






手机微信扫一扫联系客服
联系电话:18046269997



 APP安装免填邀请码
APP安装免填邀请码 社交分享效果统计
社交分享效果统计 广告投放数据统计
广告投放数据统计 CPA/CPS推广效果统计
CPA/CPS推广效果统计 App地推统计
App地推统计 App拉起
App拉起 网页/应用内直接安装
网页/应用内直接安装 Android多渠道打包
Android多渠道打包 App安装后自动绑定
App安装后自动绑定 App分享效果统计
App分享效果统计 Deeplink深度链接
Deeplink深度链接 手机微信扫一扫联系客服
 709
709Meta超级智能实验室首发Muse Spark大模型,宣告个人超级智能时代的全面降临。App开发者该如何利用ChannelCode与智能传参,接住由Agent主宰的无UI任务流量?
2026年4月9日,Meta超级智能实验室(MSL)毫无征兆地掷出了一枚重磅炸弹——内部代号为“牛油果”的首款原生多模态推理模型 Muse Spark 正式上线。当科技圈的极客们还在为它极具人类特征的“视觉思维链”和“多智能体编排”能力而狂欢时,App 开发者、产品经理与增长操盘手们却面临着一场前所未有的危机:当高达30亿的社交平台用户开始习惯由“超级智能”代劳一切,传统的App页面跳转与流量分发漏斗即将彻底崩塌。面对海量看不见、摸不着的“机器任务流量”,你的App还能接得住吗?
要理解这场流量入口的底层巨变,我们必须先剥开 Muse Spark 的技术外衣,看看扎克伯格和他的“华人天团”在过去九个月里到底酝酿了怎样的一场革命。
Muse Spark 的诞生背景极具戏剧性。去年夏天,备受瞩目的 Llama 4 遭遇史诗级滑铁卢,甚至卷入刷榜风波,导致Meta的大模型战略一度陷入被动。为了夺回通用人工智能(AGI)的主动权,扎克伯格大刀阔斧地重组了AI部门,成立了超级智能实验室(MSL),并力邀前 Scale AI 联合创始人、年仅29岁的 Alexandr Wang 出任首席AI官。
