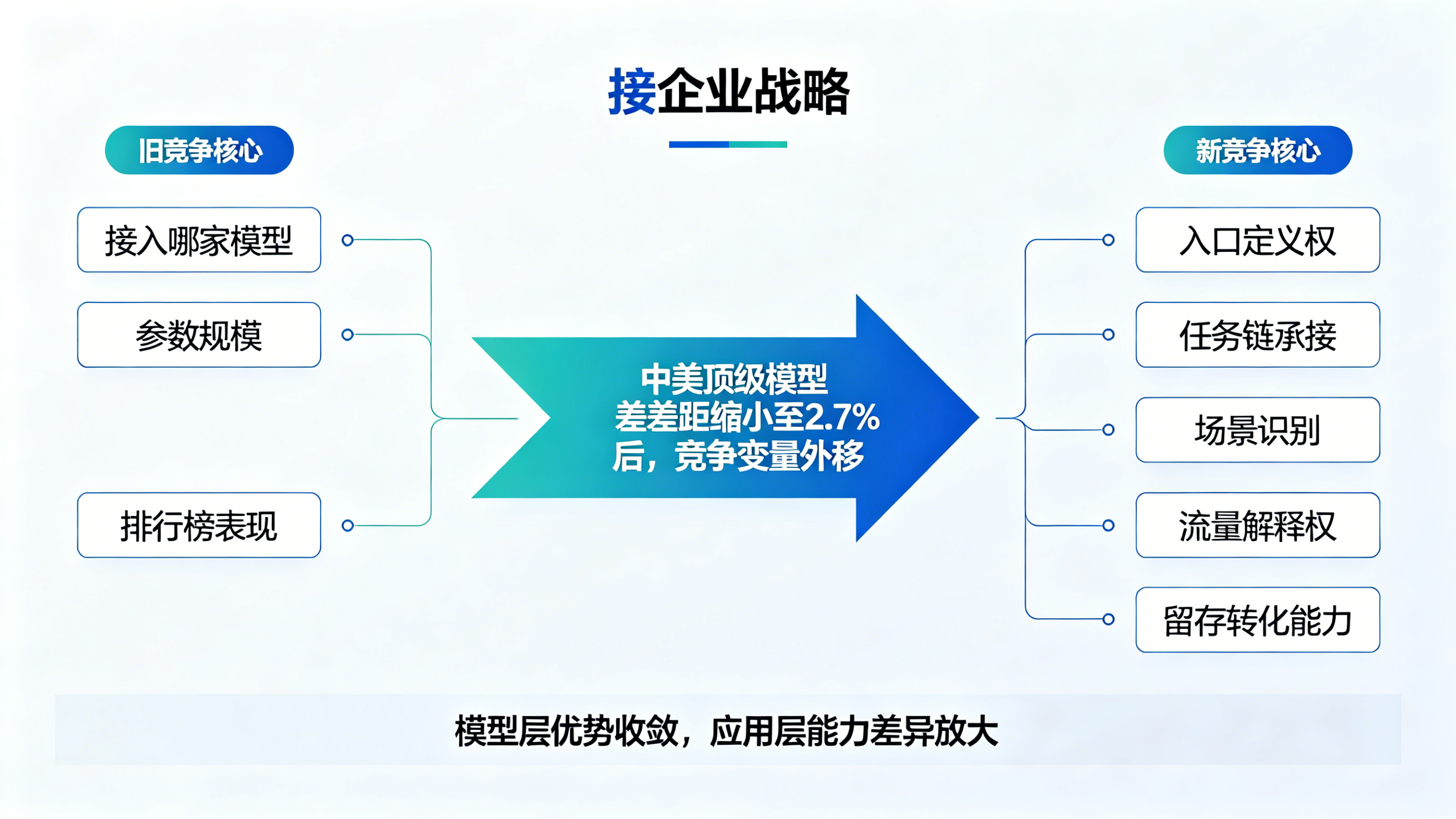 以前大家争的是模型智商,现在开始争的是谁能把模型最快送到对的人手里,并且知道这些人是从哪里来的、为什么来的、最终有没有留下来。
以前大家争的是模型智商,现在开始争的是谁能把模型最快送到对的人手里,并且知道这些人是从哪里来的、为什么来的、最终有没有留下来。
这份报告并没有简单得出“中美完全没有差别”的结论。恰恰相反,它给出的是一种更复杂、更接近真实产业结构的对比。
美国依旧在若干关键维度保持强势,例如更高数量的“值得注意的模型”、更多高影响力专利、规模远超中国的私人 AI 投资,以及庞大的数据中心基础设施。报告中提到,美国拥有 5427 个数据中心,数量超过其他任何国家 10 倍以上;2025 年美国私人 AI 投资达到 2859 亿美元,是中国的 23 倍以上。《The 2026 AI Index Report》 新浪财经《2026斯坦福AI指数报告:美国AI投资规模是中国的23倍》。
但中国也并不是“单点突破”,而是在另一套维度上形成了密集优势。公开信息显示,中国在 AI 论文发表量、引用量、专利总量以及工业机器人安装量上处于领先位置。仅工业机器人这一项,2024 年中国安装量达到 29.5 万台,占全球 54%。这意味着,中国在“AI 落地密度”和“产业连接广度”上,已经建立起不容忽视的基本盘。TechWeb 转载稿。
对 App 团队来说,这种格局变化有一个特别重要的外溢影响:模型层的竞争,会更快演变成入口层、渠道层和终端层的竞争。美国强在基础设施和资本密度,中国强在落地密度和应用生态;最终,谁更能把模型输出转译成实际任务流量,谁就更容易在应用层先拿到用户。
