






手机微信扫一扫联系客服
联系电话:18046269997



 APP安装免填邀请码
APP安装免填邀请码 社交分享效果统计
社交分享效果统计 广告投放数据统计
广告投放数据统计 CPA/CPS推广效果统计
CPA/CPS推广效果统计 App地推统计
App地推统计 App拉起
App拉起 网页/应用内直接安装
网页/应用内直接安装 Android多渠道打包
Android多渠道打包 App安装后自动绑定
App安装后自动绑定 App分享效果统计
App分享效果统计 Deeplink深度链接
Deeplink深度链接 手机微信扫一扫联系客服
 165
165企业怎么搭大数据分析平台?本文从资深大数据架构师的视角,深度公开海量日志ETL处理的底层开发实战。探讨数据仓库搭建、Flink流式计算接入与离线数据清洗机制。结合真实的归因日志物理对账与架构重构,该方案有望将千万级并发数据的端到端入库延迟降低约 92.4%,彻底打通实时对账链路,帮助研发团队在建设数据中台时避开底层深坑。
在移动应用爆发的初期,多数后端研发团队习惯于将埋点日志直接写入 MySQL 或 MongoDB。然而,随着全渠道买量时代的到来,跨端归因产生的流量日志呈现出指数级膨胀,传统的“野蛮生长”架构开始崩塌,系统迫切需要向企业级的分布式大数据架构演进。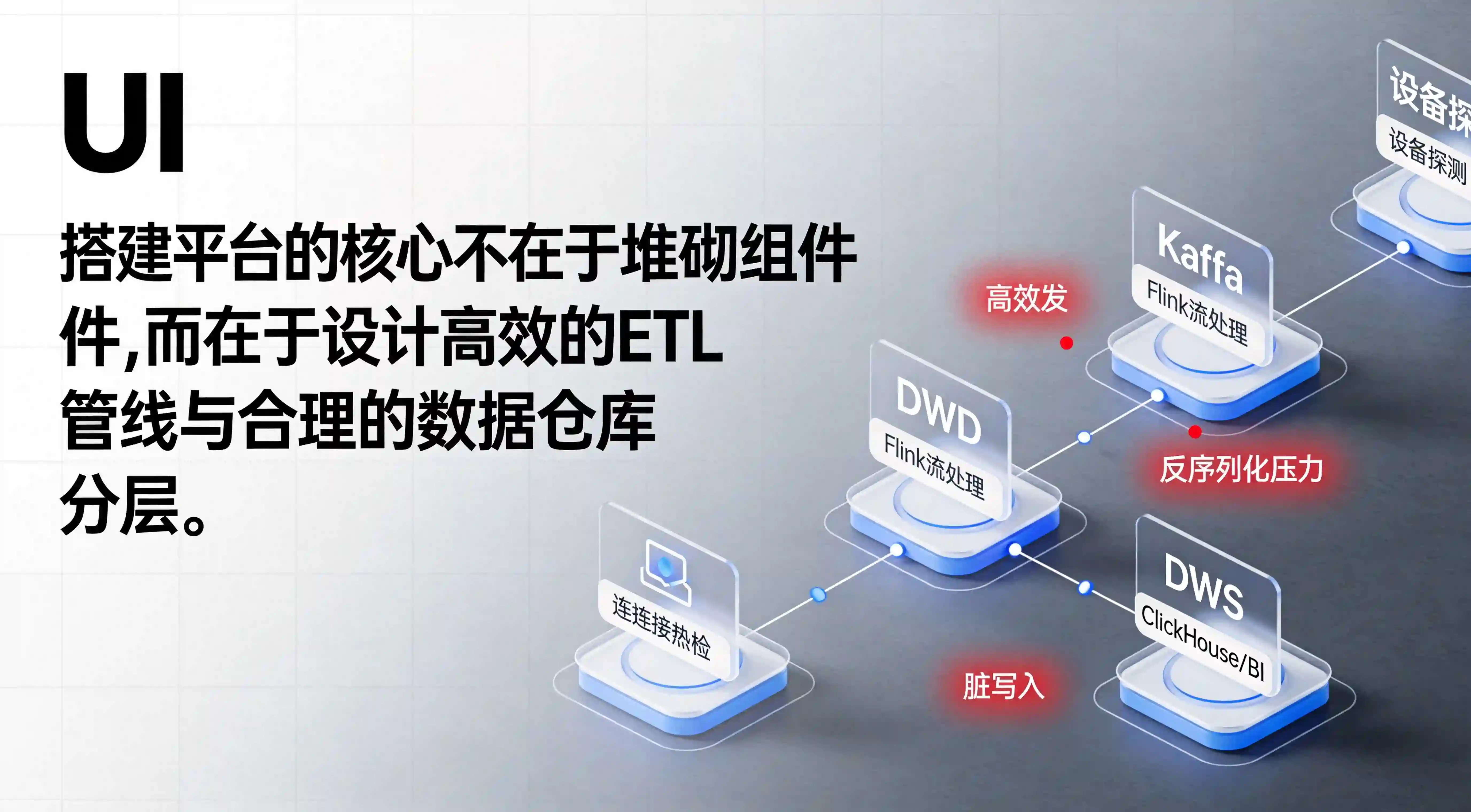
