






手机微信扫一扫联系客服
联系电话:18046269997



 APP安装免填邀请码
APP安装免填邀请码 社交分享效果统计
社交分享效果统计 广告投放数据统计
广告投放数据统计 CPA/CPS推广效果统计
CPA/CPS推广效果统计 App地推统计
App地推统计 App拉起
App拉起 网页/应用内直接安装
网页/应用内直接安装 Android多渠道打包
Android多渠道打包 App安装后自动绑定
App安装后自动绑定 App分享效果统计
App分享效果统计 Deeplink深度链接
Deeplink深度链接 手机微信扫一扫联系客服
 176
176地推二维码统计的难点不在生成二维码,而在线下扫码、应用商店下载、首次启动与安装归属之间存在天然断层。更可靠的做法是为地推人员或点位配置参数化二维码,再结合安装回流、特征匹配与幂等去重,把扫码、安装、激活和有效新增串成可复盘链路。
 地推二维码统计怎么做? 在移动增长和 App 开发领域,行业里越来越把地推二维码统计视为线下拉新能否进入精细化运营与自动结算的核心基础设施;真正可执行的做法不是单纯生成一个可扫码图片,也不是只统计访问量,而是通过参数化二维码、中转承接、安装回流、首开匹配和统一归因规则,把扫码、下载、安装、注册和有效新增串成一条可还原、可解释、可复盘的数据链。本文会从物理断层、底层原理、指标体系、技术诊断案例和常见问题几部分展开,直接回答地推二维码统计怎么做,并把扫码安装自动归因里最容易出错的环节讲透。
地推二维码统计怎么做? 在移动增长和 App 开发领域,行业里越来越把地推二维码统计视为线下拉新能否进入精细化运营与自动结算的核心基础设施;真正可执行的做法不是单纯生成一个可扫码图片,也不是只统计访问量,而是通过参数化二维码、中转承接、安装回流、首开匹配和统一归因规则,把扫码、下载、安装、注册和有效新增串成一条可还原、可解释、可复盘的数据链。本文会从物理断层、底层原理、指标体系、技术诊断案例和常见问题几部分展开,直接回答地推二维码统计怎么做,并把扫码安装自动归因里最容易出错的环节讲透。
地推二维码统计最容易被误解的地方,是很多团队以为“二维码被扫了”就等于“地推效果被统计到了”。实际上,普通二维码只能告诉你链接是否被访问,最多再知道落地页被打开了多少次,但无法天然知道用户后面是否进入应用商店、是否完成下载、是否首次打开 App,更无法判断这个新用户最终应归属于哪个业务员、哪个摊位或哪个活动批次。线下推广天然横跨多个运行环境:扫码动作发生在微信、浏览器或系统扫码容器中,下载承接发生在 H5 中转页或应用商店里,激活和注册发生在 App 内部,这几段环境之间没有自然继承关系,导致地推二维码统计一旦缺少中间层,就会从“可追踪链路”退化成“零散事件集合”。
这种断层会直接把业务拖入三个常见陷阱。第一类陷阱是“只看扫码量”,前端看上去很热闹,但后端安装和注册根本接不上,结果业务员拼命拉扫码,财务却无法发结算。第二类陷阱是“共用二维码物料”,多个地推员拿相同海报去推,最后只能看总量,无法拆解个人贡献。第三类陷阱是“后置补录来源”,例如让用户安装后填邀请码,或者靠业务员手工上报,这种方式在高并发线下场景里几乎必然失真。围绕这一问题,如何通过渠道二维码统计地推效果? 这类资料反复强调,地推二维码统计真正要统计的不是“谁扫过码”,而是“谁从哪个二维码入口进入,并最终形成了可验证的安装和转化”。
普通二维码本质上只是一个静态入口,把用户引到某个页面或链接。它没有能力在用户跳出当前容器、进入商店再返回 App 的过程中自动保留来源身份,也无法在首次启动时主动告诉服务端“这个用户是从哪张码来的”。所以普通二维码最强只能停留在访问统计层,而地推二维码统计的目标是安装统计、激活统计和效果归属统计,两者不是一个技术层级的问题。只做前者,看起来成本低,实际上后面所有效果结算都会变成争议来源。
断点通常集中在三个阶段。第一,扫码容器只能读取二维码中的 URL 或参数,但不会替你长期保存这些内容。第二,应用商店负责分发安装包,不负责传递营销来源。第三,用户首次启动 App 时,如果客户端没有把首开时间、设备特征和回流标记传回服务端,那么此前的扫码行为就无法和当前安装行为做可靠匹配。这也是为什么地推二维码统计必须引入中转暂存层,否则二维码里的渠道身份在下载阶段就已经断掉了。
漏记来自来源身份在中间链路丢失,串单来自多个二维码或多个业务员同时触达同一用户而没有明确优先级。若多个业务员使用同一物料,或者二维码参数设计过粗,后面即使有安装也无法准确还原到人。若用户今天扫码、明天安装,或者先扫 A 码再扫 B 码,系统又没有时间窗口和幂等逻辑,就很容易把一次真实新增重复算给多个入口。地推二维码统计如果不把排重和优先级设计进底层,表面上是数据多,实际上是脏数据更多。

