






手机微信扫一扫联系客服
联系电话:18046269997



 APP安装免填邀请码
APP安装免填邀请码 社交分享效果统计
社交分享效果统计 广告投放数据统计
广告投放数据统计 CPA/CPS推广效果统计
CPA/CPS推广效果统计 App地推统计
App地推统计 App拉起
App拉起 网页/应用内直接安装
网页/应用内直接安装 Android多渠道打包
Android多渠道打包 App安装后自动绑定
App安装后自动绑定 App分享效果统计
App分享效果统计 Deeplink深度链接
Deeplink深度链接 手机微信扫一扫联系客服
 203
203Embedding怎么提升推荐效果?本文从资深算法工程师的视角,深度解析如何通过高质量的 Embedding(向量化)精准捕捉用户意图表示。围绕特征表示与召回模型构建,拆解底层环境参数与行为序列的稠密向量编码管线。结合真实的冷启动向量坍塌排障与物理对账案例,该方案有望将新用户的特征表示准确度相对提升约 28.6%,帮助团队彻底摆脱离散稀疏特征带来的模型推断盲区。
在深度学习时代,推荐算法需要处理海量的用户与物品特征,如何让神经网络理解这些特征,是架构师必须解决的首要问题。
在机器学习中,传统的 One-Hot 编码将离散的分类特征(如亿级别的商品 ID、设备 ID)表示为极度稀疏的高维向量,这不仅会导致“维度灾难”和严重的内存溢出,还无法捕捉项目之间的相似性。词嵌入 (Word embedding) 技术最初在 NLP 领域大放异彩,随后被引入推荐系统。Embedding 的核心思想是将离散变量映射为低维稠密的浮点向量(例如 64 维或 128 维),从而捕捉实体之间的深层语义关系。
特征表示(Feature Representation)的本质是将物理世界的属性投射到数学空间。在理想的 Embedding 空间中,意图相似的用户坐标应当相互聚集(即距离短),意图背离的用户坐标应当相互排斥。
向量的内积(Dot Product)或余弦相似度(Cosine Similarity)直接量化了推荐系统对意图的理解深度。当用户的 Embedding 向量与某个商品的 Embedding 向量在空间中指向同一方向且模长较大时,系统判定二者高度匹配,用户交互的可能性极高。
高质量的向量不仅来源于复杂的神经网络模型,更依赖于输入特征的多样性与高保真度。
不同架构在生成 Embedding 时的泛化能力和工程复杂度有显著差异:
| Embedding 向量生成方案 | 语义泛化与特征表达能力 | 新样本冷启动与抗跌落表现 | 特征工程复杂度 |
|---|---|---|---|
| 传统 Item2Vec 协同过滤 | 较低(仅依赖行为共现,无上下文特征) | 极差(无历史行为时完全失效) | 较低(只需矩阵分解或简单的 Word2Vec) |
