






手机微信扫一扫联系客服
联系电话:18046269997



 APP安装免填邀请码
APP安装免填邀请码 社交分享效果统计
社交分享效果统计 广告投放数据统计
广告投放数据统计 CPA/CPS推广效果统计
CPA/CPS推广效果统计 App地推统计
App地推统计 App拉起
App拉起 网页/应用内直接安装
网页/应用内直接安装 Android多渠道打包
Android多渠道打包 App安装后自动绑定
App安装后自动绑定 App分享效果统计
App分享效果统计 Deeplink深度链接
Deeplink深度链接 手机微信扫一扫联系客服
 575
575当 DeepSeek-V4 不只是在模型性能上逼近头部闭源系统,还把优化重心深入到 GPU 内核、跨芯片适配与推理成本重构,AI 应用分发与入口归因的底层逻辑也在被改写。
DeepSeek-V4 发布后,“梁文锋这一次要掀桌”迅速成了行业热词。对普通读者来说,这像是又一轮大模型性能大战;但对 App 开发者、增长负责人和数据团队来说,这轮变化更值得警惕的地方在于:当底层算力、模型接入和云侧分发同时变化,全渠道归因这套老问题会被重新推到台前,而且这次不再只是投放问题,而是入口定义权的问题。
从你提供的材料看,这轮讨论的中心并不只是 DeepSeek-V4 发布了,而是它被赋予了“三重掀桌”的意义:掀模型性能桌、掀 GPU 垄断桌、掀美国 AI 封堵桌。报道之所以强调“梁文锋这一次要掀桌”,核心就在于 DeepSeek 不再只是做一轮常规版本升级,而是在试图改变大模型行业默认接受的一些前提。
过去两年,行业最主流的叙事是:更强的模型往往意味着更多卡、更高训练成本、更重的推理负担,以及对英伟达 CUDA 生态更深的依赖。DeepSeek 早期就因 V3、R1 这类模型以较高推理效率和更低成本撬动行业预期而受到关注,而 V4 则进一步把这种“反堆算力”的路线推进到了更底层。
材料中提到,V4 分为 Flash 和 Pro 两个版本,其中 Pro 版本参数达到 1.6T,Flash 版本更强调更快、更轻和更低成本。这种组合本身说明,它的目标不是单纯争一项跑分,而是试图同时覆盖“高性能”和“高可用”两个方向,让模型能力和商业可接入性一起成立。
如果只看表层信息,V4 看起来像一次“能力更强、上下文更长、价格更低”的常规模型迭代。但从报道内容看,真正值得注意的是它在底层结构上集中强调了几个技术点:Engram 记忆模块、mHC 稳定机制,以及 CSA / HCA 的注意力机制组合。
Engram 的要点,在于把“静态知识”和“主动推理”尽可能分开处理。通俗理解,就是模型不必凡事都现场计算,那些可检索、可快速调用的部分尽量转入类似“字典”式的条件记忆中处理,把珍贵的注意力资源释放给真正复杂的推理任务。这样做的价值,不只是省一点算力,而是让模型资源分配方式发生改变。
mHC 则更像是在解决“模型越深越不稳”的工程问题。大模型层数加深以后,训练稳定性、梯度传播和信息衰减都会成为现实瓶颈。报道把它类比成“给摩天大楼装自动稳定电梯”,这个比喻其实很贴切:它不是让楼更花哨,而是让楼不容易塌。对于大模型行业来说,能不能更稳地堆深网络,本身就意味着更大的训练空间和更高的工程天花板。
再加上 CSA / HCA 对长文本处理的优化,V4 试图同时解决长上下文场景里的卡顿、显存爆炸和检索效率问题。换句话说,这次更新更像是一次“性能工程”而不是单点功能秀。

