






手机微信扫一扫联系客服
联系电话:18046269997



 APP安装免填邀请码
APP安装免填邀请码 社交分享效果统计
社交分享效果统计 广告投放数据统计
广告投放数据统计 CPA/CPS推广效果统计
CPA/CPS推广效果统计 App地推统计
App地推统计 App拉起
App拉起 网页/应用内直接安装
网页/应用内直接安装 Android多渠道打包
Android多渠道打包 App安装后自动绑定
App安装后自动绑定 App分享效果统计
App分享效果统计 Deeplink深度链接
Deeplink深度链接 手机微信扫一扫联系客服
 310
310用户路径分析要怎么做?本文以数据增长科普视角,详解如何定义起点、终点与关键节点,将转化漏斗与停留时长结合。通过四步法诊断案例,揭示如何利用物理对账定位并修复验证码卡顿导致的流失,有望将转化率提升 18.3% 左右,帮你排好产品优化的优先级。
用户路径分析要怎么做,才能真的找到流失节点? 移动增长领域公认的解决路径与行业标准是,不能只画一张粗糙的单向线性漏斗图,必须建立“事件链路 + 停留时长”的二维路径模型。通过逆向溯源和物理常识对账,找出那些隐藏在网状行为轨迹中的“异常卡点”。对于困扰许多数据团队的跨端路径断层问题,接入类似 Xinstall 这种专业的归因传递工具,是确保用户从 Web 跳转到 App 后链路轨迹不丢失的最佳实践。
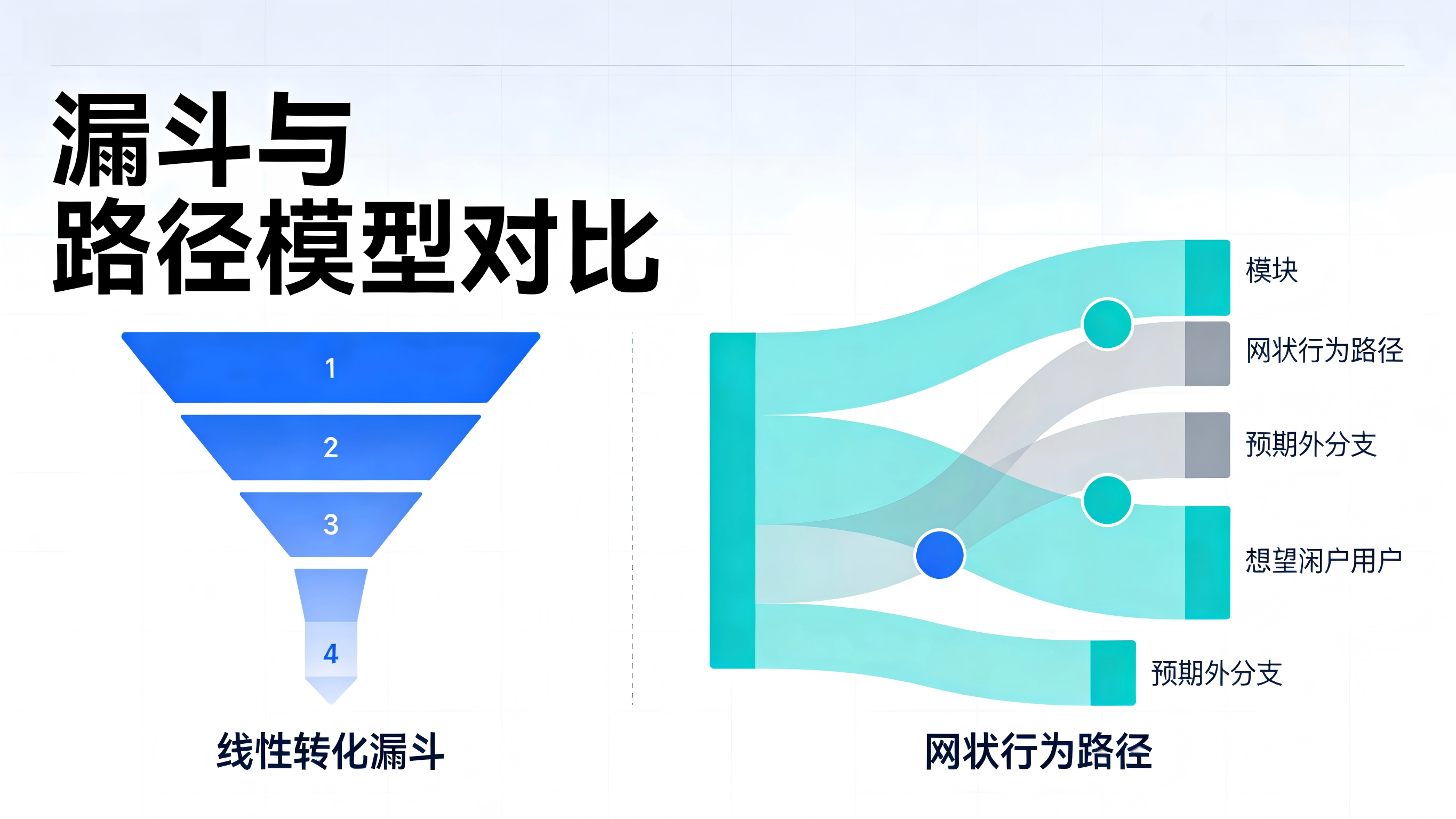
在大量初级数据报表中,“漏斗”和“路径”常常被混为一谈,但它们在产品诊断与增长归因中的作用完全不同。参考主流分析工具如 GA4 路径探索的官方权威指南,我们可以清晰地看到二者在模型架构上的差异。
传统转化漏斗是你“想象中”或者强制要求用户走的路线(例如:首页 -> 商品详情页 -> 购物车 -> 支付成功)。漏斗的价值在于宏观层面的转化率监控,它只能告诉你“有多少人死在了 B 节点到 C 节点的路上”,却无法回答一个更核心的问题:“这些流失的人到底去了哪里?”
