






手机微信扫一扫联系客服
联系电话:18046269997



 APP安装免填邀请码
APP安装免填邀请码 社交分享效果统计
社交分享效果统计 广告投放数据统计
广告投放数据统计 CPA/CPS推广效果统计
CPA/CPS推广效果统计 App地推统计
App地推统计 App拉起
App拉起 网页/应用内直接安装
网页/应用内直接安装 Android多渠道打包
Android多渠道打包 App安装后自动绑定
App安装后自动绑定 App分享效果统计
App分享效果统计 Deeplink深度链接
Deeplink深度链接 手机微信扫一扫联系客服
 183
183AI 训练与推理集群正把数据中心光纤需求推向新高,相关材料显示 2025 年该领域需求同比增长约 76%,大批量采购交货周期已拉长到 20 周以上;这不只是上游材料涨价,更是开发者、增长团队和 B 端平台必须重新理解“算力背后网络瓶颈”的信号。
AI 的算力竞赛还在继续,但很多团队最近才意识到,真正开始变贵、变慢、变紧张的,不只是 GPU。随着 AI 训练和推理集群对高密度互联的要求不断上升,【AI基础设施】正在把光纤这种过去相对“低调”的底层材料推到前台。对普通人来说,这像是一条上游产业快讯;对开发者、产品经理和增长团队来说,这其实是在提醒:如果连接层开始紧张,未来云服务、应用响应、任务稳定性乃至流量分发方式,都可能被重新改写。
过去几年大家谈 AI,最容易把注意力放在模型、芯片和云厂商资本开支上。但这次光纤涨价与交付拉长说明,AI 基础设施的瓶颈已经从算力本身扩散到了“把算力连起来”的网络层。一个更现实的问题摆在所有 App 和 B 端团队面前:当底层互联资源开始被 AI 数据中心大量锁定,谁还能稳定拿到高质量连接,谁的服务链路又会先出现隐形拥堵?这正是【AI基础设施】新闻背后,更值得被看见的那一层。
从材料来看,这一轮供需紧张的核心原因非常直接:AI 训练和推理集群需要比传统云基础设施更密集的互联架构,因此用于数据传输的光纤开始出现明显供不应求。相关数据提到,2025 年数据中心光纤需求同比增长约 76%,到 2027 年,这一领域预计将占全球光纤总需求的 30%,而在 2024 年这一占比还不到 5%。
这组数字的冲击力非常强,因为它说明数据中心场景对光纤的消耗,已经不是“增长”而是“改写结构”。不到几年的时间里,一个过去只占小头的应用方向,突然要拿走接近三分之一的全球需求。它带来的后果,不只是某个行业采购更难,而是整个光纤市场的供给逻辑开始向 AI 倾斜。