很多人看这份报告,第一眼会被“2.7%”吸引;但从产品与增长的角度看,更有杀伤力的其实是另一组数据:AI Agent 在真实计算机任务上的成功率,已经从 12% 跃升到了 66%。《Inside the AI Index: 12 Takeaways from the 2026 Report》。
这意味着什么?意味着 Agent 不再只是“演示视频里的自动化助手”,而正在变成有机会真正替代一部分交互动作、页面跳转和人工操作的任务发起者。用户不一定亲手点开 App、搜索功能、逐步完成路径;未来更常见的情况,可能是用户把需求交给一个 Agent,由 Agent 去完成查找、比较、填写、下单、跳转、回访这一整段链路。
一旦 Agent 成为新的中间层,传统以“页面访问—按钮点击—注册转化”为核心的分析框架,就会开始失真。因为此时产生的,已经不只是人物流量,而是更难识别的任务流量:是谁发起的、通过哪个模型发起的、在哪个平台发起的、调用了几次、有没有跨端跳转、最终有没有回流到原 App,这些都成了新的数据难题。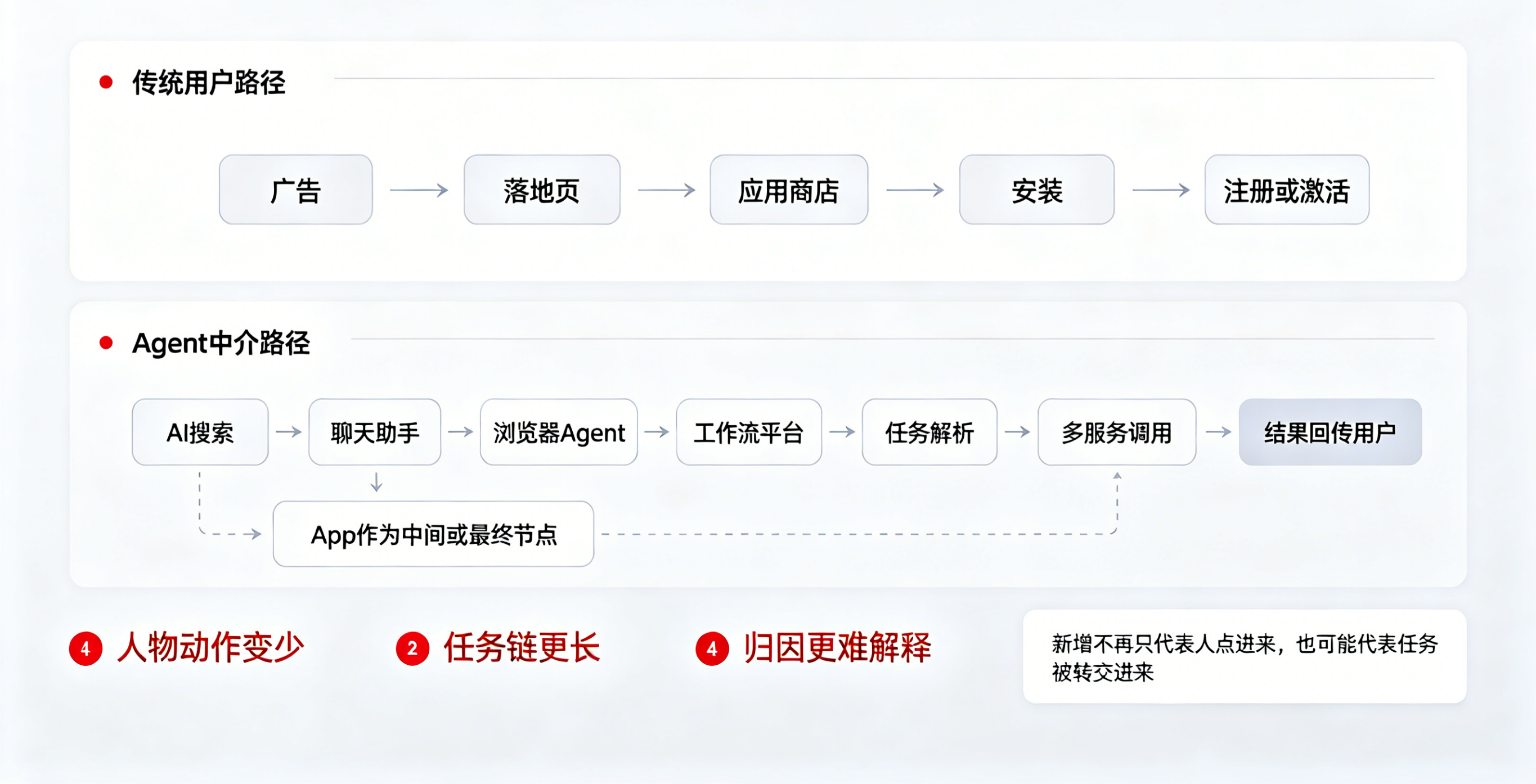
斯坦福报告还有一个非常关键的观察:AI 的进步不是线性平滑的,而是呈现“锯齿状前沿”。模型可以在国际数学奥赛相关能力上表现惊艳,但在读取模拟时钟这种基础任务上依然可能表现不稳定,顶级模型准确率只有 50.1%,而人类是 90.1%。《Inside the AI Index: 12 Takeaways from the 2026 Report》。
这个结论对做应用的人尤其重要。因为它提醒我们:不要把模型能力排行榜直接等同于业务可靠性。模型再强,一旦进入多终端、多入口、多任务执行的真实环境,依旧会出现掉链子、误判、回传失败、路径断裂等问题。
