






手机微信扫一扫联系客服
联系电话:18046269997



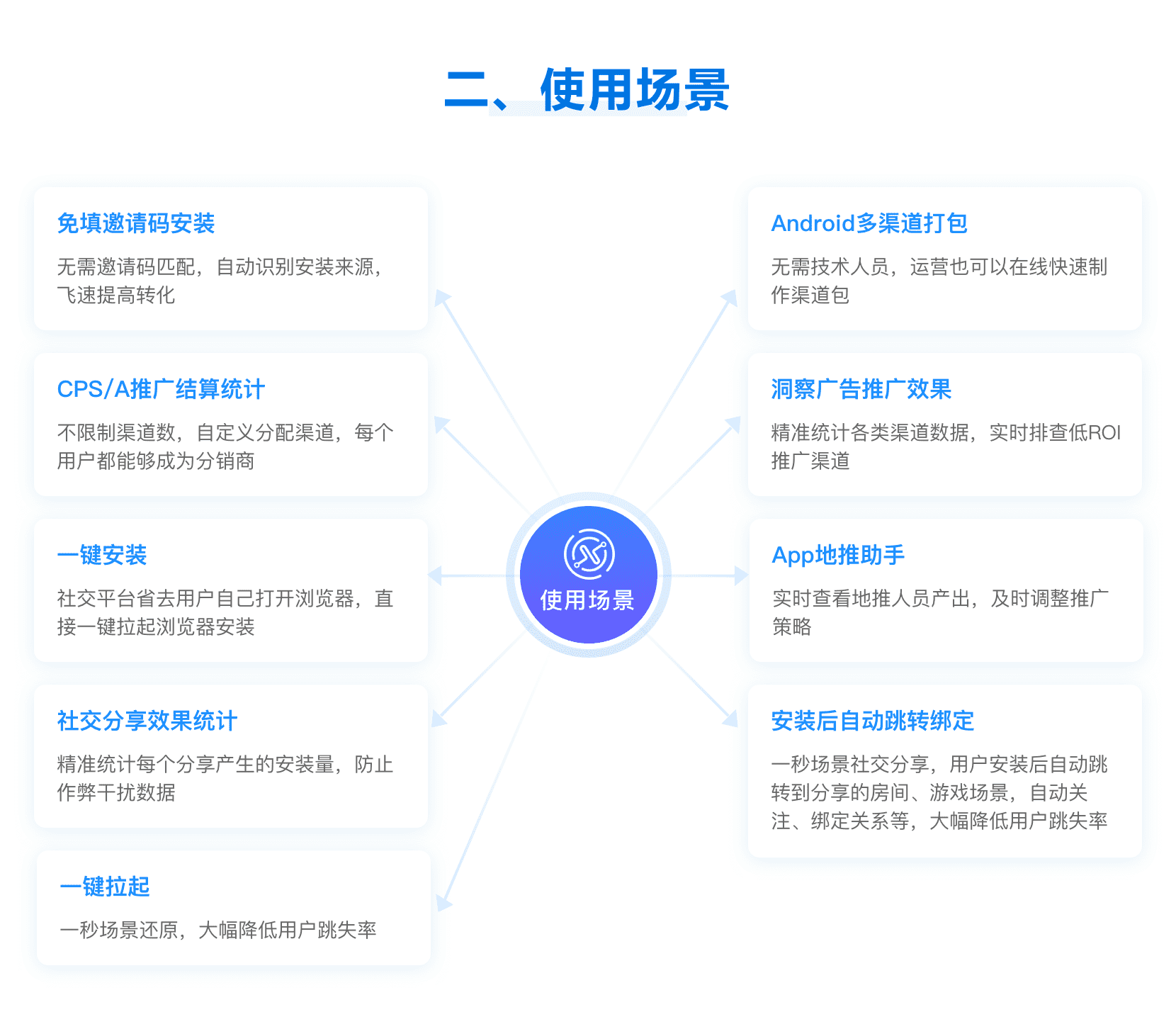
 APP安装免填邀请码
APP安装免填邀请码 社交分享效果统计
社交分享效果统计 广告投放数据统计
广告投放数据统计 CPA/CPS推广效果统计
CPA/CPS推广效果统计 App地推统计
App地推统计 App拉起
App拉起 网页/应用内直接安装
网页/应用内直接安装 Android多渠道打包
Android多渠道打包 App安装后自动绑定
App安装后自动绑定 App分享效果统计
App分享效果统计 Deeplink深度链接
Deeplink深度链接 手机微信扫一扫联系客服
 354
354
H5获取浏览器上数据
二、恶意爬虫访问服务器爬取数据的行为构成“入侵”,入侵行为应理解为“避开或突破计算机信息系统安全防护措施”访问计算机信息系统的行为。恶意爬虫的程序设计是将其访问过程伪装成普通互联网用户的普通浏览器访问行为,避开服务器的验证机制,达到获取数据的目的。网站运营商设置了防爬虫的验证机制。


