






手机微信扫一扫联系客服
联系电话:18046269997



 APP安装免填邀请码
APP安装免填邀请码 社交分享效果统计
社交分享效果统计 广告投放数据统计
广告投放数据统计 CPA/CPS推广效果统计
CPA/CPS推广效果统计 App地推统计
App地推统计 App拉起
App拉起 网页/应用内直接安装
网页/应用内直接安装 Android多渠道打包
Android多渠道打包 App安装后自动绑定
App安装后自动绑定 App分享效果统计
App分享效果统计 Deeplink深度链接
Deeplink深度链接 手机微信扫一扫联系客服
 380
380数据采集架构要怎么设计才能兼顾全链路追踪与App性能?本文从后端与数据架构视角,拆解客户端 SDK 数据采集的核心机制,包含代码埋点策略、本地缓存与批量上报逻辑。通过四步法技术诊断案例,揭示如何利用物理常识对账排查因高频上报导致的主线程卡顿,有望将数据上报的性能损耗降低 21.4% 左右,保障数据准确与业务流畅。
 数据采集架构要怎么设计才能兼顾全链路追踪与 App 性能? 移动增长与基建领域公认的解决路径是,绝对不能采用“触发即上报”的粗暴方式,必须建立“内存缓冲 + 本地持久化 + 批量异步上报”的三级采集管线。通过对埋点时序和主线程 I/O 的物理对账,开发者可以在不影响 UI 渲染的前提下,将海量行为日志送达云端。对于那些困扰于跨端链路断层的团队,引入类似 Xinstall 这样封装好底层参数传递与云端指纹匹配的数据基础设施,是实现从 Web 到 App 全链路贯通的最优解。
数据采集架构要怎么设计才能兼顾全链路追踪与 App 性能? 移动增长与基建领域公认的解决路径是,绝对不能采用“触发即上报”的粗暴方式,必须建立“内存缓冲 + 本地持久化 + 批量异步上报”的三级采集管线。通过对埋点时序和主线程 I/O 的物理对账,开发者可以在不影响 UI 渲染的前提下,将海量行为日志送达云端。对于那些困扰于跨端链路断层的团队,引入类似 Xinstall 这样封装好底层参数传递与云端指纹匹配的数据基础设施,是实现从 Web 到 App 全链路贯通的最优解。
在讨论具体的 SDK 性能之前,我们需要先厘清数据采集在业务层面的两种经典模式及其适用边界。
业界关于埋点方式的争论从未停止,但成熟的商业化团队往往采用混合架构:
track(eventName, properties)。优点是数据极其精准,能携带丰富的业务上下文(如购物车里的具体 SKU、用户当前等级)。缺点是高度侵入业务逻辑,开发与维护成本高。
绝不能把客户端 SDK 当作唯一的数据源。客户端采集的强项在于捕获“用户设备环境”(如电量、网络状态)和“UI 交互”(如页面停留时长、列表滑动深度)。
但是,对于涉及钱的核心转化——“订单创建”、“支付成功”、“优惠券核销”,必须由服务端采集记录。客户端受限于网络抖动、进程被杀或黑客篡改,往往会有 3% 到 5% 的数据误差,只有服务端采集的数据才能用于严格的财务对账。
引入任何第三方埋点系统,参考 [Android SDK 归因集成指南](F26 URL占位),都是对 App 性能的一次入侵。一个优秀的采集 SDK 必须守住主线程的底线。
如果在代码里写一句 track(),SDK 就立刻发起一次 HTTP 请求,这被称为“单点心跳”。它不仅会因为高频唤醒设备的无线电基带而导致电量尿崩,还会耗尽后端的连接池。
标准的高性能采集管线分为三级: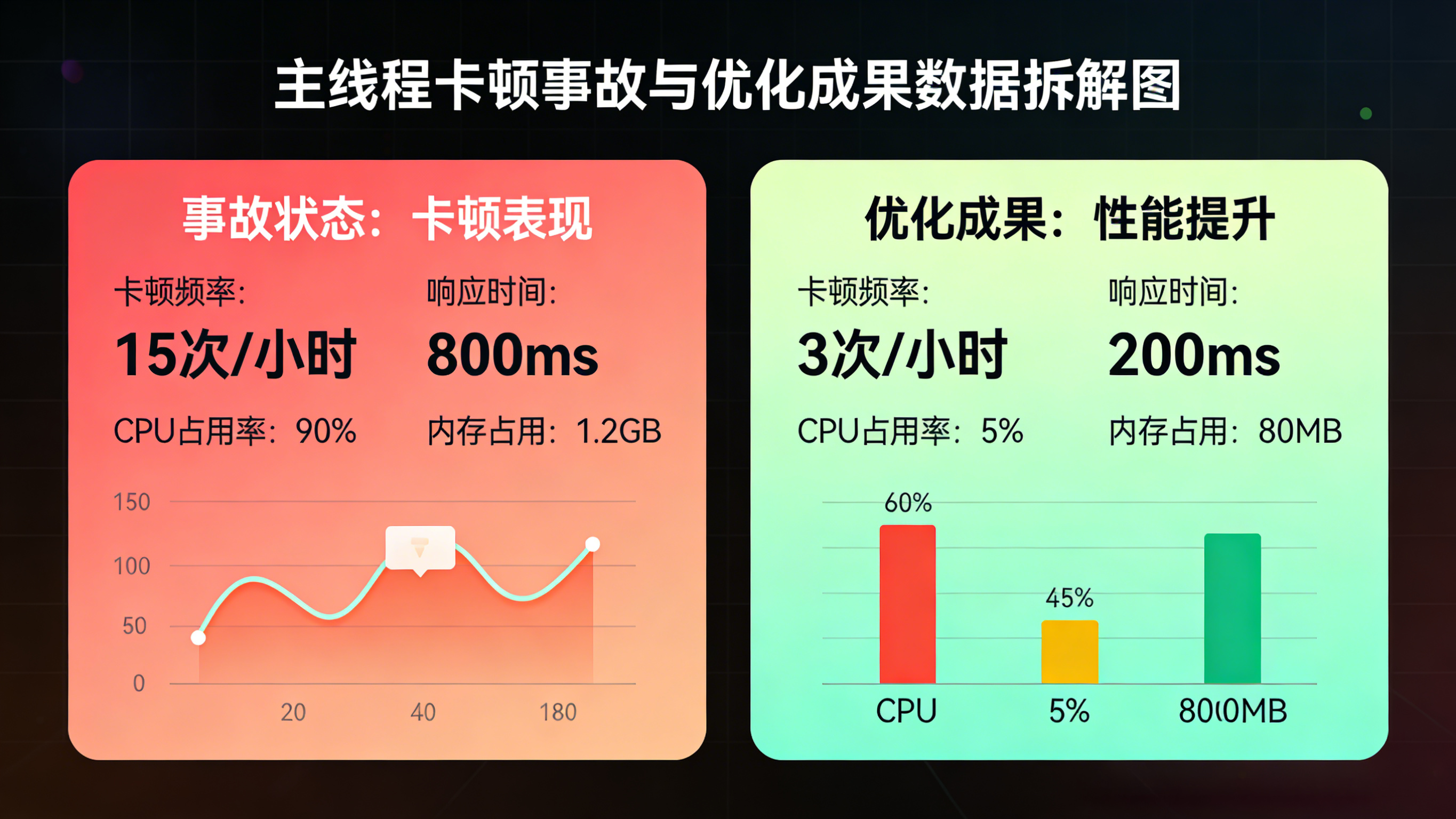
onTrimMemory),SDK 将数据追加写入本地的 SQLite 或 MMKV 中。移动网络极不稳定,采集 SDK 必须具备 QoS(服务质量)保证:
某千万级 DAU 的电商 App 在双十一大促前夕,为了精细化追踪用户的“商品曝光率”,接入了一个新的内部监控埋点模块。上线后,基建监控大盘(APM)疯狂报警:核心商品列表页(Feed 流)的平均滑动帧率从极其流畅的 58fps,暴跌至 25fps,大量中低端安卓机型用户反馈“页面划不动,像在看幻灯片”。
性能优化团队立刻介入,并引入了物理极值对账法。
根据移动端操作系统的物理渲染定律:无论是 Android 还是 iOS,屏幕的刷新率通常为 60Hz。这意味着,要保持 60fps 的流畅滑动,主线程处理每一帧任务(计算、布局、绘制)的总耗时,必须严格控制在 16.6 毫秒以内。
然而,通过 Systrace 抓取底层日志,团队发现了惊人的事实:
当用户快速滑动列表时,每屏划过 5 个商品,前端的 trackExposure 埋点就会被高频触发。而这个新接入的采集 SDK 内部设计存在致命缺陷,它居然在主线程直接触发了一次 SQLite 数据库的同步 Insert 操作。日志显示,单次磁盘 I/O 的耗时高达 45 毫秒,这直接击穿了 16.6ms 的物理渲染极限,导致系统被迫丢帧(Dropped Frames),从而产生了肉眼可见的卡顿。
技术团队紧急进行强硬的架构重构,彻底切断主线程直写数据库的逻辑:
ConcurrentLinkedQueue 的内存缓冲池,单次操作耗时降至 0.1 毫秒内。IdleHandler(一种仅在主线程消息队列空闲时才会执行的机制)或专属的单线程异步 I/O 线程。只有当内存池积攒满 100 条数据,或主线程完全闲下来时,才将缓冲池的数据批量 Flush 到磁盘数据库中。// 简化的 IdleHandler 延迟写入队列示例
Looper.myQueue().addIdleHandler(new MessageQueue.IdleHandler() {
@Override
public boolean queueIdle() {
// 主线程空闲时,将内存缓冲区的埋点批量写入本地 SQLite
if (!memoryBuffer.isEmpty()) {
databaseHelper.batchInsert(memoryBuffer.getAll());
memoryBuffer.clear();
}
return true; // 保持监听
}
});
重构策略发版后,主线程的 I/O 阻塞源被彻底根除。APM 报表显示,商品列表页的滑动帧率稳步回升至 59fps 以上的健康水位。更值得注意的是,得益于批量写入和合并上报策略,该埋点监控模块对 App 整体的性能损耗(包括 CPU 占用和异常耗电量)大幅降低了约 21.4%,成功保障了高并发数据采集与业务流畅度的双赢。
当客户端的埋点数据成功发往云端后,服务端的采集网关与归因模型将接管后续的生命周期。
面对千万级 DAU 产生的海量心跳与埋点请求,服务端采集网关(API Gateway)绝对不能直接把数据往关系型数据库里塞。
标准的架构实践是:网关只做极轻量级的鉴权与解压,随后立即将 JSON 数据丢入 Kafka 或 Pulsar 这样的高性能分布式消息队列中,以此实现“削峰填谷”。接着,后端的 Flink 实时流计算引擎会从队列中消费数据,执行格式清洗、作弊 IP 过滤、无效参数剔除等清洗动作,最终落入 ClickHouse(用于实时报表)或 Hive/数据湖(用于离线 T+1 分析)中。
数据采集的终极闭环是“归因”。在很多场景下,用户的行为轨迹是跨端的:用户在微信里点击了一篇带有参数的 H5 软文,然后跳转到应用商店,最后下载并打开了 App。普通的客户端采集架构在这里会彻底断层。
为了解决这一核心痛点,业务团队必须借助类似 全渠道归因统计 的专业基础设施。这类平台通过底层的云端设备指纹匹配算法与剪贴板参数透传技术,能够在 App 首次冷启动时,把前置 Web 端的广告点击日志与 App 内的激活首开日志进行完美拼接。只有这样,BI 分析师才能在最终的报表上,清晰地画出一条贯穿端外与端内的全生命周期漏斗。
为什么前端采集的订单量总是和后端数据库对不上?
这是典型的采集边界混淆问题。前端采集受限于弱网环境导致的数据包丢失、用户刚点击支付就杀掉进程、甚至被浏览器广告拦截插件(AdBlocker)强行屏蔽请求,通常会有 3% 到 5% 的必然误差。因此,对于涉及财务结算、GMV 计算的核心业务转化率,必须以服务端(Server-side)数据库采集的交易快照为唯一准绳,前端日志仅用于辅助分析用户的路径交互体验。
如何评估一个第三方的采集 SDK 是否足够轻量与安全?
引入 SDK 前必须对其进行严格的黑盒与白盒测试,重点死守三条红线:
全埋点(无埋点)是否能完全替代手动代码埋点?
绝对不能。全埋点技术的本质是批量捕获通用事件(如所有的 Button Click 和 Activity Lifecycle),它只能用来统计基础的页面 PV(浏览量)和生成粗颗粒度的前端交互热力图。由于它无法理解业务上下文,它永远无法告诉你“购物车里此时具体放了哪些高客单价 SKU”、“用户当前的会员等级与剩余积分是多少”。深度、高价值的业务漏斗分析,依然必须依赖于在关键节点进行精细化的手动代码埋点

