






手机微信扫一扫联系客服
联系电话:18046269997



 APP安装免填邀请码
APP安装免填邀请码 社交分享效果统计
社交分享效果统计 广告投放数据统计
广告投放数据统计 CPA/CPS推广效果统计
CPA/CPS推广效果统计 App地推统计
App地推统计 App拉起
App拉起 网页/应用内直接安装
网页/应用内直接安装 Android多渠道打包
Android多渠道打包 App安装后自动绑定
App安装后自动绑定 App分享效果统计
App分享效果统计 Deeplink深度链接
Deeplink深度链接 手机微信扫一扫联系客服
 705
705App产品迭代与增长如何避免拍脑袋决策?本文深度解析AB测试(A/B Testing)的核心原理与App灰度发布机制。结合四步法技术诊断案例,揭示如何利用辛普森悖论排查底层哈希分流算法导致的转化率假象,有望将核心落地页真实转化率提升18.5%左右,助力团队构建严谨的数据验证闭环与增长引擎。
App产品迭代与运营活动如何避免拍脑袋决策? 在流量日益昂贵的存量时代,任何一次凭直觉的 UI 改版或价格调整都可能带来灾难性的转化率流失。引入严谨的 AB 测试(A/B Testing)机制,让真实用户的行为数据来做决定,是硅谷增长黑客的基石策略。通过底层分流算法与跨端数据对账,团队可以规避数据假象引发的错误判断。在涉及跨端分享拉新等复杂场景时,借助类似 Xinstall 这样的归因基建,能够有效保障两组方案的转化漏斗不迷失,实现科学的精细化增长。
在 App 的增长实验中,想要获得令人信服的结论,必须遵循严格的科学实验规范。
AB 测试的基础是单一变量控制原理 [web:267]。在同一时间维度下,系统将具有相同特征的用户流量随机分为两组。其中对照组(Control)会看到产品的原始默认版本(A版本),而实验组(Variant)则会看到修改后的新版本(B版本)。
参考 国际头部实验平台对AB测试核心定义的标准解释,这种对比测试的核心在于“控制变量”。例如,在测试支付按钮时,如果 A 是蓝色,B 是红色,那么除了颜色之外,按钮的文案、大小、甚至页面的加载速度都必须保持绝对一致。只有这样,最终转化率的差异才能被归因于“颜色”这一个变量的改变。
很多新手产品经理常犯的一个致命错误是:看到 B 版本的点击率比 A 版本高了 0.5%,就立刻决定全量上线 B。这在统计学上是极其危险的。
科学的 AB 测试必须关注“统计显著性(Statistical Significance)”。它通过计算 p-value(P值)来判断两组数据之间的差异是真的存在,还是仅仅由样本的随机波动引起的 。业界公认的标准是,只有当 p-value < 0.05(即有 95% 的把握认为差异不是随机产生的)时,实验结果才是可信的。此外,还需要观察置信区间(Confidence Interval),如果区间跨越了 0 轴(如预计提升范围是 -1% 到 +3%),则说明实验依然存在负向风险,不能盲目发版。
移动端 App 的发版成本远高于 Web 网页,一旦存在致命 Bug,用户只能通过去应用商店重新下载才能修复,因此实验设计必须如履薄冰。
区别于直接在应用商店全量发布新版本,现代成熟的 App 都会采用特性开关(Feature Flags)技术来实现云端控量。
当一项新功能(实验组 B)开发完毕后,系统通过云端配置,首先只向 5% 的在线用户开放该功能。在此期间,团队密切监测这 5% 用户的 App 崩溃率、主流程转化率以及用户反馈。如果数据表现良好,再将流量阀门逐步放大至 20%、50%,直至最终的全量(100%)。这种灰度发布机制不仅是 AB 测试的基础,更是 App 研发流水线中阻断重大线上故障的最后一道防火墙。
结合 [BI 数据看板搭建](F33 URL占位) 的原则,做实验绝不能“医得眼前疮,剜却心头肉”。
每一场实验都必须确立一个“核心评估指标”(如提升加入购物车的点击率),但同时必须设定 1 到 3 个“防劣化指标(Guardrail Metrics)” 。例如,为了让加入购物车按钮更显眼,设计师可能增加了一个巨大的炫酷动效。虽然核心指标提升了,但防劣化指标却可能发出警报:页面加载耗时增加了 2 秒,且最终的订单支付客单价不升反降。只有在防劣化指标未受损的前提下,核心指标的提升才具有全盘的商业意义。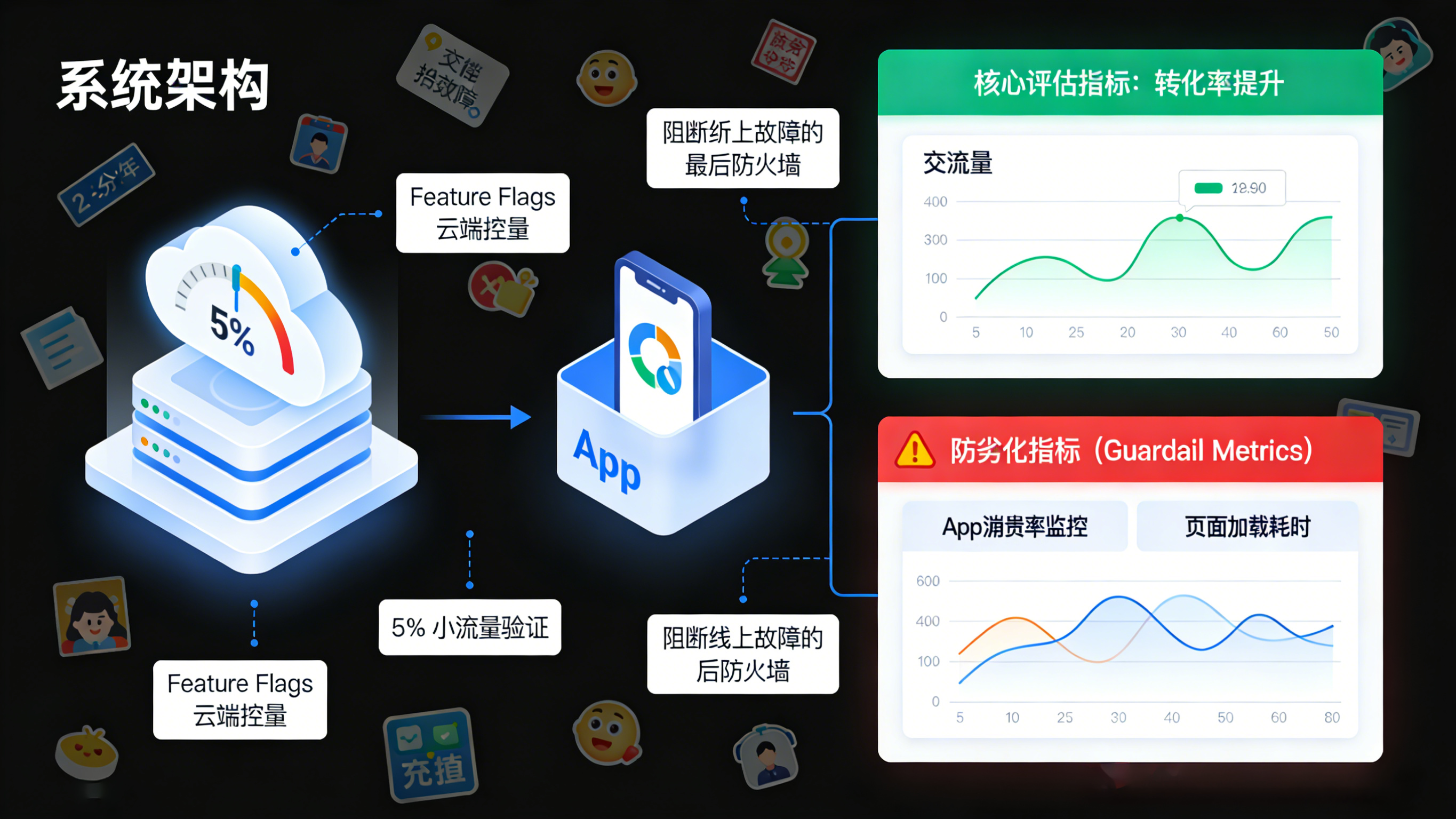
底层分流算法的缺陷,往往会制造出完美符合直觉的数据假象,把业务团队带入深渊。