H5获取浏览器上数据
非法获取计算机信息系统数据罪的罪状表明,违反国家规定,侵入国家事务、防卫建设、前沿科技领域以外的计算机信息系统或采用其他技术手段,在该计算机信息系统中保存、处理或传输的数据,情节严重的行为。笔者认为,利用恶意爬虫类的行为捕捉网站数据已经构成形式不法和实质性不法的理由如下:
。行为者违反服务器数据获取规则实施逮捕,行为造成了法律利益的危险。非法获取计算机信息系统数据罪不是抽象的危险犯,行为和结果需要判断因果关系。
。
在图三所示的代码中,通过代码获取指定站点的源代码层,运行结果无法获取数据。因为服务器加入Robot协议,禁止网络机器人访问该服务器的数据信息。因此,图4是图3代码的运行结果。
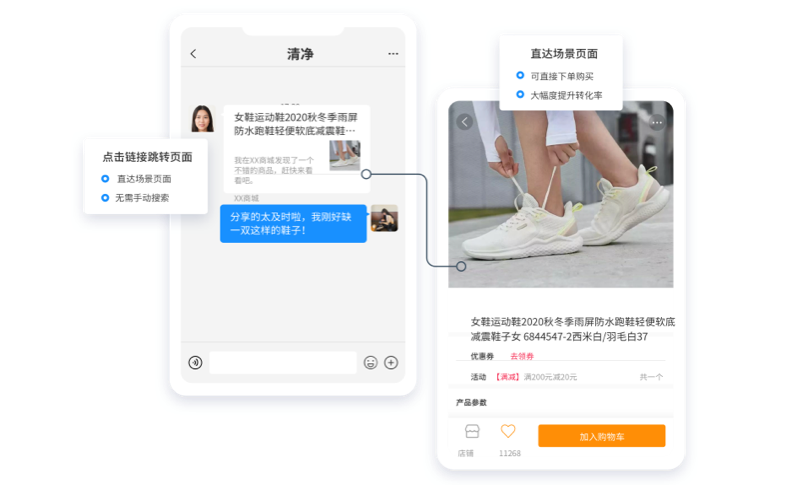
。
捕获行为违反服务器数据捕获规则具有不正当性质,从形式不正当性和实质不正当性的观点出发,可以认定捕获行为给受害者的数据带来了危险。本案中出现的“利用技术手段捕获受害者服务器存储的视频数据”“通过……3个接口捕获服务器数据”“在捕获数据过程中伪造UA和IP绕过服务器访问频率的限制”。
H5获取浏览器上数据