换句话说,AI 正在把光纤从通信行业的基础耗材,变成算力时代的核心战略物资。以前大家理解数据中心扩建,多半会想到服务器、交换机、芯片和机柜;现在必须加上一项同样关键的东西:谁能把这些机器高密度、高速率、低延迟地连起来。没有这一层,再强的算力堆积起来也很难真正转化为可用能力。
这也是为什么这条新闻值得被当成【AI基础设施】来看,而不是一条普通原材料行情。它说明 AI 竞争已经进入更深的底层阶段,开始挤占那些过去不太被公众注意、但对整个系统性能至关重要的基础环节。
如果只是需求变高,市场理论上总能靠扩产慢慢追上。问题在于,光纤的供应侧并没有那么灵活。材料提到,光纤预制棒的制造工艺技术要求极高,行业通常需要 18 到 24 个月才能完成新的预制棒投产程序,这让供给扩张天然存在显著滞后。
这意味着,光纤不是那种“需求一热,半年就能补上”的产品。它有很高的制造门槛、产线建设难度和技术准入要求。对于厂商来说,哪怕已经看见数据中心订单在加速涌来,也很难立刻通过简单扩产把缺口补平。供给追不上需求,不一定因为大家反应慢,而是因为物理世界的制造周期就是这么长。
正因为扩产慢、需求急,厂商才会优先把有限产能分给利润更高的数据中心用光纤。这又带来第二层影响:传统电信级光纤供应变得更紧,整体价格进一步被抬高。材料显示,全球光纤价格已经从 2021 年低点的 3.70 美元/公里上涨约 70%,达到约 6.30 美元/公里。
这里最值得注意的,不只是“价格涨了”,而是涨价发生在供给结构被重新分配的背景下。也就是说,AI 数据中心不是简单增加了一部分新需求,而是在重新定义什么样的订单更优先、什么样的连接需求更值钱。只要这种结构性倾斜持续存在,【AI基础设施】相关的网络资源就会越来越像一种分层配置品,而不是人人都能平等获取的标准化底座。
更具体的信号来自交付周期。材料显示,北美光纤需求今年预计增长 22%到 25%,但供应增长只有 12%到 19%;大批量买家的交货周期已经延长至 20 周,小批量买家甚至可能等上一年。
20 周是什么概念?对很多互联网和企业服务团队来说,这已经不是“采购慢一点”,而是会直接影响整条建设计划。一个 AI 数据中心要上线,不是只有机房和算力设备到位就行,高速互联是最关键的底层条件之一。交货期被拉长,意味着项目排期要变,现金流节奏要变,容量上线时间也要变。
对小买家来说,这个问题更尖锐。大厂可以签长期合同、锁定产能、提前预订;中小客户和边缘需求方则很容易被挤到后面。也就是说,未来不是所有企业都能以差不多的速度搭起 AI 基础设施,而是谁有更强的供应链议价能力,谁更容易拿到连接资源。这种变化会直接放大头部企业与一般企业之间的基础设施差距。