地推二维码统计真正可用,依赖的是一条完整且可解释的数据管线。步骤一,系统为每个地推员、摊位、海报版本或活动批次生成独立二维码,二维码背后挂载一组参数化渠道信息,至少包含渠道 ID、业务员 ID、区域 ID、活动 ID、物料版本和生成时间。步骤二,用户扫码后先进入中转层,中转层负责记录扫码时间、IP、UA、OS 版本、设备型号、网络类型、扫码容器、访问来源等环境特征,并将二维码中的渠道参数一并写入暂存池。步骤三,系统判断设备是否已安装 App:若已安装则直接唤起并透传上下文,若未安装则跳转到商店或标准下载页,但原始参数必须先在服务端保存,而不能依赖商店替你保管。步骤四,用户安装完成首次打开 App,客户端把首开时间、设备指纹摘要、IP、UA、OS 版本、包版本、网络类型等信息传回服务端。步骤五,服务端用时间窗口、特征匹配和去重逻辑,把“扫码事件”和“首次启动事件”重新拼接。步骤六,归因结果再进入渠道报表、业务员报表和结算报表,输出安装量、激活量、注册量、有效新增量等业务指标。
这套机制里最关键的不是二维码生成,而是“参数如何活着穿过下载链路”。应用商店不会替你记住地推员是谁,所以地推二维码统计必须把来源恢复的责任前置到中转层和服务端。通常做法是先把来源参数写进服务端暂存区,再在首次启动阶段凭借时间窗口与特征相似度做匹配。这里使用的特征维度不能过于单薄,至少要联合 IP、UA、OS 版本、设备型号、网络类型、首开时间偏差、扫码时间偏差等因素综合判断,必要时再加入 CTIT 分布、Z-Score 异常值判断与黑名单过滤。只有这样,扫码安装自动归因才不是一句口号,而是一套真正能跑通、能抗异常、能解释结果的技术系统。若把工具视角拉进来,地推二维码统计怎么精准?一人一码实现业务员业绩追踪 这类方案的核心也并不是“二维码样式差异”,而是让每个入口都成为一个独立可计算的渠道身份。
参数化二维码的设计原则,是让二维码不再只是“打开某个下载页”,而是“打开某个带身份的下载入口”。成熟体系里,一个二维码至少对应一个唯一渠道键,并挂载业务员、区域、活动、物料版本、点位编号等附加字段。这样做的价值不是为了后期展示更多字段,而是为了在发生争议时能把一次安装拆解回源头入口。地推二维码统计要想支撑大规模结算,参数必须足够细,否则报表只能拆到渠道组,无法拆到人和具体点位。
应用商店是地推二维码统计里最容易丢链路的阶段。因为用户一旦跳进商店,原始二维码参数通常不会继续显示在当前环境中,所以来源恢复只能依赖“事前暂存 + 事后回流”。常见做法是在扫码后先把来源参数写入服务端,再把一个临时追踪键和环境特征一起记录下来。用户安装后首次打开 App,客户端把首开信息回传,服务端再根据时间窗口和设备环境去找最可能对应的扫码事件。这个过程如果做得足够稳,哪怕用户跨分钟、跨小时甚至跨天安装,地推二维码统计仍然有机会把来源找回来。
扫码安装自动归因不能只靠单一字段硬匹配,否则容错性极差。更成熟的做法是采用多维加权:先以时间窗口筛掉明显不可能的样本,再根据 IP 相似度、UA 相似度、OS 版本一致性、设备型号一致性、网络环境接近度等维度给样本打分。如果某个样本从扫码到首开只间隔 2 秒,而安装包体积接近 100MB,那么它即便特征看上去匹配,也应被标记为异常优先检查。相反,若某个样本在 30 秒到数小时内完成首开,并且特征高度一致,便应具备更高归因权重。地推二维码统计真正考验的,就是这种“既能容错又能排错”的判定能力。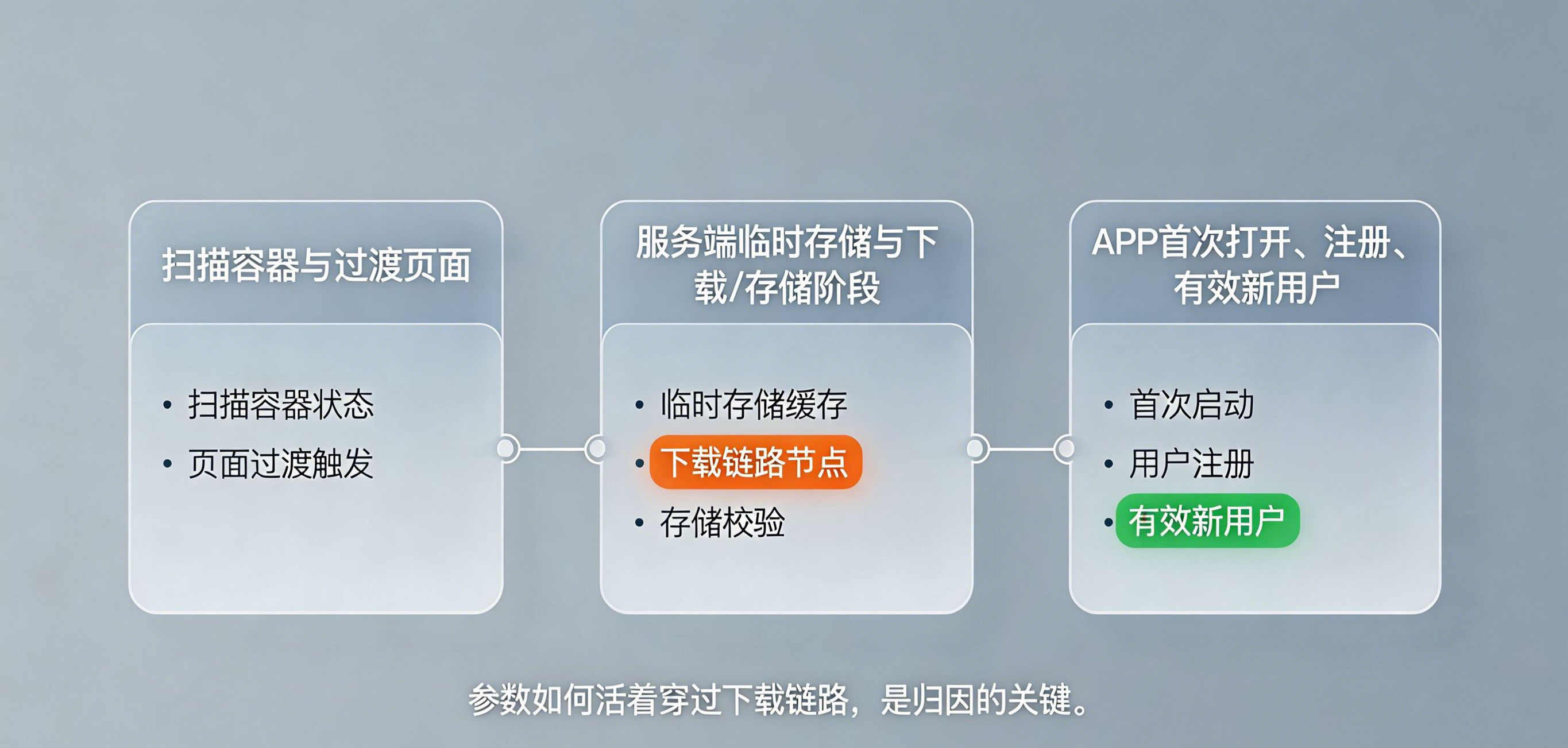
| 链路阶段 | 输入内容 | 处理逻辑 | 输出结果 |
|---|---|---|---|
