






手机微信扫一扫联系客服
联系电话:18046269997



 APP安装免填邀请码
APP安装免填邀请码 社交分享效果统计
社交分享效果统计 广告投放数据统计
广告投放数据统计 CPA/CPS推广效果统计
CPA/CPS推广效果统计 App地推统计
App地推统计 App拉起
App拉起 网页/应用内直接安装
网页/应用内直接安装 Android多渠道打包
Android多渠道打包 App安装后自动绑定
App安装后自动绑定 App分享效果统计
App分享效果统计 Deeplink深度链接
Deeplink深度链接 手机微信扫一扫联系客服
 232
232微软推出Critique与Council多模型协同系统,标志着AI应用从“单一对话”走向“复合Agent协同”。当App的服务接口被不同模型碎片化调用,开发者如何利用ChannelCode与参数还原技术,追踪多级调用的任务流量并评估真实转化?
 2026年3月底,微软为其 Copilot 助手推出了两项突破性的人工智能功能:Critique(多模态深度研究系统)与 Council(多模型并发裁决系统)。
2026年3月底,微软为其 Copilot 助手推出了两项突破性的人工智能功能:Critique(多模态深度研究系统)与 Council(多模型并发裁决系统)。
这两项功能最大的变革在于,它们打破了“单一模型处理单一任务”的局限。以 Critique 为例,它采用双模型协同架构:第一个模型(如 OpenAI 的 GPT)负责生成内容和初稿,第二个模型(如 Anthropic 的 Claude 或微软自研的 Phi)则扮演“评审员”,专门负责核查事实和逻辑。而 Council 系统更是能同时运行多个不同厂商的模型,并由一个独立的评判模型来汇总和纠偏。
这种“让 AI 监督 AI、让模型协作模型”的范式跃迁,旨在解决困扰行业已久的大模型“幻觉”问题。但对于广大的第三方 App 开发者和 SaaS 服务商而言,这种“复合 Agent”架构的普及,带来了一个极为棘手的增长挑战:当你的应用 API 和服务被多个智能体交叉调用时,你还能分清流量的真正来源和用户意图吗?