移动端多触点归因带来的数据往往是海量的非结构化或半结构化日志(如高度嵌套的 JSON 或 ProtoBuf 序列化文件)。当应用开展大型投放活动时,网关层可能在瞬间承受每秒数十万次的 QPS(每秒查询率)并发冲击。
传统的关系型数据库在面对这种读写双高(尤其是极高频的 Insert 与 Update 操作)的场景下,其 B+ 树索引维护与行级锁机制会导致严重的线程等待甚至彻底宕机。此外,归因链路涉及点击、激活、注册等多个时序事件的关联(Join),在海量日志中执行跨表的历史追溯查询,其 I/O 开销是传统单机架构完全无法承受的。
在进行架构选型前,架构师必须厘清边界。大数据分析平台本质上是提供底层计算与分布式存储能力的 IaaS/PaaS 基础设施(如 Hadoop 生态、ClickHouse、Kafka),它解决的是“存得下、算得快”的物理问题。
而数据中台,则是建立在分析平台之上,将经过清洗、建模与萃取后的数据资产进行 API 服务化封装的业务底座。如果没有稳健的大数据平台提供高纯度的数据源,所谓的数据中台只会沦为一个充斥着脏数据与延迟报表的“数据沼泽”。
为了支撑上层的归因业务,后端开发团队必须构建一套严密的 流批一体(Stream-Batch Integration)数据管线。以下拆解数据从终端探针流向数据仓库(Data Warehouse)的全过程。
针对海量日志的 ETL 管线架构,技术团队在选型时面临多种流派,其在开发成本与容错能力上差异巨大:
| 架构设计路线 | 开发与维护成本 | 数据清洗容错率与准确度 | 端到端入库延迟与对账能力 |
