






手机微信扫一扫联系客服
联系电话:18046269997



 APP安装免填邀请码
APP安装免填邀请码 社交分享效果统计
社交分享效果统计 广告投放数据统计
广告投放数据统计 CPA/CPS推广效果统计
CPA/CPS推广效果统计 App地推统计
App地推统计 App拉起
App拉起 网页/应用内直接安装
网页/应用内直接安装 Android多渠道打包
Android多渠道打包 App安装后自动绑定
App安装后自动绑定 App分享效果统计
App分享效果统计 Deeplink深度链接
Deeplink深度链接 手机微信扫一扫联系客服
 175
175面向反作弊团队与数据风控工程师,系统拆解异常流量识别在行为序列分析、设备画像建模与群体异常发现中的实现逻辑。若异常流量只靠单点阈值识别,高度伪装的批量作弊通常仍会持续穿透投放链路。
很多团队真正开始重视异常流量识别,不是在看到某个点击量突然暴涨的时候,而是在“所有表面指标都还行,但整体业务质量持续变差”的时候。CTR 不低,CPC 不高,安装数据也说得过去,可注册、留存和收入始终起不来。更麻烦的是,单点排查常常看不出明显异常:IP 不算极端集中,点击频次也没夸张到离谱,设备参数甚至都像真人。
这正是今天异常流量识别最难的地方。难点已经不再是发现“特别假”的流量,而是识别那些“单看每个点都正常,放到整体结构里却很不自然”的风险群体。也因此,异常流量识别不能只靠阈值拦截,而要升级到行为序列分析、设备画像建模和群体异常发现。
如果只从字面理解,异常流量识别好像是在找“不正常的请求”。但在真实业务里,真正要识别的不是某一个奇怪点击,而是一类没有真实商业价值、却能伪装成正常用户的流量结构。
最粗糙的异常流量确实容易看出来,比如短时间内高频点击、同源请求爆发、设备环境高度重复。但更棘手的是那些低强度、持续性、批量协同的流量,它们会刻意放慢节奏、分散来源、模拟页面停留和跳转路径,让单个请求看上去“并不离谱”。
所以异常流量识别真正要抓的,不只是特别假的流量,而是那些“看起来像用户,实际上不产生真实价值”的流量。
普通低质流量可能只是渠道不精准、用户兴趣不足,问题更多体现在转化率低。而异常流量不一样,它往往自带伪装能力。你会看到一些请求完成了点击、访问、安装,甚至带来表面上的激活,但整体路径依旧不符合真实人群特征。
这也是为什么异常流量识别不能只看某个指标低不低,而要看一整组行为和结构是否自然。
异常流量带来的损失并不只是几次无效点击。它还会污染投放优化模型、误导渠道评估结果、拉低数据解释质量,让团队基于错误样本继续做预算和策略决策。也就是说,异常流量识别保护的不只是流量本身,而是整套增长判断系统。
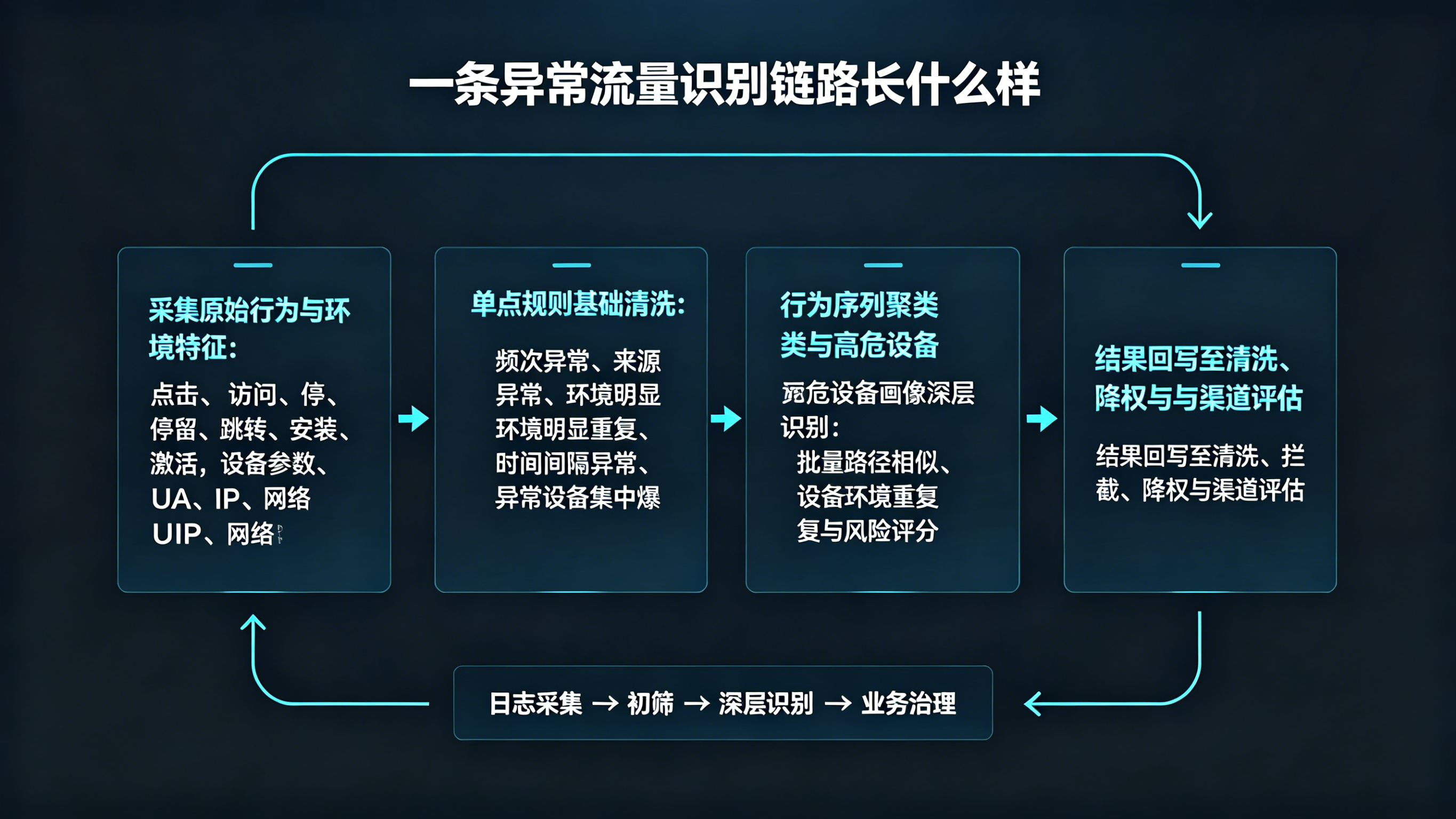
