






手机微信扫一扫联系客服
联系电话:18046269997



 APP安装免填邀请码
APP安装免填邀请码 社交分享效果统计
社交分享效果统计 广告投放数据统计
广告投放数据统计 CPA/CPS推广效果统计
CPA/CPS推广效果统计 App地推统计
App地推统计 App拉起
App拉起 网页/应用内直接安装
网页/应用内直接安装 Android多渠道打包
Android多渠道打包 App安装后自动绑定
App安装后自动绑定 App分享效果统计
App分享效果统计 Deeplink深度链接
Deeplink深度链接 手机微信扫一扫联系客服
 446
446当钉钉和飞书相继开源CLI,主动将产品能力拆解给AI Agent,标志着应用入口正从“人”转向“智能体”。开发者必须重构底层追踪逻辑,利用专属渠道标识实现多Agent任务流量的可观测性与精准归因。
2026年3月底,中国两家最大的企业协作平台——钉钉和飞书,不约而同地做出了一个极具标志性的动作:相继开源了各自的命令行工具(CLI)。飞书发布了 lark-cli,钉钉上架了 dingtalk-workspace-cli。
这场由当红智能体框架 OpenClaw 爆红引发的“跟风”背后,掩藏着一个巨大的产品逻辑突变:办公软件正在从“人操作”变成“人指挥,AI操作”。 平台正在主动把自己拆解成一条条标准化的积木指令,交给如 Claude Code、Cursor 或 OpenClaw 这类的 AI Agent 去随意拼装和调用。
对于SaaS企业和广大的App开发者而言,这不仅仅是交互方式的改变,更是一场流量底座的地震。当 DAU(日活跃用户数)、停留时长、点击率等传统指标逐渐失效,我们该如何追踪、归因和衡量这些由 AI Agent 发起的“任务流量”?
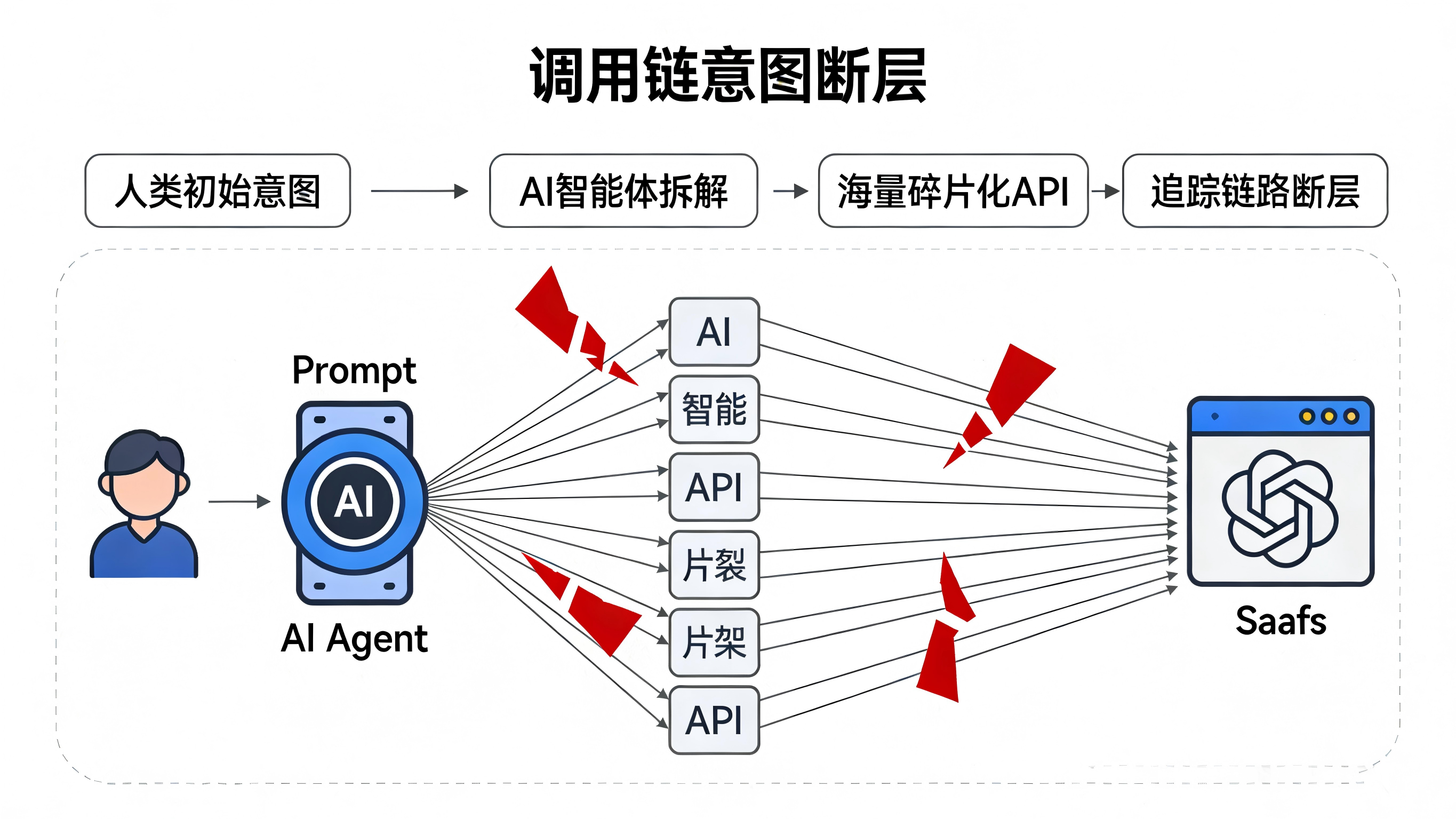 以往,我们要评估一个协作软件的价值,看的是用户每天打开了几次App,建了多少篇文档,发了多少条消息。这就是典型的“界面流量”(人机交互)。
