






手机微信扫一扫联系客服
联系电话:18046269997



 APP安装免填邀请码
APP安装免填邀请码 社交分享效果统计
社交分享效果统计 广告投放数据统计
广告投放数据统计 CPA/CPS推广效果统计
CPA/CPS推广效果统计 App地推统计
App地推统计 App拉起
App拉起 网页/应用内直接安装
网页/应用内直接安装 Android多渠道打包
Android多渠道打包 App安装后自动绑定
App安装后自动绑定 App分享效果统计
App分享效果统计 Deeplink深度链接
Deeplink深度链接 手机微信扫一扫联系客服
 715
715OpenAI 升级 Codex 后,AI 不再只是“写代码”,而是开始调用电脑上的 App、浏览器和插件执行任务。对 App 开发、增长和数据团队来说,真正新增的不是 1 个工具,而是 1 种更难统计的任务流量入口。
OpenAI 这次升级 Codex,最值得关注的并不是“AI 编程工具又变强了”,而是它开始更像一个可以直接操作电脑的任务执行层。
公开信息显示,Codex 现在可以在后台调用用户电脑上的应用,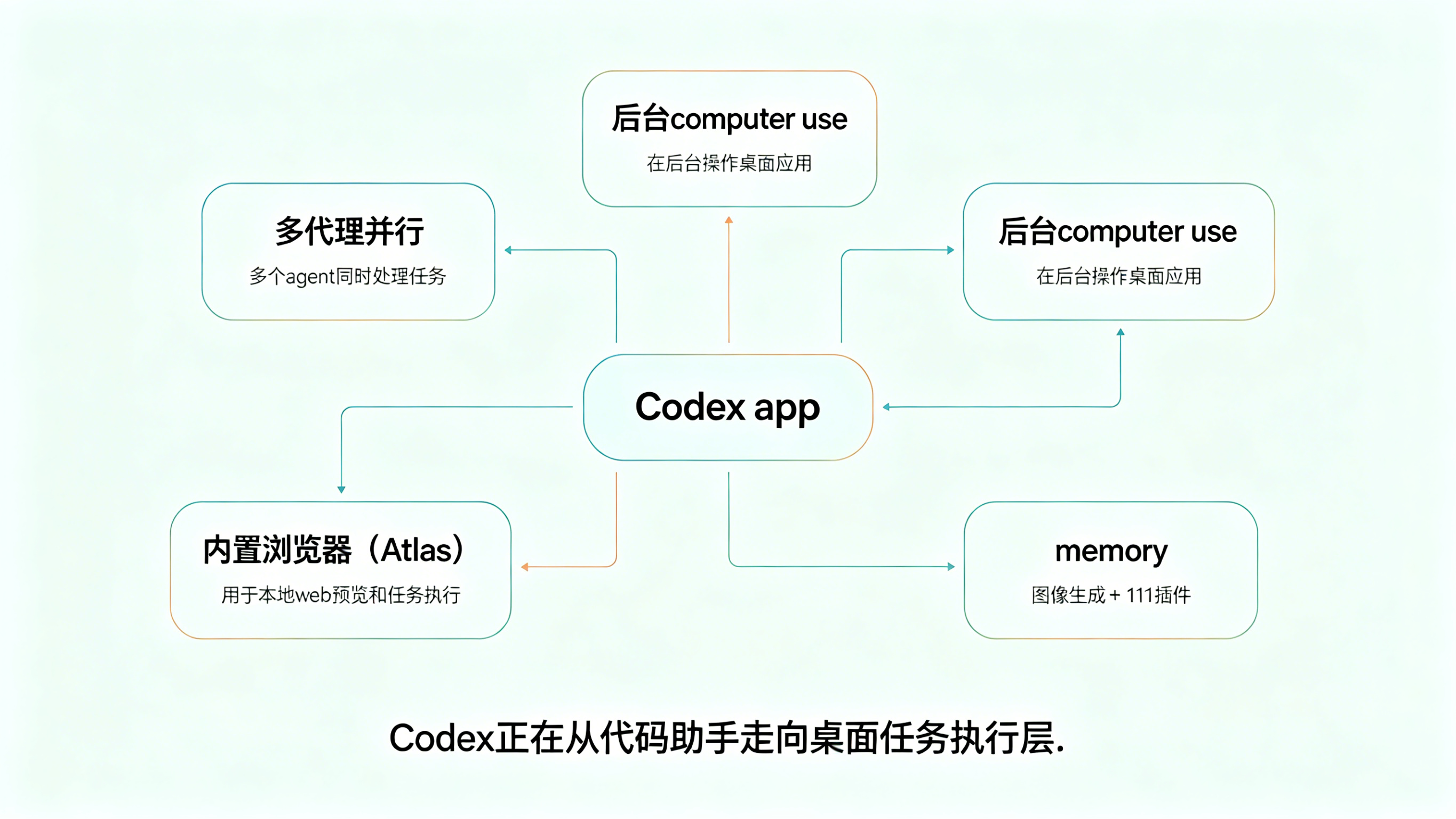 通过点击、输入、切换工具去执行任务,同时 OpenAI 还在推进整合 ChatGPT、Codex 与 Atlas 浏览器的桌面端“超级 AI 应用”。这意味着,未来很多流量入口可能不再来自“用户亲手打开 App”,而是来自“AI 代理替用户调起 App”。
通过点击、输入、切换工具去执行任务,同时 OpenAI 还在推进整合 ChatGPT、Codex 与 Atlas 浏览器的桌面端“超级 AI 应用”。这意味着,未来很多流量入口可能不再来自“用户亲手打开 App”,而是来自“AI 代理替用户调起 App”。