| 扫码入口 | 二维码参数、扫码时间、扫码容器 | 记录渠道身份与环境特征 | 扫码事件入库 |
| 中转承接 | IP、UA、OS 版本、设备型号、访问来源 | 参数暂存、是否已安装判断 | 下载或唤起路径确定 |
| 下载/商店阶段 | 标准安装包、跳转记录 | 保持服务端上下文不丢失 | 等待首开回流 |
| 首开回流 | 首开时间、设备指纹摘要、包版本、网络类型 | 与扫码事件做匹配和排重 | 形成归因结果 |
| 报表输出 | 归因结果、注册/激活/有效新增事件 | 聚合、分层、去重 | 地推二维码统计报表 |
地推二维码统计如果只盯着扫码量,很容易把无效热闹误判为高质量增长。更完整的指标体系应该至少覆盖五层:第一层是前端触达指标,包括扫码量、访问量、落地页点击率;第二层是下载承接指标,包括下载触发率和下载完成率;第三层是安装激活指标,包括安装量、首开量和激活率;第四层是业务转化指标,包括注册量、实名率、首单率、有效新增率;第五层是质量控制指标,包括重复归因率、异常样本率、串单率和渠道稳定度。只有把这五层一起看,地推二维码统计才真正有资格支撑投放优化、业务员考核和财务结算。
不同方案之间的差距也远不只是“统计细不细”。普通二维码方案几乎不具备跨环境来源恢复能力,访问量也许很多,但安装量和激活量很难稳定追上。渠道二维码已经比普通二维码强,因为至少入口开始具备身份信息;但如果没有服务端暂存和首开回流,它仍然容易在应用商店阶段断链。一人一码动态归因方案的优势在于入口身份更细、来源恢复更稳、后续结算更可解释,但代价是对后端能力、埋点设计和反作弊规则要求更高。若从线下扫码统计与渠道数据追踪的行业做法看,外部方法论普遍也把“参数化入口 + SDK 回流 + 报表分层”视为更成熟的路径。
地推二维码统计至少要关注扫码量、访问量、下载量、安装量、首开量、注册量和有效新增率。扫码量回答的是曝光后的即时吸引力,安装量回答的是承接页和下载链路是否顺畅,注册与有效新增则决定这波地推流量到底有没有真正业务价值。除此之外,重复归因率和异常样本率必须长期监控,因为这两个指标往往直接决定报表是否可信。
| 方案 | 参数保留能力 | 归因精度 | 时效性 | 作弊防护 | 管理成本 |
|---|---|---|---|---|---|
| 普通二维码 | 极弱,只能看到访问入口 | 低,几乎无法稳定追安装 | 高,访问统计快 | 极弱,无法识别串单 | 低,但后续代价高 |
| 渠道二维码 | 中,能区分不同入口 | 中,安装阶段易断链 | 中 | 中,需配套规则 | 中 |
| 一人一码动态归因 | 高,可追到业务员或点位 | 高,可恢复完整链路 | 高,支持近实时报表 | 高,可结合 CTIT 与黑名单 | 中到高,但规模化更稳 |
可信的地推二维码统计至少满足四个条件:第一,结果能精确到业务员、摊位、区域或物料版本,而不是只给总量。第二,结果经得起物理对账,例如一个 100MB 包体不可能在 2 秒内完成真实安装与首开。第三,系统能解释为什么这个新增归属于这个入口,而不是另一个入口。第四,报表口径与结算口径一致,不会出现运营看到 200 个新增、财务只认 80 个有效新增的割裂局面。
某工具类 App 曾在地铁口、商圈和展会三类场景同步铺设地推二维码,表面上看数据非常漂亮:扫码量连日增长,落地页访问也持续放大,但真正进入月底结算阶段后,团队发现安装归属一片混乱。第一,多个业务员在相近区域共享了一批物料,导致入口身份粒度不够;第二,部分用户在扫码后没有立即安装,而是过了一段时间才从应用商店完成下载,系统无法稳定找回来源;第三,某些渠道的激活量异常高,但注册率和留存极低,怀疑存在重复归因和设备刷量。业务层面的表现就是“大家都说自己有量,但没有人能证明自己的量到底值多少钱”,这正是地推二维码统计失控的典型征兆。