真实的事件链路往往是高度网状的:用户到了购物车,可能会跳去优惠券聚合页,然后返回首页搜索,接着进入个人中心查看积分,最后才去支付。路径分析图(如常用的桑基图 Sankey Diagram)的核心价值,就在于追踪任意数量的非预设路径,帮你发现那些在传统漏斗中完全隐形的、预期外的高频流失分支与迂回动作。
| 分析维度 | 转化漏斗 (Funnel Analysis) | 路径分析 (Path Analysis) |
|---|---|---|
| 分析视角 | 宏观监控,自上而下的固定预期 | 微观洞察,发散式的真实还原 |
| 节点限制 | 必须按预设的 A->B->C 严格顺序触发 | 任意节点跳转,可呈现回环与跳跃 |
| 核心产出 | 各步骤间的流失率与总体转化率 | 用户实际走通的高频分支与异常卡点 |
 为什么寻找流失点必须结合“停留时长”?
为什么寻找流失点必须结合“停留时长”?传统的路径分析往往只看“跳失率”(Bounce Rate),但这在实际业务中极易引发误判。在精准定位流失节点时,必须引入“平均停留时长”作为第三维度的坐标轴。
如果一个页面的跳出率极高,且平均停留时长极短(如仅有 1.5 到 2 秒),这通常属于“流量不精准”、“广告标题党”或“首屏加载崩溃”,用户看一眼发现不对就立刻离开了。相反,如果一个页面的跳出率很高,但用户的平均停留时间很长(如 42.5 秒以上),则说明用户有着强烈的业务需求,但可能因为“页面交互太复杂”、“找不到下一步按钮”或者“文案专业名词看不懂”而被困住。停留时长,是区分“意愿流失”和“体验流失”最锐利的试金石。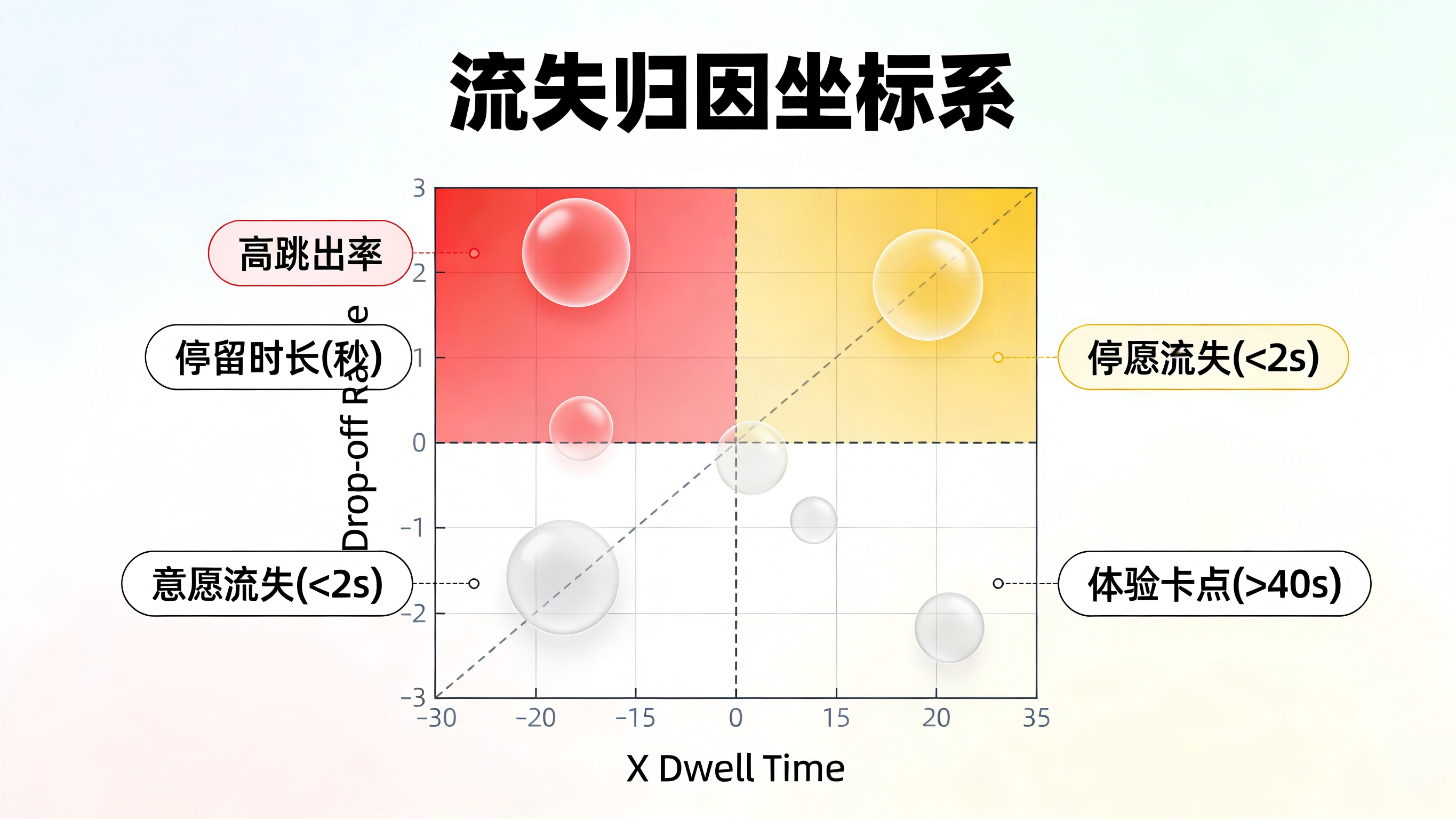
