






手机微信扫一扫联系客服
联系电话:18046269997



 APP安装免填邀请码
APP安装免填邀请码 社交分享效果统计
社交分享效果统计 广告投放数据统计
广告投放数据统计 CPA/CPS推广效果统计
CPA/CPS推广效果统计 App地推统计
App地推统计 App拉起
App拉起 网页/应用内直接安装
网页/应用内直接安装 Android多渠道打包
Android多渠道打包 App安装后自动绑定
App安装后自动绑定 App分享效果统计
App分享效果统计 Deeplink深度链接
Deeplink深度链接 手机微信扫一扫联系客服
 298
298当“超级员工”成为职场标配,企业级应用和SaaS产品面临大量由AI代理发起的请求,如何在底层日志中区分“人”与“机”,成为新的数据基建挑战。
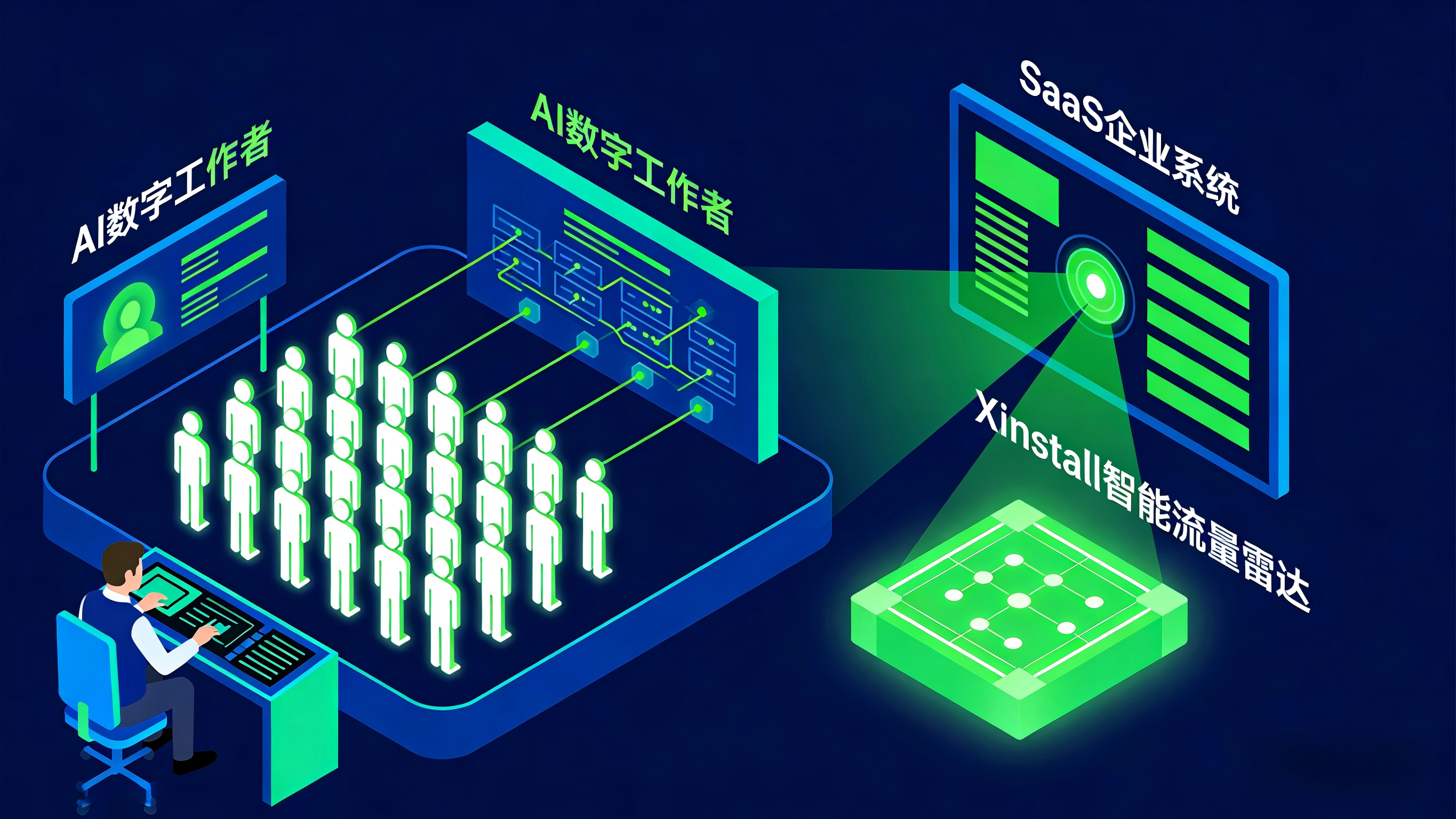 一位前谷歌产品负责人,如今是自动化平台 Relay.app 创始人的 Jacob Bank,向外界展示了一个颠覆认知的团队配置:他每月仅花费 500 美元,运营着 40 个 AI 代理,完成了原本需要 5 万美元营销团队才能做完的工作。当“一人公司”借助 AI 代理变成普遍现实,那些服务于这些企业的 B 端 SaaS、工具类 App 和 CRM 系统,即将面临一场前所未有的流量身份危机:当服务器里涌入海量的调用请求时,对面坐着的到底是人,还是机器?