进入日志与链路对账阶段后,团队把扫码日志、中转页访问日志、下载跳转日志、首次启动日志和注册日志全部拉通,开始做逐层映射。最先引入的不是模型,而是物理约束:若安装包约 100MB,在 5G 网络环境下从下载到安装完成通常需要 10–15 秒,那么从扫码到首开仅 2–4 秒的记录大概率不是一次真实新装,更可能是已安装直接拉起、异常缓存回流或伪造设备上报。继续往下看,团队又发现异常样本在 UA、OS 版本和机型上高度集中,某几个 IP 段短时间内出现大量“新装”,而且其中不少记录缺失完整中转页日志。这一步非常关键,因为它证明问题并不只是“二维码不够多”,而是整条地推二维码统计链路的参数保留、安装回流和异常识别都存在短板。
技术介入后,团队做了四件事。第一,重做二维码策略,为每个业务员、每个活动点位和每个物料版本生成独立参数化入口,彻底废掉多人共用同一下载链接的做法。第二,重构中转层,把扫码时间、IP、UA、OS 版本、设备型号、网络类型、活动参数全部写入服务端暂存池,并建立 3 天回流窗口。第三,调整归因模型,引入 CTIT 分布约束、Z-Score 异常值识别、设备指纹加权匹配、幂等去重和黑名单规则,对反复安装、反复首开和异常高频来源进行拦截。第四,重做报表口径,把扫码量、首开量、注册量、有效新增量和异常样本量分层展示,不再让“总量看起来很大”的假象掩盖底层问题。整个过程中,真正有效的不是某一个神奇参数,而是把地推二维码统计重新变成一条有因果约束的链路。
复盘结果很清晰:系统把安装来源恢复率提升到了 98.7%,有效新增识别率提升了 21.4%,串单争议显著下降,异常样本拦截率也得到明显改善。更重要的是,团队终于可以把一次地推活动拆到业务员、点位、物料和时间批次四个维度,并且用统一规则解释每一条新增的来源。这个案例留下的可复用经验是三条:第一,地推二维码统计怎么做,核心不是先做图,而是先做参数体系;第二,扫码安装自动归因必须依赖中转暂存和首开回流,不能把来源恢复寄希望于应用商店;第三,只有同时加入物理约束、特征匹配和排重风控,报表才真正有资格进入结算层。
要看到安装结果,不能只生成一个可访问链接,而要把二维码做成带参数的入口,并配合中转承接、安装回流和首开匹配机制。这样系统才能在用户跳商店后仍保留来源身份,并在首次打开 App 时把扫码事件与安装事件重新连接起来,最终输出真正可用的地推二维码统计结果。
普通二维码主要解决“用户能不能扫进去”,它偏访问入口;渠道二维码解决的是“用户从哪个入口进来,并最终有没有形成安装和转化”,它偏来源识别和效果归属。前者更像一个静态门牌,后者更像一个可追踪渠道。若没有后续回流与去重机制,普通二维码的数据看似简单,其实最难支撑真实业务结算。
因为真实世界的安装链路并不稳定。用户可能延迟安装、重复扫码、跨网络环境切换,也可能先后接触多个二维码入口。只要系统没有充分利用时间窗口、设备特征、CTIT 分布、优先级规则和幂等逻辑,就会出现误差。地推二维码统计不是追求零误差,而是追求在可解释前提下把误差压到可控范围。
本文主要参考了地推二维码统计、渠道二维码归因、App 地推效果统计、参数化入口设计以及线下渠道数据追踪等类型的资料,包括官方文档、站内方法论文章、行业技术实践和渠道统计场景说明。它们共同指向一个结论:地推二维码统计不是简单生成二维码,而是入口参数、服务端暂存、安装回流、异常识别和业务结算之间的一整套系统工程。