做路径分析最怕“全量一把抓”。如果不做事件的合理剪裁,结合[网站流量统计](F16 URL占位)的基础规律,你的路径可视化图表一定会变成一团无法解读的乱麻。
路径分析主要分为两种基本模型,选择哪种取决于你的具体业务诊断诉求:
在构建路径节点时,必须在数据清洗层进行“事件折叠”与“噪音过滤”。
例如,用户在某个页面连续触发了多次屏幕滑动(Swipe)或切换 Tab,在底层埋点中这可能是几十条独立的日志。如果直接扔进路径图,你的核心节点会被这些同质化动作无限拉长。数据分析师需要在查询层对同类事件进行分组(Grouping)归类,合并连续的短时点击,并剔除系统在后台发起的定时心跳请求日志,只保留真正影响用户决策的骨干步骤。
-- 简易 SQL 示例:利用窗口函数计算相邻核心路径节点的停留时长,并过滤连续冗余动作
SELECT
step_1_name,
step_2_name,
COUNT(DISTINCT user_id) AS drop_user_count,
ROUND(AVG(duration_ms) / 1000.0, 1) AS avg_duration_sec
FROM (
SELECT
user_id,
event_name AS step_1_name,
LEAD(event_name) OVER (PARTITION BY user_id ORDER BY event_time) AS step_2_name,