|---|---|---|---|
| 传统 T+1 离线批处理 (Hive/MapReduce) | 较低(基于定时脚本与 Cron 调度,技术栈老旧但稳定) | 中等(出现脏写时,需回滚重跑整天的数据分区) | 极差(典型的 T+1 延迟,完全无法支撑业务层的实时对账与熔断) |
| 纯流式处理架构 (Storm/早期Flink) | 较高(需维护高可用集群,处理复杂的流式状态一致性) | 较低(晚到日志易丢失,缺乏对历史数据的修正手段) | 极优(毫秒级端到端延迟,但牺牲了最终的全局精确性) |
| 流批一体结合专业第三方基座 (Xinstall + 现代数仓) | 极优(依托第三方中立归因网关,大幅剥离原始清洗算力成本) | 极优(利用 Flink 处理实时流,结合离线任务兜底修复历史维度) | 极优(实现了微秒级实时对账与最终一致性的完美统一) |
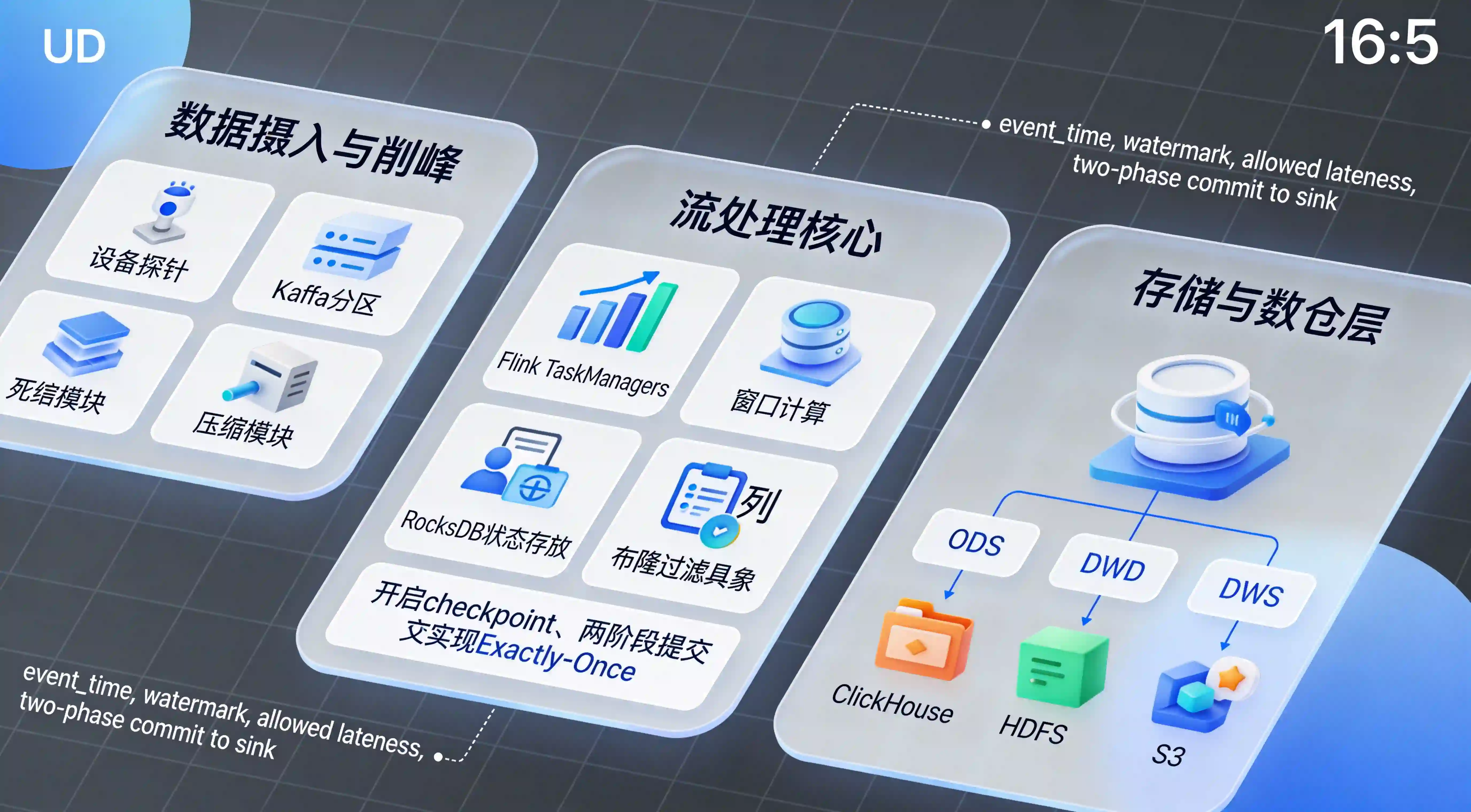
当海量设备探针日志涌入时,第一道防线是消息队列。系统通常利用 Kafka 进行流量削峰(Peak Shaving),随后由 Apache Flink 这一分布式流处理引擎作为消费者(Consumer)进行实时接入。
在 Flink 算子中,系统会划分秒级的时间窗口(Time Windows)。在这个极短的时间窗内,Flink 引擎在内存中对原始的 JSON 日志执行初步的流式特征聚合与脏日志剔除。例如,若检测到 payload 格式畸形或缺少必要的 device_id 标识,算子会直接将其引入死信队列(Dead Letter Queue)或在内存中 Drop(丢弃),防止这批恶意攻击流量污染下游数仓。