如果只把这件事理解成 OpenAI 和 Anthropic 在 AI 编程工具上的竞争加剧,就低估了它对 App 分发、用户路径和归因体系的冲击。因为一旦 AI 代理开始替人使用电脑,原来基于“人点击、人打开、人操作”的增长和统计逻辑,就会越来越不够用。
根据公开报道和官方介绍,这次 Codex 的升级重点不只是代码能力,而是新增了后台操作电脑的能力。它可以在用户电脑上调用本地应用,通过模拟点击和输入完成任务,而且支持多个代理并行工作,不会和用户抢占当前操作。
除此之外,Codex 还新增了应用内浏览器、记忆能力、图像生成,以及 111 个插件集成。这意味着它不再是一个只服务代码仓库的工具,而是在往更完整的桌面工作代理演化。
从使用场景看,它已经可以覆盖前端迭代修改、应用测试、处理没有开放 API 的应用任务,甚至可以结合 Slack、Google Calendar 一类工具去帮助用户整理待办、汇总上下文和执行重复性工作。
很多 AI 产品更新,核心是“更强的回答”或“更高的生成质量”。Codex 这次不一样,它直接接近了操作系统层面的入口控制权。
过去一个 AI 工具大多停留在“建议”和“生成”阶段,最终点击按钮、切换页面、打开软件、触发流程的还是用户自己。现在 Codex 开始能够把这些动作接过去,意味着它正在从“辅助你做事”,转向“替你把事做完一部分”。
一旦这种模式成立,流量就会发生结构性变化。因为很多原本发生在 App 内部、浏览器页面或者插件界面的行为,不再是用户显式点击,而是代理在后台完成。对产品后台来说,这可能还是一次访问、一次登录、一次拉起、一次任务执行;但对增长分析来说,这已经不是传统意义上的同一种流量了。
公开信息已经很明确:OpenAI 并不满足于让 Codex 成为一款更能打的编程助手,而是希望它成为更大工作流的一部分,并服务于桌面端“超级 AI 应用”的构建。
这背后的逻辑并不复杂。谁能掌握任务分发权,谁就更接近下一代入口。未来用户未必会逐个打开工具,而更可能先对一个上层 AI 应用说“帮我把今天的工作处理一下”,再由这个 AI 去决定该调用哪个本地 App、哪个网页工具、哪个插件和哪个服务。