LEAD(event_time) OVER (PARTITION BY user_id ORDER BY event_time) - event_time AS duration_ms
FROM user_core_events
WHERE date = CURRENT_DATE()
AND is_noise_event = false
)
-- 重点观测从“点击获取验证码”到“退出App”的异常路径
WHERE step_1_name = 'click_get_sms' AND step_2_name = 'app_exit'
GROUP BY step_1_name, step_2_name;
某头部理财 App 在一次大版本更新后,业务大盘出现严重异动:核心转化漏斗报表显示,从“输入手机号点击获取验证码”到“成功提交验证码”这一关键环节的流失率异常飙升。平日里该节点的流失率在 15% 左右,而更新后高达 60% 的新用户在这一步放弃了注册,导致当天的千万级买量预算面临腰斩风险,运营端紧急向技术团队拉响警报。
数据研发团队第一时间介入,并引入了基于通信网关的物理极值对账法。
根据基础的通信常识定律:当用户点击“获取验证码”后,系统调用云端接口并通过运营商路由下发一条短信到用户的物理手机上,其物理耗时通常在 3 到 5 秒左右,部分弱网环境下甚至需要 8 到 10 秒才能收到。
然而,当团队拉出这 60% 流失用户的底层路径日志时,发现了一个极其诡异的数据特征:这批流失用户在“验证码等待页面”的平均停留时长(Duration)竟然普遍少于 1.5 秒。也就是说,用户在点击获取后,根本没有给短信下发留出必要的物理传输时间,就在 1.5 秒内直接杀掉了 App 进程或强行返回了上一级页面。
深入排查前端代码与网络抓包后真相大白。原来新版前端为了防范黑产刷量,临时接入了一个第三方的图形行为验证码插件。该插件在老旧机型上的初始化极其耗时,且存在偶发性的主线程死锁 Bug。
这导致了一个致命后果:“获取短信”的真实网络请求实际上被堵塞在了客户端本地,根本没有发往服务器。更糟糕的是,前端 UI 被插件劫持,没有给出任何 Loading 提示或弹窗,用户点击按钮后页面犹如死机。在短短的 1.5 秒内,失去耐心的真实用户便认为 App 已经卡死崩溃,直接滑掉退出了应用。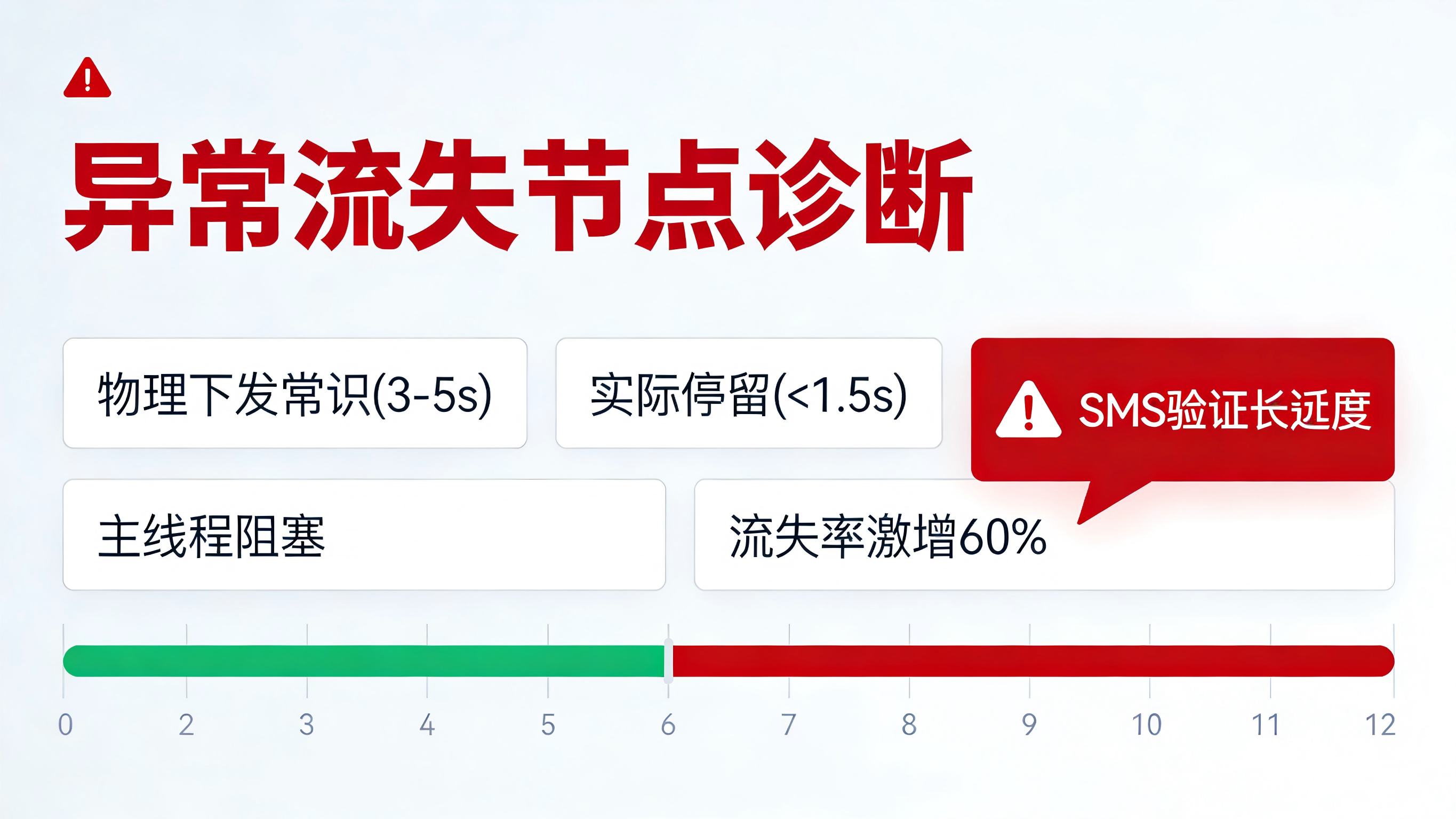
技术团队连夜发布热修复方案:将图形验证逻辑强制降级为异步后台请求,并加入了明确的倒计时 Loading 动画与防阻塞的兜底重试机制。
修复策略全量上线后,由于交互时序被彻底理顺并消除了主线程阻塞,虚假的“验证码流失卡点”被成功打通。数据显示,该节点的异常流失被成功剔除了约 42.6%,漏斗重新恢复健康。整体的新用户注册转化率在两周的观察期内稳步回升了 18.3%。这次技术诊断充分证明,只有将业务节点与物理停留时间进行严格对账,才能揭开路径流失背后的真实面纱。
找到了成百上千个流失节点,并不意味着立刻就要调集所有研发资源去挨个修补。面对错综复杂的网状路径,建立科学的优化优先级,比盲目动手更考验增长团队的功力。