想把异常流量识别做扎实,最有效的方式不是先上模型,而是先把识别链路想清楚。
一切识别都建立在可用数据上。系统至少要采集点击、访问、停留、跳转、安装、激活这些行为日志,同时记录设备参数、UA、IP、网络环境、时间分布等上下文信息。如果原始数据不细,后面就只能做很浅的判断。
很多异常流量识别失败,不是模型不够高级,而是底层日志压根不够建模。
基础规则依然重要。比如频率异常、来源异常、环境明显重复、时间间隔异常短、某类设备环境集中爆发,这些都适合先做第一层拦截。它的作用不是彻底解决问题,而是快速挡住最粗糙的异常样本。
换句话说,单点规则适合做门卫,但不适合做终审。
当明显异常被初筛掉后,剩下最难处理的,就是那些单点正常但群体异常的流量。这时候,行为序列聚类会去看一批用户的动作路径是否高度相似,高危设备画像会去看这些请求是否长期共享某类可疑环境特征。两者结合,才更容易识别出群控设备、设备农场和批量拟人化操作。
这一步才是异常流量识别真正拉开差距的地方。
识别不是为了生成一份技术报告,而是为了影响业务结果。被识别出的异常流量,需要进入流量清洗、风险拦截、投放降权、渠道评分和报表解释逻辑中。否则你虽然“知道有问题”,却没有真正减少损失。
很多团队做异常流量识别的第一反应是多设几个阈值。但今天光靠这套办法,已经越来越难识别高伪装作弊。
点击频次过高、同 IP 爆发过猛、请求节奏机械、环境参数明显不合理,这类问题仍然可以靠阈值快速发现。对于早期团队来说,这是一道必要的防线。
但问题在于,高级异常流量早就知道你会看这些点。
它们会控制点击节奏、分散网络来源、模拟停留时间、插入看似自然的页面路径,让每一个单独样本都刚好落在“正常区间”里。于是你看单个点很正常,看整体却越来越不对劲。
这也是为什么异常流量识别必须从“单点异常”升级到“群体结构异常”。
这是最关键的认知变化。今天许多风险流量不是单次行为太夸张,而是一批行为之间过于一致:路径相似、节奏接近、设备结构雷同、时间窗口聚集。这种异常不是阈值能轻易看出来的,而更像是模式识别问题。
这两个能力经常一起出现,但它们其实解决的是不同层面的异常流量识别问题。
行为序列聚类关注的是用户从点击到后续动作的完整路径,比如先进入哪个页面、停留多久、什么时候跳转、何时安装、多久激活。真实用户的路径通常有自然差异,而批量流量即使伪装,也常常会呈现较高的路径重复度。
所以它最适合发现“动作太像”的问题,也就是那些单个样本看起来合理、整体却高度模板化的流量。
高危设备画像更像是在做“风险记忆”。它不只看一次请求,而是看某类设备特征组合、网络环境、历史命中记录、模拟环境痕迹、重复行为轨迹是否长期可疑。黑名单只能记录“这个东西以前有问题”,画像则能回答“这类东西整体风险高不高”。
这使得高危设备画像特别适合处理持续演化的异常流量,而不只是一次性封禁。