这时,底层 App 的获客逻辑就会被改写。它们争夺的可能不只是用户的主动下载和打开,还包括“是否能被代理优先纳入任务链路”。
传统 App 增长体系里,一个默认前提几乎没有被怀疑过:流量来自人。
用户看见内容,点击链接,下载安装,打开应用,完成注册、付费或其他转化。
但 Codex 这类桌面代理能力会让这个前提开始动摇。因为越来越多的行为,可能不是由用户一步步手动触发,而是由代理完成:打开浏览器、切换工具、输入文本、读取页面、调起应用、执行脚本、汇总结果。
于是,一种新的流量类型开始变得重要:任务流量。
它和传统“人流量”的核心差别在于,发起动作的主体不再稳定是用户本人,而可能是一个代理、一个 workflow、一个插件组合,或者一次自动化调用。
假设一个用户通过 Codex 调起你的产品后台、网页应用或桌面端服务,系统看到的可能只是一次正常访问。但实际上,你未必知道:
它到底是用户本人发起,还是 Codex 子代理发起;
它来自哪个具体任务;
它是浏览器场景、插件场景,还是桌面电脑调用场景;
它最终有没有形成真实的用户行为,还是只完成了一次自动化动作。
如果这些信息全都丢失,那么原来的“渠道—点击—激活—转化”模型就会越来越不准确。因为在新链路里,真正重要的不是谁点了,而是谁触发了任务、任务经过了什么路径、最后有没有转交给真人并形成业务结果。
一旦超级 AI 应用成为工作入口,很多 App 面对的第一触点就不再是用户本人,而是代理层。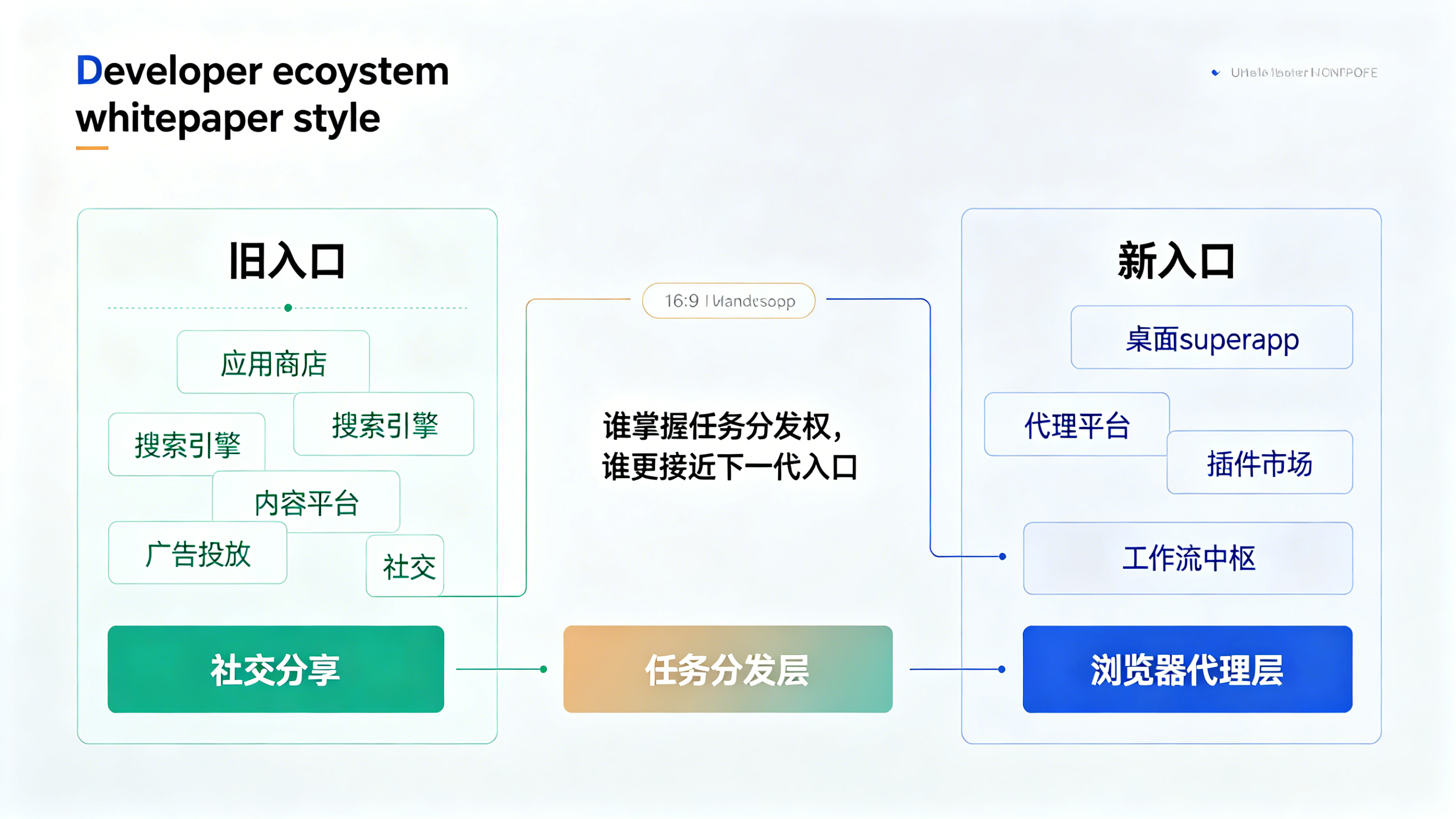
这会让原本熟悉的分发入口发生变化:
过去是应用商店、搜索引擎、广告投放、内容平台和社交分享;
未来还会多出代理平台、桌面工作流、插件市场、任务中枢和浏览器代理层。
这类入口变化对 B2B 产品、开发工具、SaaS 服务和多端应用的影响会尤其明显。因为它们本来就高度依赖工作流嵌入,而不是单次消费点击。现在上层代理一旦开始接管调度,这些产品就必须重新理解“谁把流量带进来”。