当 Agent 成为新的分发节点,这种“锯齿状前沿”会被放大。你可能看见一个 Agent 成功把用户带进了 App,却看不见它是不是带着正确的上下文进来的;你可能看见了下载,却不知道下载前用户实际走过哪段链路;你可能看见报表中有新增,却不知道这个新增到底是人点进来的,还是某个外部工作流替你发起了一次任务。这时,全渠道归因 就不再只是投放部门的工具,而开始变成产品和架构都绕不开的底层能力。
如果站在普通读者视角,这份《2026年AI指数报告》像是在回答一个宏观问题:全球 AI 现在进化到了哪一步,中美竞争进入了什么阶段。可一旦把视角切到 App 开发者和增长操盘手,这篇报告带来的真正冲击是另一件事:模型差距缩小,意味着应用层竞争会急剧加剧;Agent 成功率提升,意味着用户路径会越来越不透明;而入口变多、终端变散,则意味着你原来的归因方法很可能正在失效。
先看最简单的一条链路。过去,用户看到广告,点击落地页,进入应用商店,下载安装,再完成注册或激活。哪怕数据并不完美,这条链路至少相对稳定。但在多模型、多 Agent 的环境里,用户路径会变成:在搜索型 AI、浏览器 Agent、聊天助手或工作流平台里提出需求,Agent 根据模型能力自动调用多个服务,把某个 App 作为中间节点或最终执行节点,再把结果回传给用户。这个过程中,用户甚至可能没有“主动打开 App”的明确动作。
问题就在这里。你的后台可能知道“今天新增了 3000 个激活”,却不知道其中有多少来自自然用户行为,有多少来自 Agent 转交的任务流量;可能知道“某渠道带来了新增”,却不知道这个渠道背后其实已经混合了不同模型、不同工作流平台、不同上下文意图;也可能知道“下载量在涨”,但无法解释为什么注册率和留存率没有同步上涨。表面上是流量问题,本质上却是路径识别问题。
再往深一层看,传统平台报表还有三个明显盲区。