如果说前面的结构创新主要影响模型圈,那么更值得应用侧关注的,是 DeepSeek 同时把手伸进了 GPU 内核和编译抽象层。材料提到,V4 发布前一天,DeepSeek 开源了 Tile Kernels 模块,并使用 TileLang 语言来表达计算逻辑和生成面向不同硬件的优化代码。
这件事的重要性,在于它不再默认接受“GPU 优化必须深度依赖 CUDA”的路径。过去做 AI 推理和训练优化,很多团队默认把 NVIDIA GPU 和 CUDA 视作不可替代的组合,软件栈、算子生态、部署经验几乎都围绕这一套体系展开。TileLang 这类方案尝试把优化逻辑从固定平台中抽离出来,让上层逻辑具备更高的跨芯片可迁移性。
这并不意味着英伟达会立刻失去统治力,但它确实意味着一个新的行业信号:未来模型部署效率的竞争,不再只靠买到最好的卡,也开始靠谁能更好地调度、编译和榨干已有算力。对国产芯片来说,这种变化尤其重要,因为它把竞争门槛从“谁先天更强”部分转向“谁后天更会用”。
另一条不能忽略的信息,是华为云很快宣布对 DeepSeek-V4 首发适配,并给出免部署、一键调用的服务路径。根据华为云的官方说明,DeepSeek-V4 拥有百万 Token 超长上下文,华为云 MaaS 平台已经面向开发者提供免部署调用服务;相关报道也提到,平台围绕注意力压缩机制、KVCache 分配和昇腾融合算子做了适配优化。
这说明模型竞争已经不是“谁先训练出来”这么简单,而是“谁能最快把模型接到云上、接到企业里、接到应用入口上”。一旦模型发布与服务落地的时间差被大幅缩短,应用层面对 AI 的感知就会发生变化:它不再是一项需要长周期研发才能接入的新技术,而是可能在几天内就被云平台转化成一个可调用能力。
而一旦能力可调用,就会进入分发生态。谁能率先把 DeepSeek-V4 这种能力嵌进自己的 Agent、企业工具、开发平台、内容入口和工作流中,谁就更有机会抢到下一轮流量入口。
普通读者关心的是:DeepSeek-V4 到底强不强,会不会冲击 OpenAI,会不会继续压低模型价格。可对 App 团队来说,更棘手的问题不是“模型谁赢了”,而是“入口是谁的了”。