在过去,应用的流量入口相对单一(比如用户直接打开 App 或点击网页)。而在单模型 Agent 时代,虽然变成了“用户对 AI 说话,AI 调你的接口”,但至少路径是单向的。
随着微软多模型协同架构的落地,未来的场景会变得极其碎片化和复杂。例如,用户要求系统做一份深度旅游攻略并完成预订:
在这个过程中,如果缺乏底层的追踪基建,App 开发者在后台看到的只是一堆杂乱无章的 API 调用记录(Task Traffic)。由于调用被“切碎”分发给了不同的模型节点,开发者根本无法把这些独立的参数请求追溯回最初那个“准备旅游的用户”,更无法核算各个模型入口所带来的真实 ROI(投资回报率)。
注:本文探讨的针对多智能体(Agent)任务流量追踪的技术方案,旨在帮助 App 开发者与 SaaS 平台在复杂的 AI 调度网络中实现意图留存与精准归因。如果您的团队正面临 API 被频繁机器调用但转化不明、多端流量数据割裂等痛点,欢迎联系 Xinstall 客服团队获取专属的技术支持。
面对多模型协作带来的“流量黑盒”,开发者必须重构底层追踪逻辑,利用专业的分发基建建立跨生态的可观测性。
利用 ChannelCode 统一调度标识