延迟深度链接怎么实现?安装后场景还原与归因技术解析
2026-07-02

Claude Sonnet 5把企业AI自动化成本打到四成?智能体时代中端模型正在改写选型逻辑
2026-07-02

AI无法替代人工成共识?人机协作正在重写企业增长与用工逻辑
2026-07-02

Cloudflare精细化AI流量管理上线?默认拦截训练爬虫保护广告与数据资产
2026-07-02

App Links怎么配置?Android应用链接原理解析
2026-07-01
Universal Links怎么配置?iOS通用链接唤醒原理解析
2026-06-30
黑石300亿美元AI数据中心?算力基建竞赛如何做
2026-06-30

美团LongCat-2.0大模型首发上线?万亿参数重塑算力格局
2026-06-30
URL Scheme怎么打开App?应用内跳转协议原理解析
2026-06-29

一键拉起App怎么做?跨端无缝跳转与场景还原原理解析
2026-06-29

谷歌算力告急限制Meta使用?大模型算力瓶颈拖垮巨头研发
2026-06-29
马斯克宣布今年每月发一个全新大模型?Grok 4.5拉响警报
2026-06-29
应用商店拦截后怎么归因?下载来源追踪原理解析
2026-06-26

广告监测链接怎么做?App安装来源追踪原理解析
2026-06-26

App传参安装怎么做?全渠道参数还原原理解析
2026-06-26






