以往,我们要评估一个协作软件的价值,看的是用户每天打开了几次App,建了多少篇文档,发了多少条消息。这就是典型的“界面流量”(人机交互)。
但随着钉钉和飞书将日历、待办、多维表格等核心功能以 CLI 和原生 API 的形式向 AI 工具全面敞开,未来的工作流变成了这样:你在 OpenClaw 的终端里输入一句:“帮我把下周的周报整理成飞书文档,并用钉钉发给主管。” 整个过程你甚至不需要打开飞书和钉钉的App界面。
这意味着,衡量软件平台价值的维度正在悄然被 “Agent调用频次” 所替代。
随之而来的是开发者面临的三大挑战:
注:本文探讨的针对多Agent任务流量归因与渠道参数追踪的技术方案,旨在帮助SaaS及App开发者重构底层的可观测性基建。如果您的团队正面临 API 被频繁调用但来源不清、跨系统协同效果难以衡量等痛点,欢迎联系 Xinstall 客服团队获取专业的渠道归因与智能传参解决方案。
面对不可逆的“机器代人”流量趋势,SaaS 与 App 开发者必须在底层建立一套适应 Agent 调用的全新追踪体系。
分配独立的渠道标识(ChannelCode)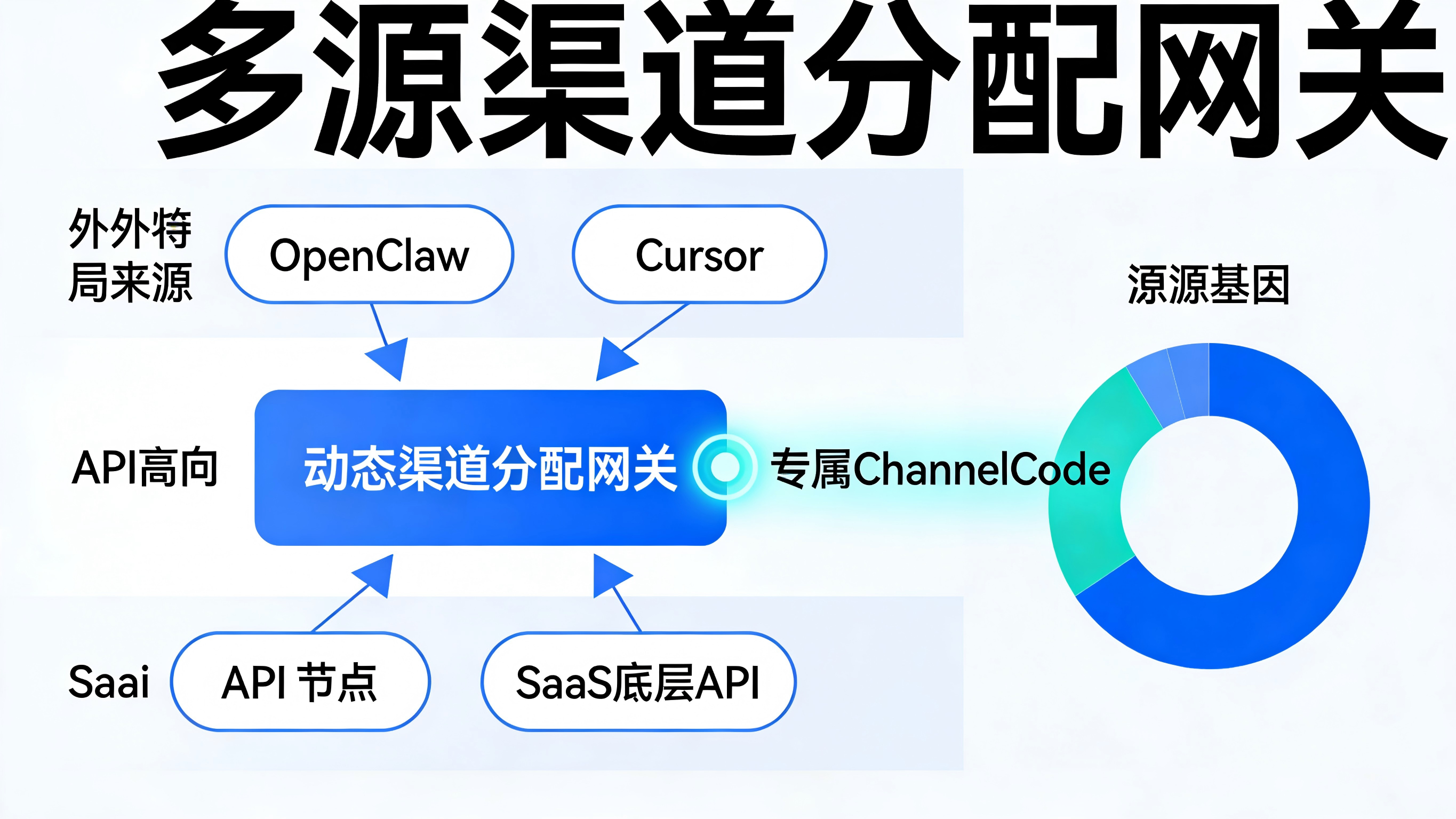
当外部的 AI Agent 成为应用的高频访问者时,不能再用一套通用的 OpenAPI 密钥打天下。
针对不同的智能体接入来源(例如飞书官方插件、个人的 OpenClaw 本地环境、第三方的 Cursor 开发环境),必须利用类似 Xinstall 的底层机制,为其动态生成和分配独立的 ChannelCode(渠道编号)。
通过在每一次 CLI 或 API 调用中强制附带该标识,开发者能在后台的渠道统计面板上清晰地看到:哪些智能体带来的调用是最活跃的?哪个渠道的 AI 任务产生了实际的商业转化(如触发了高级功能的订阅)?