全球首例AI Agent勒索攻击曝光?AI完全接管黑客链路将如何颠覆生态
2026-07-06

生数科技发布视频大模型Vidu S1?实时交互技术突破或将彻底颠覆内容引流转化
2026-07-06

苹果首款折叠手机被曝出货量不足?全新屏幕终端形态或将彻底颠覆传统应用生态
2026-07-06

延迟深度链接怎么实现?安装后场景还原与归因技术解析
2026-07-02

Claude Sonnet 5把企业AI自动化成本打到四成?智能体时代中端模型正在改写选型逻辑
2026-07-02

AI无法替代人工成共识?人机协作正在重写企业增长与用工逻辑
2026-07-02

Cloudflare精细化AI流量管理上线?默认拦截训练爬虫保护广告与数据资产
2026-07-02

App Links怎么配置?Android应用链接原理解析
2026-07-01
Universal Links怎么配置?iOS通用链接唤醒原理解析
2026-06-30
黑石300亿美元AI数据中心?算力基建竞赛如何做
2026-06-30

美团LongCat-2.0大模型首发上线?万亿参数重塑算力格局
2026-06-30
URL Scheme怎么打开App?应用内跳转协议原理解析
2026-06-29

一键拉起App怎么做?跨端无缝跳转与场景还原原理解析
2026-06-29

谷歌算力告急限制Meta使用?大模型算力瓶颈拖垮巨头研发
2026-06-29
马斯克宣布今年每月发一个全新大模型?Grok 4.5拉响警报
2026-06-29






