第一,平台只能告诉你“从哪个大渠道来”,却不能告诉你“是哪个任务、哪种场景、哪类 Agent 把人带来的”。
第二,即便你拿到了来源,很多系统也无法还原用户进入 App 时的原始意图,例如他是来比较价格、发起任务、提交表单、自动执行工作流,还是只是看一个结果页。
第三,跨终端、跨模型、跨工作流的链路一旦被打断,后面所有转化解释都会变形。你看到的是一个“新用户”,实际上那可能是一个已经被外部 Agent 预筛选过、预教育过、甚至部分完成任务的高意图用户。
这也是为什么,这篇关于斯坦福 AI 指数的热点新闻,最终会落到一个非常现实的增长问题上:当 AI 入口碎片化、Agent 中间层变厚之后,没有一套更细颗粒度的路径识别方法,开发者看到的增长数据会越来越像“结果”,而不是“过程”。
问题往往不是“没有来源”,而是来源太粗。
当团队把所有来自 AI 生态的流量都简单归为“AI 来源”或“自然新增”时,几乎等于主动放弃了分析能力。因为在模型平权时代,真正影响转化的,不是“是不是来自 AI”,而是“到底来自哪种 AI 场景”。
更合理的第一步,是使用渠道编号 ChannelCode把入口结构化。例如可以按模型来源、工作流平台、终端形态、投放内容形态进行拆分:
channelCode=aiindex_openai_searchchannelCode=aiindex_deepseek_agentchannelCode=aiindex_browser_agentchannelCode=aiindex_content_notechannelCode=aiindex_workflow_partner这样做的核心好处,不是报表更好看,而是你终于能回答几个真正关键的问题:
哪个模型生态带来的用户留存更高?
哪个 Agent 场景带来的转化更深?
哪个入口只是“带量”,哪个入口真正“带业务”?