过去移动互联网的增长结构相对清晰:流量来自投放平台、内容平台、搜索平台、私域或自然商店分发,用户点击、下载、安装、注册、激活,路径虽然复杂,但大致还在“人主动找 App”的框架里。可 AI 时代的变化在于,用户越来越可能先在模型环境里完成理解、检索、筛选和初步决策,再被引导到具体产品。
这意味着很多高价值流量不会再从传统广告位开始,而会从模型结果页、云 API 入口、Agent 工作流、系统推荐、插件调用甚至企业内部工具触发开始。一个用户可能先在 AI 环境里完成“想做什么”,之后才进入 App 执行“怎么做”。入口前移了,传统报表却还停留在安装点和点击点。
问题恰恰出在这里。旧的归因体系擅长回答“用户从哪条链接下载”,却不擅长回答“用户最早是在哪个模型或任务流里被影响”。当模型、云平台和 Agent 成为前置分发层时,App 团队如果仍然只用安装归因思路看流量,就会把大量新型入口误判成“自然流量”或“无法识别流量”。
这就是为什么这条热点真正落到业务层时,会变成全渠道归因的问题。它不只是多加几个来源字段,而是必须重新定义“第一触点”和“入口真身”。当用户先被 DeepSeek-V4 这样的模型能力影响,再进入你的产品时,真正的流量源头就已经不在下载页,而在模型前面的那一层了。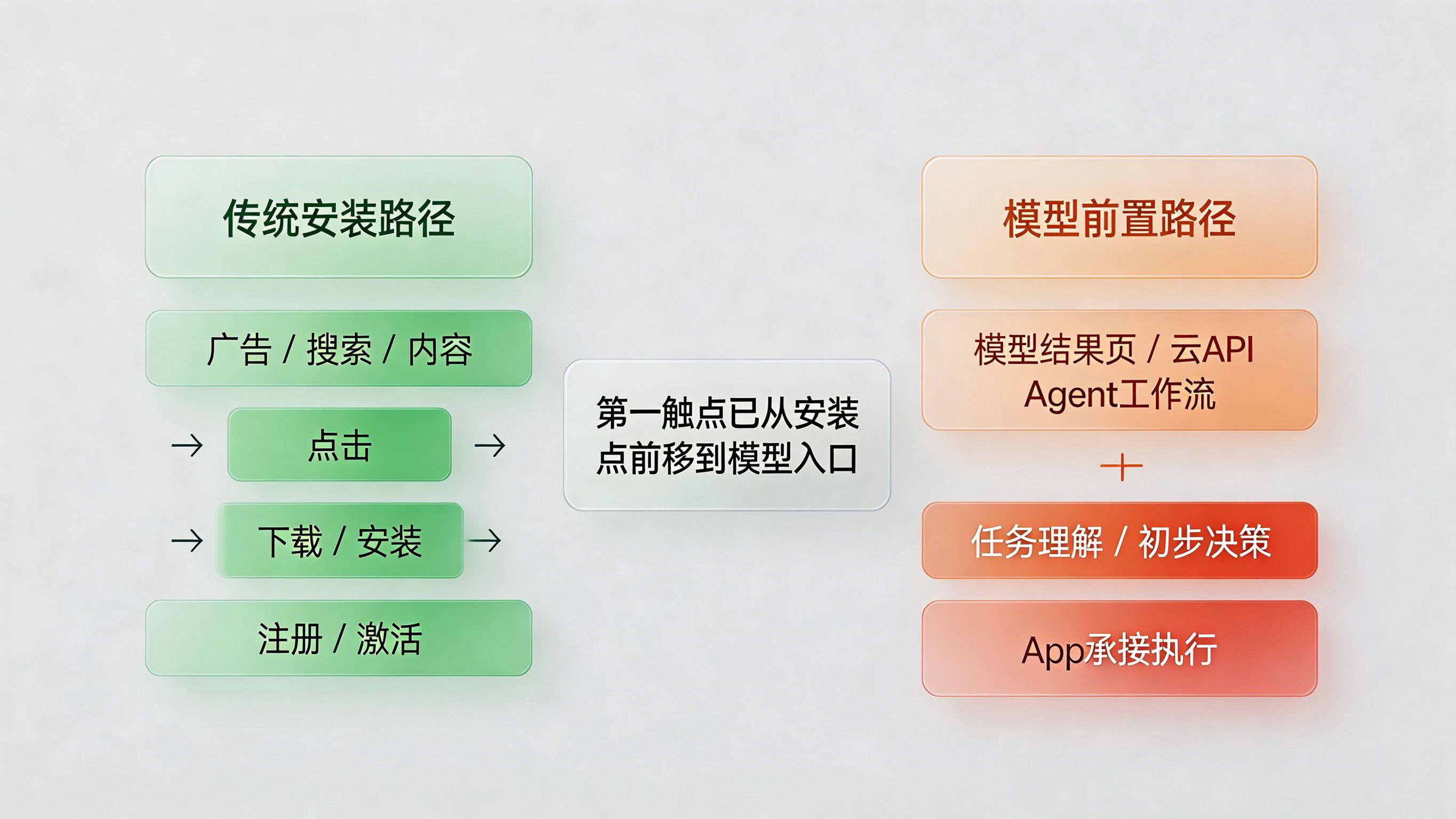
更进一步说,在 AI 时代还会出现两类并行流量:一类是传统“人物流量”,即用户本人打开 App、完成浏览、点击和注册;另一类是“任务流量”,即某个 Agent、工作流或外部系统发起任务,再把请求或结果传入 App。对于后者,如果没有新的归因设计,后台看到的只是调用,却看不到任务从哪来、为何而来、经过了哪些系统。
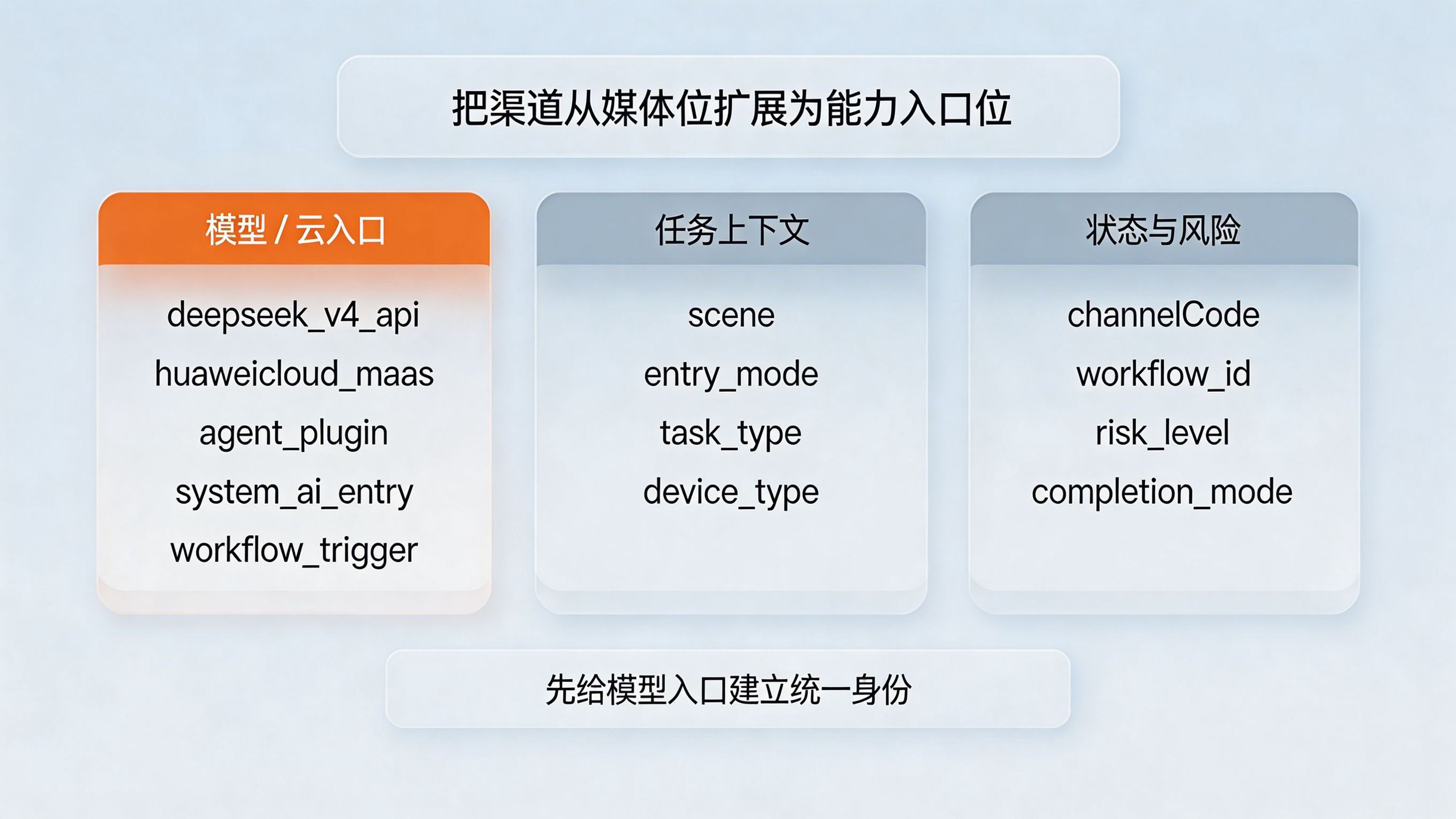
问题:很多团队现在给渠道编号,还是广告思维——按媒体、投放计划、达人、落地页来分。但 DeepSeek-V4 这类热点背后的真实变化是,未来大量流量的第一触点并不来自广告平台,而来自模型入口、云服务入口、Agent 入口和系统级调用入口。
做法:这时就需要用渠道编号 ChannelCode的思路,把“渠道”从传统媒体位扩展为“能力入口位”。例如,可按 deepseek_v4_api、huaweicloud_maas、agent_plugin、system_ai_entry、workflow_trigger 这类方式管理入口编号,同时附加 scene、entry_mode、task_type、device_type、risk_level 等字段。这样,团队统计的就不只是“哪个渠道来的人”,而是“哪个 AI 入口发起了这次业务触达”。
