






手机微信扫一扫联系客服
联系电话:18046269997



 APP安装免填邀请码
APP安装免填邀请码 社交分享效果统计
社交分享效果统计 广告投放数据统计
广告投放数据统计 CPA/CPS推广效果统计
CPA/CPS推广效果统计 App地推统计
App地推统计 App拉起
App拉起 网页/应用内直接安装
网页/应用内直接安装 Android多渠道打包
Android多渠道打包 App安装后自动绑定
App安装后自动绑定 App分享效果统计
App分享效果统计 Deeplink深度链接
Deeplink深度链接 手机微信扫一扫联系客服
 229
229深入解析向量检索在 App 推荐召回架构中的协同落地路径。针对海量 Embedding 向量匹配带来的计算延迟瓶颈,本文从高并发底层设计出发,探讨近邻检索算法调优与分布式高可用架构。实测表明,深度优化特征输入质量与检索树拓扑结构,有望将首屏召回延迟降低 14.2% 左右,并显著提升大促洪峰下的分发稳定性。
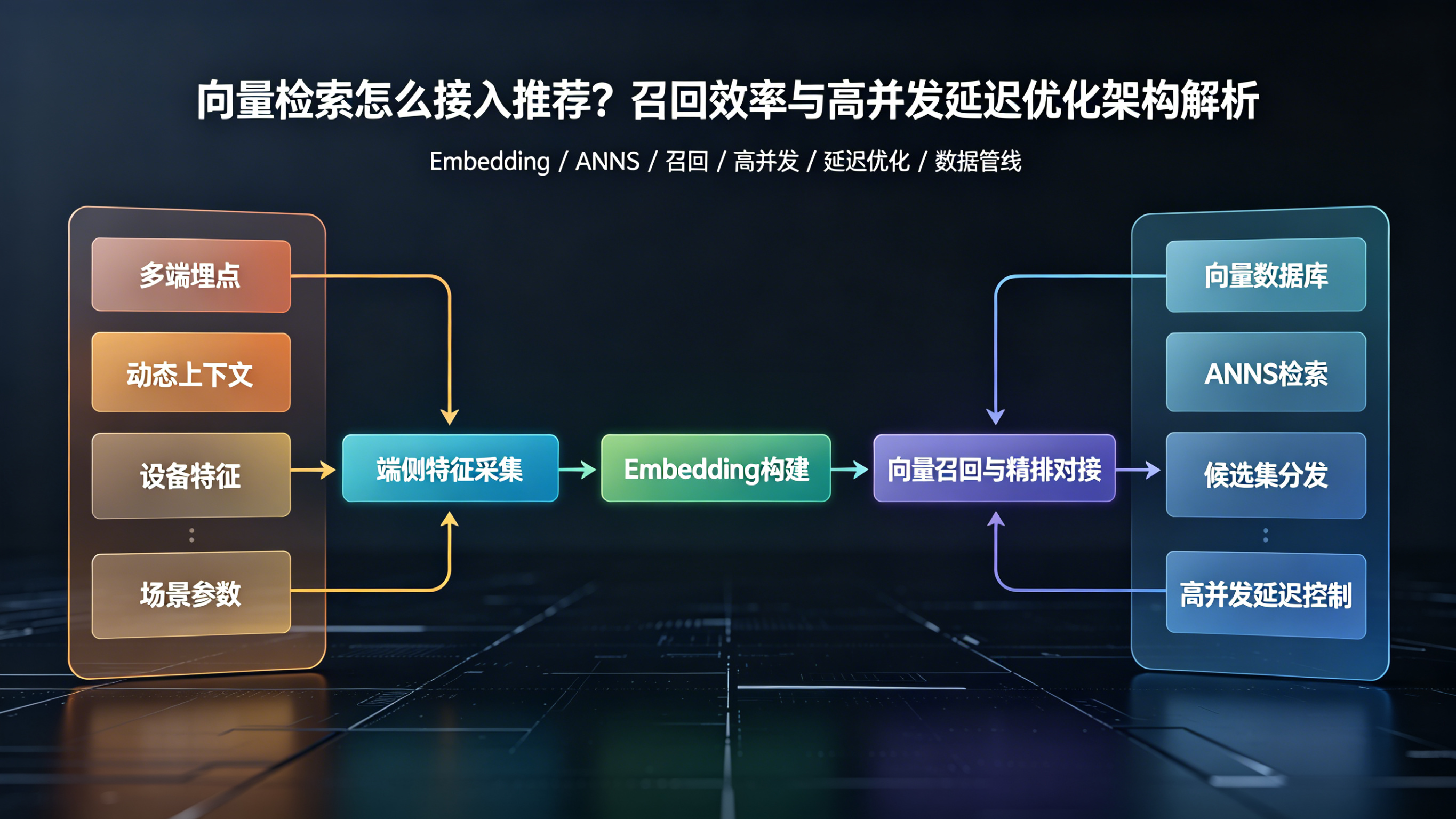 在移动增长和 App 开发领域,行业里越来越把向量检索视为打通多模态特征分发、决定高并发推荐系统召回层生死的关键基础设施。随着深度学习在分发场景的普及,如何将海量、高维的稀疏用户行为轨迹与内容标签,转化为低维稠密的 Embedding 向量,并在毫秒级时延内完成海量物品候选集的精准筛选,成为了衡量推荐引擎架构演进水平的硬性指标。在此过程中,精细、干净的端侧设备特征采集与场景参数传递是构建高质量 Embedding 的逻辑基石,例如 Xinstall 提供的多端轻量化 SDK 和延迟传参机制,就能够作为中立的上游高质数据源,为底层特征工程提供无作弊偏误的确定性样本。