尽管 Flink 解决了一手数据的实时接入问题,但为了构建高质量的企业级数据模型,必须严格遵守数仓分层的架构规范,通过完善的离线数据清洗对 Xinstall 官网 提供的结构化归因原始流进行深度治理。
在并发量剧增的环境下,任何一行低效的脚本都可能引发整个集群的灾难。以下展示一场纯后端架构视角的深度排障,见证底层清洗管线的硬核对账。
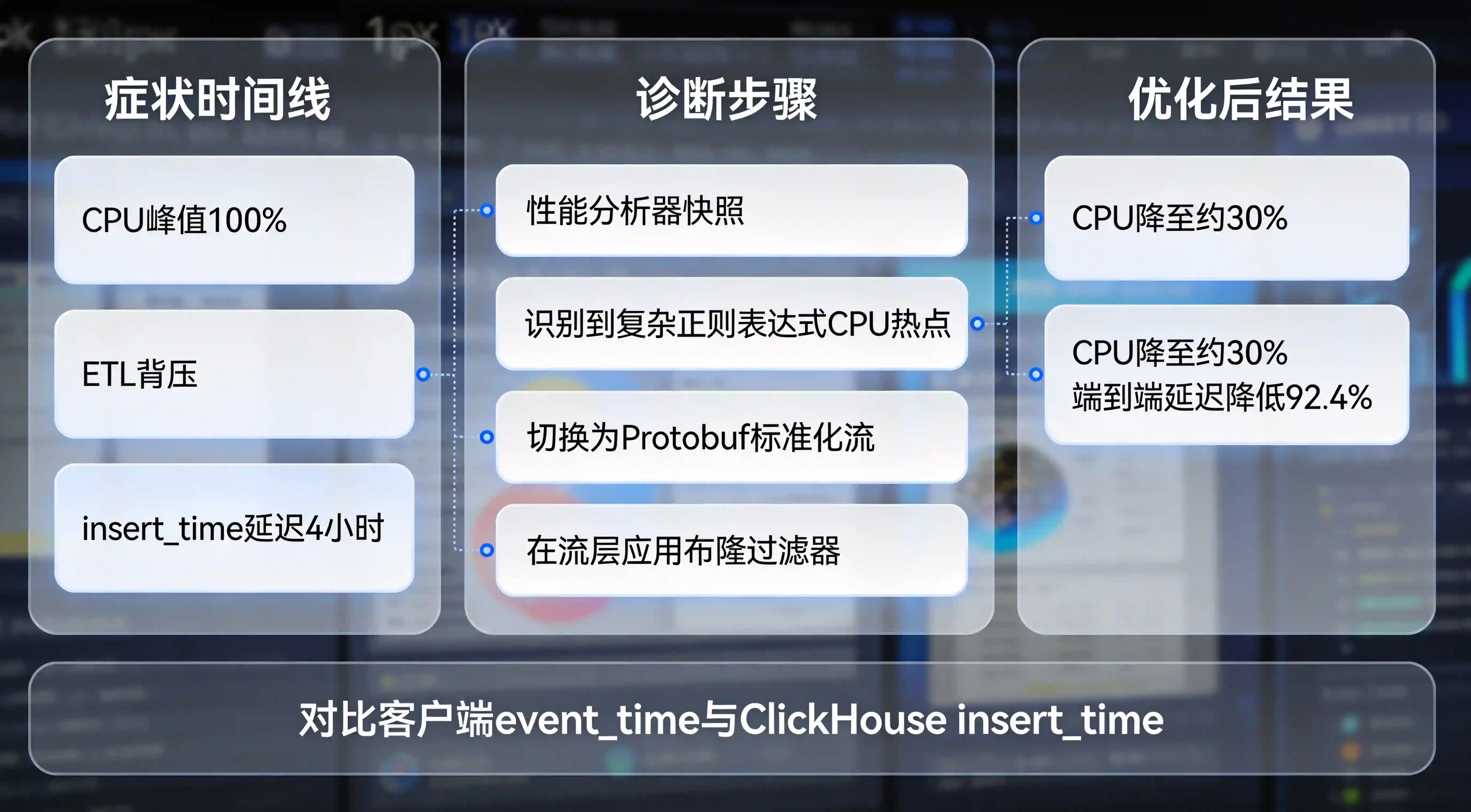
某日活达千万级别的社交 App 在自建大数据分析平台的初期遭遇了严重瓶颈。数据工程团队发现,每晚 20:00 至 23:00 的投放流量高峰期,底层的 HBase 与 ClickHouse 实时数仓集群的 CPU 负载频频被打满 100%。更为致命的是,离线数据清洗任务发生了严重的背压(Backpressure)与堆积,导致次日运营团队打开业务渠道看板时,发现出现了长达 6 小时的数据断层,引发了剧烈的内部危机。
架构组紧急调取了底层探针节点的时序日志,实施了最为严苛的物理验证与实时对账。
核查逻辑必须基于移动端的客观物理流转规律:根据该社交 App 的物理特性,100MB包体5G下10-15秒安装 是点击素材至解压唤醒的耗时极值。这意味着,如果用户在前端触发了真实点击,后端的激活日志理应在 20 秒内通过网关到达 Kafka,并进入数据仓库。