这支汇聚了赵晟佳、毕树超、Jason Wei 以及前蚂蚁集团RL实验室首席科学家吴翼等顶尖华人大牛的团队,在短短9个月内,从零开始重构了Meta的整套AI技术栈——包括基础设施、模型架构和数据管线。其结果是惊人的:Muse Spark 达到与 Llama 4 Maverick 同等性能所需的算力,整整减少了一个数量级以上,算力利用率实现了恐怖的跃升。
作为一款原生多模态大模型,Muse Spark 彻底摆脱了早期模型只能“看图说话”的局限。在大模型测评平台 Artificial Analysis 上,它的智能指数直接飙升至52分,稳居行业第一梯队。
更具突破性的是,Meta 为其引入了全新的“沉思模式”(Contemplating mode)。在这种模式下,模型可以调度多个智能体(Agent)并行推理。在极度困难的 HLE(人类最后的考试)基准测试中,沉思模式让 Muse Spark 拿下了58%的正确率,在CharXiv Reasoning(技术图表分析)等测试中更是直接击败了 Claude Opus 4.6。这种“让模型在给出答案前先思考”的测试时推理(Test-Time Reasoning)机制,使得 Muse Spark 能够像顶尖工程师一样拆解复杂任务。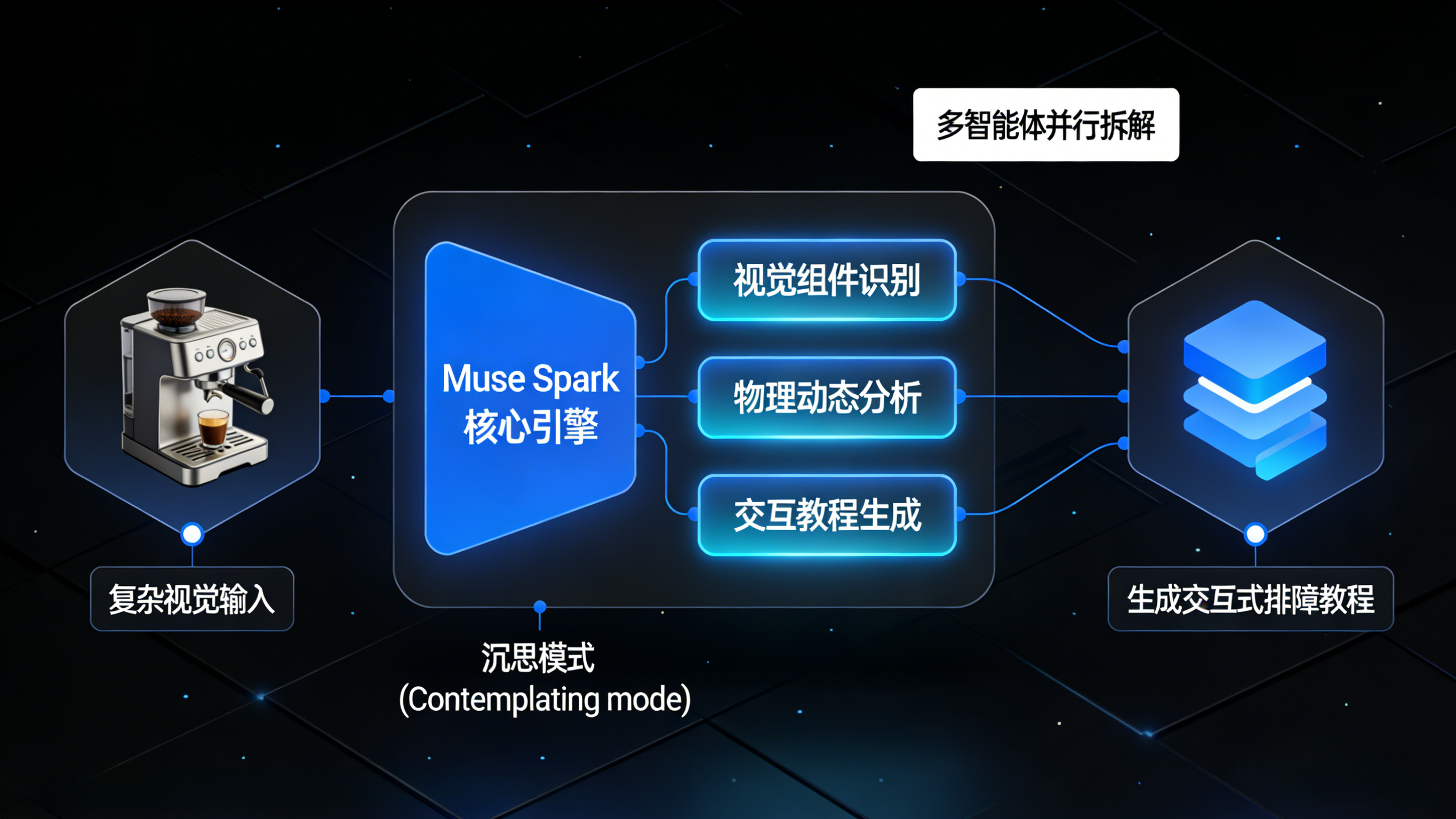
与许多仅仅追求刷榜的通用大模型不同,Muse Spark 的定位极其明确:构建面向个人的超级智能。它不只是一个处理文本的聊天框,而是能够“看见并理解你周围世界”的数字延伸。
在实际演示中,用户仅需上传一张豆包App的截图,Muse Spark 就能在几分钟内1:1复刻出完整的交互网页;用户拍下一台咖啡机,它能精准识别组件并生成带有动态边界框的交互式拉花教程;在医疗健康领域,凭借1000多名医生的专业数据微调,Muse Spark 甚至能根据用户的胆固醇指标和食物照片,动态生成个性化的营养评分与饮食建议。这种深入物理世界、执行高度个性化任务的能力,正是它最可怕的护城河。