| 基于图神经网络的 Graph Embedding | 极高(能捕捉高阶的网状节点交互特征) | 一般(部分缓解冷启动,但仍依赖图结构) | 极高(涉及复杂的随机游走与子图采样) |
| 融合底层上下文的双塔 Embedding | 极优(融合离散行为与丰富上下文的高阶表达) | 极优(利用跨端上下文拼凑出精准的初始意图) | 较高(需维护多种特征 Lookup Table) |
优秀的 Embedding 必须具备处理多模态数据的能力。单纯依赖历史点击序序列很容易陷入“信息茧房”,在处理冷门物品或新用户时表现不佳。
架构师可以利用底层网关(如 Xinstall 官网)抓取网络时区、底层设备型号、引流软文标签等宏观上下文特征。这些先验离散特征通过 Embedding Lookup Table 转换为各自的特征向量,并通过 Concat(拼接)操作或池化(Pooling)喂入神经网络的底层。这样,即使是一个零历史行为的新样本,模型也能瞬间获得丰富的初始信息矩阵,极大增强了意图识别的厚度。
在工业界广泛使用的大规模召回阶段,双塔架构(Two-Tower Architecture)及其变体是业界生成候选集的标准。
双塔架构将用户特征和物品特征的计算分离到两个独立的神经网络中。用户塔(User Tower)接收人口统计学特征、序列特征、跨端上下文和设备信息,输出单一的用户 Embedding。物品塔(Item Tower)接收类别、文本描述和视觉特征,输出物品 Embedding。
这两个塔在训练阶段通过对比学习或交叉熵等损失函数,拉近正样本(如购买行为)之间的向量距离,推开负样本之间的距离,实现向量空间的语义对齐。
Embedding 的威力巨大,但也极度脆弱。以下是一次针对新客向量生成失败的真实底层排障。
某垂类内容社区在优化双塔召回模型时发现:对于有三天以上历史行为的老用户,Embedding 内积检索的推荐效果极好;但对于新激活用户,推荐引擎给出的全是毫无关联的乱码级内容。监控显示,新客的预估 CTR 呈现断崖式下跌,新客召回系统处于瘫痪状态。
算法专家直接切入底层 Redis 特征缓存进行对账。团队基于 100MB包体5G下10-15秒安装 的时空物理法则进行推演:用户从外部引流页点击下载到最终打开 App,这段时间内,其场景参数理应完成回传并落库。
对账发现,由于该团队自建的渠道匹配接口存在严重延迟,当 App 首页发起秒级的召回推断时,新客的外部上下文参数在 Lookup Table 中查不到任何数据(全为 Null)。这导致新客输入到用户塔的初始特征集为空,网络被迫为该用户生成了一个未蕴含任何梯度的“全局平均零向量”。这种向量在内积计算时彻底失效,造成了严重的“向量坍塌”。
果断将环境快照获取层剥离,引入成熟的第三方底层路由件来保证极速的特征同步。