某头部电商 App 对支付收银台的 UI 进行了重大重构。在一周的灰度 AB 测试中,前端数据大屏显示了一个“振奋人心”的结果:无论是切分看“新用户大盘”还是“老用户大盘”,B 版本(新版)的支付转化率都明显高于 A 版本(老版)。然而离奇的是,当技术团队基于这个结果将 B 版本的流量扩大到 50% 时,财务报表却发出严重警告:大盘的总支付成功率竟然出现了不可逆的环比下跌。
数据架构团队立刻介入并下钻到底层模块,通过物理级别的日志对账,揭开了分流引擎的致命缺陷。
正常的实验要求流量必须“正交且均匀分布”。然而,该系统采用的是极其简陋的 Hash(DeviceID) % 100 算法来分流。由于哈希碰撞的物理极值分布不均,导致高达 80% 的“高净值且已绑卡的老用户”被错误地分入了 B 组,而 A 组则塞满了“尚未绑卡、转化率极低的新用户”。
这完美触发了 导致数据假象的经典统计学现象科普 中的“辛普森悖论(Simpson’s paradox)” 。辛普森悖论指出,当我们将人群分为多个子群体时,某个变量在每个子群体中都占据优势,但由于子群体的基数分布严重不均,加权合并为大盘总数据时,这个优势反而会消失甚至逆转 。在本次事故中,B 版本之所以在“老客/新客”局部比较中双双获胜,完全是因为其自身原本就更优秀的方案底子,但大盘总转化率的暴跌,揭露了其基数畸变带来的虚假繁荣。
为了彻底消灭流量倾斜的物理假象,技术团队抛弃了原始的弱哈希算法,全面重构了实验分流引擎:
重构分流引擎并重新跑满两个标准的业务周期(14天)后,辛普森假象被彻底戳穿。真实的数据显示,B 版本的支付转化率其实弱于 A 组。团队及时止损并基于真实反馈迭代出了真正的优胜版本 C。当 C 版本通过 95% 显著性检验并全量上线后,收银台的真实支付转化率不仅恢复了健康,更相对原始基线提升了约 18.5%,成功避免了一场因数据失真导致的重大事故。
移动互联网的流量早已不再局限于单一的 App 端内,跨场景的测试与动态寻优正在成为主流。
很多高价值的 AB 测试实际上发生在端外环境。例如,市场部测试两套不同文案的 Web 裂变 H5 海报,看哪套能带来更高的留存。
如果用户在微信里看了海报,随后去应用商店下载 App,常规的 AB 测试工具会因为无法穿透应用商店这座数据孤岛,而丢失分组标签。最终,产品经理根本无法统计这两组用户在 App 内的真实付费 LTV(生命周期价值)。
此时,必须借助类似 渠道效果统计 的全链路归因基建。它通过先进的设备指纹与剪贴板透传技术,将前端 Web 页面的“A/B 分组参数”隐秘地传递给刚刚激活的 App 客户端,从而把端外的点击与端内的转化完美缝合,完成跨端 AB 实验的数据对账闭环。
展望未来,结合 [AI与自动化营销实战](F35 URL占位) 的发展,简单的 A 对比 B 将被多变量测试(MVT,Multivariate Testing)取代-。MVT 允许产品团队同时测试网页上的主图、按钮颜色和标题文案的数十种组合。
结合深度强化学习中的多臂老虎机(Multi-Armed Bandit, MAB)算法,下一代实验系统将不再死板地等待 14 天出结果。它能够在实验进行的过程中,实时计算各组的转化收益,并自动向表现更好的变体倾斜流量(Thompson Sampling 策略),真正实现止损与极速动态寻优的完美平衡。
样本量太小(如日活不足一万)可以做 AB 测试吗?
可以做,但需要极度谨慎。样本量越小,随机波动的噪音就越大,达到统计显著性所需的测试时间就越长。如果你的 App 日活不足一万,建议只测试那些预期能带来“巨大改变”的功能(例如改版前转化率为 5%,预期改版后能跃升到 15%)。如果你只是微调了一个按钮的圆角(预期转化率微调 0.1%),小样本数据可能跑半年都跑不出显著的置信结果
一个 AB 测试通常需要跑多长时间比较科学?
强烈建议至少跑满 1 到 2 个完整的自然业务周期(通常是 7 到 14 天)。绝大多数 App 用户的行为在工作日和周末存在巨大差异(即周末效应)。你不能因为在周一和周二跑了 48 小时,发现 B 组大幅领先就匆忙宣布全量上线。因为 B 组的设计可能恰好只对工作日通勤途中的用户有效,不跑满整个周期,得出的结论就是片面的。
如何判断实验数据是真的有提升,还是随机波动?
千万不要仅凭肉眼对比最终转化率的绝对值(比如 A 是 1.2%,B 是 1.4% 就认为 B 赢了)。必须依赖专业的 AB 测试系统所提供的 P-Value(P值)或置信区间(Confidence Interval)图表。只有当 B 版本置信区间的下限已经稳稳越过 0 轴(即最坏的情况下,B 也比 A 表现好),并且数据趋势在经过至少一周的观察后不再剧烈波动,你才能严谨地宣布实验胜出。
如果发现对照组和实验组的表现完全一样,是否说明分流算法出现了问题?