从 Llama 系列的“开源基座”,到如今 Muse Spark 的“闭源私有API预览”,Meta 正在悄然完成从“造轮子”到“做入口”的战略转身。《36氪:阿里电商AI新动向:围绕Token重构电商》中曾指出,未来的交互核心将围绕Token和指令展开。而坐拥数十亿月活的Meta,显然意图让 Muse Spark 成为这些用户的终极交互枢纽。当用户买东西、查资料、做计划都不再打开一个个独立的App,而是直接向个人超级智能下达语音或视觉指令时,App 的前端 UI 将被彻底旁路,传统的“人机交互”正在光速演变为“机机交互”。
在AI研究员们为 Muse Spark 通过“六边形小球弹跳测试”而欢呼时,视角平移到App开发者和数据分析师的工位上,这场交互革命却是一场不折不扣的流量灾难。
在传统的移动互联网增长模型中,流量的漏斗是清晰且由“人”主导的:用户看到信息流广告 -> 产生兴趣点击 -> 跳转落地页 -> 唤起应用商店 -> 下载激活App。在这个过程中,无论是利用设备指纹、Cookie还是传统的UTM尾巴,数据中台都能将这笔“人物流量(Human Traffic)”的来龙去脉算得清清楚楚。
但当流量的主宰者变成 Muse Spark 这样的个人超级智能时,整条链路瞬间“失明”了:
假设用户对着 Meta AI 眼镜说:“帮我买一款适合我车型的博世雨刮器”。Muse Spark 经过“沉思模式”的复杂推理,最终在后台静默调用了你的汽配电商App的API,或者直接给用户生成了一个下载你App并跳转到该商品页的链接。
当“任务流量(Task Traffic)”取代“人物流量”,失去归因能力不仅意味着App团队无法衡量接入各大Agent平台的ROI,更意味着App彻底失去了对这笔高价值机器流量的定价权与运营抓手。
面对“无UI”分发带来的系统黑盒与意图孤岛,App必须抛弃对页面跳转和设备指纹的路径依赖,利用更底层的参数流转技术,重建被机器切断的握手协议。
问题:未来不仅有 Meta 的 Muse Spark,还有 OpenAI、各种开源的 .skill 插件甚至实体机器人。当唤起App的节点碎裂成成千上万个Agent工作流时,如何收束和追踪这些隐秘的流量入口?
做法:App需要放弃粗放的宏观渠道包,转而为每一个开放给AI生态的API接口、每一个入驻Meta或各大模型的应用助手,分配专属的底层标识。通过渠道编号 ChannelCode技术,当 Agent 生成App的唤起指令或下载链接时,底层已自动强制嵌入该追踪 ID。