如果把它继续往下推,对上层应用的影响也会开始显现。某些企业的 AI 服务上线会更快,某些区域的数据中心部署会更密,某些平台的响应、推理和并发承载会更稳;反过来,一些资源较弱的平台可能会在底层网络上先吃到瓶颈。这也是为什么这条新闻并不只属于上游制造业,它最终会渗透到 App 可用性、服务时延和任务完成率上。
真正说明问题严重程度的,不是分析师报告,而是头部公司的采购动作。公开信息显示,Meta 在今年 1 月与康宁达成一项多年期、最高可达 60 亿美元的协议,用于为其数据中心供应光纤、光缆和连接解决方案。为了支持这项合作,康宁还将扩大其在北卡罗来纳州的制造能力,Meta 则充当锚定客户。Meta 与 Corning 的协议说明
这说明什么?说明 Meta 已经不满足于在市场里“正常下单”,而是开始通过长期合同去锁定未来几年产能。这种动作通常只会发生在两种情况下:一是资源极其关键,二是大家都担心未来更难买。无论哪一种,都证明光纤在 AI 数据中心体系中的地位已经明显上升。
英伟达的动作也很说明问题。公开资料显示,英伟达与康宁宣布长期合作,推动在美国扩建三座先进光学制造设施,布局北卡罗来纳州和德克萨斯州,用于满足下一代 AI 基础设施对先进光连接方案的需求。NVIDIA 与 Corning 合作公告 多家报道还提到,相关投资规模达到数亿美元,并明确面向美国本土光纤制造扩张。
这类动作有一个很重要的信号意义:头部企业已经不再把光纤当成普通配套,而是把它当成需要前置锁定的战略资源。过去大家抢的是 GPU 配额,现在连连接层也开始被“预定”。从产业演进看,这通常意味着一个环节已经从成本项转变为瓶颈项。
材料里还有一个容易被忽略、但非常值得注意的细节:光纤不仅被广泛应用于 AI 数据中心,也在无人机等场景中被大量使用。由于无人机在现代地缘冲突中的高频应用,光纤甚至开始带有某种“战略资源”色彩。材料援引的案例提到,战场上使用的 50 公里光纤电缆,价格已经从过去的 300 美元上涨到 2500 美元。
这说明光纤需求并不是单一来源驱动,而是正被多个高优先级场景同时拉动:AI 数据中心、传统通信网络、军事与无人系统、工业连接等都在争夺同一种底层资源。只要多个场景同时提升优先级,价格和交付就很难快速回落。
这种多场景竞争很值得开发者和 B 端团队关注。因为它意味着,未来连接资源的紧张未必会随着某一个行业增速回落而立刻缓解。只要 AI 和其他高价值场景继续扩张,光纤就会维持在更高的战略位置。对于【AI基础设施】来说,网络层的供需矛盾很可能不是一阵风,而是一段持续数年的结构性变化。