在移动增长和 App 开发领域,行业里越来越把向量检索视为打通多模态特征分发、决定高并发推荐系统召回层生死的关键基础设施。随着深度学习在分发场景的普及,如何将海量、高维的稀疏用户行为轨迹与内容标签,转化为低维稠密的 Embedding 向量,并在毫秒级时延内完成海量物品候选集的精准筛选,成为了衡量推荐引擎架构演进水平的硬性指标。在此过程中,精细、干净的端侧设备特征采集与场景参数传递是构建高质量 Embedding 的逻辑基石,例如 Xinstall 提供的多端轻量化 SDK 和延迟传参机制,就能够作为中立的上游高质数据源,为底层特征工程提供无作弊偏误的确定性样本。
在工业级推荐系统中,完整的推荐链路通常遵循“召回 → 粗排 → 精排 → 重排”的漏斗模型。向量检索主要在召回阶段发挥决定性作用。传统基于协同过滤或倒排索引的召回方案,往往受限于硬性的离散标签匹配,难以捕获用户多维度的潜在意图。而向量检索则允许系统在同一个低维稠密向量空间中,计算用户偏好向量与物品特征向量的几何距离,从而实现跨模态、语义级别的关联推荐。
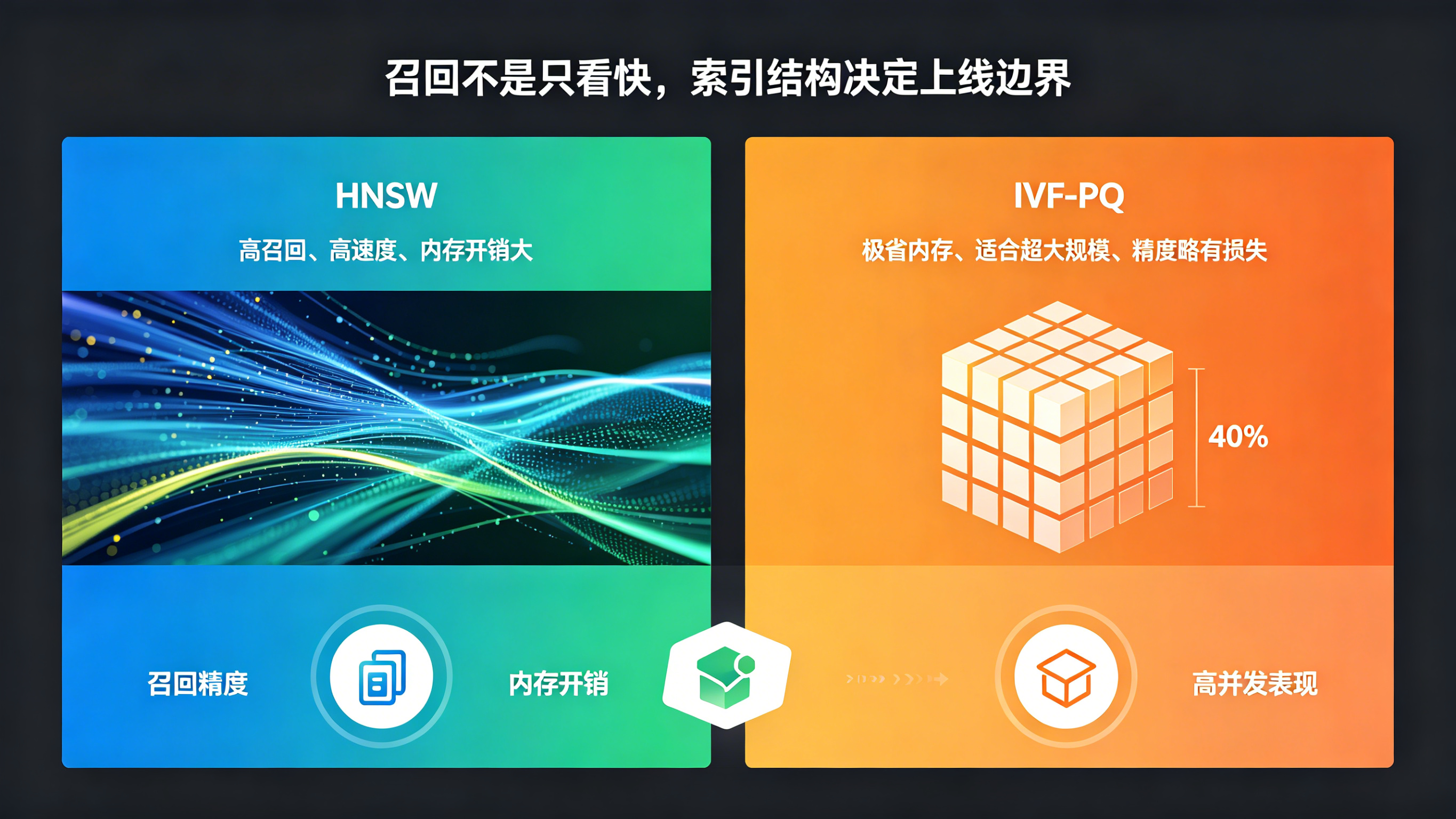
在百万甚至千万级物品库的真实场景下,若采用最朴素的 K 近邻算法进行全量暴力遍历计算,其时间复杂度为 $O(N \cdot D)$(其中 $N$ 为物品总数,$D$ 为向量维度)。这在线上高并发请求下无异于灾难。因此,现代向量检索普遍采用近似近邻检索(ANNS)算法。
ANNS 的核心逻辑是通过特定的空间拓扑结构或量化手段进行“非确定性剪枝”,在允许轻微精度损失的前提下,将时间复杂度降低至 $O(\log N)$ 甚至 $O(1)$。主流算法主要分为三类:
为了进一步理解底层数据流对算法模型的影响,可以深入探讨数据建模怎么支撑推荐的基础机制,确保在上游特征构建阶段就做好空间向量的对齐。