带来的好处:将混沌的机器分发网络重新网格化。通过全渠道统计看板,开发者能清晰地看到究竟是 Muse Spark 带来了最高的激活率,还是某个开源 Agent 工作流带来了最高的订单转化,从而为后续的算力API开放策略提供精准的数据支撑。
问题:即使 Agent 在输出的链接中带上了参数,一旦跨越应用商店的鸿沟,用户在首次冷启动App时,因为操作系统的阻断,这些上下文参数依然会彻底丢失。
做法:引入强大的云网协同基建。当 Muse Spark 引导用户前往下载页面时,服务端的特殊短链会将该 Agent 抛出的上下文参数(如 agent_platform=meta_muse, intent=buy_wiper, item_id=12345)短暂悬挂在云端。当用户完成安装并在手机上首次打开App的毫秒间,App内置的 SDK 会瞬间向云端发起握手请求,也就是业界成熟的智能传参安装逻辑,精准取回并还原这些被拦截的业务参数。
带来的好处:实现了真正意义上的跨系统“懂你所想”。App可以直接跳过通用的开屏广告与繁琐注册,将用户直接传送到指定的雨刮器购买页面,甚至实现免填邀请码或自动应用专属折扣。这种极简的承接体验,是挽救任务流量漏斗的唯一杀手锏。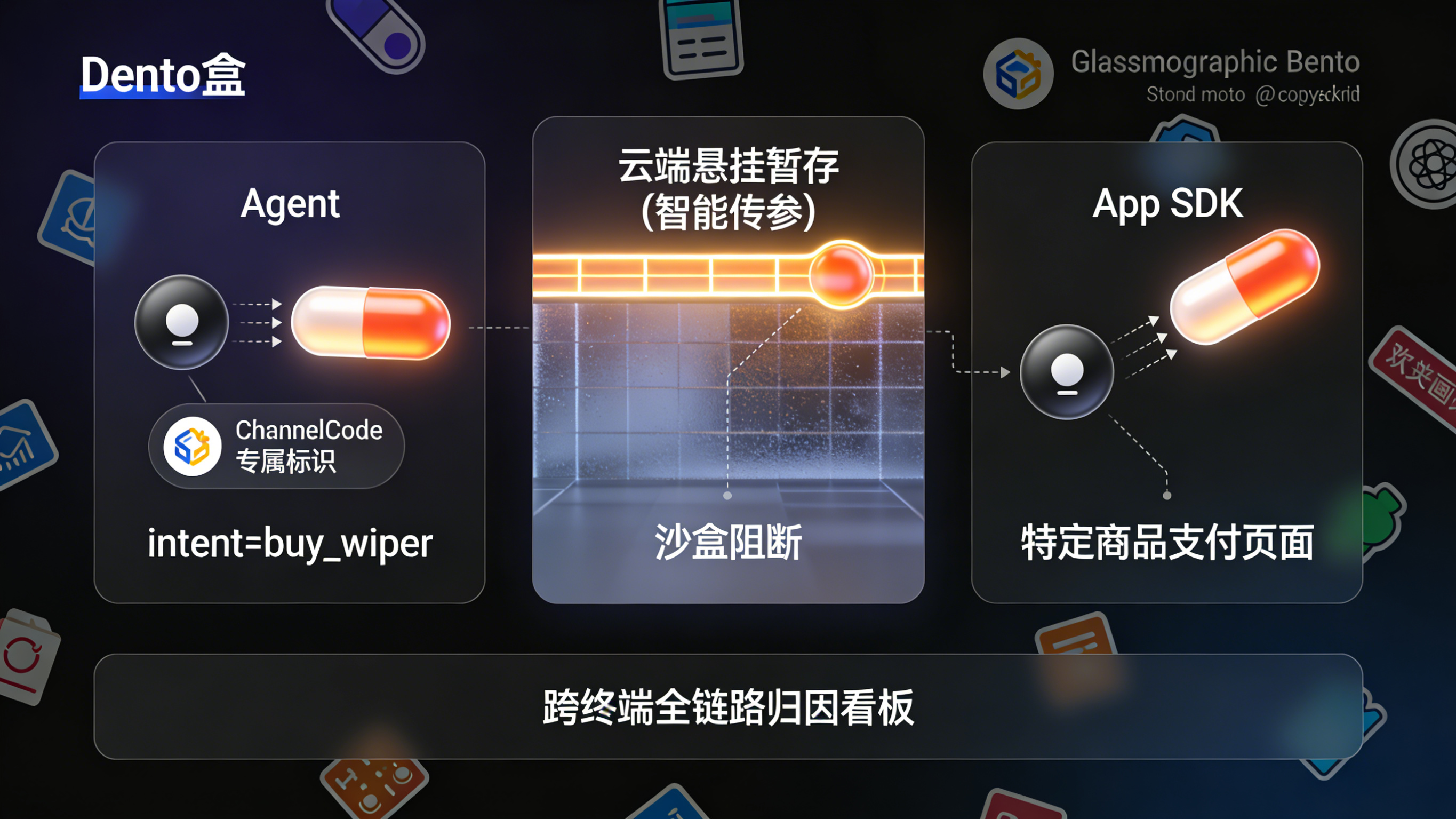
当流量来源从单一的手机屏幕演变为空间计算设备(如 Meta AI 眼镜)与手机的跨端协同,单一的唤起已经不够。企业需要在数据仓中构建跨终端的事件图谱,利用 workflow_id 等自定义参数,将用户在眼镜端发起的语音意图,与最终在手机端App内完成的支付事件完美缝合。
注:本文探讨的跨Agent系统的极度细分流量追踪、基于智能体指令集的静默唤起与参数云端悬挂等场景,属于对未来智能体分发趋势的前瞻性技术延展与思考。目前受限于各大科技巨头严格的隐私沙盒政策,此类高度定制化的跨生态链路尚未作为标准功能全量实现。如App开发者有类似高阶业务与跨云追踪需求,欢迎联系 Xinstall 客服团队进行技术探讨或共同定向研发拓展。在架构思路上,可重点参考业界前沿的《智能体指令集 Skills.sh 发布:AI Agent 分发生态下的 App 归因新范式》。