这是一个产品迭代中极易踩坑的误区。某个隐藏在三级菜单的边缘功能页,可能流失率高达 89.5%,但每天只有 100 个人访问;而从“购物车”到“确认支付页”的流失率虽然只有 6.2%,但每天流经这里的绝对流量基数是十万人。
科学的优化优先级模型必须引入两个权重指标:一是“流量绝对基数”,二是“距离终点(商业转化)的层级”。原则上,越靠近支付、绑卡或核心留资环节的流失点,其挽回的潜在 ROI(投资回报率)越高,即使只能优化零点几个百分点,也应当被无条件列为 P0 级优化任务。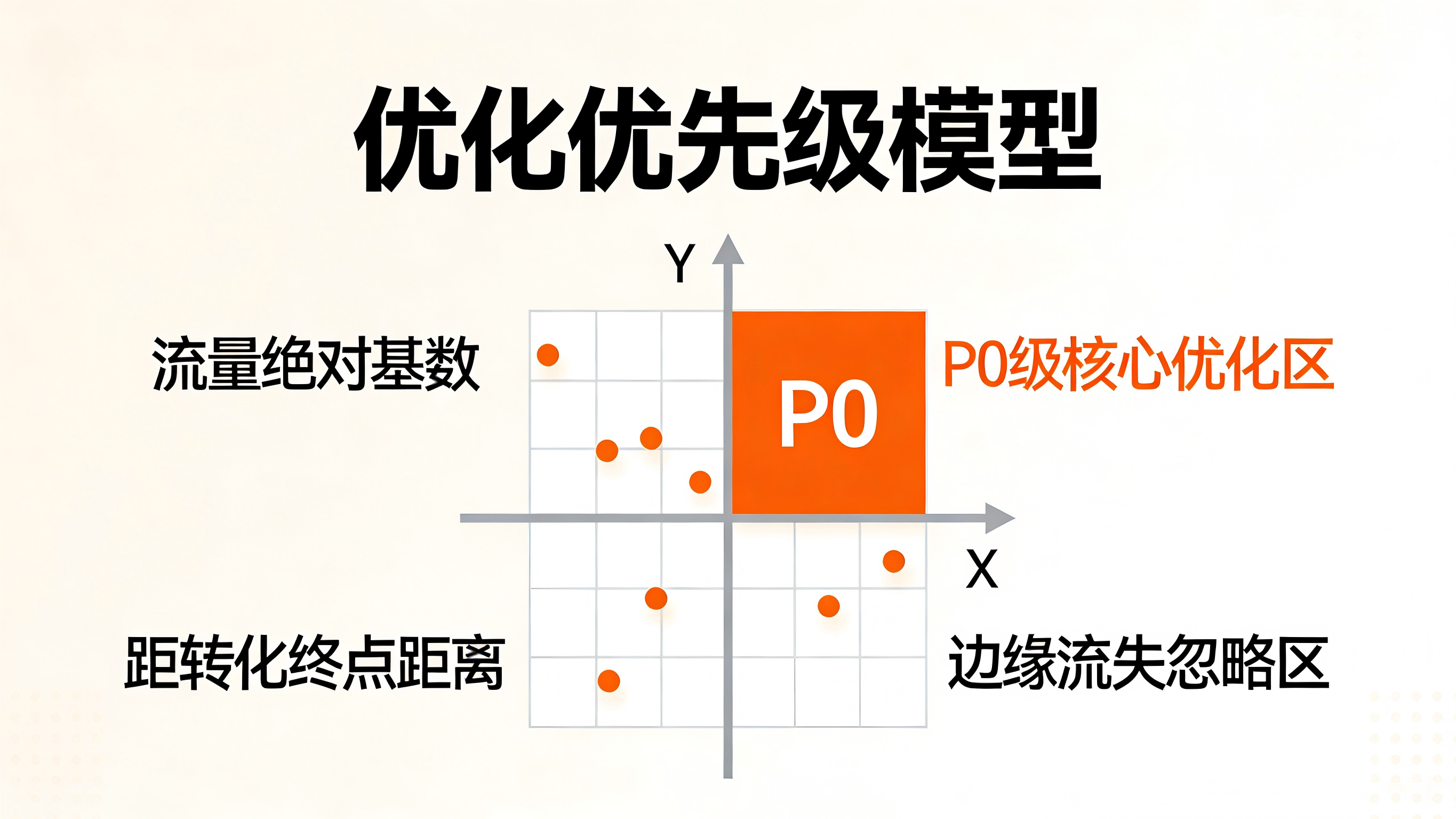
现代移动端路径分析中最棘手的问题,往往发生在跨端跳转场景上。当一个用户在微信里看了一篇爆款 H5 文章,点击底部的“下载 App”并跳入各大应用商店后,用户的行为路径在传统的 Web 统计和 App 端内统计中就彻底断成了两截。普通的路径探索工具无法将这两段跨越了生态壁垒的独立会话(Session)合二为一。
为了解决这个致命断层,业界主流且成熟的解法是引入类似全渠道归因统计的基础设施。这类工具能通过底层的参数透传技术(如通过剪贴板、指纹设备匹配等模糊与精确结合的算法),把 Web 端的设备特征、点击场景与渠道标签暂存下来,并在用户下载 App 首次冷启动时瞬间完成匹配与缝合。这样,分析师就能在一条完整的闭环路径图上,清晰地看到究竟是哪篇文章引流来的用户,在 App 里的后续交互最深、留存率和生命周期价值(LTV)最高。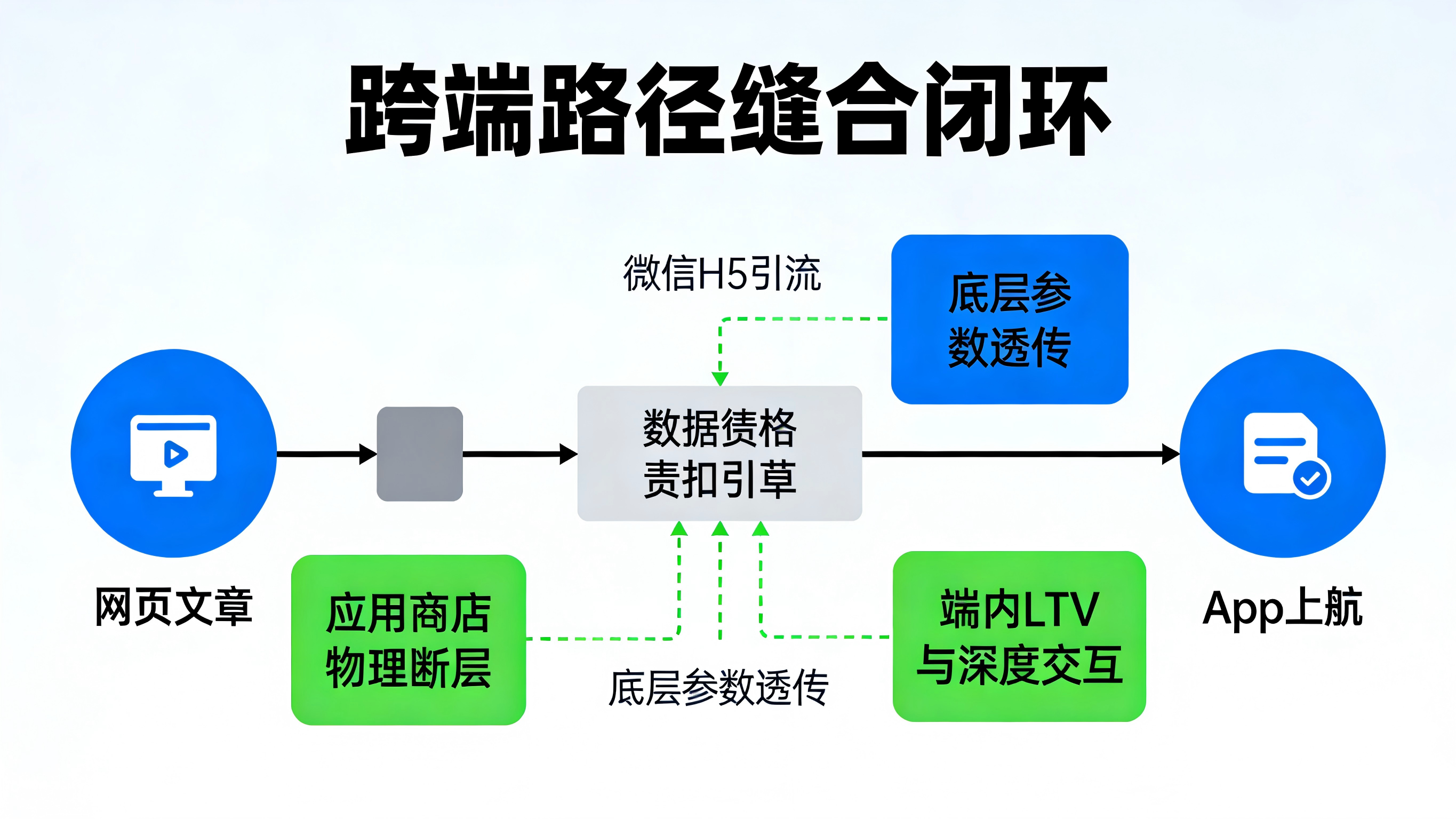