表面上看,这条新闻讲的是光纤涨价、交付延长、供需紧张,很像上游行业资讯。但如果你是 App 开发者、产品经理或增长负责人,真正应该关注的不是每公里光纤涨了多少,而是底层连接资源一旦紧张,最终会怎样传导到用户路径。
在今天的大多数互联网产品里,团队往往默认网络是“始终可用”的,区别只是成本和带宽大小。但在 AI 服务越来越依赖高密度数据中心互联的前提下,网络层开始从透明底座变成性能约束。也就是说,用户虽然看不到光纤,却可能会在另一个地方感受到它:调用更慢、任务排队更久、AI 响应更不稳定、跨区服务时延更高,甚至在某些高峰时段出现更明显的失败与重试。
这会直接影响用户从“被触达”到“完成任务”的真实链路。过去一条路径可能是:用户看到入口、点击进入、安装 App、注册、调用 AI 能力、完成任务。以后这条链路里间接多了一层新的不确定性:底层连接和算力网络是否稳定承接了这次请求。对于团队来说,这就不再是单纯的产品问题,而是【AI基础设施】开始进入体验问题。
一旦底层网络层变得更紧张,传统归因和埋点体系就很容易出错。因为绝大多数系统今天更擅长记录“前端行为”,比如点击、下载、安装、激活、留存,却不擅长解释“为什么用户在中途掉了”“为什么这一批 AI 任务完成率突然下降”“为什么同样的入口在不同区域表现完全不同”。
如果没有把基础设施视角纳入观察,团队很容易把底层网络约束误读成运营异常。比如:
这种误判的后果很现实。你可能会去改素材、调投放、换落地页、重做引导流程,结果真正的问题根本不在前面,而在更深的服务链路里。对增长团队来说,最怕的不是指标变差,而是找错原因。AI 基础设施一旦开始影响体验,归因系统就必须更往下看,而不能只盯着最后几步页面动作。
这类新闻之所以和 App 业务相关,是因为 AI 产品的核心价值越来越不只是“用户打开了”,而是“任务有没有真正跑完”。尤其在 Agent、深度研究、推理问答、企业流程自动化这些场景里,用户的满意度并不取决于是否进入 App,而取决于一次调用是否被稳定承接、是否按预期执行、是否在合理时间内返回结果。
这会带来一个重要变化:未来很多产品必须把“成功调用”当成和“安装成功”“注册成功”一样重要的关键事件。因为如果调用失败率变高、排队时间变长、跨区域延迟上升,用户并不会区分这是网络层问题、算力调度问题还是产品问题,他们只会认为“这个 App 不稳定”。
也正因为如此,AI 基础设施不再只是 CTO 或云架构团队的议题,它正在进入增长、转化和留存视角。你能不能看清一次高价值任务到底死在入口、死在首启、死在调用、还是死在底层承接能力上,将决定你接下来是优化产品,还是该先优化链路。
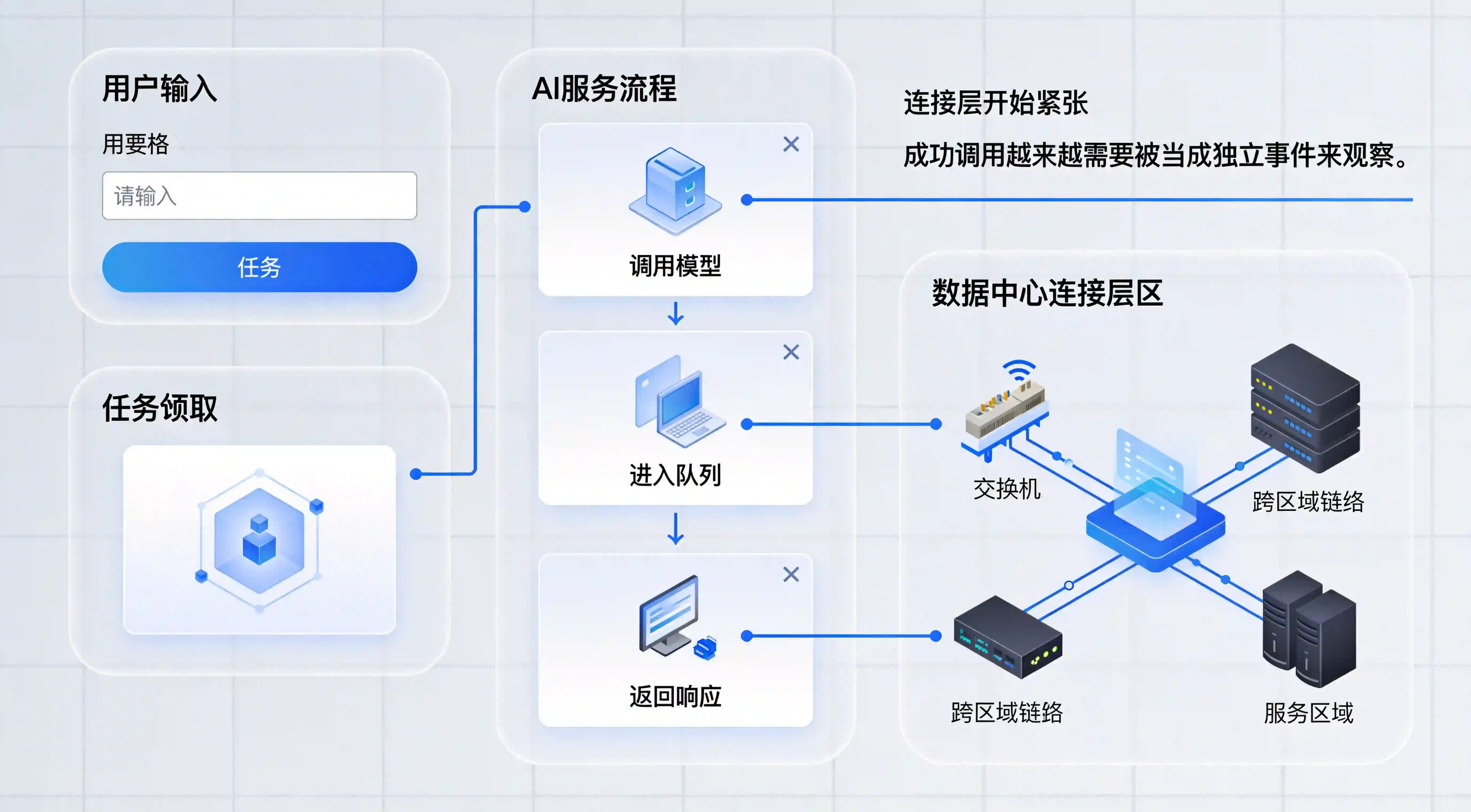