随着 Muse Spark 等个人超级智能的全面铺开,传统的App团队必须迅速完成从“服务于人”到“服务于机器”的作战姿态调整。
agent_id、scene、risk_level)。Muse Spark 是由 Meta 内部新成立的超级智能实验室(MSL)研发的首款原生多模态推理模型,内部代号为“牛油果”。它不仅能处理文本,还能直接理解图像、视频和现实物理环境,具备工具调用、视觉思维链和多智能体协同能力,是 Meta 迈向“个人超级智能”的核心基础设施。
“沉思模式”是 Muse Spark 针对复杂任务推出的一种极限推理机制。开启该模式后,模型不会立刻输出答案,而是会在后台调度多个 AI 智能体并行推理,将复杂问题拆解为多个子步骤。这种测试时推理(Test-Time Reasoning)技术大幅提升了模型的逻辑上限,使其在 HLE(人类最后的考试)等权威测试中取得了惊人的58%正确率。
去年发布的 Llama 4 模型在性能和口碑上遭遇严重挫折,使得 Meta 在 AGI 竞争中一度落后。为了扭转局势,Meta 创始人扎克伯格重组了 AI 团队,任命 Alexandr Wang 为首席 AI 官。新团队在9个月内从零开始彻底重构了基础设施、模型架构和数据管线,大幅提升了算力利用率,最终孕育出了性能实现跨代跃升的 Muse Spark 模型。
从 OpenAI 的强化推理模型,到如今 Meta 交出 Muse Spark 这份高分答卷,巨头们在通用人工智能领域的角力已经进入了最残酷的“深水区”。但更值得行业警惕的,是这场技术革命背后隐藏的商业模式洗牌:AI 的价值正在从“提供生产力工具”迅速向“垄断流量分发入口”转移。
当“个人超级智能”成为30亿人连接数字世界与物理世界的唯一代理人,应用分发市场将迎来二十年来最大的变局。那些依然死守着应用商店排名、指望用户在屏幕上主动搜索下载的 App,将在浩浩荡荡的机器流量暗战中被彻底边缘化;而能够迅速重构底层参数逻辑、利用 ChannelCode 和智能传参将自身服务完美融入 Agent 任务生态的先行者,必将拿到通往下一个十年的珍贵船票。