很多团队现在做来源统计,粒度还停留在“自然流量、投放流量、合作流量、官网流量”这种层级。到了 Agent 时代,这种粒度很快就会不够。
因为同样来自 OpenAI 生态,来源也可能完全不同:
可能是 Codex 桌面端;
可能是内置浏览器;
可能是某个插件链路;
可能是某个子代理并发调用;
也可能是 ChatGPT 与 Codex 的任务交接。
如果只把这些都记成“OpenAI 来源”,后面几乎无法分析真实质量差异。
更合理的做法,是给不同入口分配明确的 ChannelCode,把“平台来源”细化成“任务入口来源”。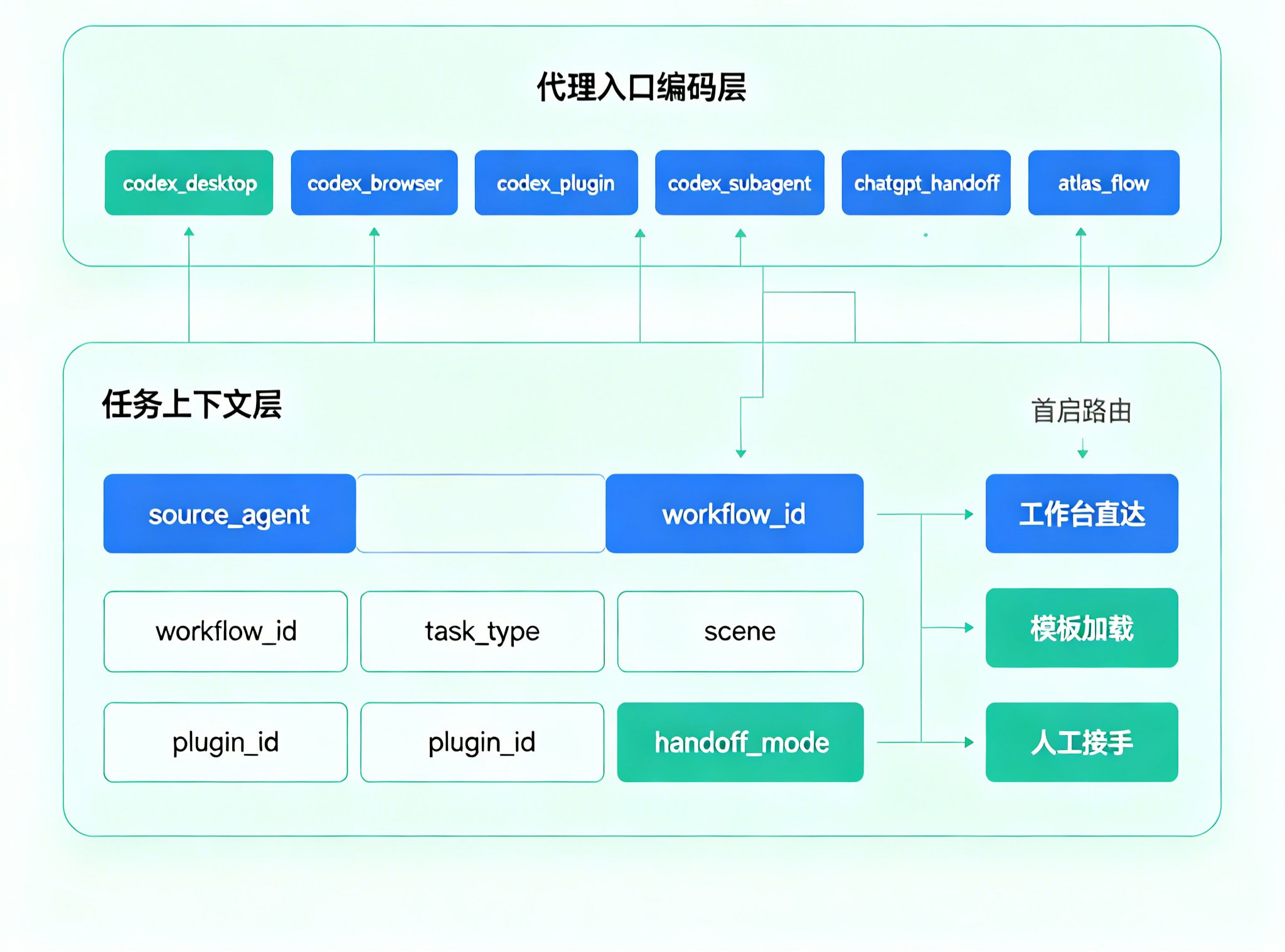
比如:
这样做的好处是,后续你不只是知道“流量来自 OpenAI”,而是知道“究竟是哪类代理入口带来了注册、留资、付费或高价值调用”。
只记录来源还不够。
因为这类代理流量最关键的信息,往往不是“从哪来”,而是“为什么来”。
一个由 Codex 拉起的访问,背后可能是:
如果这些上下文在打开产品后全部丢失,后端就只能把它看作一次普通访问,产品侧也无法做更准确的承接。
这时,更适合的做法是引入 智能传参安装 思路,把场景参数带进首启和后续流程,例如:
这样,产品不只是知道“有人进来了”,而是知道“这个访问由哪个代理、基于什么任务、在什么场景下进入”。
后续无论是跳转页面、直达工作台、免填邀请码、加载预设模板还是路由分发,都可以更精准。
如果 Codex 这类入口持续发展,最应该升级的不是某一个埋点,而是整个归因模型。
因为旧模型更偏“点击统计”,而新模型更需要“任务统计”。
真正应该纳入体系的字段,包括:
这样,团队才能真正回答一些关键问题:
哪类代理入口带来了真实业务结果;
哪些只是自动化空跑,没有形成有效用户;
哪种 workflow 更容易促成后续转化;
哪些入口更值得重点合作、运营或产品化。