一位前谷歌产品负责人,如今是自动化平台 Relay.app 创始人的 Jacob Bank,向外界展示了一个颠覆认知的团队配置:他每月仅花费 500 美元,运营着 40 个 AI 代理,完成了原本需要 5 万美元营销团队才能做完的工作。当“一人公司”借助 AI 代理变成普遍现实,那些服务于这些企业的 B 端 SaaS、工具类 App 和 CRM 系统,即将面临一场前所未有的流量身份危机:当服务器里涌入海量的调用请求时,对面坐着的到底是人,还是机器?
根据36氪的报道,Jacob Bank 构建的 40 个 AI 代理各司其职,涵盖了社交媒体发布、竞品动态监测、销售会议复盘和客户邮件跟进等任务。这种模式正在迅速普及,许多外贸和电商业者也开始使用开源框架(如 OpenClaw 或低代码平台)搭建 AI 员工,实现自动跟进询盘或数据分析。
这意味着职场的运作方式正在从“人操作软件”向“人指挥 AI,AI 操作软件”转变。对于协同办公、内容发布、CRM 管理等 App 和 SaaS 平台而言,环境发生了巨变:它们的日活用户(DAU)或调用量可能会出现指数级增长,但这背后的真实人类用户并没有等比例增加。大量请求是 AI 代理基于自动化工作流(Workflow)定时、条件触发或通过 API 批量发起的。系统正在被大量的“非人流量”所接管。
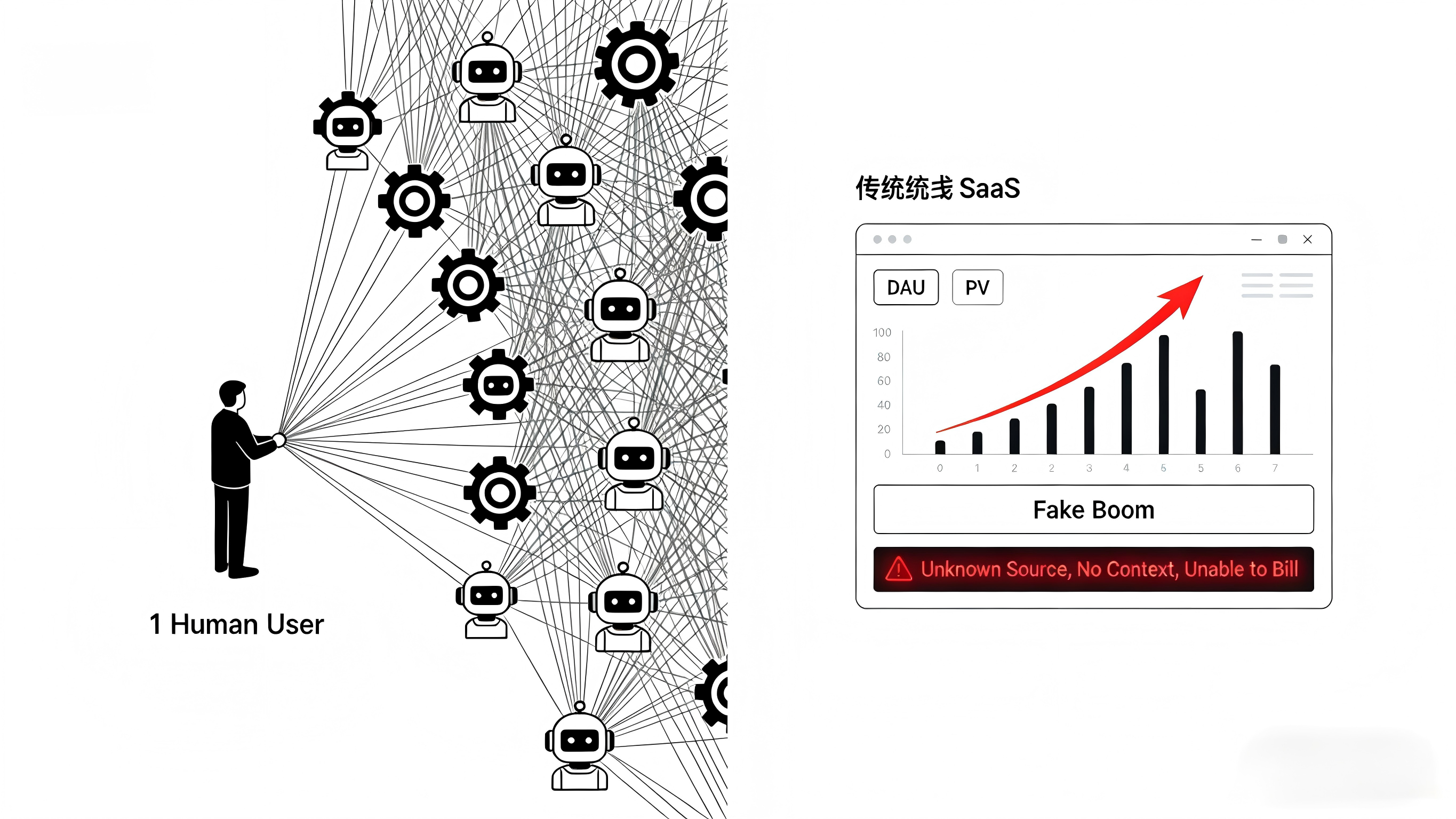
在传统的软件服务中,增长团队习惯于追踪一个人的行为轨迹:员工 A 登录了系统,点击了新建文档,编辑了 30 分钟,最后点击保存并分享。这一整套动作构成了有价值的用户活跃度。
但在 Jacob Bank 的 40 个 AI 代理模型下,真实的链路变成了:Jacob 发布了一个 YouTube 视频,触发了代理 A 的任务机制;代理 A 通过 API 调用了排版软件生成文案,接着调用了社交媒体 App 发布动态;同时,代理 B 自动抓取并总结了这场活动的竞品数据,最后把文档塞进了 CRM 系统。