重构基于“任务 ID”的跨链路归因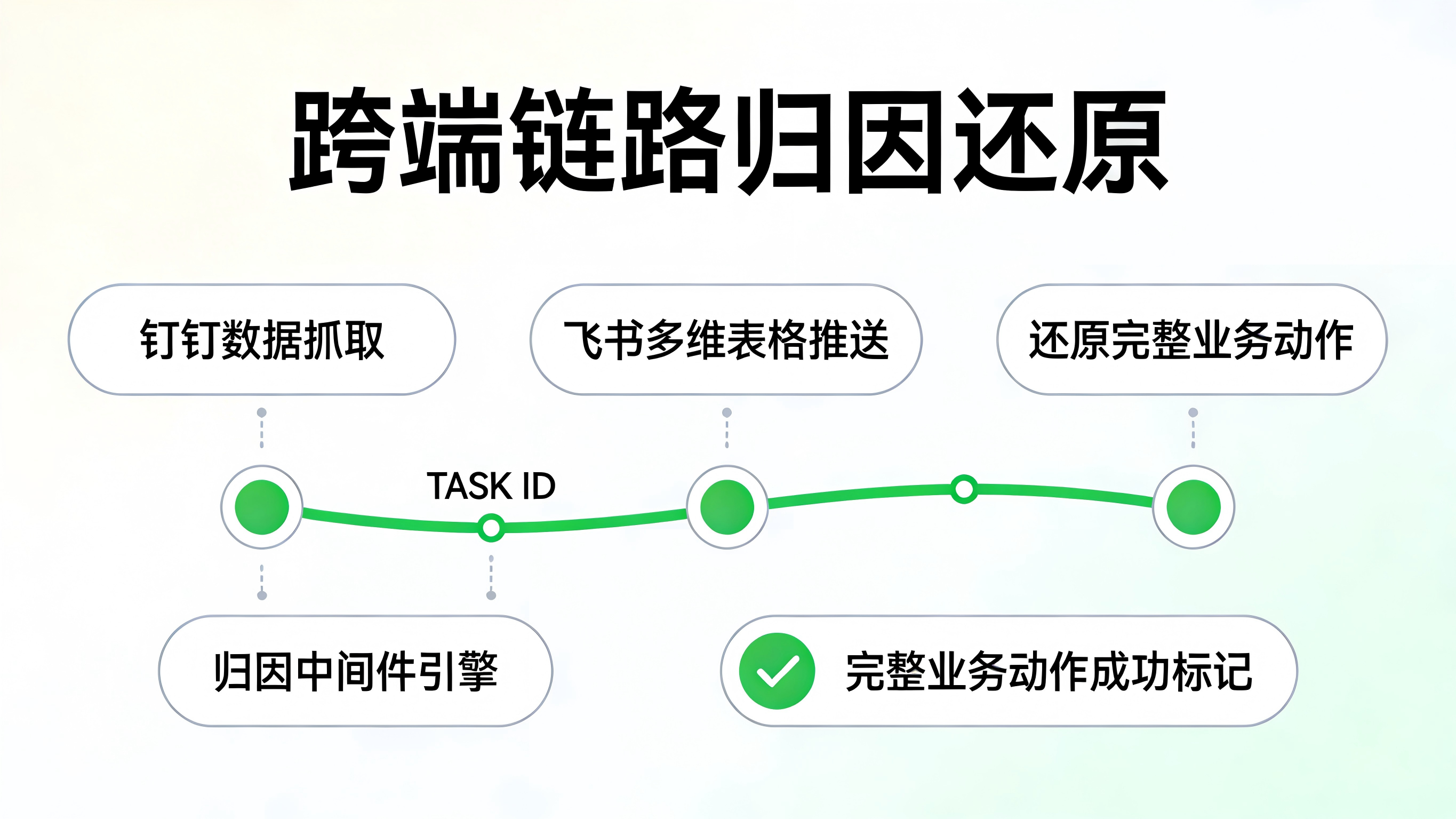
传统的页面归因模型失效了,必须转向基于事件和参数的归因。
在 AI 调用链中,需要将用户的初始意图封装为一个全局唯一的 Task_ID。当 Agent 跨越多个平台(例如从钉钉抓取数据,在本地大模型中处理,最后推送到飞书多维表格)时,利用底层参数传递技术,确保这个 Task_ID 能在不同的沙盒环境和 API 节点中无损流转。
这样,哪怕一次工作流被拆解成了几十条零散的 CLI 指令,数据后台依然能将其还原为一次完整的“业务动作”,从而精准评估该功能的实际转化价值。
建立“人”与“机”分流的异常监控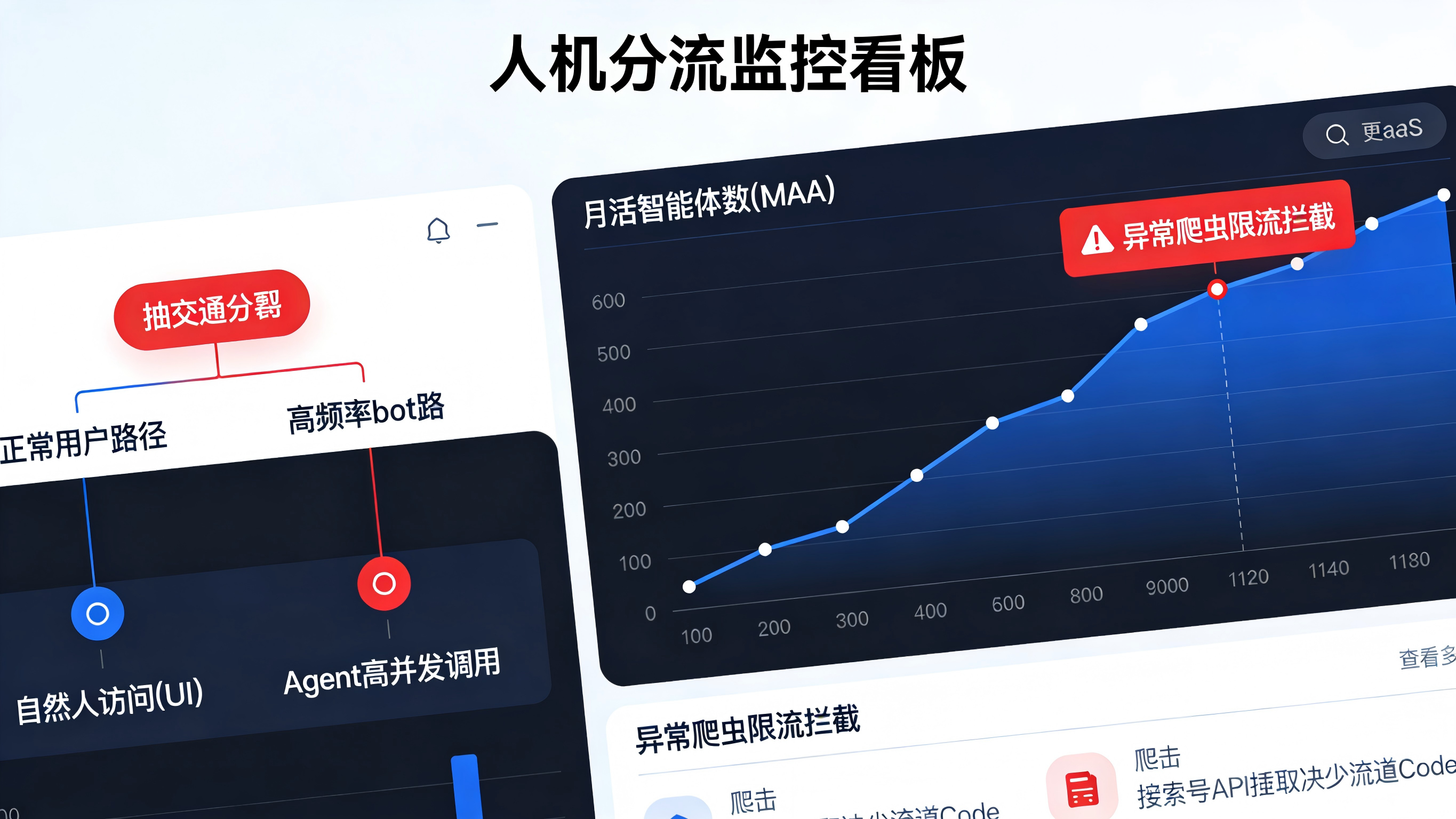
Agent 的执行速度是人类的千万倍,这也放大了风险。在底层埋点与日志系统中,必须增加 is_bot 和 agent_platform 维度,严格区分自然人访问与机器并发调用。