注:本文中提到的“任务流量”“Agent 流量可观测性”“多代理入口归因”等内容,属于基于新型 AI 分发生态的前瞻性业务延展。类似复杂场景下的渠道识别、任务参数传递、跨系统归因与场景还原,往往需要结合具体业务架构和客户端形态进行定制化配置,并非所有产品默认具备统一能力。如已出现 Agent 平台接入、自动化任务分发、多终端协同等复杂需求,欢迎联系 Xinstall 客服团队进一步沟通。
开发团队首先要做的,不是判断 Codex 会不会替代现有工具,而是先把系统设计成“能识别代理调用”。
也就是说,系统至少要能够区分:
如果这些类型全部混在一起,后面的体验优化、风险判断、产品承接和商业分析都会被干扰。
增长团队则要重新定义“高质量流量”。
过去,高质量流量通常意味着高激活、高留存和高付费;未来还需要增加一层:高质量任务入口。
也就是:
哪些代理平台会持续带来真实需求;
哪些插件或任务场景会稳定产生后续转化;
哪些调用只是看起来热闹,实际上没有商业价值。
因此,增长报表不能只看“来源平台”,而要升级到“来源平台 + 任务场景 + 接手结果 + 最终转化”。
不是单纯代码能力增强,而是加入了后台操作电脑、内置浏览器、记忆和插件能力,让它更像一个可以在桌面执行任务的代理。
因为当代理开始替用户调用 App 和网页时,很多入口不再是用户自己点击,而是由任务触发,这会改变原有分发路径。
可以简单理解为:由代理、工作流或自动化系统触发的访问、调用和执行,而不是由用户手动点击直接产生的流量。
因为传统归因擅长记录“谁点了什么”,但 Agent 时代更需要记录“哪个任务因为什么触发、经过了哪些链路、最终有没有变成真实业务结果”。
Codex 这次升级释放出的信号非常明确:桌面端超级 AI 应用的竞争,已经不只是模型能力竞争,而是任务入口竞争。
对 App 团队来说,这不是一个遥远概念,而是会快速落到统计、归因和增长判断上的现实变化。因为当用户越来越少亲自操作,越来越多把任务交给代理时,旧的流量模型就不够用了,任务流量会成为新的增长基础设施议题。