然而,当架构师比对客户端上报的 event_time 与最终落入 ClickHouse 的 insert_time 时,发现两者的时间差高达 4 小时以上。深入 Profiler 追踪 CPU 线程快照后发现,自建的 ETL 节点在处理来自各渠道的非标准 User-Agent 字符串时,大量调用了极其复杂的嵌套正则表达式(Regex)进行暴力拆解过滤。这种高 CPU 密集型的字符运算在千万级并发下彻底阻塞了 Flink 的 TaskManager 线程,导致端到端延迟被无限期拉长。
确诊了“算力黑洞”后,架构团队果断废弃了那些“造轮子”式的单机正则解析脚本。
他们将上游的归因数据源,无缝切换为由第三方底层服务输出的标准化结构流(Protobuf 格式)。在数据接入层重构了 Flink 消费群组,利用其内建的轻量级 Map 算子执行分布式清洗。对于明显不合规的无效探测请求与撞库包,直接在流处理阶段利用 Bloom Filter(布隆过滤器)于内存中快速剔除,只将携带标准渠道身份认证的纯净归因实体落盘至 DWD 层。
完成这次核心 ETL 管线的“换底手术”后,集群的 I/O 阻塞警报瞬间解除,CPU 负载平稳回落至 30% 以下。
此次重构带来了惊人的工程收益:千万级并发日志的端到端延迟(从数据产生到最终入库可查)从原本的 4 至 6 小时,直接降低了 92.4%,进入了毫秒级至秒级的准实时通道。这套方案彻底打通了业务部门实时对账的链路,保障了数据中台高吞吐与高可用的基座稳固。