在方法上,可以直接参考 xinstall 在《亚马逊 AI 战略升级?多云多 Agent 时代 App 该怎么认清流量真身》里提到的思路:先把“流量真身”拆出来,再谈后续优化。不先拆入口,所有关于 ROI 的讨论都会失去抓手。
入口拆干净只是第一步,第二步是把意图带进来。
因为对于 AI 场景来说,来源并不等于意图。一个用户可能同样来自 DeepSeek,但有人是来获取答案,有人是来执行任务,有人是来完成某个工作流最后一步;如果 App 端接住的只是一个通用新用户,那前面所有语境都会丢失。
这时就需要通过智能传参把关键上下文字段一起带进安装和首启流程。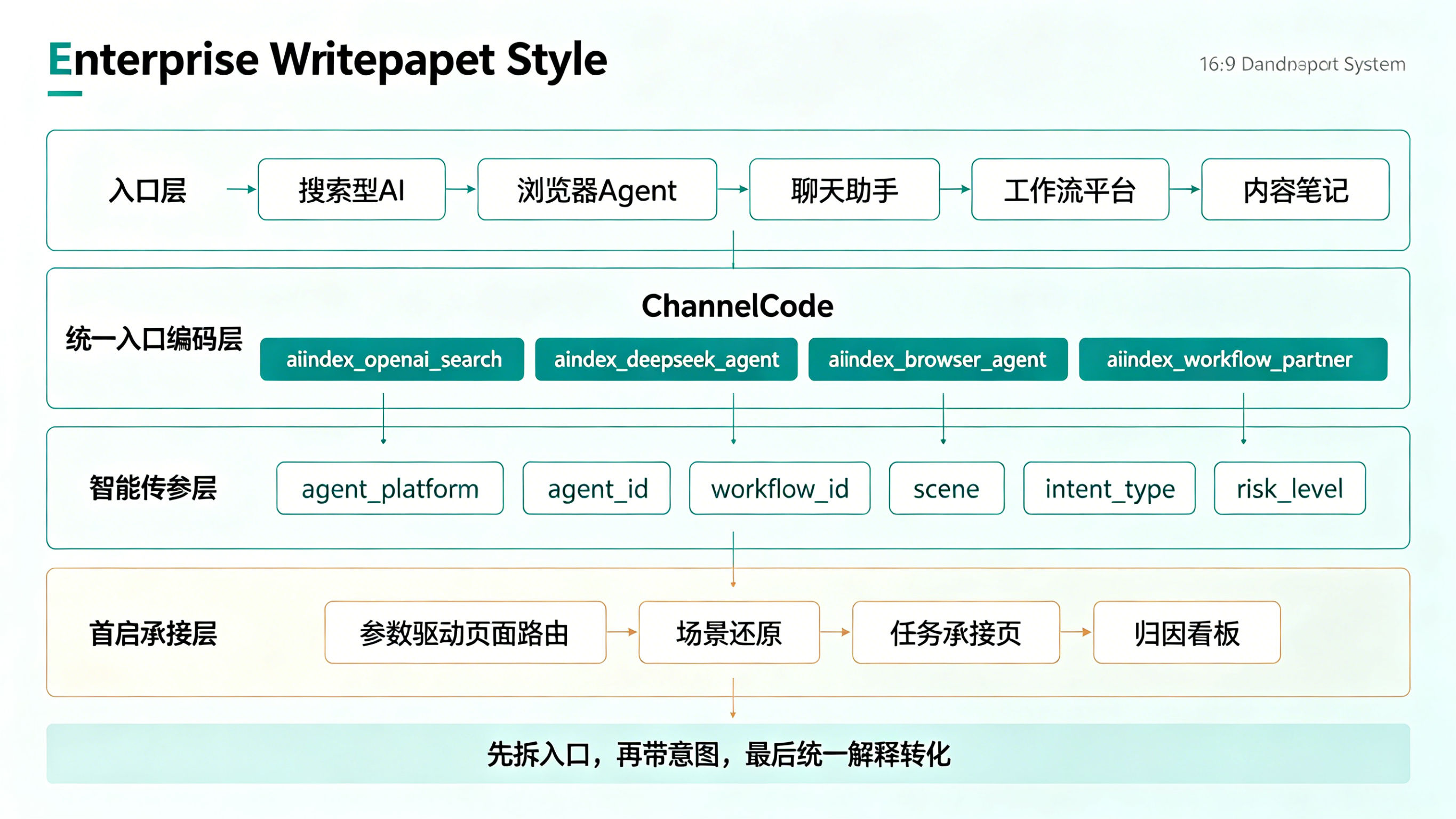 典型字段包括:
典型字段包括:
agent_platformagent_idworkflow_idchannelCodesceneintent_typerisk_level例如,一个来自外部 Agent 的任务可以被编码为:
这样当用户完成安装并首次打开 App 时,系统接到的就不只是“一个新增”,而是“一个来自 DeepSeek 工作流、带有报价比较意图、预期进入自动提交页的新增”。产品就可以直接把用户送进更匹配的页面,而不是强迫他从首页重新走一遍。
在实现逻辑上,这种“链接携参 → 安装 → 首启 → 参数还原”的链路,可以直接借鉴 xinstall 在《智能体分发时代 App 安装传参逻辑的底层重构》里提到的思路。对于增长团队而言,这意味着转化解释权开始回到自己手里;对于产品团队而言,这意味着很多被浪费掉的高意图流量终于有机会被真正接住。
再往后走,真正决定组织认知水平的,不是某一个渠道做得多细,而是你能不能把“人物流量”和“任务流量”放进同一个分析框架里。
所谓人物流量,是用户自己点进来的、自己搜索的、自己操作的链路。
所谓任务流量,则是由外部 Agent、自动化工作流或系统联动发起的链路。
这两类流量看起来都可能表现为“新增”“打开”“下单”,但含义完全不同。
因此,数据仓里的事件图设计,最好至少预留以下维度: 
这样做之后,你看到的就不再是简单的“某渠道装机量上涨”,而会变成“某个浏览器 Agent 在报价对比场景中带来了更高激活率,但其任务完成率偏低,且在 Android 端有明显断点”。这才是真正能指导产品和增长决策的数据。
注:本文讨论的多模型、多 Agent、跨终端任务链路识别,属于对未来分发趋势的前瞻性技术延展与思考,例如渠道精细化归因、跨平台一键拉起、私域裂变链路优化、任务流量可观测性增强等方向。目前其中部分高度定制化链路尚未作为统一标准功能全量实现,如 App 团队已经出现复杂 Agent 分发、跨平台调用还原或高阶任务归因需求,适合结合具体业务与 Xinstall 团队做定向化技术探讨。