在这条链路上,SaaS 平台的统计报表很容易陷入混乱。如果只是简单记录调用次数,产品经理会看到令人兴奋的虚假繁荣;如果无法区分这些请求来自哪个具体的工作流、哪个自动化平台(如 Relay.app、Zapier 等)或哪种类型的 AI 代理,客户成功团队就不知道该如何向企业收费,销售团队也无法评估到底是哪个核心功能的活跃度真正带来了续费增购。多云、多 Agent 的交织,让系统的埋点盲区暴露无遗。
注:本文探讨的针对多 Agent 与自动化工作流场景的底层流量识别和跨端精细化归因,属于对未来企业级应用分发与计量趋势的前瞻性技术延展。目前此类高度定制化的高阶数据链路尚未作为标准功能全量实现,如 B 端 SaaS 或 App 开发者有类似需求,欢迎联系 Xinstall 客服团队进行技术探讨或共同定向研发拓展。
面对越来越多像 Relay.app 这样的 AI 代理平台发起的请求,SaaS 与企业应用团队需要在数据底层进行重构:
使用 ChannelCode 为不同 AI 代理发放“身份牌”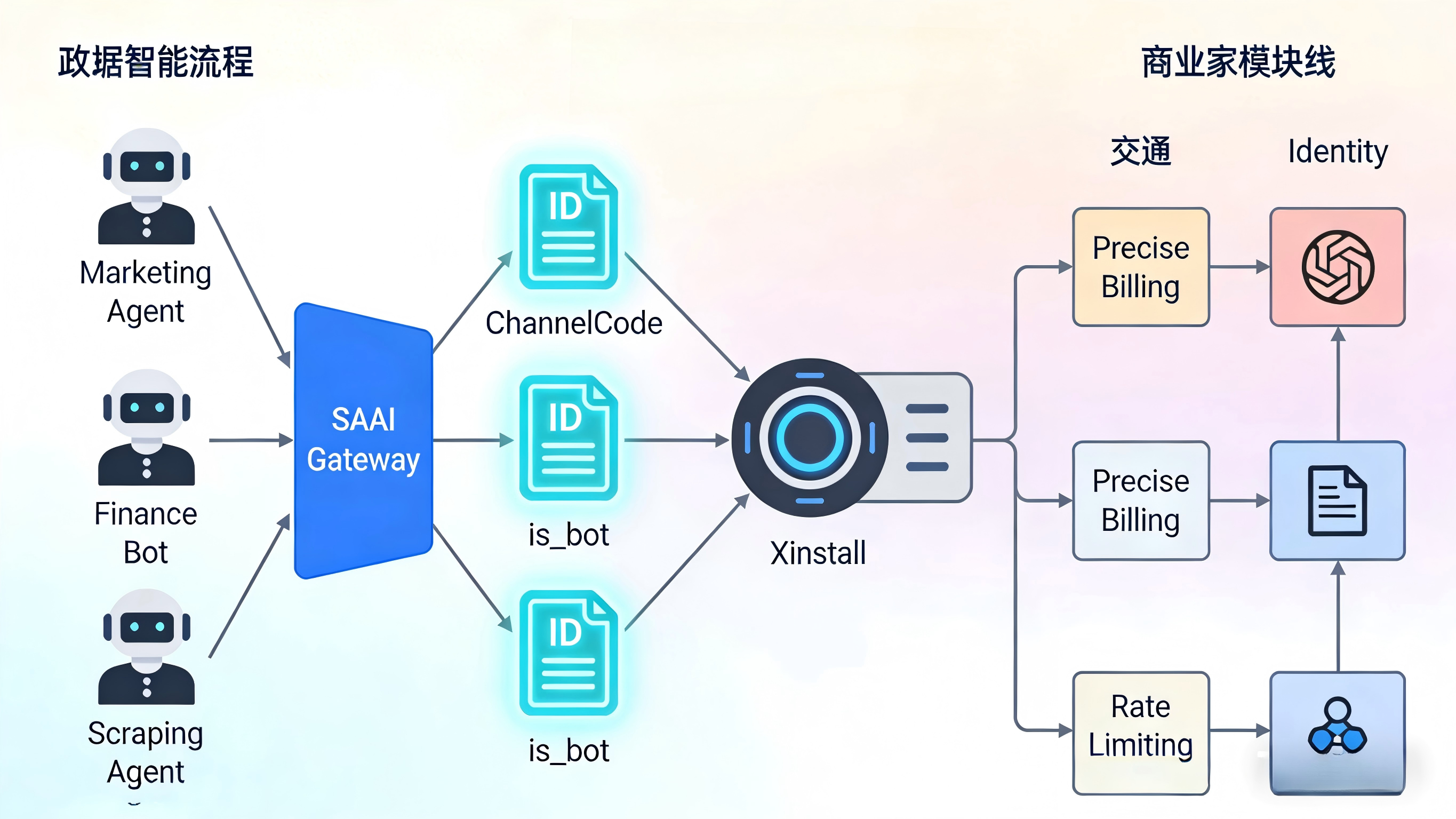