亚马逊季度营收首次破2000亿美元?云与广告双轮驱动下B端应用迎来分发与归因重构
2026-07-31

千问已在特斯拉车机内测?大模型上车打通跨端服务与全渠道归因新闭环
2026-07-31

Win11七月更新上线?桌面环境能力升级加速PC端智能助手与应用分发一体化
2026-07-30

悟空大圣上映5天票房仅15万?国产动画宣发失灵暴露渠道归因黑洞
2026-07-30
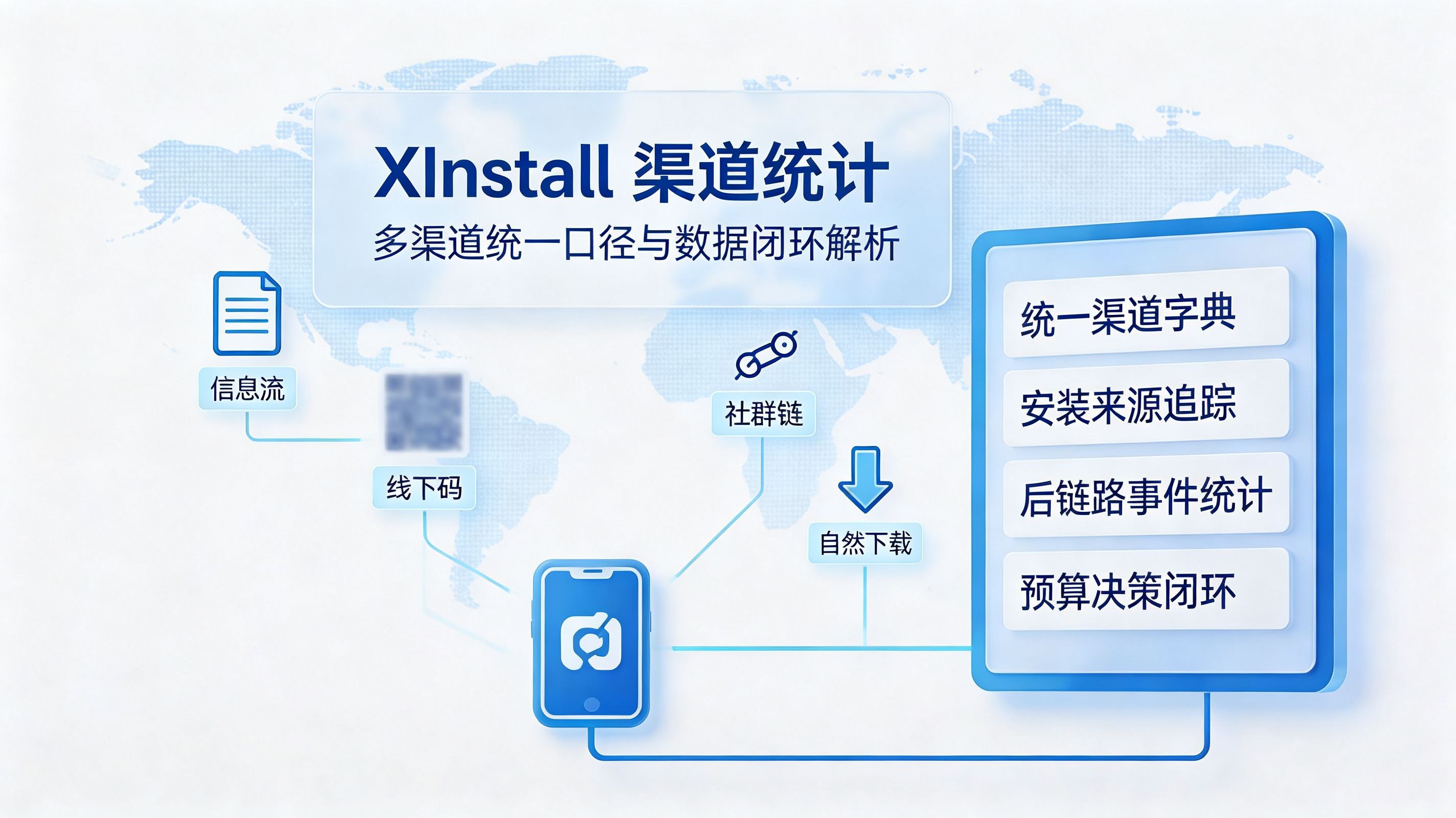
Xinstall 渠道统计怎么做 ?多渠道统一口径与数据闭环解析
2026-07-29

Xinstall 传参安装怎么实现 ?端云协同与参数透传机制解析
2026-07-29

闲鱼AI服务订单暴涨157%?轻创业热潮催生智能传参刚需
2026-07-29

美团CatPaw智能工作台上线?本地生活巨头入局重塑B端智能分发链路
2026-07-29

OceanBase首轮融资达30亿?国产底层架构重组或催生全渠道归因新标配
2026-07-29

Xinstall 免填邀请码怎么实现 ?携带参数安装底层架构解析
2026-07-28

Xinstall 跳转失败怎么排查? 内链失效与唤起链路治理指南
2026-07-28

极氪全新车型今日上市?车机生态繁荣催生跨屏应用深度链接基建
2026-07-28

苹果全新系统正式发布?底层隐私收紧倒逼移动端应用归因策略突围
2026-07-28

腾讯官宣QQ宠物回归?经典IP变身大模型智能体考验全链路追踪
2026-07-28

腾讯Miora向全球开放?巨头智能体生态加速多端全链路归因
2026-07-27






