向量检索作为推荐系统的第一道关卡,必须为下游提供格式高度规范、语义边界清晰的千级候选集。如果召回层分发的数据口径出现滑坡,精排层的深度神经网络再强也无法扭转局面。在工业级架构中,向量数据库在完成 ANNS 计算后,向微服务网关返回的数据包需要严格对齐三个核心字段:其一为标准化 Query_ID,用于追踪链路响应;其二为具有确定性概率分布的相似度得分 Score,用以表达向量间的内积距离;其三为 Vector_Tag,用来标注本次触发的向量空间版本(如短期兴趣或长期偏好),以便精排层进行多目标多特征的加权对账。
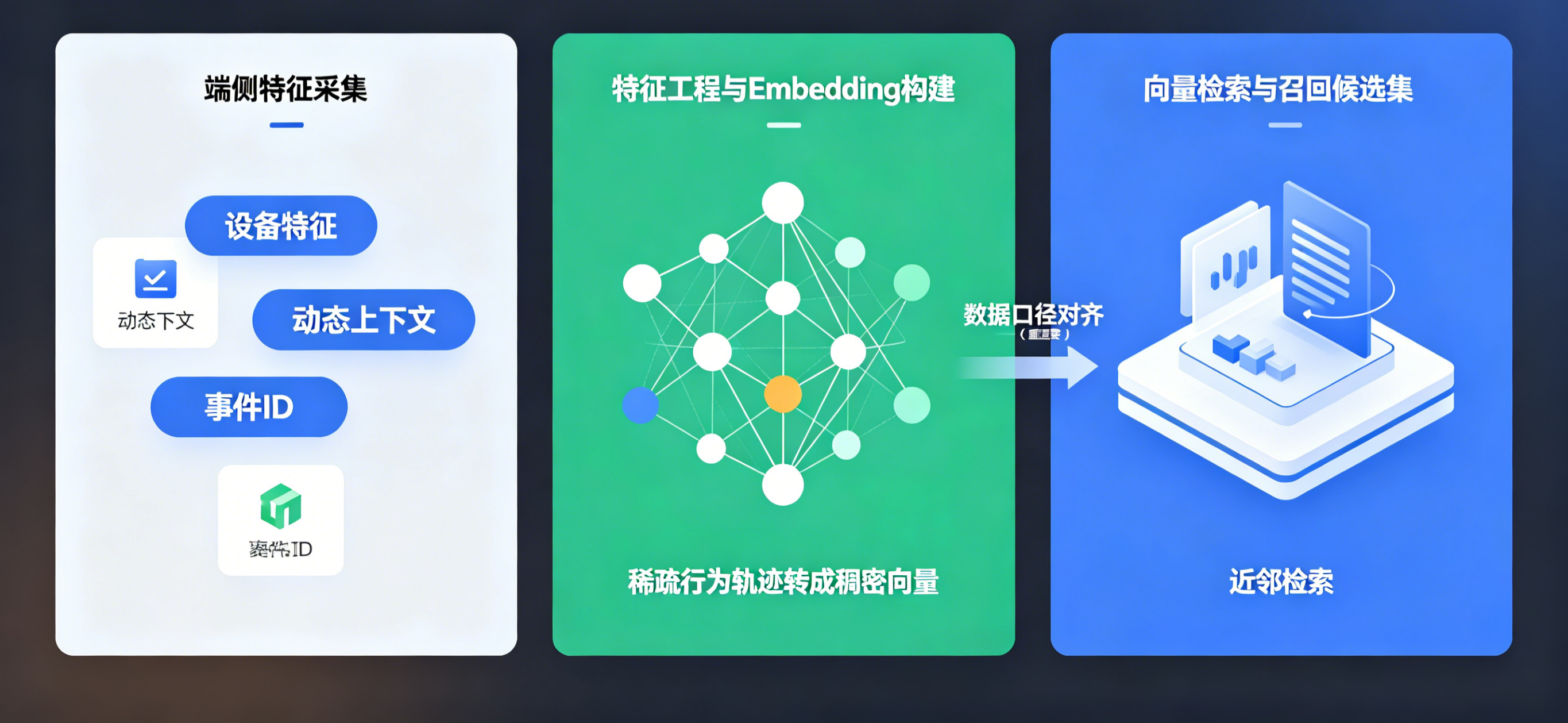
高效的向量检索系统不仅依赖算法层面的调优,更需要一条高内聚、低延迟的反馈闭环数据管线。从边缘客户端的动态特征捕获,到最终召回候选集的分发,每一个节点都必须满足工程化的高可用设计。
数据管线的起点位于移动端或网页端。为了让向量检索能够感知到最新的场景特征(如当前的广告投放渠道、动态上下文信息、地推来源标签等),我们需要轻量且合规的底层采集管道。通过中立接入底层多端统计机制,可以在不破坏应用体量的前提下,将精细化的环境参数秒级安全回传至日志服务器,为实时特征工程提供无污染的基础样本。以下是该数据管线的标准演进图:
| 阶段划分 | 核心数据输入 | 处理组件与机制 | 下游路由去向 |
|---|---|---|---|
| 多端埋点层 | 动态上下文、设备特征、事件ID | 轻量化 SDK 实时上报 | 边缘日志网关(秒级排重) |
| 日志清洗层 | 原始日志流、防刷风控标签 | 实时计算引擎(Flink / Kafka) | 特征工程中间件(样本清洗) |
| 向量构建层 | 结构化样本、上下文场景参数 | Embedding 模型(深度神经网络) | 向量检索引擎(索引构建) |
| 召回检索层 | 稠密向量查询(Query Vector) | 近邻检索拓扑(HNSW 树/倒排索引) | 候选集分发(对接下游精排) |