路径分析工具怎么选?用 GA4 还是专门的埋点平台?
这取决于你的业务复杂度与数据监控的颗粒度。对于基础网站和只看大盘宏观流量的轻量级应用,GA4 免费提供的路径探索功能已经足够强大;但如果你的业务涉及极其深度的自定义事件属性下钻(比如需要按不同会员等级、不同城市类目来拆解交互链路),或者需要针对特定流失动作做实时的策略阻断和发券挽回,那么引入专业的全链路行为分析平台会大幅降低团队的数据清洗和工程维护成本。
页面停留时长算在路径分析里吗?
严格来说,古典的转化漏斗模型不看时长,但现代科学的路径分析必须强制绑定时长。没有时长作为第三维度的参照,当用户在某个节点离开时,你永远无法准确判断其流失原因到底是“页面交互没看懂/Bug卡死”还是“对内容根本不感兴趣”。目前高级的数据增长平台都已经支持在路径节点图上直接叠加呈现中位数停留时长(Median Duration)。
为什么我的桑基图(Sankey Diagram)看起来一团乱麻?
通常是因为你的事件颗粒度划得太细,或者噪音数据没有在底层清洗干净。建议在做可视化路径分析前,先做“抽象与归类”。例如,不要把“点击了红色毛衣”、“点击了蓝色牛仔裤”当成几十个分散的独立节点,而是把它们统一聚类合并为“触发商品详情页”这一个核心大事件。先把骨干大路径理清,一旦发现某条主干流失异常,再下钻到具体的参数维度层面去寻找原因。
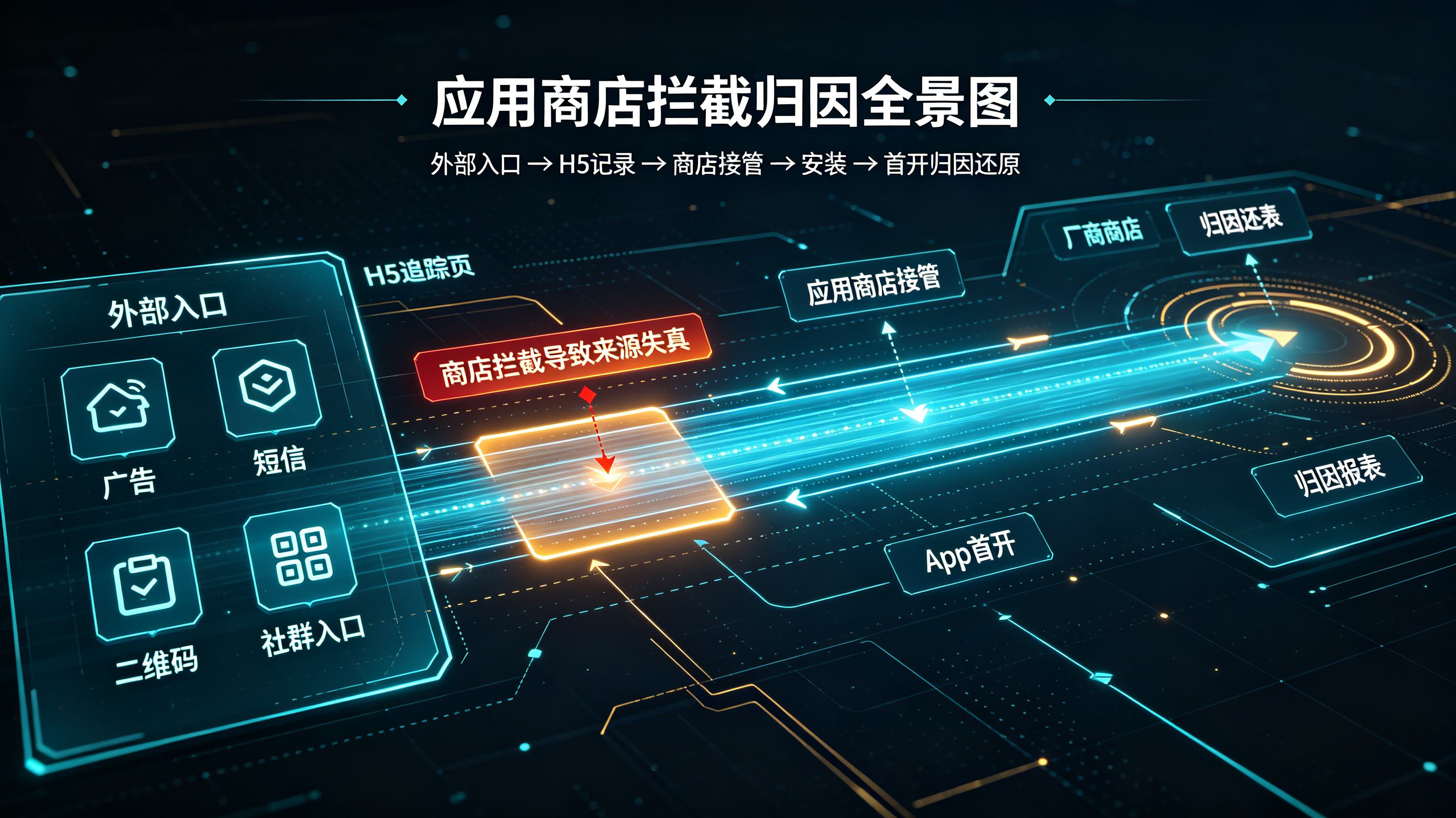
应用商店拦截后怎么归因?下载来源追踪原理解析