只看行为序列,可能忽略环境风险;只看设备画像,可能漏掉路径异常。异常流量识别做到后期,往往一定要把“动作”和“载体”联合起来分析。一个看过程,一个看承载环境,合在一起才更接近真实风险。
真实落地时,最忌讳的是一上来就追求最复杂算法。更稳妥的做法,是分层搭能力。
日志要细、字段要全、时间要准,这是异常流量识别的前提。没有足够高质量的事件流,就谈不上行为序列;没有完整环境字段,就谈不上设备画像。很多团队一开始就急着做模型,最后发现根本没有可用原料。
比较稳的结构通常是三层:规则负责拦明显异常,聚类负责找相似群体,画像负责做风险记忆。这样既能保留实时性,也能提升识别深度,还能让系统随着样本积累不断变强。
像 广告效果监测、异常流量识别、广告反作弊 和 广告数据验证 这类能力,真正的关键不在概念,而在于它们是否能把采集、识别、清洗和回写接成一个闭环。
如果识别结果只停留在风控后台,那异常流量识别最多只能算“发现问题”。真正有效的是把结果同步到渠道评分、预算分配、报表清洗和异常告警里,让投放团队看到的是清洗后的真实质量,而不是表面繁荣。
这部分是异常流量识别能否从“技术发现”走到“业务治理”的关键。
真正有价值的群体特征图,不是看某个平均值,而是看相似度、重复率、集中度和聚集关系。比如一批流量的行为序列相似度异常高、某类设备环境在多个渠道反复出现、某时段风险流量明显聚集,这些结构信息比单点统计更重要。
明显异常可以直接拦截,中风险流量更适合降权观察,边界样本则可以延迟判断或进入人工复核。如果所有异常样本都直接封掉,误伤率会很高;如果全部只做观察,损失又来不及止住。异常流量识别最终要落到“不同风险层,对应不同治理动作”。
这是异常流量识别最容易忽略的一点。模型越复杂,越要保留解释能力。为什么某批流量被判为高风险,命中了哪些行为特征,和哪些高危画像相似,后链路结果有没有验证,这些都要能回溯。否则团队很难信任识别结果,也很难持续优化。