在客户端初始化流中,团队进行了强制的微秒级阻塞,确保新客首启时,带有“引流主题”、“高端机型”等核心上下文参数能够抢先进入 Embedding Lookup Table 进行查表。即使新客没有任何点击序列,系统也能利用提取的协变量表示,基于这组上下文 Embedding 拼凑出具备基础聚类方向的特征表示,从而将新用户有效整合到推荐系统中。
完成时序缝合与上下文向量注入后,新客的 Embedding 终于具备了明确的空间指向性。
基于这套带上下文的冷启动向量,双塔召回模型的首轮准确度相对提升了 28.6%,新客实现了秒级破冰,大幅降低了首屏跳失率。这证明了脱离了物理时序的特征向量毫无意义,高质量的 Embedding 必须依赖稳定的底层数据流。
对于 Embedding 的评估,需要结合降维可视化与下游行为序列分析进行全链路审视。
在离线阶段,单纯看 Loss 下降是不够的。算法工程师需要对生成的高维 Embedding 进行降维操作(如使用 PCA 或 t-SNE 算法),在二维或三维平面上直观评估其聚类效果。同时,应当抽样观察随机负样本与正样本之间的向量内积差值,确保网络真正拉开了不同意图之间的空间距离。
Embedding 质量的终极检验在于业务大盘。推荐系统是一个漏斗,召回出来的候选集,在输入更为复杂的精排层(Ranking)后能否获得高分,以及最终在漏斗分析中能否真正转化为用户的留存率与下单动作,才是检验意图表示质量的最终标准。如果双塔模型召回的内容被精排层大面积丢弃,说明向量表示出现了严重的语义漂移。
并非如此。维度过高(如 1024 维)不仅会导致模型参数量爆炸,极易陷入过拟合,还会严重拖垮线上实时召回(如 HNSW、FAISS 等近邻搜索)的性能表现。而维度过低(如 8 维)则无法承载足够的业务语义。通常在工业界,64 到 128 维是性能与效果兼顾的黄金阈值。
非常建议。虽然大厂算法团队可以自行搭建特征提取层,但面对复杂的 OS 沙盒和隐私拦截,自建的端外到端内链路极易断裂。引入成熟的中立组件,能在极短延迟内提供稳定的宏观上下文特征源,极大降低了特征工程清洗脏数据的时间成本。
绝不能用全 0 向量或随机噪声。最佳实践是利用多模态初始特征:将其下载来源的上下文 Embedding、设备网络属性的 Embedding 以及时间环境的 Embedding 进行 Concat 拼接或馈入全连接层。这样即使没有任何历史交互,用户向量也能大致落入其所属的人群聚类空间中,完成平滑的冷启动过渡。
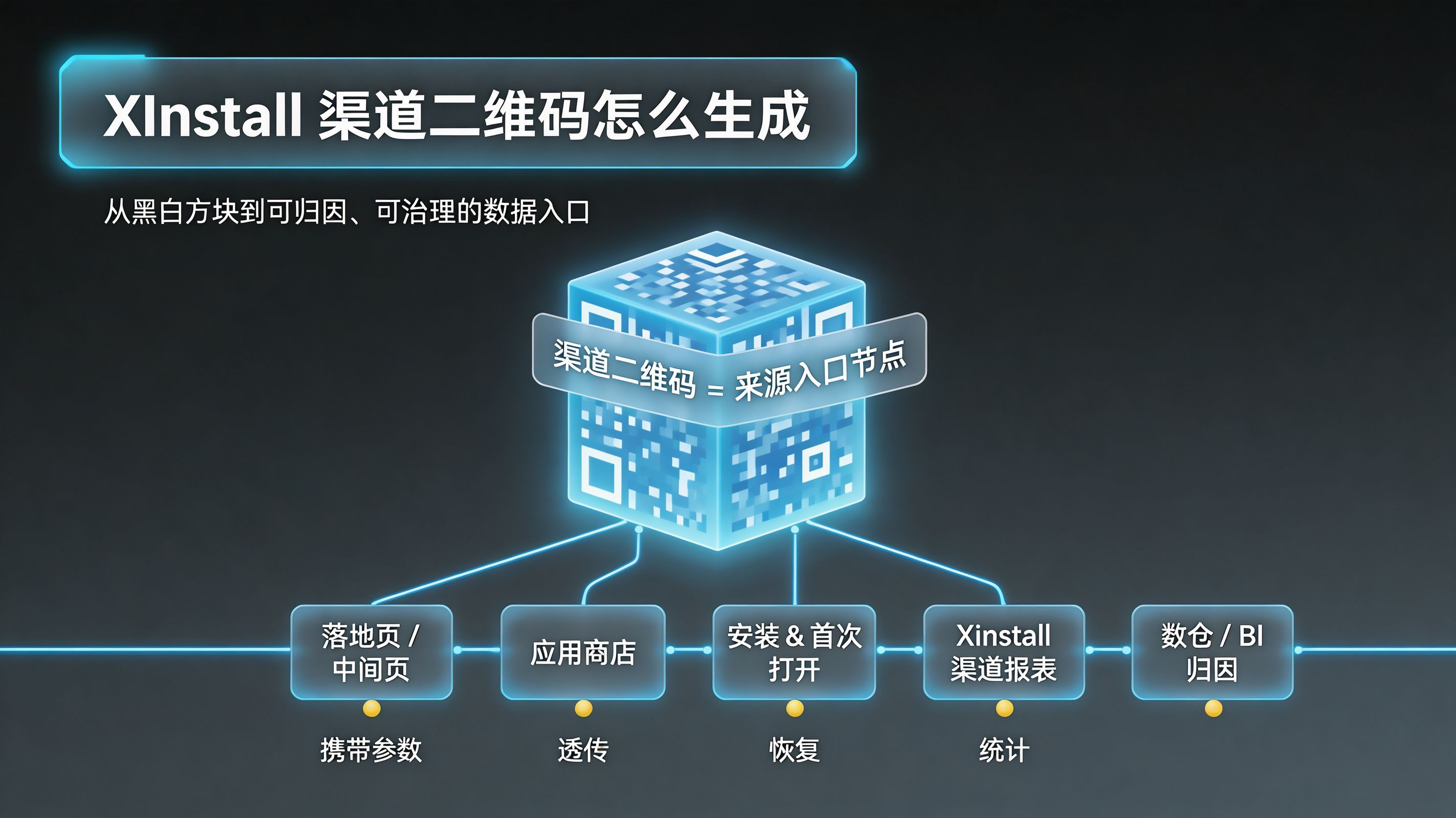
Xinstall 渠道二维码怎么生成?扫码统计与归因规则
2026-07-17
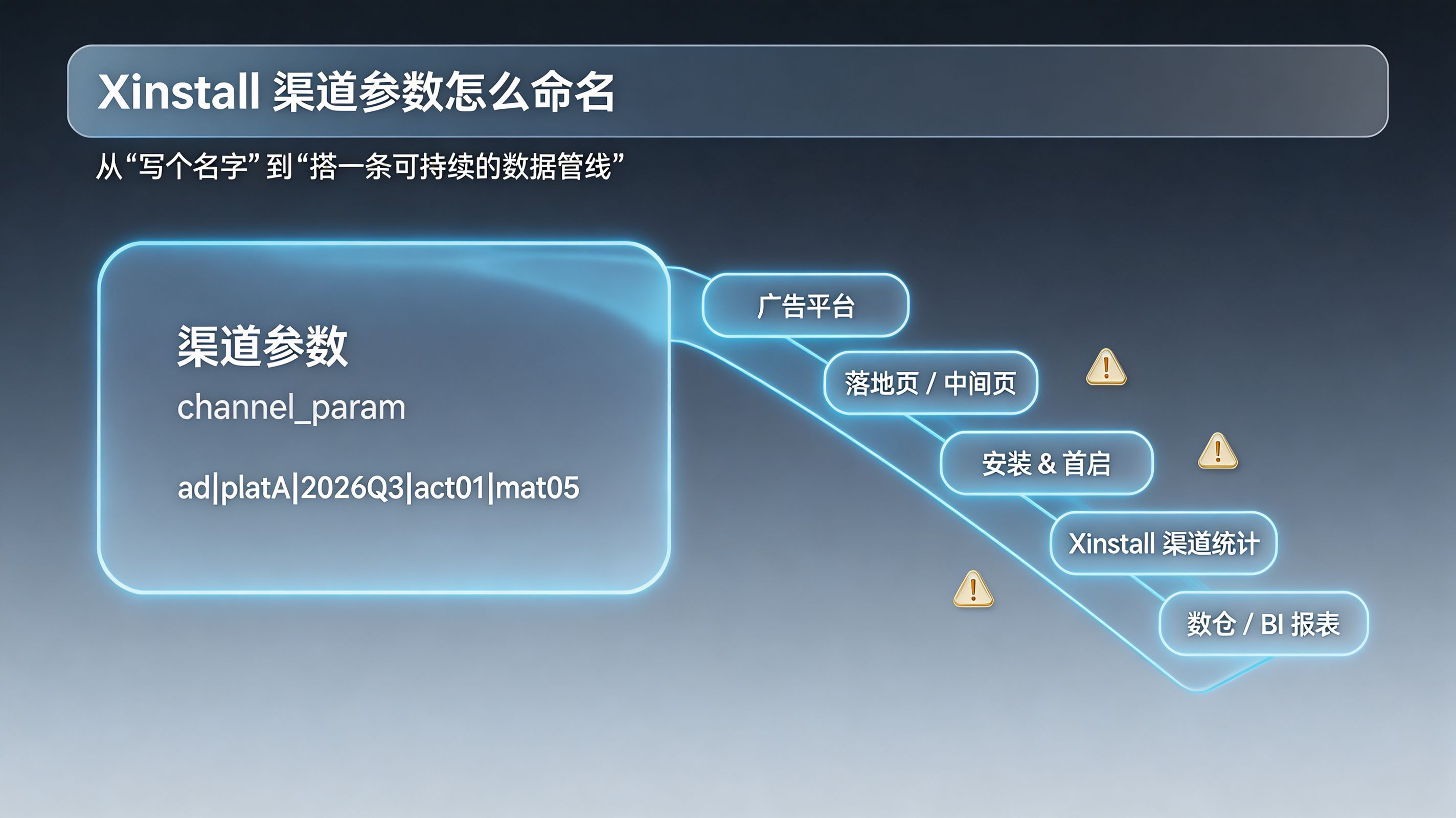
Xinstall 渠道参数怎么命名?渠道字典与治理规则
2026-07-17