全球首例AI Agent勒索攻击曝光?AI完全接管黑客链路将如何颠覆生态
2026-07-06

生数科技发布视频大模型Vidu S1?实时交互技术突破或将彻底颠覆内容引流转化
2026-07-06

苹果首款折叠手机被曝出货量不足?全新屏幕终端形态或将彻底颠覆传统应用生态
2026-07-06

延迟深度链接怎么实现?安装后场景还原与归因技术解析
2026-07-02

Claude Sonnet 5把企业AI自动化成本打到四成?智能体时代中端模型正在改写选型逻辑
2026-07-02

AI无法替代人工成共识?人机协作正在重写企业增长与用工逻辑
2026-07-02

Cloudflare精细化AI流量管理上线?默认拦截训练爬虫保护广告与数据资产
2026-07-02

App Links怎么配置?Android应用链接原理解析
2026-07-01
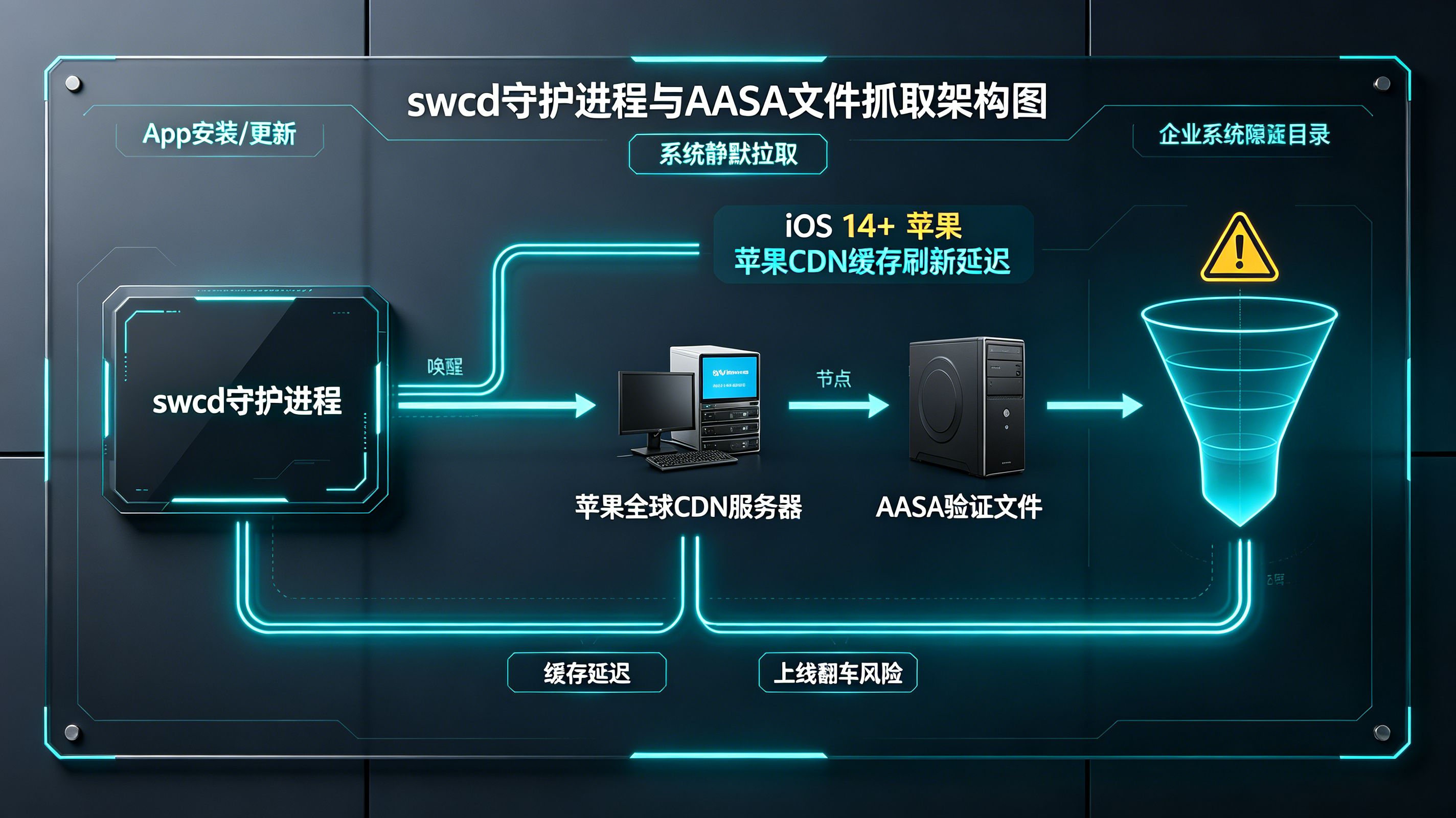
Universal Links怎么配置?iOS通用链接唤醒原理解析
2026-06-30
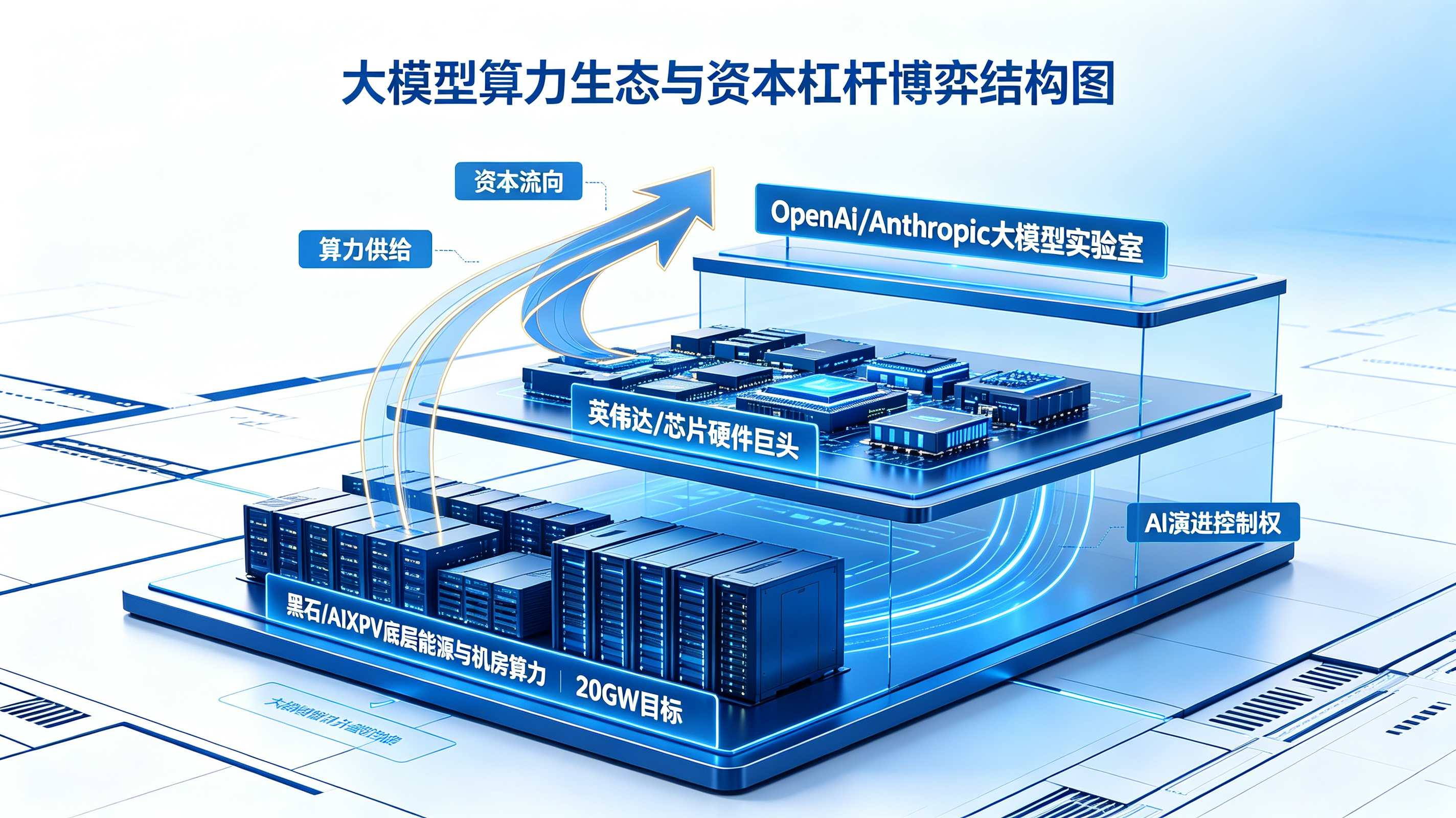
黑石300亿美元AI数据中心?算力基建竞赛如何做
2026-06-30