既然无法阻止企业使用 AI 代理调用服务,第一步就是规范管理。当第三方自动化平台或自研 Agent 接入系统时,必须为它们分配独立的渠道编号 ChannelCode。通过给不同角色的 AI 员工(如“营销代理”“财务助理”)打上专属的标签体系,SaaS 后台就能一眼看清:到底是哪一个 ChannelCode 带来了最多的高价值调用。问题是“人机混淆”,做法是“给机器独立发牌”,好处是让基于用量的阶梯定价与商业化结算有了清晰的依据。
利用智能传参携带工作流上下文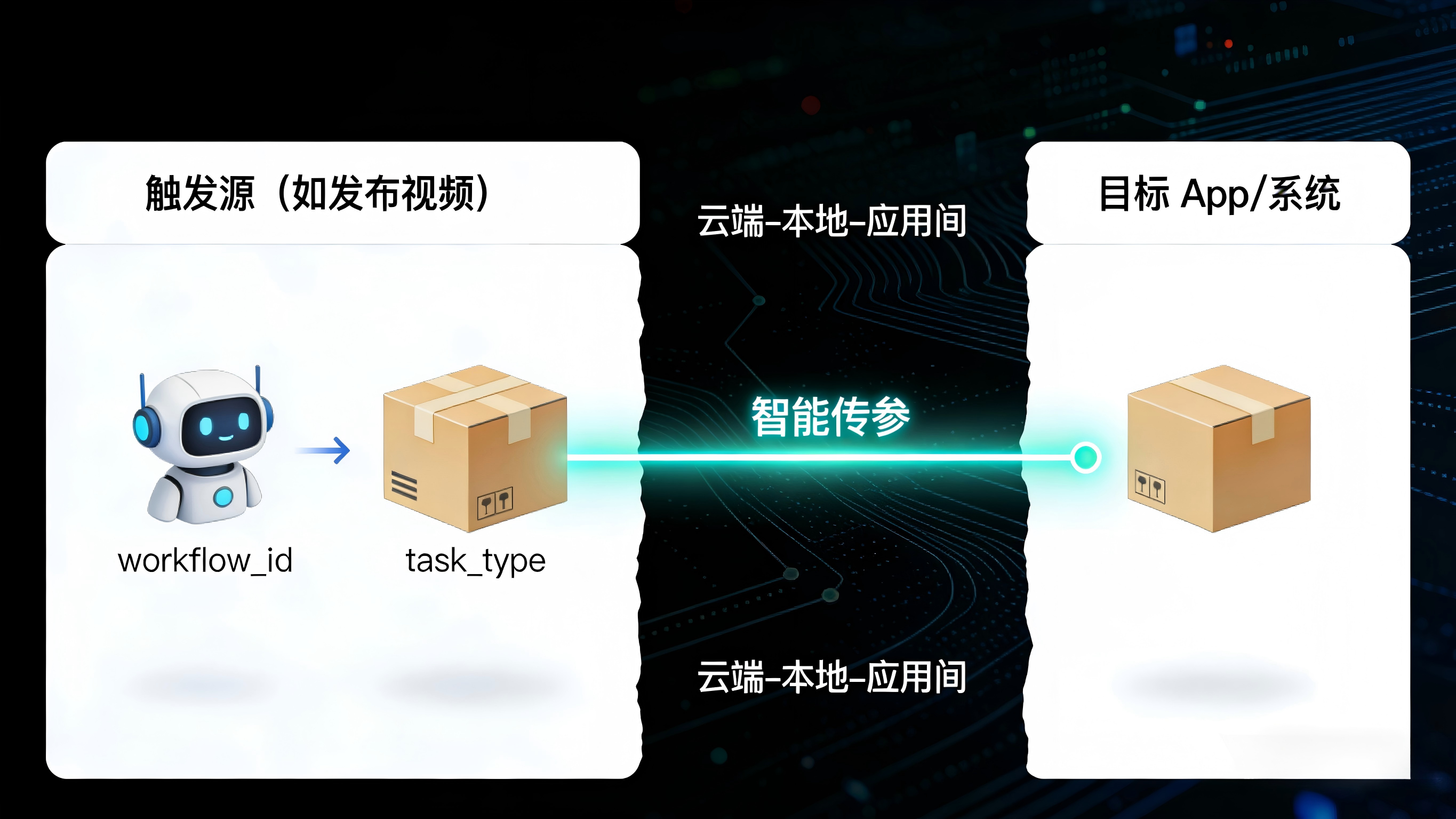
当 AI 代理在执行复杂任务时,经常需要跨越不同的软件或终端(例如从云端抓取数据,再推送到本地的分析 App 中)。在此过程中,如果调用请求仅仅是“唤醒”应用而没有携带业务上下文,任务就会中断。通过类似智能传参的逻辑机制,AI 代理在发起请求时,可以将 workflow_id、trigger_source、task_type 等深度参数注入调用链路。即便中间经历了跳转或验证,系统在处理该请求时依然能瞬间还原这笔任务的前因后果,确保 AI 代理的操作无缝履约。