带来的好处:一旦入口有统一身份,增长团队就能把原本混在一起的 AI 流量拆开,判断到底是模型结果页更能转化,还是云控制台试用页更能转化,还是某个 Agent 工作流更适合承接高价值用户。对于全渠道归因来说,这一步是重新拿回入口解释权的基础。
问题:AI 场景最大的损耗之一,是上下文在跳转时中断。用户可能在 DeepSeek-V4 支持的某个环境中已经完成了一轮复杂意图表达,甚至已经形成明确任务,但一旦进入下载、安装、首启链路,前面这些信息全部丢失,后端只能看到一个“新增”。
做法:这时就需要更重视智能传参和安装后参数还原。做法上,可以在入口阶段保留 source_channel、model_name、scene、intent_type、workflow_id、task_type 等信息,并在首启或激活阶段进行受控恢复。实现思路上,也可以参考 xinstall 在《智能体分发时代 App 安装传参逻辑的底层重构》里提到的链路设计:不是只记录“从哪来”,而是尽可能保住“为什么来、带着什么任务来”。
带来的好处:产品团队不再只知道用户来了,而能知道这名用户是被模型问答吸引来的、被任务结果推动来的,还是在云平台试用后转化来的。增长团队则可以把不同 AI 入口对应的意图层级区分出来,而不是把所有新流量都当成同类新增。
注:本文讨论的部分模型上下文承接、跨 Agent 任务保真、系统级 AI 入口携参等方向,属于面向未来分发趋势的前瞻性技术延展与思考,例如渠道精细化归因、复杂工作流上下文衔接、跨平台拉起与任务回流等应用方向。此类链路在不同终端和业务系统中的实现成熟度并不一致,目前仍需结合实际架构进行评估,若有高阶场景需求,可进一步与 Xinstall 团队做技术探讨。
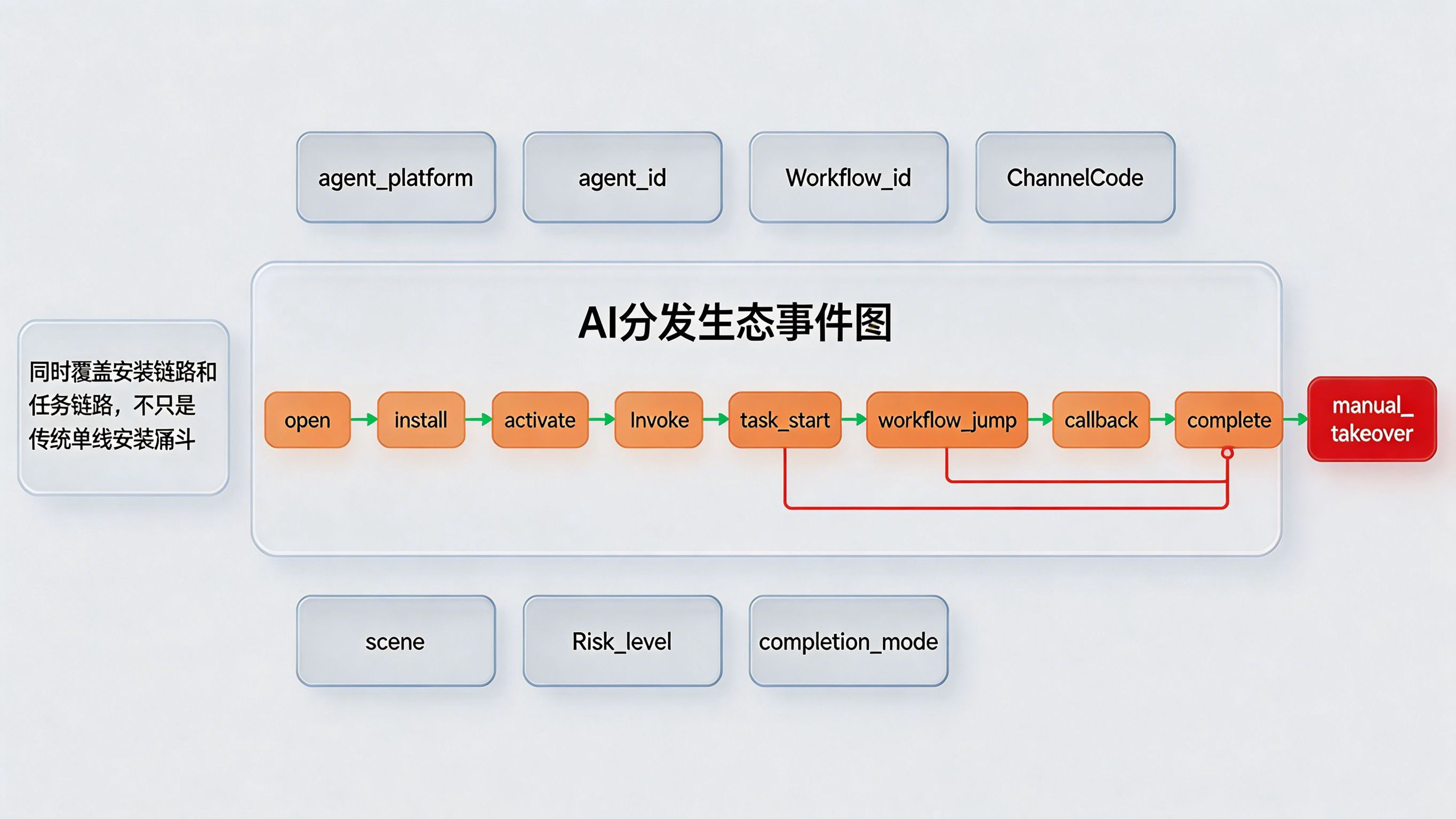
问题:只靠安装归因已经很难解释 DeepSeek-V4 带来的新流量结构,因为用户不一定是自己点进来的,也可能是外部系统、Agent 或云工作流把任务带进来的。如果后台只能看到“调用发生了”,却看不到谁发起、如何回流、在哪中断,就很难判断什么入口真正有效。