面对来自 OpenAI、Claude 或是微软底层路由的不同调用,开发者不能再用一套通用的 OpenAPI 密钥打天下。必须利用如 Xinstall 全渠道统计 技术,为每一个接入的模型接口或 Agent 工作流分配专属的动态 ChannelCode(渠道编号)。
通过在网关层强制校验该标识,后台能自动剥离出自然人操作和机器“任务流量”,让你清晰看到:到底是模型 A 带来的订单转化率高,还是模型 B 纯粹只是在做低价值的数据抓取。
参数还原技术打通“意图流断层”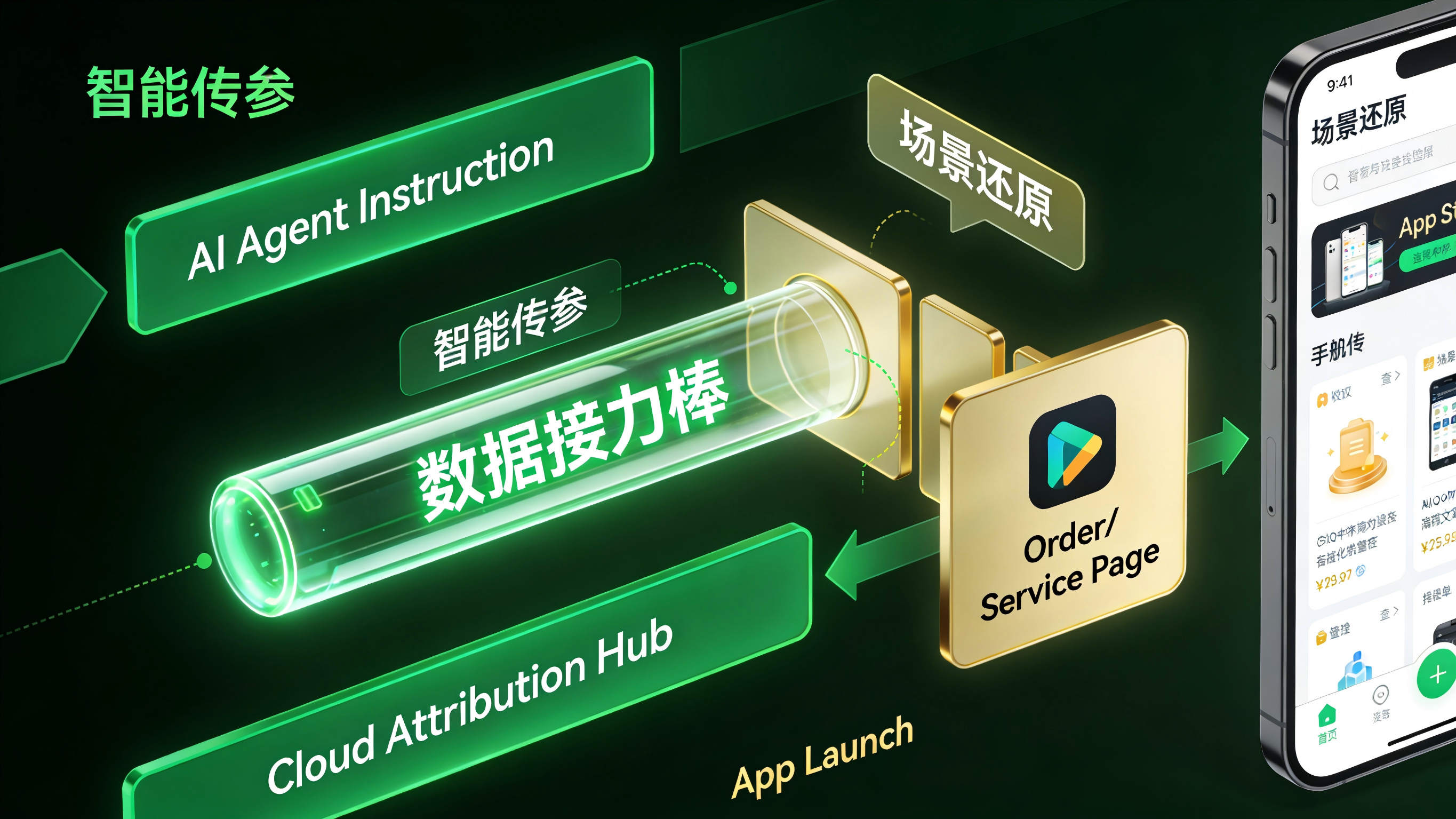
为了避免用户意图在多模型交接中丢失(即上下文溢出或断裂),App 的底层设计需要引入“意图流追踪”。
当首个模型触发操作时,利用参数还原算法在云端暂存一个全局唯一的 Task_ID 与核心业务参数(如用户的搜索条件)。当后续模型接力,或者最终用户被唤起打开原生 App 进行履约时,系统能够通过多维环境特征匹配,将暂存的意图参数自动下发并还原。
这样,无论工作流被拆解得多碎,归因后台都能将其串联归一,还原出一幅完整的“跨 Agent 转化图谱”。