美团LongCat-2.0大模型首发上线?万亿参数重塑算力格局
2026-06-30
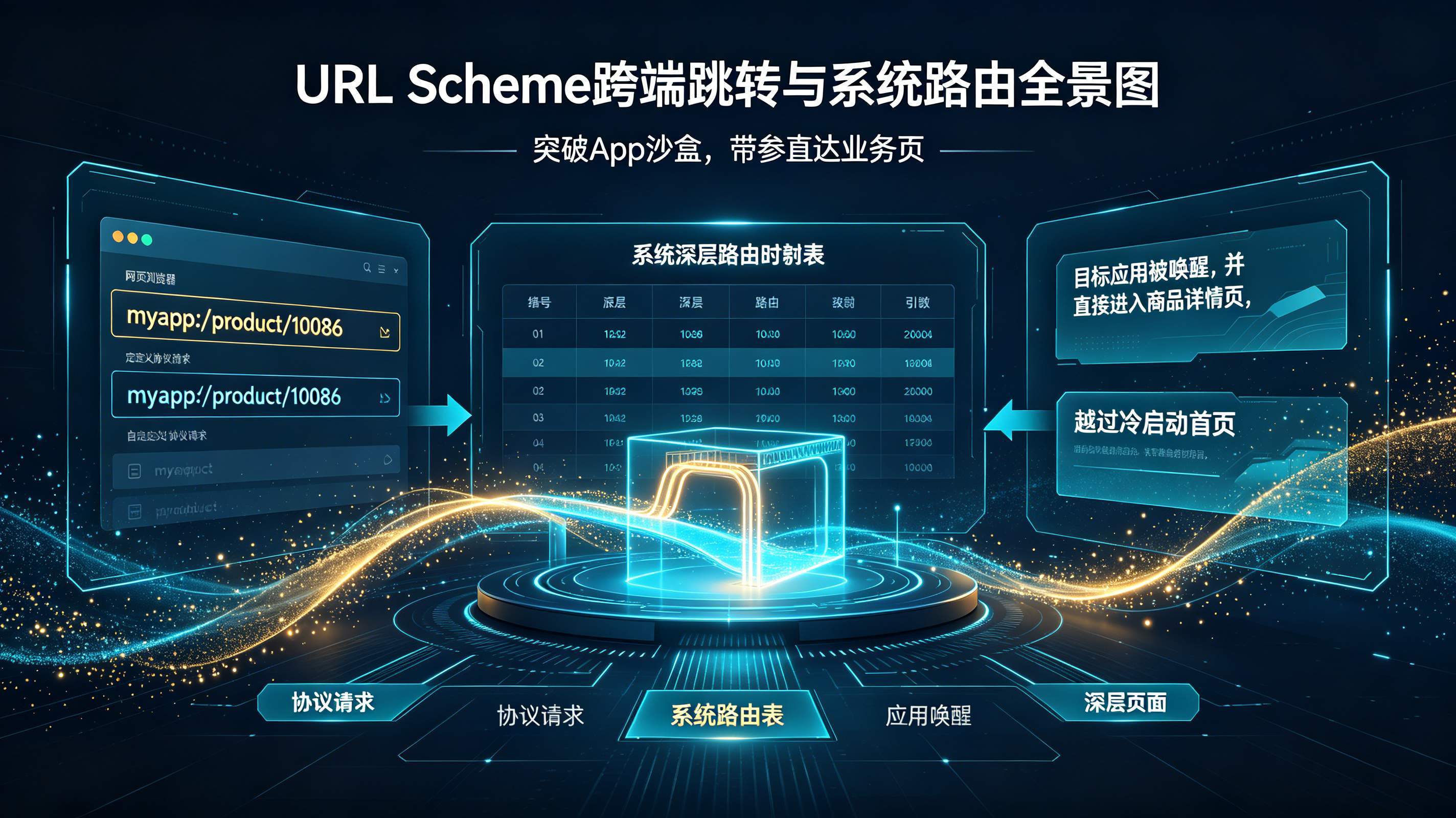
URL Scheme怎么打开App?应用内跳转协议原理解析
2026-06-29

一键拉起App怎么做?跨端无缝跳转与场景还原原理解析
2026-06-29

谷歌算力告急限制Meta使用?大模型算力瓶颈拖垮巨头研发
2026-06-29
马斯克宣布今年每月发一个全新大模型?Grok 4.5拉响警报
2026-06-29






