做法:数据层需要建立新的事件模型,把人物行为和任务行为同时纳入。比如围绕 open、install、activate、invoke、task_start、workflow_jump、callback、complete、manual_takeover 等节点建模,并增加 agent_platform、agent_id、workflow_id、channelCode、scene、risk_level 等字段。对于这类多系统链路,也可结合 xinstall 过往在《亚马逊 AI 战略升级?多云多 Agent 时代 App 该怎么认清流量真身》和《OpenClaw 引爆智能体分发:AI 个人助理重构 App 参数传参安装范式》中的分析思路,把模型入口、安装链路和回流事件统一观察。
带来的好处:团队不只是知道“这个用户装了”,而是知道“这次任务从哪个 AI 平台触发、经过哪个工作流进入 App、在哪个节点中断、最后是 AI 完成还是人工接管”。这正是 AI 时代全渠道归因必须升级的地方:看见的不再只是人,而是人和任务同时构成的新流量结构。
如果你的业务未来会接入 DeepSeek、华为云 MaaS、第三方 Agent 或多模型工作流,最应该尽早做的,不是等待流量起来后再补埋点,而是提前给新入口留字段。建议优先考虑:
这些字段的意义,在于未来你还能不能解释“这次转化到底从哪开始”。如果今天不留,等明天模型流量混进自然流量后,再回头补基本上只能靠猜。
对产品经理来说,这轮变化最大的风险,不是对手模型更强,而是你对入口的定义还停留在旧时代。过去入口是落地页、搜索位、活动页、应用商店位;现在入口可能是模型回答页、工作流卡片、系统 AI 按钮、插件调用页。
如果产品设计还默认“用户先找到 App,再使用能力”,很多 AI 前置流量会直接在外部被截走。真正需要重新设计的,是产品如何被模型调用后还能保住上下文、如何在跳转后仍能识别用户意图、如何在多个 AI 入口中保持体验一致。
增长负责人最容易低估的一点,是模型流量一开始看起来像零散的新入口,久而久之却可能成为主入口之一。尤其当 DeepSeek-V4 这种模型把成本压低、上下文拉长、推理能力增强以后,越来越多用户会先在 AI 环境里完成种草、理解和比较,再进入最终业务节点。
现在可以做的事有三件:

从这次材料看,V4 不只是性能续作,而是更强调底层结构优化和工程效率。它在记忆机制、长上下文处理、深层网络稳定性以及 GPU 内核优化上都比此前更系统,意味着目标已经从“做一个强模型”转向“做一套更能规模化部署的模型能力”。
因为这次争议不只在模型分数,而在软件栈控制权。过去很多 AI 团队默认依赖 NVIDIA GPU 和 CUDA 生态,而 TileLang、Tile Kernels 这类方案的意义,是尝试把优化逻辑从固定平台里抽离出来,让更多芯片也能承接高性能推理和训练任务。
这意味着模型竞争和应用落地之间的距离正在缩短。模型一旦快速被云平台接住,就会迅速进入企业工具、开发平台和业务系统,AI 能力不再只是行业新闻,而会更快变成真正可调用、可接入、可分发的基础设施。
因为它改变的是入口链条。用户未来可能不是先打开 App,再去找 AI 功能,而是先在 AI 环境里完成任务,再被导入 App。入口前移之后,原有安装统计、投放报表和渠道判断都可能失真,App 团队必须更早识别模型触点和任务来源。
“梁文锋这一次要掀桌”之所以值得写成长文,不是因为它只代表某一家模型公司又赢了一轮热搜,而是因为它揭示了一个更深的趋势:AI 行业的竞争,正在从模型榜单扩展到芯片适配、云平台接力、应用入口和流量解释权。DeepSeek-V4 如果真的把算力利用率、推理成本和跨芯片部署门槛持续往下拉,那么接下来被改写的就不只是大模型赛道,也包括上层 App 的获客方式、接入方式和用户路径。
对 B 端团队和 App 团队来说,现在恰恰是重构数据体系的窗口期。因为等模型、云和 Agent 真的成为主流入口之后,再回头补入口编号、补参数还原、补任务事件图,成本会远比现在高得多。真正值得提前做的,是把人物流量和任务流量一起纳入看板,把第一触点从“安装页”前移到“模型入口”,并用全渠道归因重新拿回对新流量时代的解释权。这个窗口不会一直开着,而下一轮真正决定增长效率的,很可能就是谁先把全渠道归因做成面向 AI 分发生态的底层能力。