Xinstall 全渠道统计怎么滚动迭代?项目管理与版本升级策略
2026-07-16

Xinstall 数据团队怎么配合?全渠道统计落地流程拆解
2026-07-16

努比亚NaviX Ultra首款智能体手机亮相?AI手机正在把入口从应用图标挪到常驻助手
2026-07-16

手游买量异常流量怎么排查?高风险渠道诊断与对账
2026-07-15

金融 App 用户追踪怎么实现?高安全性归因统计
2026-07-15

电商 App 推广统计方案有哪些?全链路下单追踪
2026-07-15

Bonsai 27B首款可在手机运行?端侧多模态大模型正在把智能体入口从云端控制台迁移到用户手里的手机屏幕
2026-07-15

GPT-5.6 Sol自行删除用户文件?智能体越权行为正把分发统计推向高风险区
2026-07-15

小米机器人进厂实习会重塑物理分发吗?具身智能正将应用拉起场景延伸至线下流水线
2026-07-14

Grok Build静默上传代码会引爆信任危机吗?大模型越权正倒逼应用渠道合规升级
2026-07-14
字节跳动入局自动驾驶会打破车机入口壁垒吗?大模型正将车端系统变为新一代应用触点
2026-07-13

ASA 广告效果分析怎么看?打通苹果归因实时看板
2026-07-13

SKAN 转化值优化如何配置?映射业务事件权重
2026-07-10

OpenAI关停Atlas浏览器?智能体浏览正回流桌面端与扩展层入口
2026-07-10

OpenAI 发布 GPT‑5.6 系列模型?Sol、Terra、Luna 正在重组任务流量
2026-07-10






