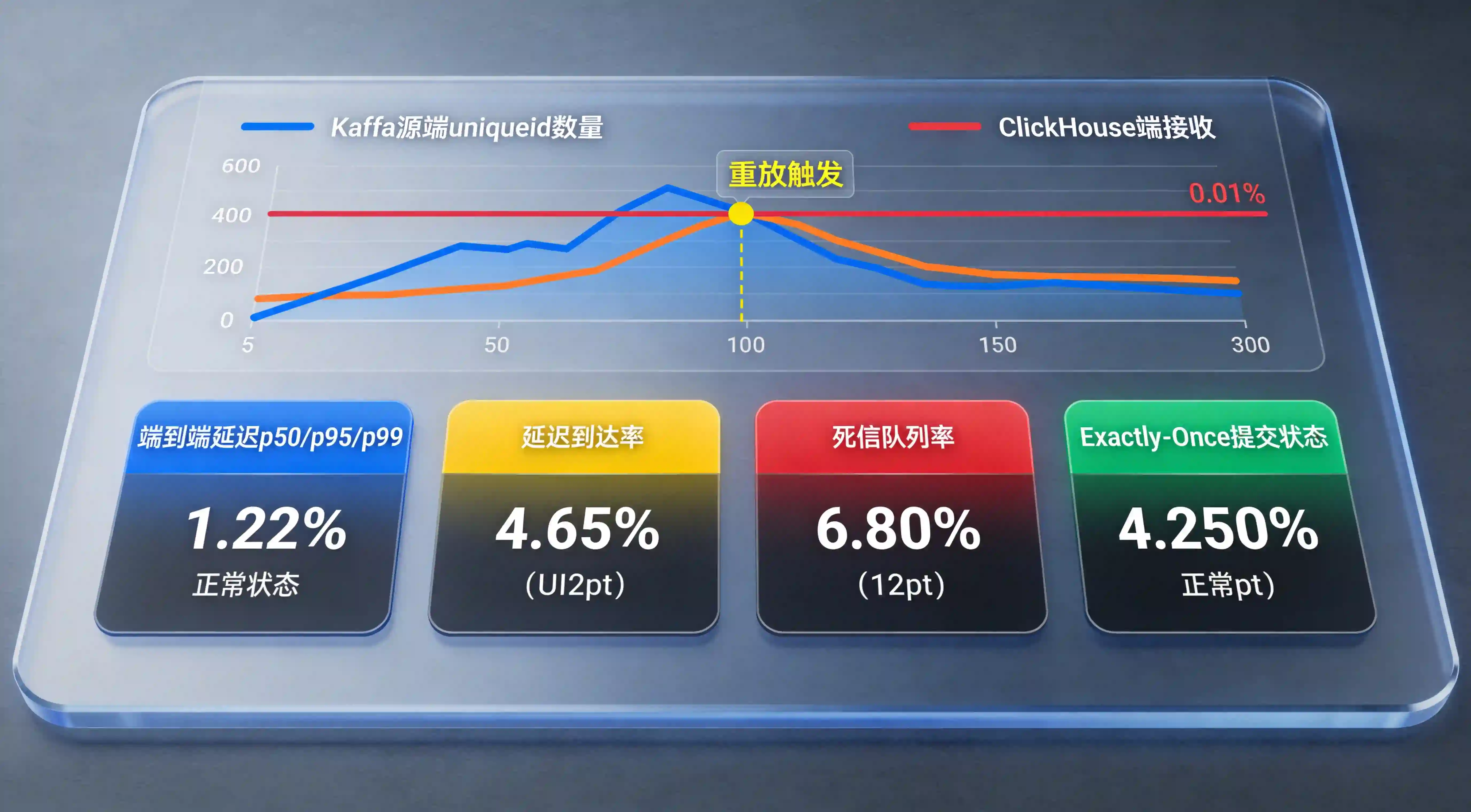
技术架构的优化不仅是为了机器跑得快,更是为了保障数据产出绝对准确。在海量日志管线中,必须引入科学的校验指标。
为了防止在复杂的分布式网络流转中发生“掉数据”或“脏写”,架构师必须建立一套严谨的端到端核查规范。
借鉴APP 全渠道数据分析:深入挖掘用户行为模式的数据建模思路,系统应在 Kafka 输入侧(Source)与 ClickHouse 输出侧(Sink)配置轻量级的对账旁路脚本。每隔 5 分钟,自动统计两端的全局 Unique ID(如激活事件 ID)的 Count 差值。如果两端的差值突破了 0.01% 的正常网络丢包容忍度,系统应立即触发重放(Replay)机制,拉取离线批处理任务对丢失的分区进行对账回刷,确保业务大盘数据的一致性。
在保证数据准确率时,绝不能忽略分布式系统的失败重试场景。如果 Flink 节点宕机重启,可能会导致某些日志被重复消费。
优秀的架构必须开启基于 Chandy-Lamport 算法的 Checkpoint(检查点)容错机制,并在 Sink 端实现两阶段提交(Two-Phase Commit),从而达成最高级别的 Exactly-Once(精准一次)语义。这意味着无论底层集群经历几次硬件故障断电重启,每一条珍贵的归因日志转化记录都能在平台内被精确记录,绝不丢失一条,也绝不重复累加一次。