AMD 机架级AI系统全面投产,智能体时代算力再洗牌?
2026-07-24
Xinstall 全链路归因怎么做? 统一口径与闭环分析指南
2026-07-24
Xinstall 内链为什么无法跳转 ?跳转失败原因与排查路径解析
2026-07-24

Xinstall 跨渠道怎么归因?全链路追踪与统一口径
2026-07-23

Xinstall 安装来源怎么统计?归因恢复与链路设计
2026-07-23

上海科创板新政落地?未盈利硬科技的上市窗口怎么变
2026-07-23

iPhone18系列已量产?供应链装机归因进入重构期
2026-07-22

数据建模怎么支撑推荐?从用户特征到召回排序
2026-07-21

Xinstall 裂变拉新怎么统计?邀请关系与转化追踪
2026-07-21
Xinstall 地推业绩怎么统计?推广员数据归因与考核规则
2026-07-21

三星设立机器人部门加速商业化?实体终端入口正在重构跨端链路
2026-07-21

腾讯Hyra智能体实现递归自我改进?长周期任务正在倒逼归因漏斗重建
2026-07-21

千问办公合并三款智能体?超级工作台跨端唤起将迎终极考验
2026-07-21

AI智能体全面接管智能晶圆厂?跨终端软硬协同正在重置底层流转规则
2026-07-20

Kimi K3触发算力告急?长任务智能体正在重塑开发者的架构边界
2026-07-20






