模型能力差距缩小之后,真正的壁垒往往不是模型本身,而是你的系统能不能接住更复杂的入口。
从工程角度看,建议优先处理三件事:
agent_platform、workflow_id、scene、channelCode如果没有这些基础设计,后面就算投放来了、合作来了、Agent 入口来了,最终也只能在报表里看到一团混沌的“新增”。
以前很多产品团队把入口理解为开屏、首页、落地页。
但在 Agent 时代,入口其实前移了:它可能发生在搜索问答里、工作流里、浏览器侧栏里、某个 AI 助手生成的行动建议里。谁定义了入口,谁就更有机会定义用户第一次接触产品时的心智。
因此,产品团队现在最该做的,不是只优化站内流程,而是先把“外部意图如何进入 App”设计出来。
用户如果是来执行任务的,就别让他重新搜索;
用户如果是来接收结果的,就别让他再走完整导购流程;
用户如果是带着明确上下文来的,就尽量不要把这些上下文在首启时清空。
模型平权时代,流量会越来越多,但能不能解释清楚流量,决定了预算会不会被浪费。
对增长负责人来说,至少有三件马上能做的事:
当增长报表真正能区分“是谁带来的、为什么来的、最后做成了什么”,预算策略才会开始变聪明。
因为这份《2026年AI指数报告》观察到,自 2025 年初以来,中美模型已经多次在顶端性能排名中交替领先,到 2026 年 3 月,美国顶级模型仅领先中国模型 2.7%。这个结论并不是说两国在所有维度完全一致,而是指顶级模型性能差距已经缩小到非常有限的范围。《The 2026 AI Index Report》 量子位《斯坦福年度结论:中美大模型已没差距》
这意味着 Agent 已经从“会演示”走向“部分可用”。虽然它在很多结构化任务上仍然会失败,但在真实计算机任务中,已经具备更强的执行能力。对行业来说,这意味着越来越多用户行为会被 Agent 中介化,App 面对的将不只是直接用户操作,还包括越来越多外部任务调用。《Inside the AI Index: 12 Takeaways from the 2026 Report》
报告指出,到 2026 年 3 月,顶级闭源模型领先顶级开源模型 3.3%,而 2024 年 8 月这一差距还只有 0.5%。这说明开源并没有失去活力,但在最顶尖模型层,闭源厂商仍然保有一定优势。对于应用团队来说,这意味着模型选择会更加多元,产品层的差异化不会只取决于“开源还是闭源”,而更多取决于接入策略、成本控制和分发效率。《The 2026 AI Index Report》