避免依赖前端沙箱的弱追踪
在复合 Agent 时代,前端运行环境变化莫测。开发者应放弃依赖传统的剪贴板或脆弱的本地 Cookie 传参。拥抱基于服务端的云端加密匹配体系,能够有效避开各家模型沙箱的干扰,甚至实现“跨生态唤醒 + 免填邀请码”的高级增长策略。
面向底层开发团队:
model_source、workflow_id 等)。将传参解析的逻辑交由成熟的第三方中间件处理,从而实现业务逻辑与归因逻辑的解耦。面向产品 / 商业化团队:
如果多个模型并发请求我的接口,系统还能准确归因到最初的用户吗?
只要在最初的唤醒协议或多模态交互入口中植入了带有特征标签的 ChannelCode,并通过云端参数暂存机制绑定了意图 Session,即使后续有并发调用,系统也能凭借高效的匹配算法将它们汇聚到同一个用户生命周期路径下。
引入针对Agent流量的归因机制,会大幅增加研发部门的维护成本吗?
不会。成熟的全链路参数还原机制基本已经组件化,它通过旁路日志上报和轻量级的参数拼接来实现,与 App 的核心业务逻辑是解耦的。接入成熟的 SDK,反而能省去后期在多套复杂大模型系统中扯皮排错的时间。