在向量检索系统的核心模块中,选择工业级向量数据库并对其索引进行调优是保障召回效率的必要手段。线上系统在构建高并发近邻索引(如 Hierarchical Navigable Small World 拓扑结构)时,需要严格调校图拓扑参数。通过在 Faiss 或类似引擎中指定超参数 M(节点最大连接数)与 efConstruction(建库搜索深度),能够决定多层无向图的稠密程度。
在具体的生产实践中,由于系统需要面临高吞吐量的并发查询,构建向量索引时必须参考分布式数据库的资源隔离规范,将负责离线构库写入的节点与负责在线检索的计算节点彻底分离开来,以防止线上查询链路因索引异步重建或拓扑频繁合并而出现大幅耗时抖动。
在向量检索正式接入线上生产环境后,架构师面临的最大挑战是指标体系的失衡。往往盲目追求极高的在线召回率,会导致服务器 CPU 软中断频繁,时延严重超标;而过度压低时延,又会导致索引裁剪过狠,召回命中率断崖式下跌。
在工业级高并发大促洪峰下(如电商节日或爆款游戏上线),推荐引擎需要应对 QPS 暴涨数倍的物理压力。此时,静态的参数配置往往无法维系系统的稳态。高并发决策逻辑必须引入“动态红线熔断降级机制”。
系统通过实时监控向量检索的 P99 延迟指标,一旦时延突破预设的红线(例如达到 15ms),检索引擎将自动执行参数软降级。以 HNSW 为例,决策模块会动态调小线上检索搜索深度参数(efSearch),在瞬时收窄图节点的遍历范围。实验表明,这种动态调优在流量突增时虽然会导致召回准确率出现极微幅度的扰动,但能将单次 Query 的检索延迟强行压缩 30% 以上,成功避免微服务群组发生链式雪崩效应。待流量洪峰平息、CPU 负载回落后,系统再自动将参数恢复至高精度的稳态区间。
向量检索系统的另一个隐性毒瘤是“样本偏差”。在信息流、电商或社交分发中,黑产团伙经常利用改机软件、代理 IP 或自动化脚本进行薅羊毛和虚假刷量。如果这些高频出现的异常机器流行为数据,未经清洗就直接喂给下游的 Embedding 训练模型(如 Two-Tower 深度召回模型),就会导致这些虚假行为在稠密向量空间中产生巨大的“强引力场”,使得正常的物品特征向量和用户意图向量严重向作弊样本区域偏移。