构建多 Agent 的跨系统事件模型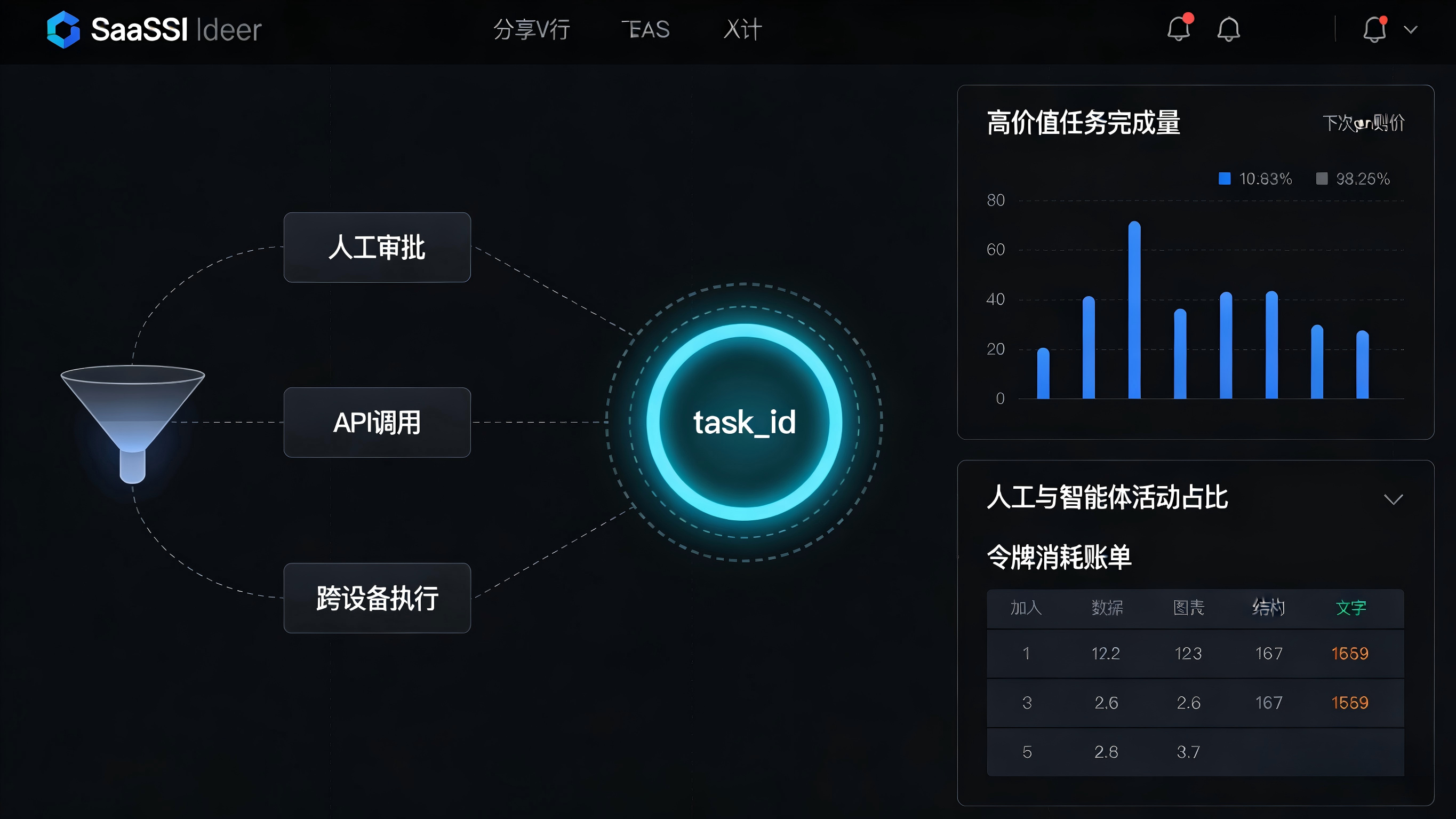
为了真实衡量“一人+几十个代理”模式下的企业账户活跃度,不能再以传统的单用户页面点击(PV/UV)作为核心指标。数据团队需要建立以 task_id 为核心的事件关联图谱。把来自网页端的人工确认、来自不同 Agent 平台的 API 调用、以及跨终端履约的动作合并到同一个企业账号的主键下。这样才能清晰地还原出:这批任务流量经过了哪些节点,最终转化为哪种业务成果。
面向开发 / 架构团队:
agent_platform 和 is_bot 等维度,严格区分自然人访问与机器并发调用。针对 AI 代理的高频操作,做好限流、防重试与幂等性设计,避免服务器资源被低价值的心跳检测或重复抓取耗尽。面向产品 / 增长团队:
如果我们把 AI 代理流量单独剥离,会不会导致报表上的日活(DAU)大幅下降,没法向投资人交差?