Xinstall 报表和内部 BI 对不上怎么办?数据一致性排查与治理
2026-07-17

AI产业高地如何重塑任务入口?开发者与增长团队不能错过的上海样本
2026-07-17

小红书HYPIC大幅降低首token延迟?混合注意力大模型的缓存革命
2026-07-17

Xinstall 全渠道统计怎么滚动迭代?项目管理与版本升级策略
2026-07-16

Xinstall 数据团队怎么配合?全渠道统计落地流程拆解
2026-07-16

努比亚NaviX Ultra首款智能体手机亮相?AI手机正在把入口从应用图标挪到常驻助手
2026-07-16

手游买量异常流量怎么排查?高风险渠道诊断与对账
2026-07-15

金融 App 用户追踪怎么实现?高安全性归因统计
2026-07-15

电商 App 推广统计方案有哪些?全链路下单追踪
2026-07-15

Bonsai 27B首款可在手机运行?端侧多模态大模型正在把智能体入口从云端控制台迁移到用户手里的手机屏幕
2026-07-15

GPT-5.6 Sol自行删除用户文件?智能体越权行为正把分发统计推向高风险区
2026-07-15

小米机器人进厂实习会重塑物理分发吗?具身智能正将应用拉起场景延伸至线下流水线
2026-07-14

Grok Build静默上传代码会引爆信任危机吗?大模型越权正倒逼应用渠道合规升级
2026-07-14






