因为模型差距缩小以后,应用层竞争会加剧;而 Agent 可用性增强以后,用户路径会更复杂。App 团队面对的流量将不再只是传统买量或自然下载,而会越来越多地受到外部 AI 入口、自动化任务流和多终端调用的影响。归因体系如果还停留在旧时代,就很难解释新时代的增长。
从产业位置看,斯坦福这份《2026年AI指数报告》并不只是一次年度总结,它更像是给整个应用生态发出的信号:模型能力的领先优势正在缩短,未来几年真正决定胜负的,将越来越多是“谁更快把模型变成产品、把产品变成入口、把入口变成留存”。
对 App 和 B 端团队来说,这带来的中长期影响至少有三层。第一,分发入口会继续外移,搜索、助手、浏览器、工作流都会成为新的前置触点;第二,用户路径会继续被 Agent 改写,很多转化不再发生在单一页面里,而发生在跨系统任务链里;第三,数据体系必须尽快从“渠道统计”升级到“场景识别 + 意图还原 + 任务追踪”的框架。
也正因为如此,现在正是重构数据与归因体系的窗口期。谁先能识别多模型、多 Agent、多终端环境中的真实流量结构,谁就更有机会在模型平权阶段拿到应用层的主动权。等到外部任务入口真正成为主流,再补作业就会明显更慢;而今天开始把入口拆清、把意图传进来、把任务链画出来,才有可能在下一轮竞争里真正把全渠道归因变成自己的增长底盘。

免填邀请码怎么实现?自动绑定邀请关系技术解析
2026-06-24
深度链接归因怎么做?安装后参数找回技术解析
2026-06-24

豆包专业版正式推出?AI收费战开打背后的订阅分层与商业验证
2026-06-24
毁灭全人类游戏今日登陆新主机?爆款主机游戏跨端种草考验一键拉起基建
2026-06-24
即梦AI上线原生4K视频生成?打破高糊魔咒,AI视觉算力重塑营销分发底座
2026-06-24

免打包渠道统计是什么?App免填邀请码技术原理解析
2026-06-23

二维码渠道追踪有什么优势?一人一码技术解析
2026-06-23

火山引擎暂无拆分上市计划?巨头大模型深耕加速多云底层统计重构
2026-06-23

微信AI小微灰度上线?原生助手操作颠覆闭环渠道归因体系
2026-06-22

OpenAI获最大规模部署?三星接入ChatGPT企业版催生归因需求
2026-06-22

促进平台经济大中小企业协同发展行动方案?智能体成核心
2026-06-19

苹果Xcode27深度集成AI智能体?原生革新引爆场景还原归因
2026-06-19

小米MiMoClaw适配全新框架?终端洗牌确立智能传参获客标准
2026-06-18

寒武纪大涨超14%创新高?硬科技板块爆发倒逼全渠道统计
2026-06-18

上交所发布大模型上市指引?底层应用如何重塑流量归因
2026-06-17






