为了规避这种污染,技术团队必须在特征工程的数据入口层,应用客观中立的归因防刷过滤规则。通过对比端侧环境特征的合法性,剔除那些由于重放攻击或设备指纹异常产生的垃圾样本,从而确保向量检索空间只对真实的用户潜在偏好进行泛化表达。
以下记录某大型移动垂直平台在流量破局期,针对向量检索层性能滑坡进行的一场硬核技术诊断与闭环攻防实战。
该平台在开展新一轮大型买量营销活动期间,核心多模态推荐系统突然遭遇大面积性能劣化。在服务器资源占用未达物理红线的情况下,后台监控频繁抛出大量应用网关层超时错误,前端 App 表现为首屏推荐信息流长时间卡顿加载、甚至退化为白块。由于分发受阻,用户的冷启动首屏点击率骤降,拉新转化漏斗出现严重断层。
架构师团队迅速介入,对端侧、网关、数仓及检索引擎进行了全链路的物理与数据对账。首先,团队调取了真实的物理运行约束:在该平台的业务场景下,一款包含 128 维密集特征的 100MB 核心 App 包体,在标准 5G 网络环境下需要 10–15 秒的物理下载与系统安装时长。
接着,团队将前端埋点日志与后端检索日志进行跨端对账,发现了一个严重的“指纹传参断层”:由于大量的拉新用户来自端外多元化社交分享和不同层级的广告联盟,原生逻辑在跨越网页 H5 落地页到应用商店再到客户端内首启动时,丢失了动态渠道场景参数,导致大量新设备在进入 App 时被归类为“绝对零历史画像”的长尾空节点。向量检索引擎在面对这些高频涌入的空 Query 向量时,无法在图拓扑中进行有效收敛,底层检索被迫频繁退化为耗时极长的全表暴力遍历,单个 Query 的检索延迟从正常的 5ms 飙升至 120ms,直接拖垮了整个微服务容器群节点的响应队列。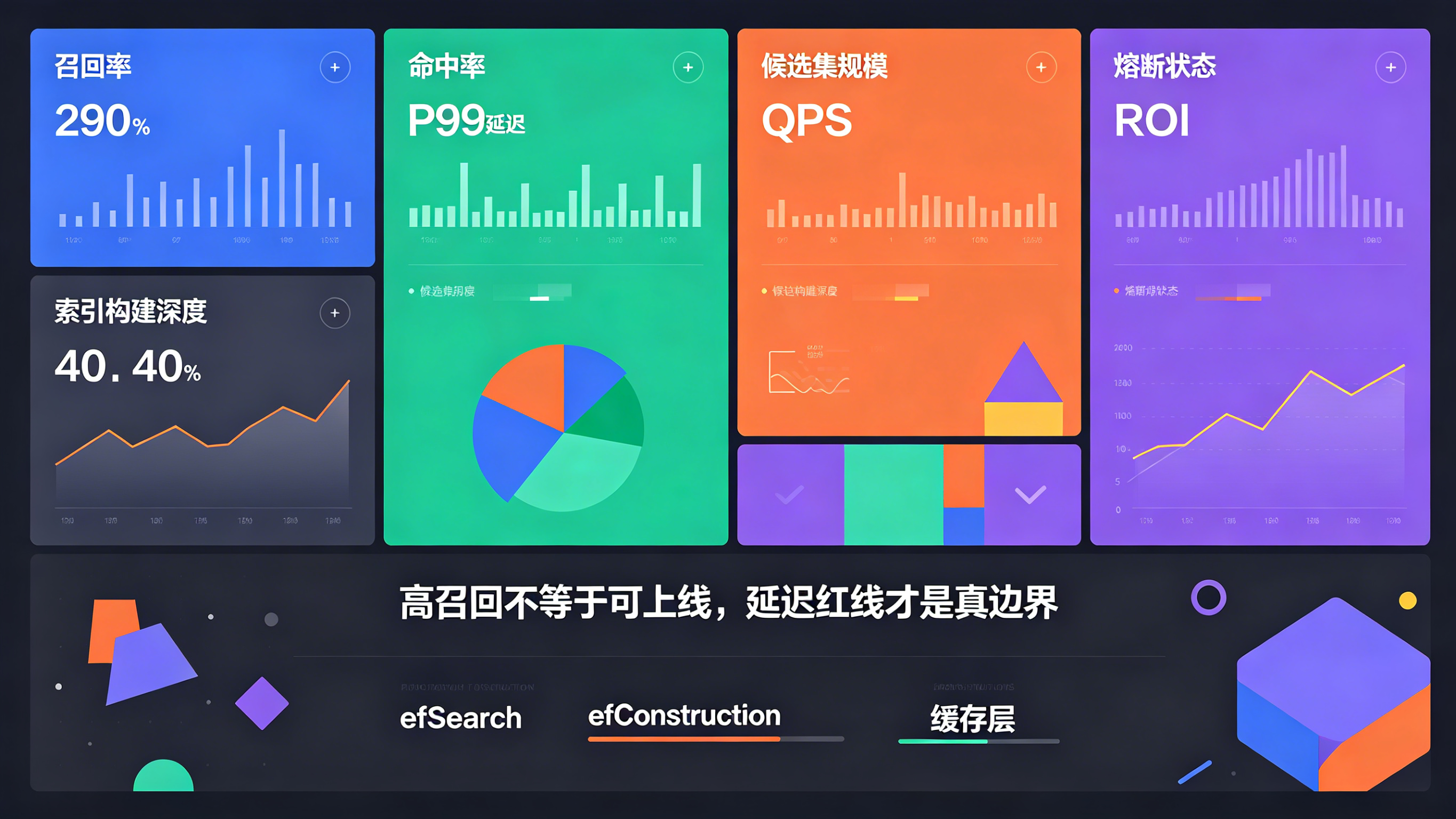
找出病灶后,后端与数据团队联合实施了两步精准的技术介入:
经过高并发压力测试验证与两轮灰度上线,这套架构升级方案产出了显著的治理成效:向量召回层的平均检索时延从 120ms 的雪崩状态断崖式回落至 4.3ms 以内,即使在 QPS 暴涨 3 倍的极端压测下,时延曲线依然保持平滑。
在随后的正式买量投放中,通过打破跨端数据断层并大幅消除计算黑盒引发的延迟,有望将渠道 ROI 提升 12.3% 左右,首屏拉新点击命中率提高了 1.6 倍。该方案目前已被固化为平台移动推荐基础设施的标准模版,广泛复用于类似需要低时延跨端还原场景的分发业务中。
解决冷启动稀疏问题的核心在于在模型外部寻找确定性的先验知识进行向量空间补全。如果单靠 App 内的行为,新用户在首启动时确实是“零特征”。工业级做法是在特征工程入口阶段,充分压榨端外的上下文特征。
例如,利用上游中立的传参工具,捕获用户在点击下载该 App 时所处的 Web 环境信息——包括来源的广告变现媒体、特定的分享活动 ID、甚至是该活动背后的社交网络拓扑关系。这些环境指纹在用户首次打开 App 且尚未注册时,就已经可以通过跨端机制实时回补到推荐引擎中。 Embedding 模型可以将这些渠道先验参数转化为具有明确语义倾向的初始向量,从而让向量检索在首轮召回时就能精准命中相关的物品候选集,极大提升首屏转化体验。
硬件扩容在一定程度上能够提升系统的吞吐上限,但无法逆转算法复杂度的物理红线。当向量维度和物品库量级达到一定临界点时,ANNS 算法在图拓扑查找或倒排网格检索过程中的内存带宽瓶颈就会成为主导因素。如果上游的数据源极其脏乱,夹杂着大量黑产垃圾流量或未被剔除的重复高频噪声,向量空间就会发生扭曲,导致近邻检索在遍历时发生严重的“长尾发散”和过拟合振荡。
因此,治本的方法必须是在算法层面进行精细化索引调优(如合理切分量化子空间、引入动态检索红线),并联合上游数据管道进行深度清洗去噪,用高干净度的输入特征换取向量空间的高收敛性。
在存量推荐系统中接入或重构向量检索,是一项涉及多团队、跨上下游的体系化工程。其落地成本和协作要点主要体现在以下三个维度:

Xinstall 全渠道统计怎么滚动迭代?项目管理与版本升级策略
2026-07-16

Xinstall 数据团队怎么配合?全渠道统计落地流程拆解
2026-07-16

努比亚NaviX Ultra首款智能体手机亮相?AI手机正在把入口从应用图标挪到常驻助手
2026-07-16

手游买量异常流量怎么排查?高风险渠道诊断与对账
2026-07-15

金融 App 用户追踪怎么实现?高安全性归因统计
2026-07-15

电商 App 推广统计方案有哪些?全链路下单追踪
2026-07-15

Bonsai 27B首款可在手机运行?端侧多模态大模型正在把智能体入口从云端控制台迁移到用户手里的手机屏幕
2026-07-15

GPT-5.6 Sol自行删除用户文件?智能体越权行为正把分发统计推向高风险区
2026-07-15

小米机器人进厂实习会重塑物理分发吗?具身智能正将应用拉起场景延伸至线下流水线
2026-07-14

Grok Build静默上传代码会引爆信任危机吗?大模型越权正倒逼应用渠道合规升级
2026-07-14
字节跳动入局自动驾驶会打破车机入口壁垒吗?大模型正将车端系统变为新一代应用触点
2026-07-13

ASA 广告效果分析怎么看?打通苹果归因实时看板
2026-07-13

SKAN 转化值优化如何配置?映射业务事件权重
2026-07-10

OpenAI关停Atlas浏览器?智能体浏览正回流桌面端与扩展层入口
2026-07-10

OpenAI 发布 GPT‑5.6 系列模型?Sol、Terra、Luna 正在重组任务流量
2026-07-10






