面对基础设施波动带来的链路变化,第一步不是急着上复杂模型,而是先把入口识别做清楚。很多团队现在的问题是,所有 AI 相关新增都被统一算成“自然流量”或“站内转化”,结果后面根本看不出哪些入口带来了高价值用户,哪些入口带来了高成本请求,哪些入口对底层服务压力最大。
更稳妥的做法,是先使用 渠道编号 ChannelCode 这种统一入口标识思路,把不同场景拆开。比如内容入口、广告入口、私域入口、Agent 调用入口、合作平台入口,都应该有自己的可识别编号。只有先把入口拆开,你才能继续分析:到底是哪一类流量更依赖重度 AI 调用,哪一类流量更容易在基础设施拥堵时掉链子。
在【AI基础设施】越来越紧张的情况下,这一步尤其重要。因为未来并不是所有流量都值得被同样对待。有些入口带来的只是阅读型用户,有些入口带来的是会连续调用模型、占用更多连接和算力资源的任务型用户。如果入口不区分,后续所有资源调度和增长判断都会很粗糙。
第二步,是把用户或任务的上下文保留下来。对于 AI 产品来说,用户来的时候往往已经带着明确目的:问答、生成、编码、研究、审校、自动化处理等。若这些上下文在跳转、安装、首启过程中丢失,App 就很难做更聪明的承接,也更难判断哪类场景在消耗更多基础设施资源。
这也是为什么 智能传参 在 AI 产品链路里越来越重要。它不是简单地把一个邀请码带进来,而是把场景、来源、意图和任务状态一起传过来。对于这类场景,至少可以考虑保留这些字段:
scenechannelCodetask_typesource_platformservice_regionrisk_level当这些上下文被保留下来后,团队就能更准确地看出:哪些区域的请求更容易超时,哪些任务类型更容易重试,哪些来源的用户对时延更敏感。对于以模型调用为核心的产品来说,这种信息会比单纯知道“新用户来自哪里”更有价值。
在实现方法上,也可以参考 xinstall 在《亚马逊 AI 战略升级?多云多 Agent 时代 App 该怎么认清流量真身》和《智能体分发时代 App 安装传参逻辑的底层重构》里讨论的思路:先把入口身份建立起来,再把任务语境沿链路带进去,最后在 App 内恢复并使用它们。这样做的本质,是把“谁来的”升级为“为什么来的、带着什么任务来的”。
第三步,是不要再只看“有没有转化”,而要开始看任务过程。对于 AI 产品,尤其是和推理、生成、Agent 执行相关的产品,很多关键损耗不发生在安装前,而发生在安装后和调用中。如果系统里没有事件图,团队就很难判断瓶颈到底在哪。
更适合的做法,是构建一张覆盖入口、安装、调用、结果返回的任务事件图,例如:
link_openedapp_installedfirst_launchtask_startedqueue_enteredmodel_calledresponse_returnedtask_completedtask_failed_retry有了这张图,团队才有机会把基础设施信号和增长信号放在同一张地图里。比如你可以看见:某个渠道带来的用户首启率很高,但在 model_called 到 response_returned 之间大量流失;某个区域注册转化不差,但 task_completed 明显偏低。这时候你就知道,问题不在拉新,而在服务承接。
注:本文讨论的跨平台任务识别、区域级承接分析、任务事件图与复杂 AI 服务链路治理,属于面向未来分发趋势的工程设计思路与前瞻性技术延展。目前其中不少场景仍需结合具体业务架构、云资源部署与数据中台体系做专项适配,并不等同于统一标准化现成功能。
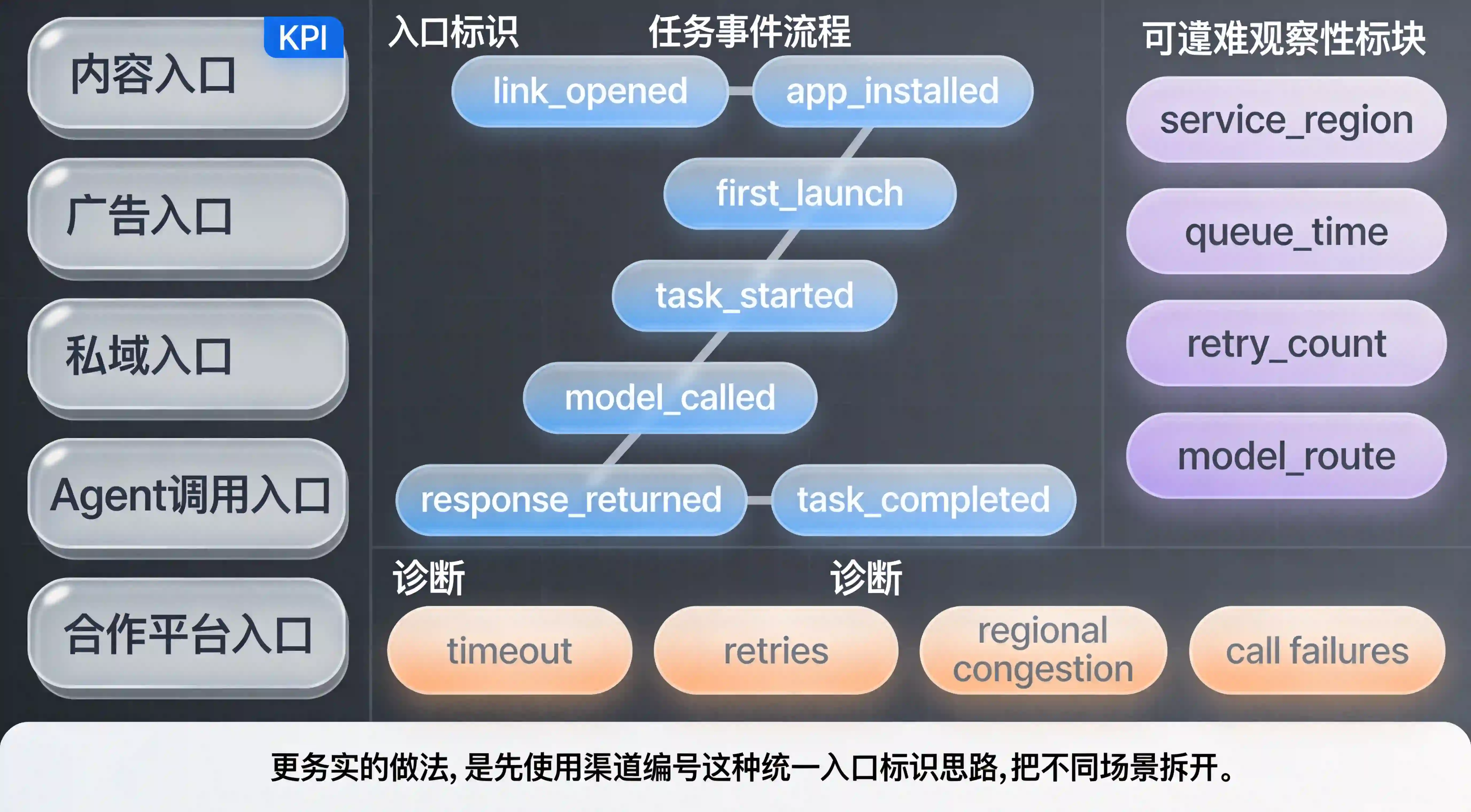
如果你是研发或架构负责人,这条新闻最值得带走的不是“光纤价格涨了”,而是连接层正在变成 AI 服务稳定性的隐形上限。以前很多系统会重点埋用户操作,却不记录任务排队、服务区域、请求重试、返回时延这些过程数据。未来如果继续缺失这些字段,团队看到的就只会是模糊的成功率波动。
更务实的做法,是从现在开始预留一批与任务执行和基础设施承接相关的字段,例如:
service_regionqueue_timeretry_counttask_typechannelCodemodel_route这些字段不一定一开始就全部用上,但它们会在【AI基础设施】约束变强时,成为解释业务波动的关键证据。
如果你是产品或增长负责人,这件事最大的变化在于:未来很多业务波动不再只由素材、投放、版本和转化文案决定,底层承接能力也会越来越强地参与结果形成。也就是说,你不能只盯前端入口,也要开始盯“入口之后那条看不见的服务链”。
现在就可以做几件事:
这样做的意义,是把“流量来了没”升级成“流量来了以后有没有被稳定接住”。在 AI 产品时代,这两件事会越来越不是同一个问题。
因为 AI 训练和推理集群需要更高密度、更高带宽、更低时延的互联结构,服务器之间要交换的数据量远大于传统云场景。算力节点越多,互联需求就越强,光纤自然会被更快消耗。
因为供给扩张速度跟不上需求扩张速度。光纤预制棒扩产周期长、技术门槛高,而数据中心需求增长又非常快,供给侧很难在短时间内补齐缺口,所以价格和交期都更容易持续处于高位。