短期内数据的结构会发生变化,但在 AI 时代,虚高的“机器 DAU”并不产生真实的商业价值,反而会增加服务器成本。向投资人展示“人类决策者数量 + 高价值 AI 代理调用量”的双轨数据模型,反而更能证明产品的不可替代性。
如何防止恶意的爬虫伪装成 AI 代理大量消耗我们的系统资源?
单纯依靠请求频率已经很难甄别。必须结合 ChannelCode 的授信白名单机制、多因素鉴权以及结合业务上下文的参数校验。合法的 AI 代理任务通常带有明确的逻辑连贯性和工作流 ID,而恶意爬虫多为无差别的高频抓取。
小型工具 App 有必要为了 AI 代理做这么复杂的底层重构吗?
非常有必要。小型工具往往是 AI 代理工作流中最容易被调用的“原子节点”(例如专门做图片去背、或发票识别的 App)。如果你的底层系统无法识别来源并做好参数还原,你就会沦为其他大平台的免费算力提供者,而无法将这些任务流量转化为你自己的商业资产。
从 Jacob Bank 的实践可以看出,“超级独立贡献者 + 庞大 AI 代理团队”的新型职场模式正在成型。硅谷的一线经验表明,企业的数字化运转正在加速脱离对单纯人力的依赖,转而构建基于 AI 的自动化底座。
这对于所有服务于 C 端和 B 端的软件开发者来说,无异于一次流量入口的大洗牌。当人们不再需要打开你的 App,而是让 AI 代理在后台悄无声息地调用你的服务时,你必须有一套足够敏锐的数据雷达来识别这位“看不见的超级员工”。正如在《亚马逊 AI 战略升级?多云多 Agent 时代 App 该怎么认清流量真身》中讨论的,谁能用可靠的归因体系看清多 Agent 环境下的真实调用源和意图参数,谁就能在企业级服务市场的新一轮角逐中掌握计费权和议价权。
