






手机微信扫一扫联系客服
联系电话:18046269997



 APP安装免填邀请码
APP安装免填邀请码 社交分享效果统计
社交分享效果统计 广告投放数据统计
广告投放数据统计 CPA/CPS推广效果统计
CPA/CPS推广效果统计 App地推统计
App地推统计 App拉起
App拉起 网页/应用内直接安装
网页/应用内直接安装 Android多渠道打包
Android多渠道打包 App安装后自动绑定
App安装后自动绑定 App分享效果统计
App分享效果统计 Deeplink深度链接
Deeplink深度链接 手机微信扫一扫联系客服
 152
152算电协同从“东数西算”的基础配套,正在升级为AI时代的新型供给系统。示范项目投运、四部门联合方案发布、绿电直供与智能调度提速,说明AI应用的稳定性、时延、成本与可扩展性,越来越取决于“电从哪来、算在哪跑、任务何时调度”。对开发者、产品经理和增长负责人而言,这不只是能源行业的新故事,更是应用分发、任务承接与全链路归因必须重写的前奏。
 算电协同迎价值重估,这条新闻表面上讲的是能源、电网、储能和数据中心,实际上讲的是 AI 应用未来会建立在怎样的一套供给系统上。过去很多团队谈增长,习惯盯投放、转化、留存和页面路径;但在 AI 时代,真正决定应用能不能稳定承接任务的,已经不只是前台产品设计,而是后端算力和电力能不能协同工作。今天这件事值得写,不是因为资本市场又多了一条主线,而是因为应用链路开始从“流量逻辑”走向“供给逻辑”。
算电协同迎价值重估,这条新闻表面上讲的是能源、电网、储能和数据中心,实际上讲的是 AI 应用未来会建立在怎样的一套供给系统上。过去很多团队谈增长,习惯盯投放、转化、留存和页面路径;但在 AI 时代,真正决定应用能不能稳定承接任务的,已经不只是前台产品设计,而是后端算力和电力能不能协同工作。今天这件事值得写,不是因为资本市场又多了一条主线,而是因为应用链路开始从“流量逻辑”走向“供给逻辑”。
从材料看,这轮“算电协同”升温,不是单点消息推动,而是项目落地和顶层设计同步推进。一边是宁夏中卫的大规模算电协同绿电直供项目正式投运,意味着“东数西算”第一次更清晰地实现了从风光电到数字算力的直连;另一边是国家发展改革委、国家能源局、工业和信息化部、国家数据局联合印发《关于促进人工智能与能源双向赋能的行动方案》,说明这件事已经从地方尝试走向国家级框架。