同时,结合精细化的参数识别机制,对于没有携带合法场景参数(或来源渠道不明)的高频 API 请求,进行限流与预警,防止平台资源被无效心跳检测或恶意爬虫耗尽。
面向架构/后端团队:
面向产品/商业化团队:
如果用户的 AI Agent 是部署在本地完全断网的环境下,还能统计到调用吗?
只要该 Agent 最终需要通过网络请求调用 SaaS 平台的 API 接口,服务端就可以在请求头或参数体中捕获其预先分配的渠道标识与任务参数,从而实现云端的归因统计。纯本地化的数据处理则无法追踪。
给大量的第三方智能体分配独立的 ChannelCode,会造成系统的性能负担吗?
不会。专业的渠道服务商(如 Xinstall)拥有极高并发的处理能力,其生成的动态 ChannelCode 非常轻量,且通过高效的云端索引机制进行匹配,完全能够支撑百万级以上的并发验证与数据上报,不会拖慢原本的业务接口响应速度。
如何防止渠道标识被恶意脚本盗用并伪造虚假流量?
现代的追踪技术不仅依赖单一的 ID 字符串,还会结合多维度的请求特征指纹、时间戳验证以及行为轨迹分析,能够有效识别并过滤掉那些异常的、非合理业务逻辑下的机器群刷行为。
飞书和钉钉开源 CLI 只是一个开始。随着大模型能力的下探和执行层插件的爆发,越来越多的应用会被“拆解”成能力组件。未来的互联网不再是“App 的孤岛”,而是“API 的海洋”。
在这个新时代,谁能够看清这些在暗处流动的“任务流量”,谁能精准评估每一个智能体带来的真实价值,谁就能在 AI 重新分配红利的浪潮中抢占先机。而这一切的前提,是拥有一个强大的底层参数追踪与全渠道归因底座。
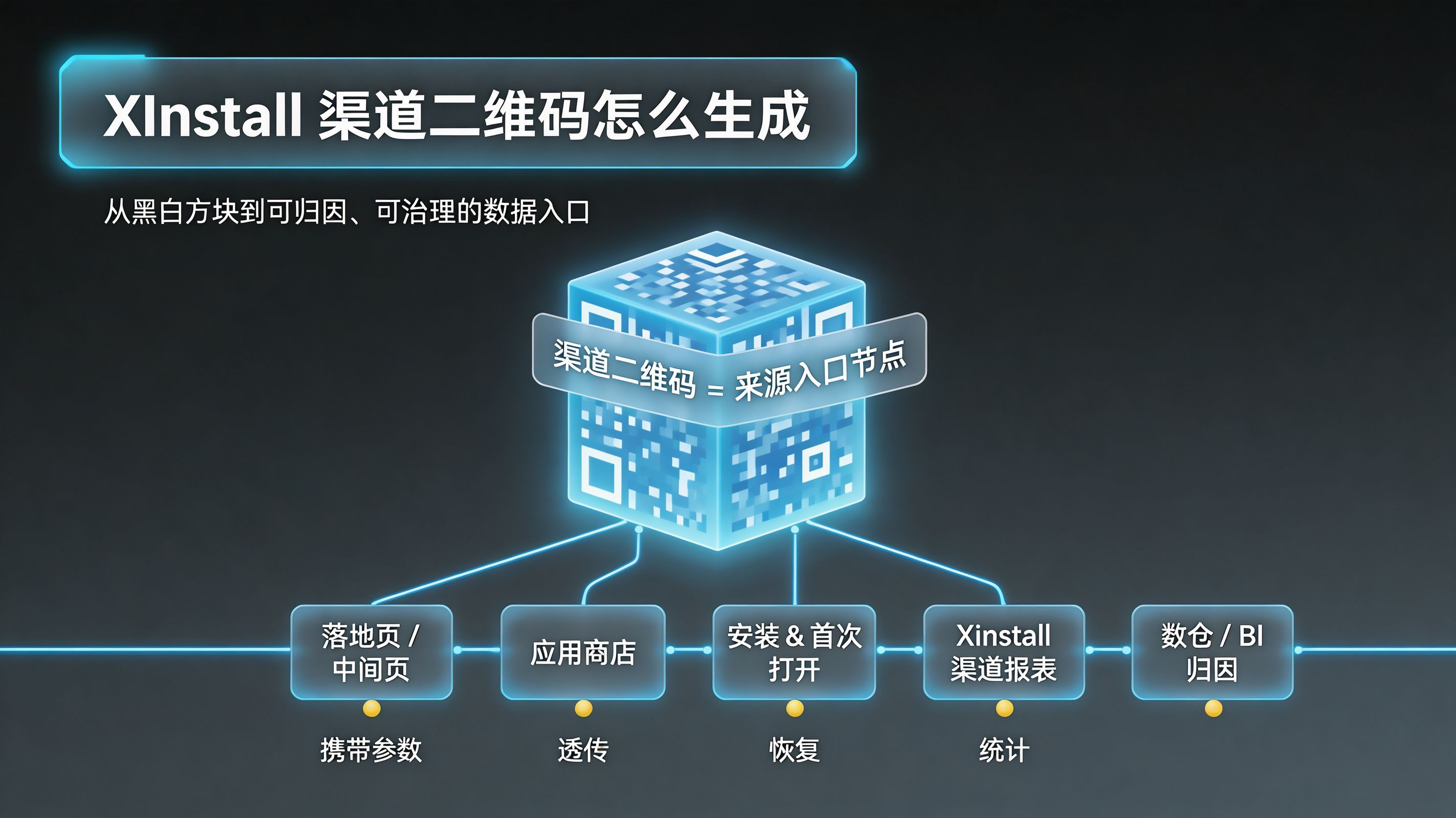
Xinstall 渠道二维码怎么生成?扫码统计与归因规则
2026-07-17
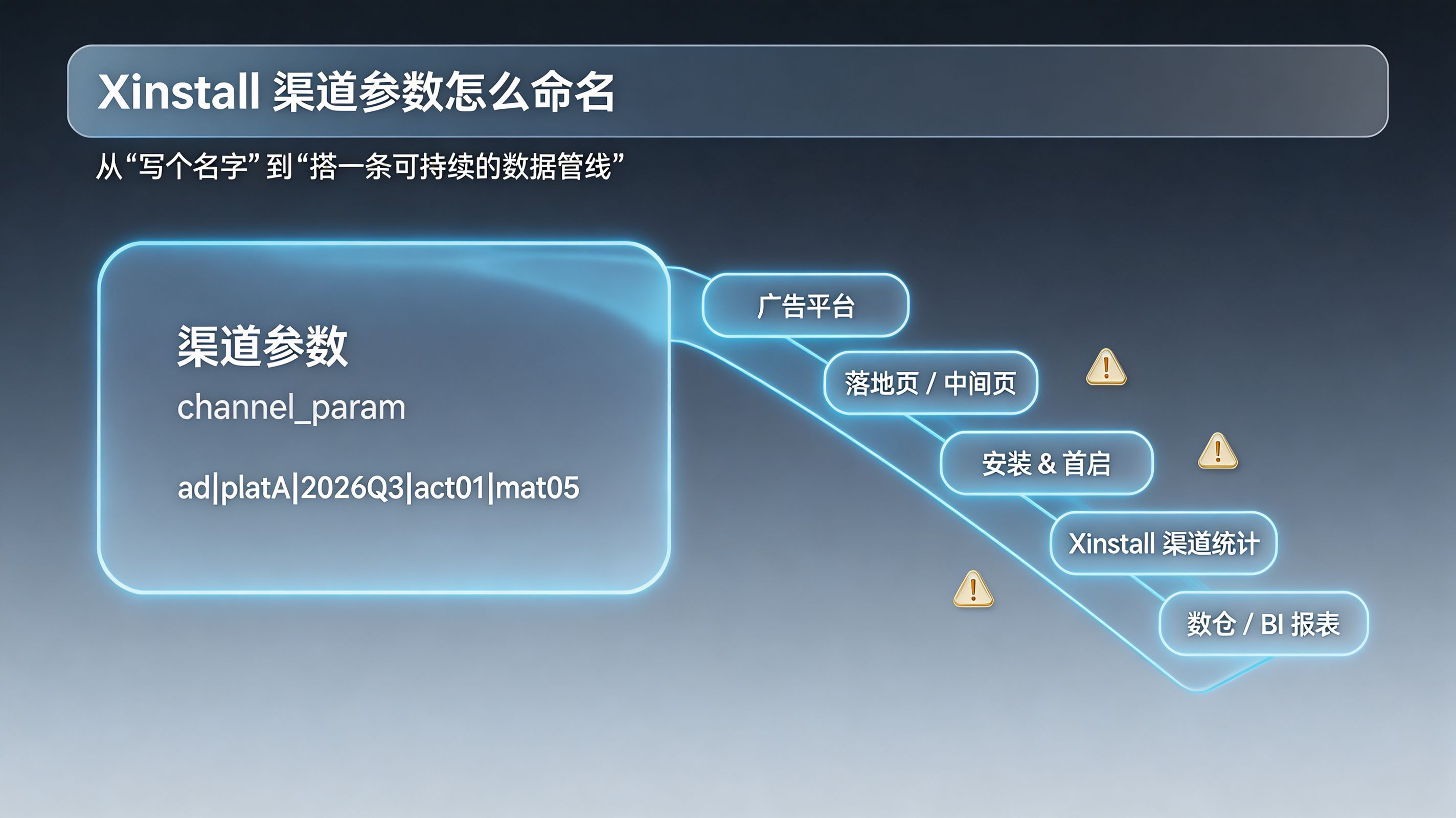
Xinstall 渠道参数怎么命名?渠道字典与治理规则
2026-07-17