因为对头部公司来说,光纤已经不再是普通采购项,而是 AI 基础设施能否按计划扩张的关键资源。签长期合同、投资制造能力,本质上是在提前锁住未来几年的连接能力,避免在需求高峰期被动排队。
会,但通常不是以“你看见光纤短缺”的方式体现,而是通过服务体验间接显现。比如 AI 功能响应变慢、任务更容易排队、某些区域服务不够稳定,甚至同一功能在不同时间段表现差异更大。这些现象的背后,可能就有基础设施承接能力变化的影子。
这次光纤价格上涨和交付拉长,表面上是上游制造业的供需新闻,实质上却是 AI 产业进入深水区的标志之一:竞争不再只发生在模型参数和 GPU 数量上,而是开始蔓延到连接层、制造层和供应链层。谁能拿到更稳定的互联资源,谁就更有机会把算力真正变成服务能力。
对 App 与 B 端团队来说,这条新闻最重要的提醒不是“上游又涨价了”,而是未来越来越多业务波动,都会同时受到流量质量和底层承接能力的双重影响。现在正是重构数据与归因体系的窗口期:从入口编号、场景透传到任务事件图,都要尽早补起来。因为当【AI基础设施】真的开始决定用户能否顺利完成任务时,解释权就不会再只属于投放后台和产品漏斗,而会属于那些能看清整条链路的人。

AI无法替代人工成共识?人机协作正在重写企业增长与用工逻辑
2026-07-02

Cloudflare精细化AI流量管理上线?默认拦截训练爬虫保护广告与数据资产
2026-07-02

App Links怎么配置?Android应用链接原理解析
2026-07-01
Universal Links怎么配置?iOS通用链接唤醒原理解析
2026-06-30
黑石300亿美元AI数据中心?算力基建竞赛如何做
2026-06-30

美团LongCat-2.0大模型首发上线?万亿参数重塑算力格局
2026-06-30
URL Scheme怎么打开App?应用内跳转协议原理解析
2026-06-29

一键拉起App怎么做?跨端无缝跳转与场景还原原理解析
2026-06-29

谷歌算力告急限制Meta使用?大模型算力瓶颈拖垮巨头研发
2026-06-29
马斯克宣布今年每月发一个全新大模型?Grok 4.5拉响警报
2026-06-29
应用商店拦截后怎么归因?下载来源追踪原理解析
2026-06-26

广告监测链接怎么做?App安装来源追踪原理解析
2026-06-26

App传参安装怎么做?全渠道参数还原原理解析
2026-06-26

谷歌重组AI编程小组?追赶Anthropic的节奏被迫加速
2026-06-26
科大讯飞AI招采平台2.0如何重构流程?招投标开始进入全链路智能化
2026-06-26






