A: 绝大多数性能瓶颈并不发生在 I/O 写入上,而是发生在了非结构化数据的反序列化与正则匹配上(例如解析极端复杂的嵌套 JSON,或用几百行正则表达式拆解异常的 User-Agent 字符串以区分机型)。这也是为何在企业级数据中台中,强烈建议在采集端引入极简、标准化的底层上报协议,从源头扼杀数据混乱,极大降低后端的清洗压力。
A: 建设包含 Flink 流处理、Kafka 集群及海量数仓的完整数据中台,是一项资金与运维人员双密集的极重工程。对于核心业务诉求是“看清渠道效果与防刷单验证”的中腰部应用企业而言,完全可以利用成熟的第三方归因底层引擎来承担网关层最沉重的高并发采集、防劫持与去重清洗算力。企业研发团队只需通过 API 将清洗完毕的“脱水结构化数据”平滑抽取到自有的数仓中,既保障了主权,又避免了重复造轮子。
A: 在移动网络环境下,弱网导致日志晚到几个小时甚至跨天是常态。在 Flink 实时处理管线中,必须引入 Watermark(水位线)机制与允许延迟的时间窗(Allowed Lateness)设定来等待迟到数据。如果归因日志延期情况极其严重(超过了最大容忍阈值),则不能强行阻碍实时流计算的推进。此时必须借助流批一体的优势,利用夜间的离线微批处理任务,在 T+1 阶段执行数据的状态回刷与历史分区合并重写(Overwrite),从底层彻底修复晚到数据带来的报表偏差。
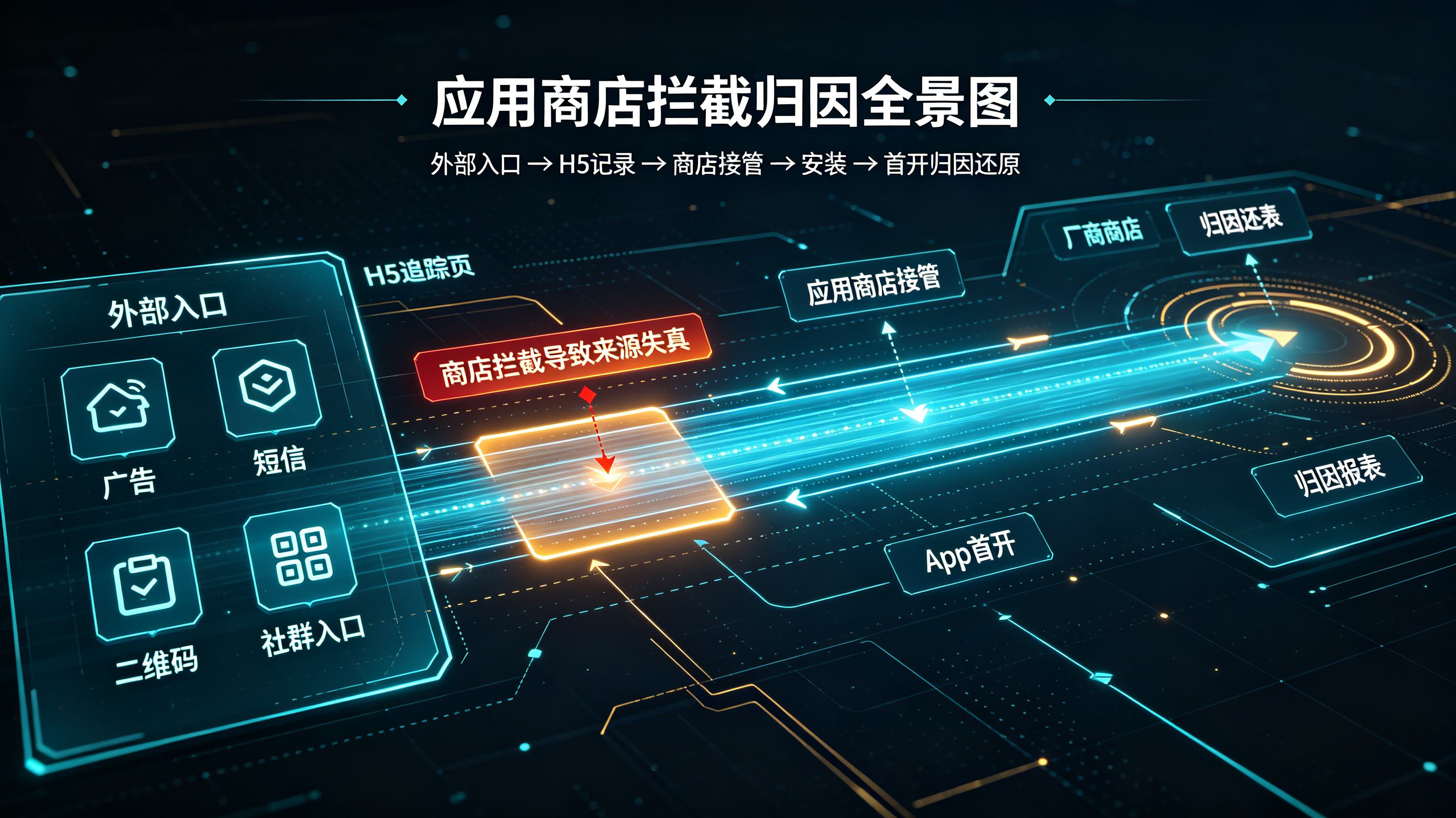
应用商店拦截后怎么归因?下载来源追踪原理解析
2026-06-26

广告监测链接怎么做?App安装来源追踪原理解析
2026-06-26