某团队长期遇到一个问题:某渠道点击和安装数据看起来都没有明显异常,但注册率和次留始终偏低。前期他们用频次阈值、IP 黑名单和基础设备规则排查,都没有发现明确作弊入口。后来团队开始做异常流量识别升级,把行为序列聚类和高危设备画像拉进来,才发现一批样本虽然单看都像真人,但整体路径高度相似,且背后设备环境存在结构性重复。
随后,团队增加了序列相似度分析、设备风险评分和群体异常发现逻辑,并将清洗结果同步到投放评分体系。调整后,异常群体识别召回率提升了 21.7%。这个案例最说明问题的一点是:今天很多异常流量,不是输在“不会伪装”,而是输在“群体结构太像”。
| 方案 | 优势 | 局限 | 适合场景 |
|---|---|---|---|
| 单点阈值规则 | 实现快,适合早期防护 | 容易被绕过,识别深度有限 | 初级风控团队 |
| 规则 + 设备画像 | 风险记忆更强,能识别长期可疑环境 | 对行为协同识别仍有限 | 成长期反作弊体系 |
| 规则 + 行为聚类 + 画像联合方案 | 更适合复杂异常与高伪装协同流量 | 实施复杂度高,对数据质量要求高 | 成熟风控与广告技术团队 |
通常不够。阈值只能发现明显异常,而高伪装流量往往会主动规避这些规则。真正成熟的异常流量识别,还需要群体分析、行为聚类和设备画像配合。
它最大的价值,是能发现单点规则看不到的群体相似性。特别是那些每个样本都看起来不夸张,但整体动作路径像复制出来的流量,序列聚类很容易把它们拉出来。
黑名单更像历史结果记录,画像更像长期特征建模。黑名单适合直接阻断已知高危对象,画像则更适合做风险评分、相似环境扩展和持续识别。

最容易忽略的通常不是模型形式,而是底层日志质量、结果回写闭环和误伤控制。如果这些基础层没搭好,再复杂的模型也很难真正稳定落地。
异常流量识别真正成熟的标志,不是能抓到几个异常样本,而是能把“单点看正常、群体看不自然”的风险结构识别出来,并让识别结果真正进入投放、报表和预算系统。对风控团队来说,这是从静态规则走向结构识别的问题;对数据团队来说,这是可建模数据质量问题;对投放团队来说,则是让优化建立在真实流量而不是伪装样本之上的基础问题。
携带参数安装怎么实现?安装传参与归因技术解析
2026-06-25

Agent Ready怎么落地?企业智能体进入统一管理时代
2026-06-25

360与惠普签署战略合作?AI安全与终端融合进入落地期
2026-06-25

荣耀终端要被AI重做?MWC上海上终端变革的真实信号
2026-06-25

免填邀请码怎么实现?自动绑定邀请关系技术解析
2026-06-24
深度链接归因怎么做?安装后参数找回技术解析
2026-06-24

豆包专业版正式推出?AI收费战开打背后的订阅分层与商业验证
2026-06-24
毁灭全人类游戏今日登陆新主机?爆款主机游戏跨端种草考验一键拉起基建
2026-06-24
即梦AI上线原生4K视频生成?打破高糊魔咒,AI视觉算力重塑营销分发底座
2026-06-24

免打包渠道统计是什么?App免填邀请码技术原理解析
2026-06-23

二维码渠道追踪有什么优势?一人一码技术解析
2026-06-23

火山引擎暂无拆分上市计划?巨头大模型深耕加速多云底层统计重构
2026-06-23

微信AI小微灰度上线?原生助手操作颠覆闭环渠道归因体系
2026-06-22

OpenAI获最大规模部署?三星接入ChatGPT企业版催生归因需求
2026-06-22

促进平台经济大中小企业协同发展行动方案?智能体成核心
2026-06-19






