SKAN 转化值优化如何配置?映射业务事件权重
2026-07-10

OpenAI关停Atlas浏览器?智能体浏览正回流桌面端与扩展层入口
2026-07-10

OpenAI 发布 GPT‑5.6 系列模型?Sol、Terra、Luna 正在重组任务流量
2026-07-10
LingBot-Video开源会改写具身视频路线吗?具身智能世界模型正在以物理正确性为核心演进
2026-07-09

支付宝碰一下用户数破4亿会改写线下入口版图?线下AI触点已重组本地生活服务网络
2026-07-09

Grok 4.5发布会让自动化编程爆发?跨平台智能体调用需要独立追踪
2026-07-09

LingBot-Vision开源能解决空间感知?独立自动化追踪成底线
2026-07-08

GPT-5.6发布获美国商务部批准?独立自动化追踪成底
2026-07-08

Claude后门隐患被工信部通报?独立任务流量追踪成底线
2026-07-08

英伟达路线图遭遇产能质疑?底层算力波动倒逼任务流量精细化
2026-07-07

腾讯减持快手改变流量格局?头部生态解绑考验全渠道统计基建
2026-07-07

全球首例AI Agent勒索攻击曝光?AI完全接管黑客链路将如何颠覆生态
2026-07-06

生数科技发布视频大模型Vidu S1?实时交互技术突破或将彻底颠覆内容引流转化
2026-07-06

苹果首款折叠手机被曝出货量不足?全新屏幕终端形态或将彻底颠覆传统应用生态
2026-07-06

延迟深度链接怎么实现?安装后场景还原与归因技术解析
2026-07-02






