App传参安装怎么做?全渠道参数还原原理解析
2026-06-26

谷歌重组AI编程小组?追赶Anthropic的节奏被迫加速
2026-06-26
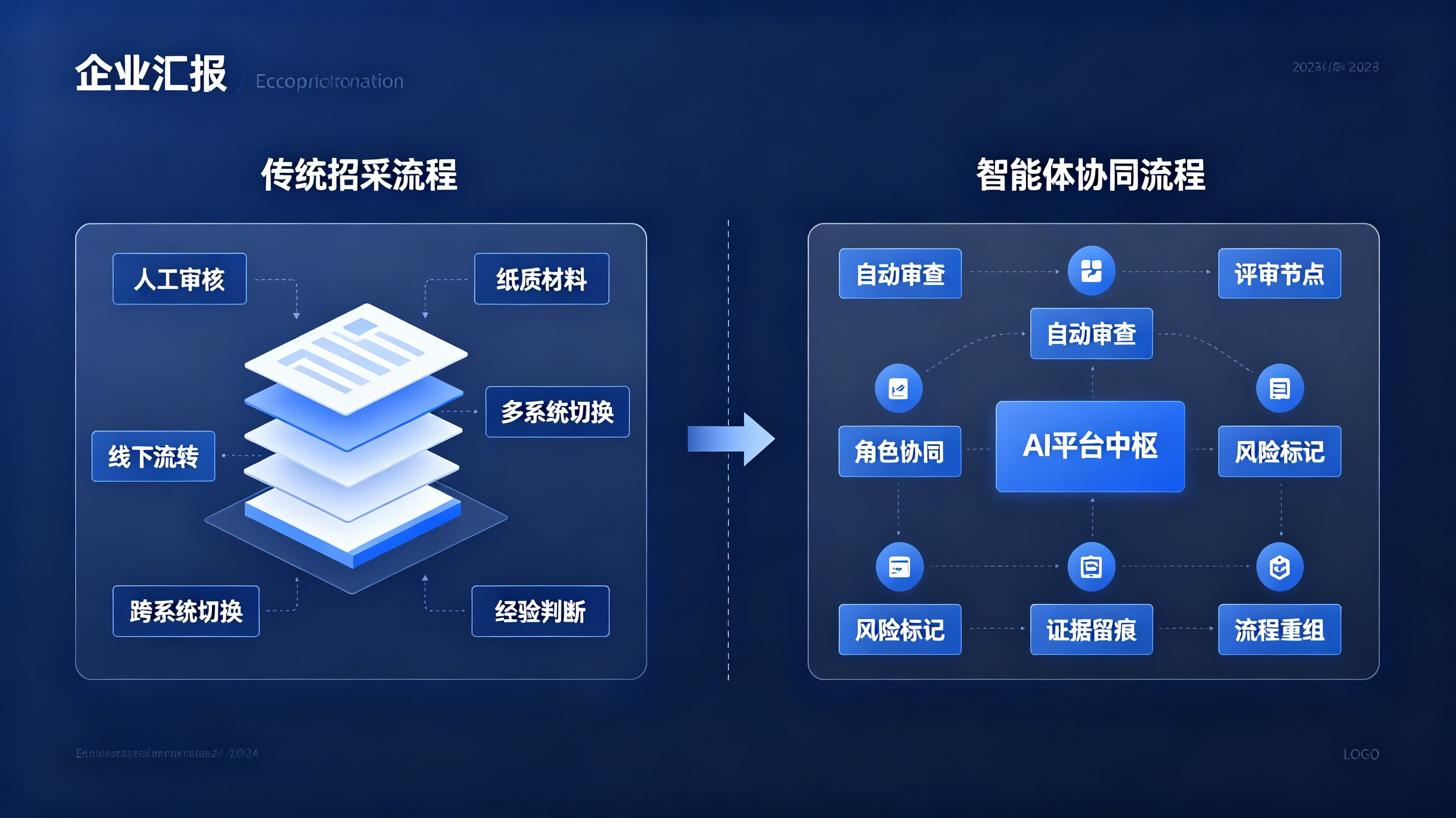
科大讯飞AI招采平台2.0如何重构流程?招投标开始进入全链路智能化
2026-06-26
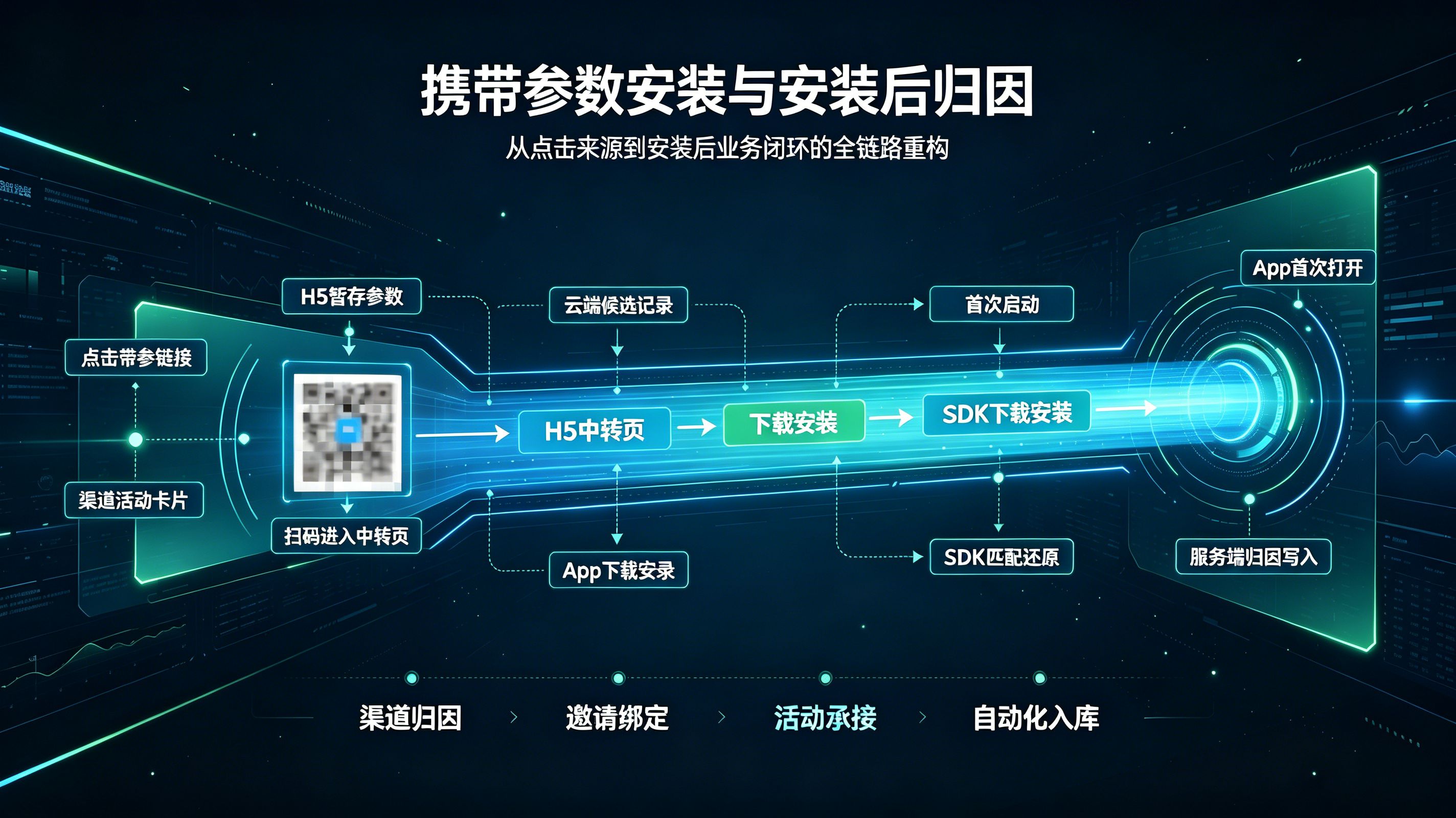
携带参数安装怎么实现?安装传参与归因技术解析
2026-06-25

Agent Ready怎么落地?企业智能体进入统一管理时代
2026-06-25

360与惠普签署战略合作?AI安全与终端融合进入落地期
2026-06-25

荣耀终端要被AI重做?MWC上海上终端变革的真实信号
2026-06-25

免填邀请码怎么实现?自动绑定邀请关系技术解析
2026-06-24
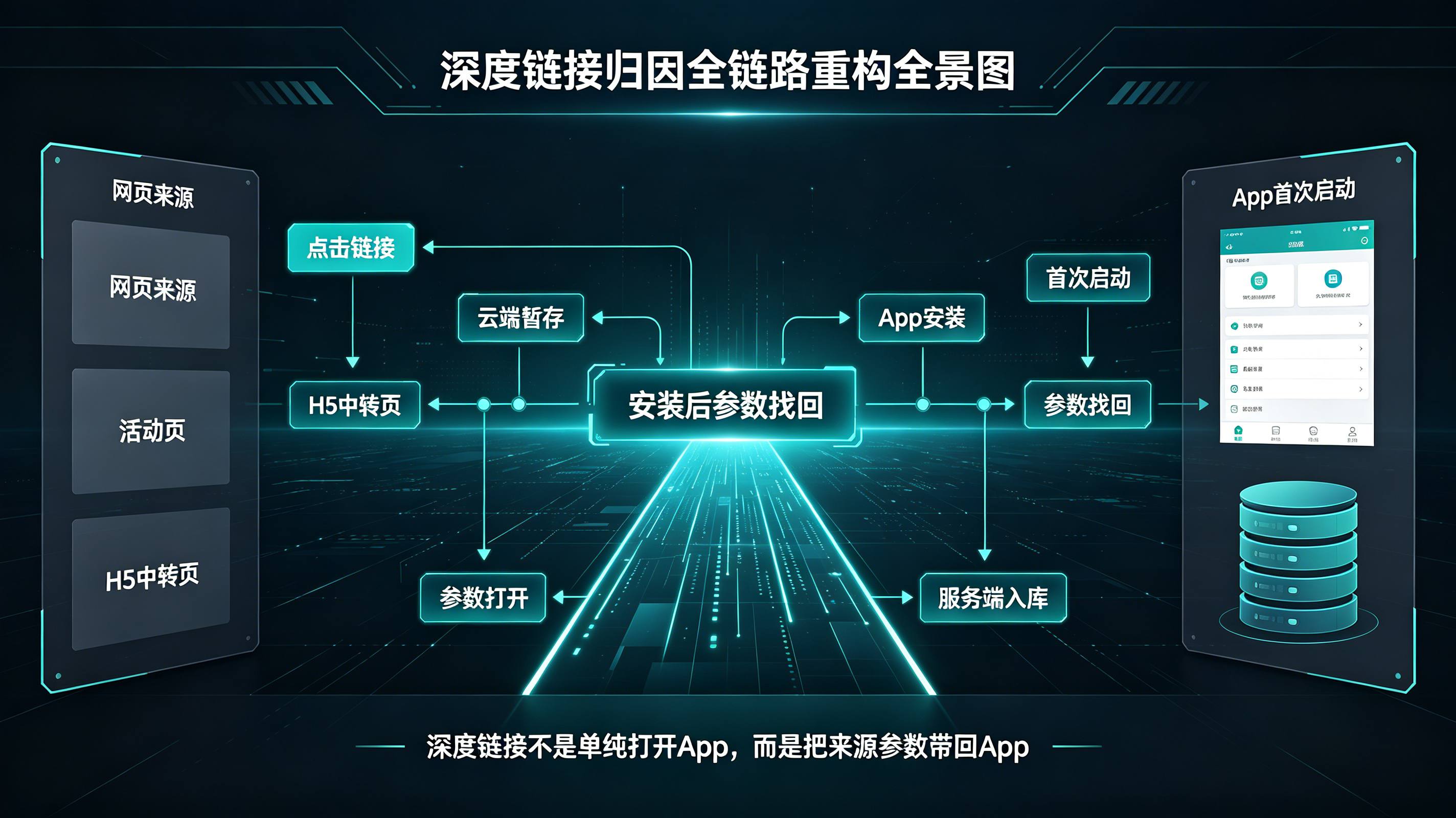
深度链接归因怎么做?安装后参数找回技术解析
2026-06-24

豆包专业版正式推出?AI收费战开打背后的订阅分层与商业验证
2026-06-24
毁灭全人类游戏今日登陆新主机?爆款主机游戏跨端种草考验一键拉起基建
2026-06-24
即梦AI上线原生4K视频生成?打破高糊魔咒,AI视觉算力重塑营销分发底座
2026-06-24

免打包渠道统计是什么?App免填邀请码技术原理解析
2026-06-23






