应用商店拦截后怎么归因?下载来源追踪原理解析
2026-06-26

广告监测链接怎么做?App安装来源追踪原理解析
2026-06-26

App传参安装怎么做?全渠道参数还原原理解析
2026-06-26

谷歌重组AI编程小组?追赶Anthropic的节奏被迫加速
2026-06-26
科大讯飞AI招采平台2.0如何重构流程?招投标开始进入全链路智能化
2026-06-26
携带参数安装怎么实现?安装传参与归因技术解析
2026-06-25

Agent Ready怎么落地?企业智能体进入统一管理时代
2026-06-25

360与惠普签署战略合作?AI安全与终端融合进入落地期
2026-06-25

荣耀终端要被AI重做?MWC上海上终端变革的真实信号
2026-06-25

免填邀请码怎么实现?自动绑定邀请关系技术解析
2026-06-24
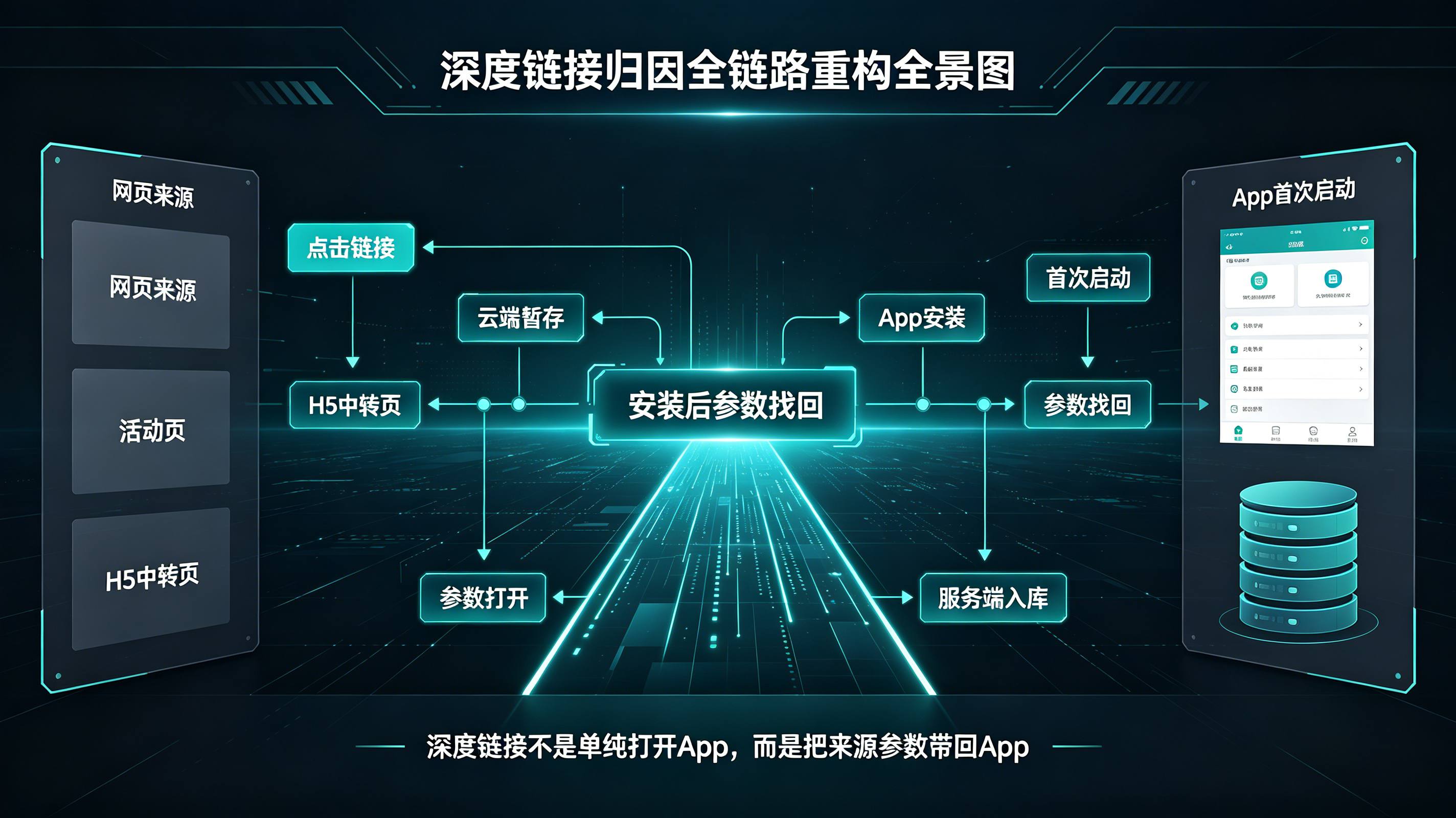
深度链接归因怎么做?安装后参数找回技术解析
2026-06-24

豆包专业版正式推出?AI收费战开打背后的订阅分层与商业验证
2026-06-24
毁灭全人类游戏今日登陆新主机?爆款主机游戏跨端种草考验一键拉起基建
2026-06-24
即梦AI上线原生4K视频生成?打破高糊魔咒,AI视觉算力重塑营销分发底座
2026-06-24

免打包渠道统计是什么?App免填邀请码技术原理解析
2026-06-23






