微软 Critique 和 Council 的发布,宣告了 AI 从“单打独斗”正式迈入“多兵种联合作战”的新纪元。未来,用户的任务将越来越多地被不同的大模型在后台“切块外包”。
对于应用开发者而言,谁能在流量变得彻底碎片化之前,率先建立起跨终端、多 Agent 的全链路参数追踪体系,谁就能在这场 AI 分发范式的剧变中看清流量的真身,把控住真正的商业命脉。
URL Scheme怎么打开App?应用内跳转协议原理解析
2026-06-29

一键拉起App怎么做?跨端无缝跳转与场景还原原理解析
2026-06-29

谷歌算力告急限制Meta使用?大模型算力瓶颈拖垮巨头研发
2026-06-29
马斯克宣布今年每月发一个全新大模型?Grok 4.5拉响警报
2026-06-29
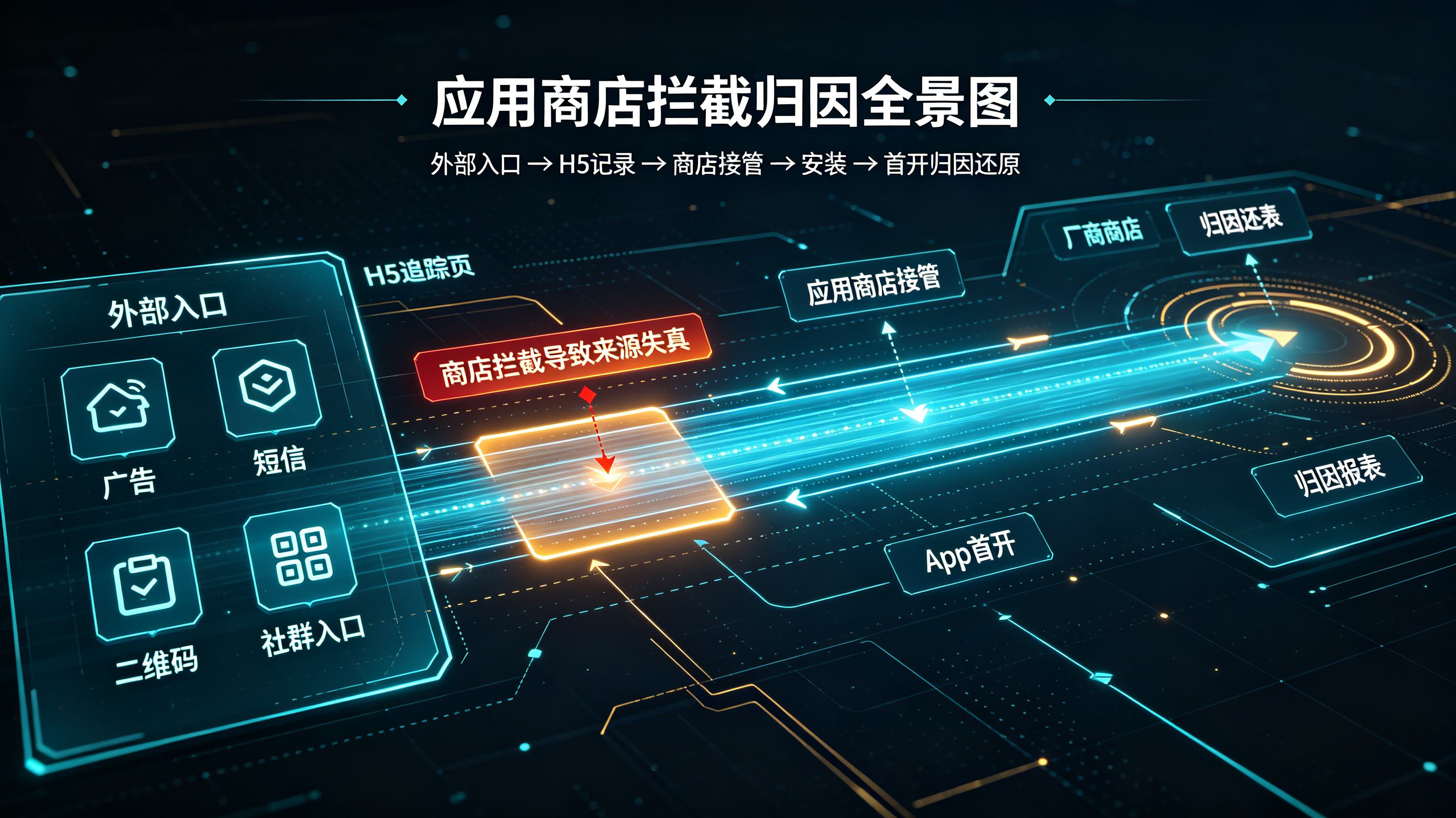
应用商店拦截后怎么归因?下载来源追踪原理解析
2026-06-26

广告监测链接怎么做?App安装来源追踪原理解析
2026-06-26