2026-06-26

广告监测链接怎么做?App安装来源追踪原理解析
2026-06-26

App传参安装怎么做?全渠道参数还原原理解析
2026-06-26

谷歌重组AI编程小组?追赶Anthropic的节奏被迫加速
2026-06-26
科大讯飞AI招采平台2.0如何重构流程?招投标开始进入全链路智能化
2026-06-26
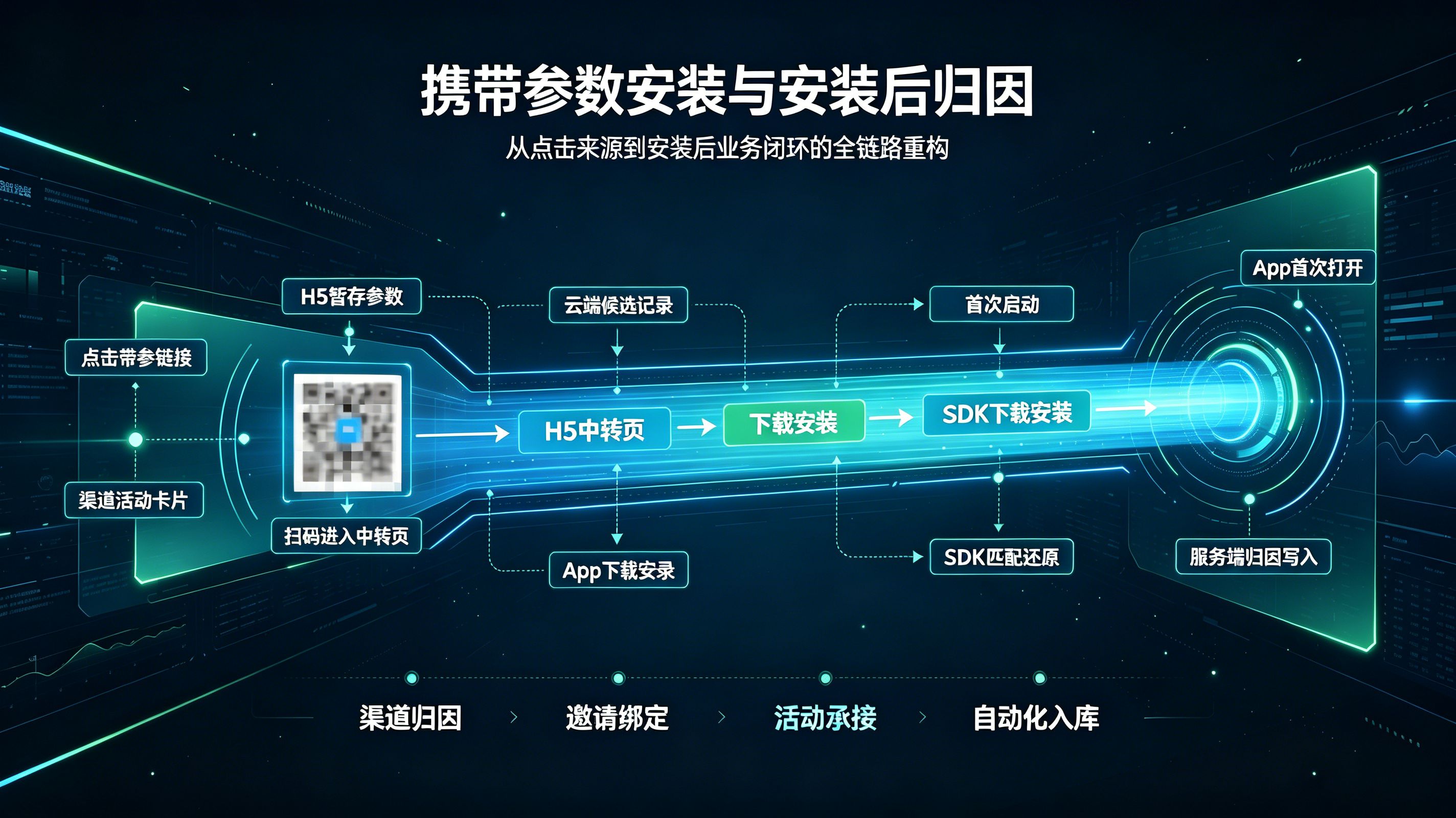
携带参数安装怎么实现?安装传参与归因技术解析
2026-06-25

Agent Ready怎么落地?企业智能体进入统一管理时代
2026-06-25

360与惠普签署战略合作?AI安全与终端融合进入落地期
2026-06-25

荣耀终端要被AI重做?MWC上海上终端变革的真实信号
2026-06-25

免填邀请码怎么实现?自动绑定邀请关系技术解析
2026-06-24
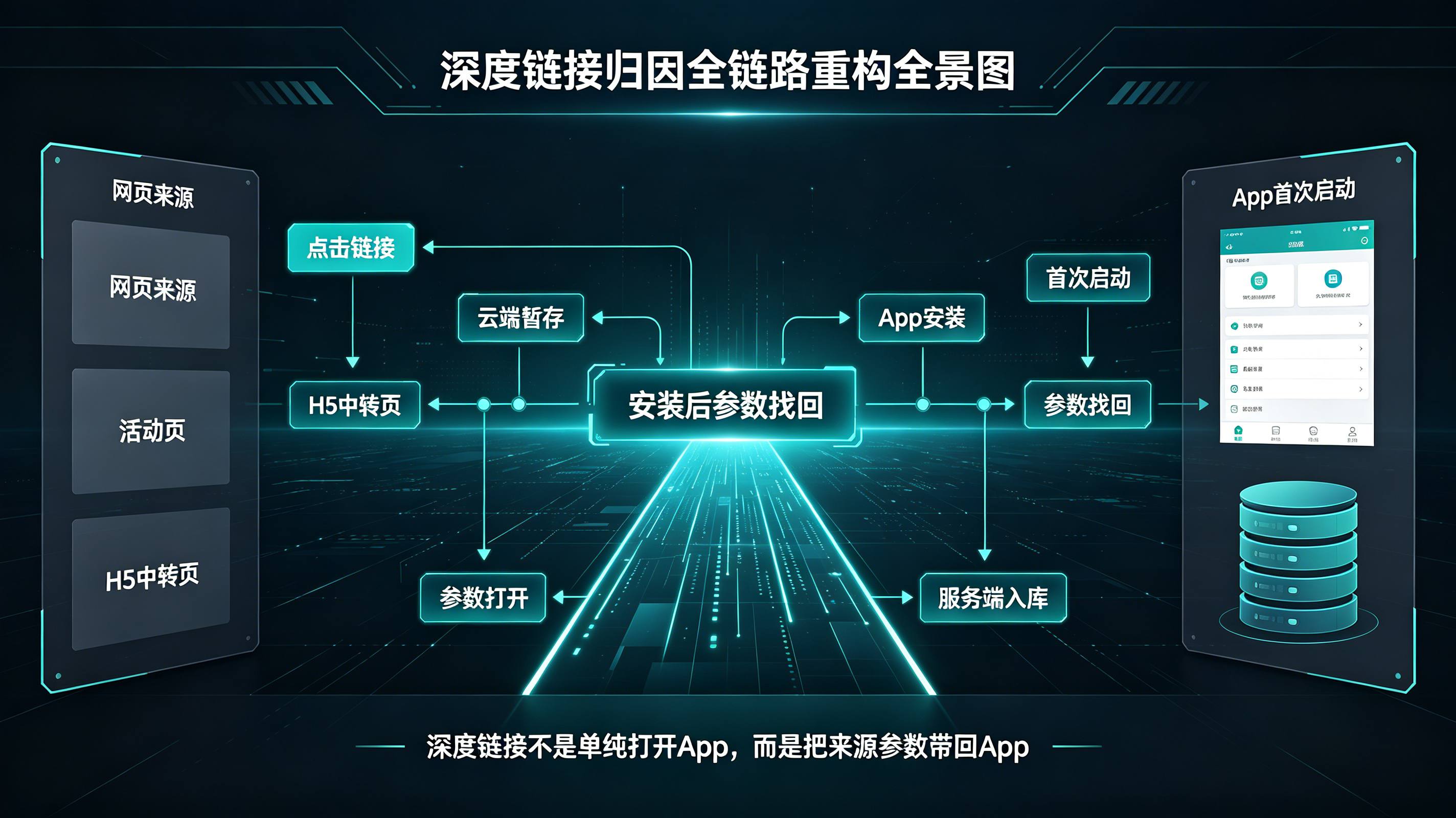
深度链接归因怎么做?安装后参数找回技术解析
2026-06-24

豆包专业版正式推出?AI收费战开打背后的订阅分层与商业验证
2026-06-24
毁灭全人类游戏今日登陆新主机?爆款主机游戏跨端种草考验一键拉起基建
2026-06-24
即梦AI上线原生4K视频生成?打破高糊魔咒,AI视觉算力重塑营销分发底座
2026-06-24

免打包渠道统计是什么?App免填邀请码技术原理解析
2026-06-23






