Xinstall 报表和内部 BI 对不上怎么办?数据一致性排查与治理
2026-07-17

AI产业高地如何重塑任务入口?开发者与增长团队不能错过的上海样本
2026-07-17

小红书HYPIC大幅降低首token延迟?混合注意力大模型的缓存革命
2026-07-17

Xinstall 全渠道统计怎么滚动迭代?项目管理与版本升级策略
2026-07-16

Xinstall 数据团队怎么配合?全渠道统计落地流程拆解
2026-07-16

努比亚NaviX Ultra首款智能体手机亮相?AI手机正在把入口从应用图标挪到常驻助手
2026-07-16

手游买量异常流量怎么排查?高风险渠道诊断与对账
2026-07-15

金融 App 用户追踪怎么实现?高安全性归因统计
2026-07-15

电商 App 推广统计方案有哪些?全链路下单追踪
2026-07-15

Bonsai 27B首款可在手机运行?端侧多模态大模型正在把智能体入口从云端控制台迁移到用户手里的手机屏幕
2026-07-15

GPT-5.6 Sol自行删除用户文件?智能体越权行为正把分发统计推向高风险区
2026-07-15

小米机器人进厂实习会重塑物理分发吗?具身智能正将应用拉起场景延伸至线下流水线
2026-07-14

Grok Build静默上传代码会引爆信任危机吗?大模型越权正倒逼应用渠道合规升级
2026-07-14






