App传参安装怎么做?全渠道参数还原原理解析
2026-06-26

谷歌重组AI编程小组?追赶Anthropic的节奏被迫加速
2026-06-26
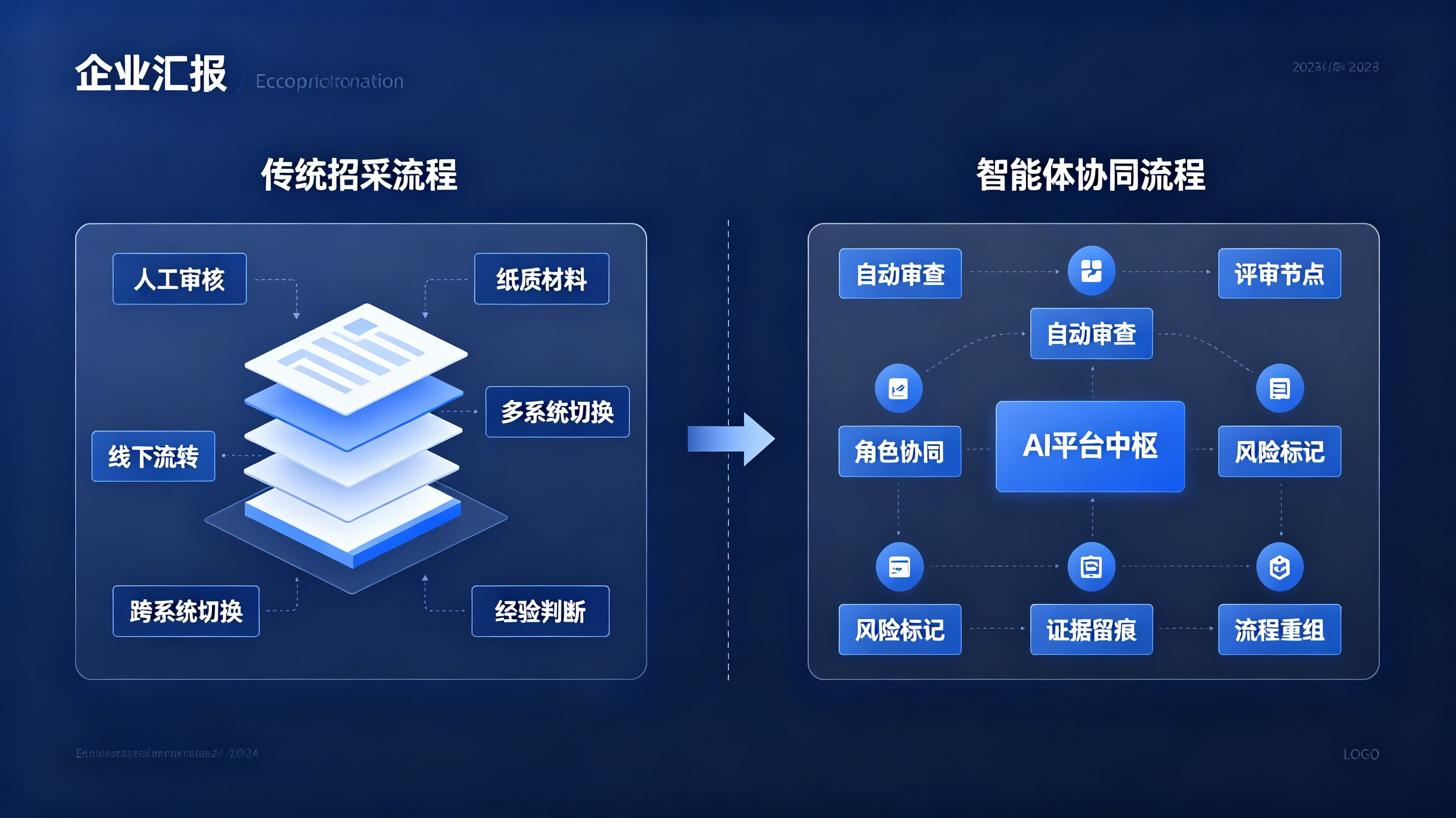
科大讯飞AI招采平台2.0如何重构流程?招投标开始进入全链路智能化
2026-06-26
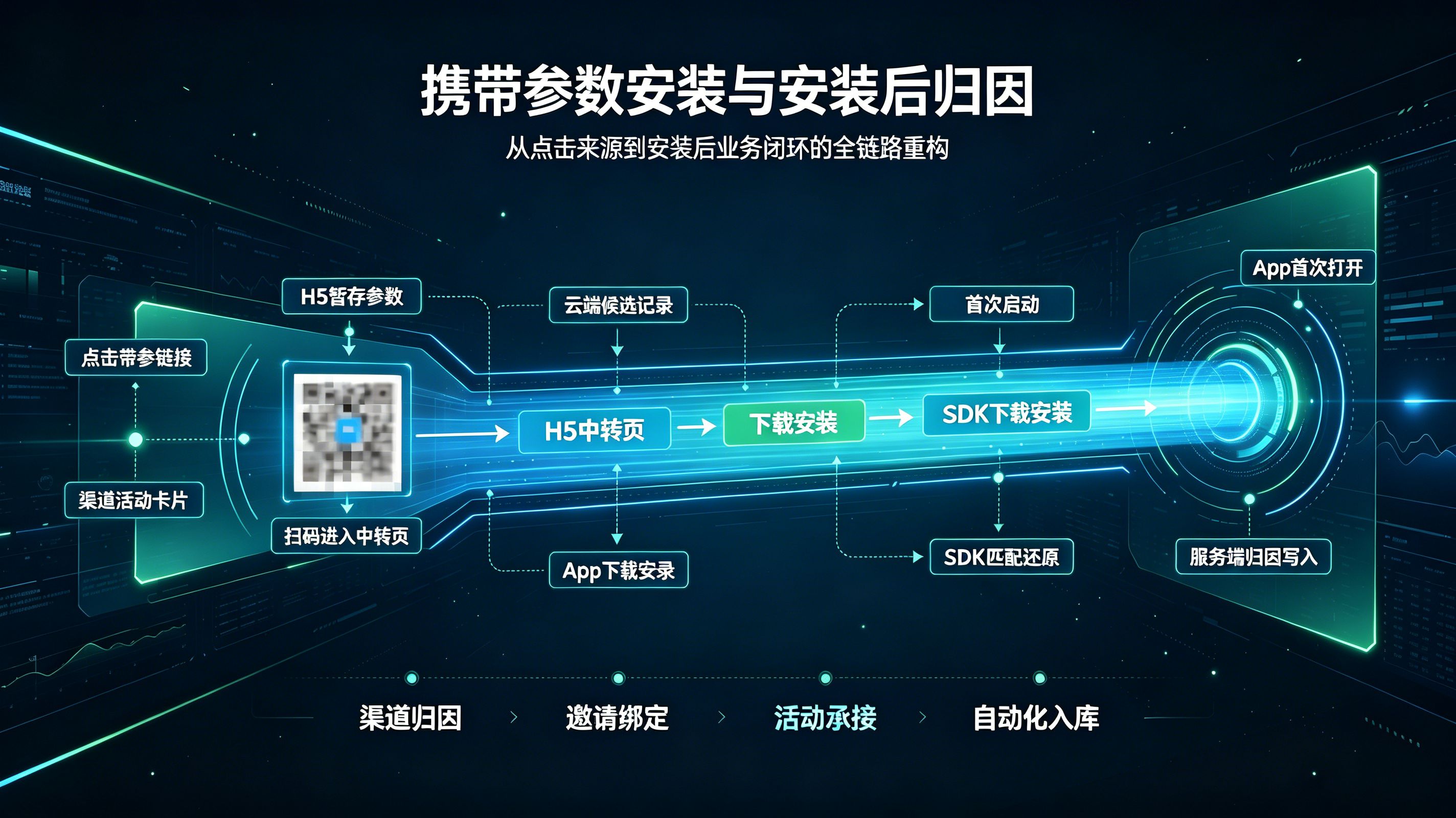
携带参数安装怎么实现?安装传参与归因技术解析
2026-06-25

Agent Ready怎么落地?企业智能体进入统一管理时代
2026-06-25

360与惠普签署战略合作?AI安全与终端融合进入落地期
2026-06-25

荣耀终端要被AI重做?MWC上海上终端变革的真实信号
2026-06-25

免填邀请码怎么实现?自动绑定邀请关系技术解析
2026-06-24
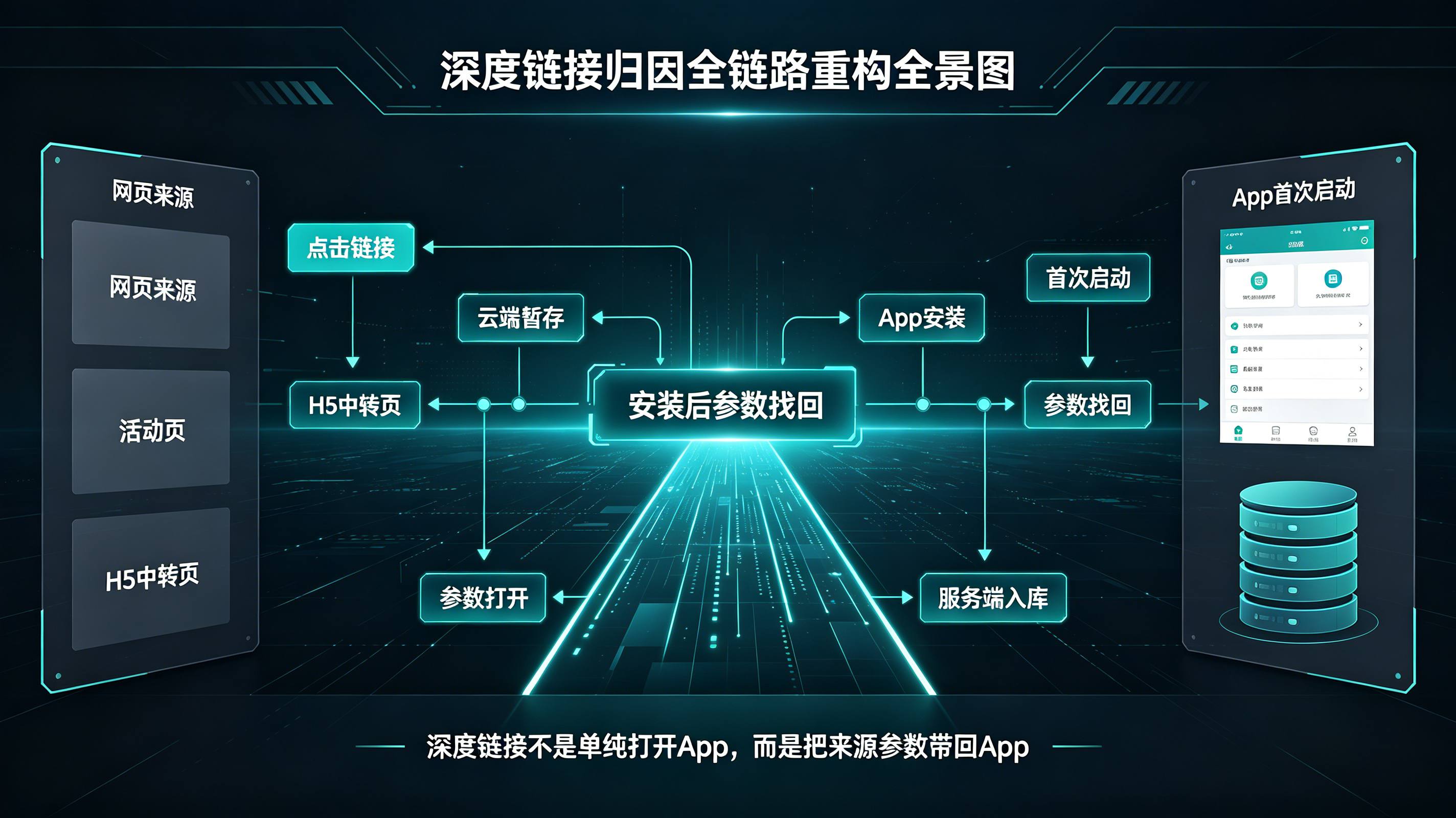
深度链接归因怎么做?安装后参数找回技术解析
2026-06-24






