这和过去很多“新概念”最大的不一样,在于它不是讲未来遥远愿景,而是供给端已经开始接实物、接项目、接政策。项目给出验证,政策给出方向,资本市场再顺势把“源网荷储算”拉成主线。对于做 App、AI 产品、Agent 服务和企业级数字化工具的人来说,这不是“电力行业利好”,而是你所在的应用环境,正在被重新定义。
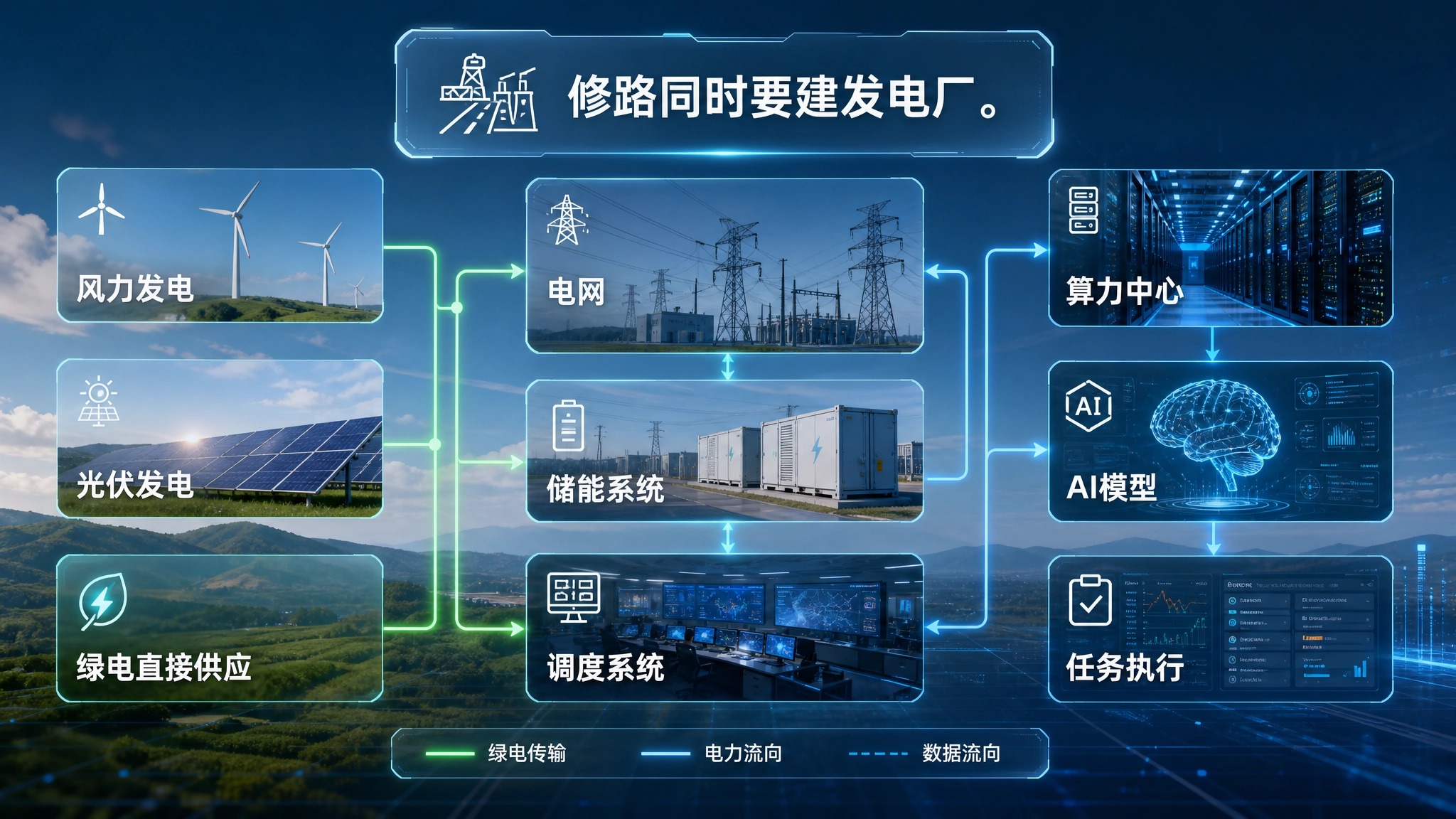
如果把传统互联网时代的基础设施比作“修路”,那 AI 时代的基础设施更像“修路同时要建发电厂”。原因很简单:传统 App 的边际成本低,用户多了,服务器开销会上升,但不会像 AI 一样每一次调用都对应真实的推理成本、算力调度和能源消耗。可一旦应用背后是大模型、Agent、多轮调用、实时生成,那系统每多承接一个任务,后端就会多承担一笔实打实的算力和电力成本。
所以过去“有云就行”的思维,到了 AI 时代已经不够。现在要问的是:算力建在哪?用什么电?什么时候跑最划算?能不能在波谷时段训练、在绿电富余时段处理高负载任务?能不能让算力负荷反过来配合电力调度,而不是只当一个不断吞电的黑洞?这就是新闻里强调“空间协同”和“时间协同”的真正含义。
也就是说,算电协同不是在给 AI 产业做辅助,而是在决定 AI 能不能以更低成本、更高稳定性、更大规模继续往前走。谁掌握更好的算电协同能力,谁就更可能拥有更强的产品供给能力。
很多人对“东数西算”的印象,还停留在把数据中心搬到西部、利用低成本电力和土地资源。但这次材料里更值得注意的是,“东数西算”正在往“源网荷储算”演进。也就是说,不只是算力位置被重构,连电源、电网、储能、负荷和计算设施本身都在进入同一个协同系统。
这对应用团队意味着什么?意味着未来一个任务的完成路径,已经不只是“用户点一下—服务器执行—结果返回”这么简单。它背后越来越像一个复杂的动态系统:任务发起后,系统要判断当前算力资源、能源价格、绿电占比、储能状态、调度优先级,再决定这个任务在哪跑、何时跑、以什么成本跑。
换句话说,用户看到的是一个 AI 问答、一个图片生成、一个代码助手、一个智能客服,但系统实际处理的已经是“任务—算力—能源—调度”四位一体的链路。应用团队如果仍然只盯着前端交互,而忽略底层供给系统,后面会越来越难解释为什么某些任务稳定、某些任务贵、某些任务慢、某些任务无法扩展。
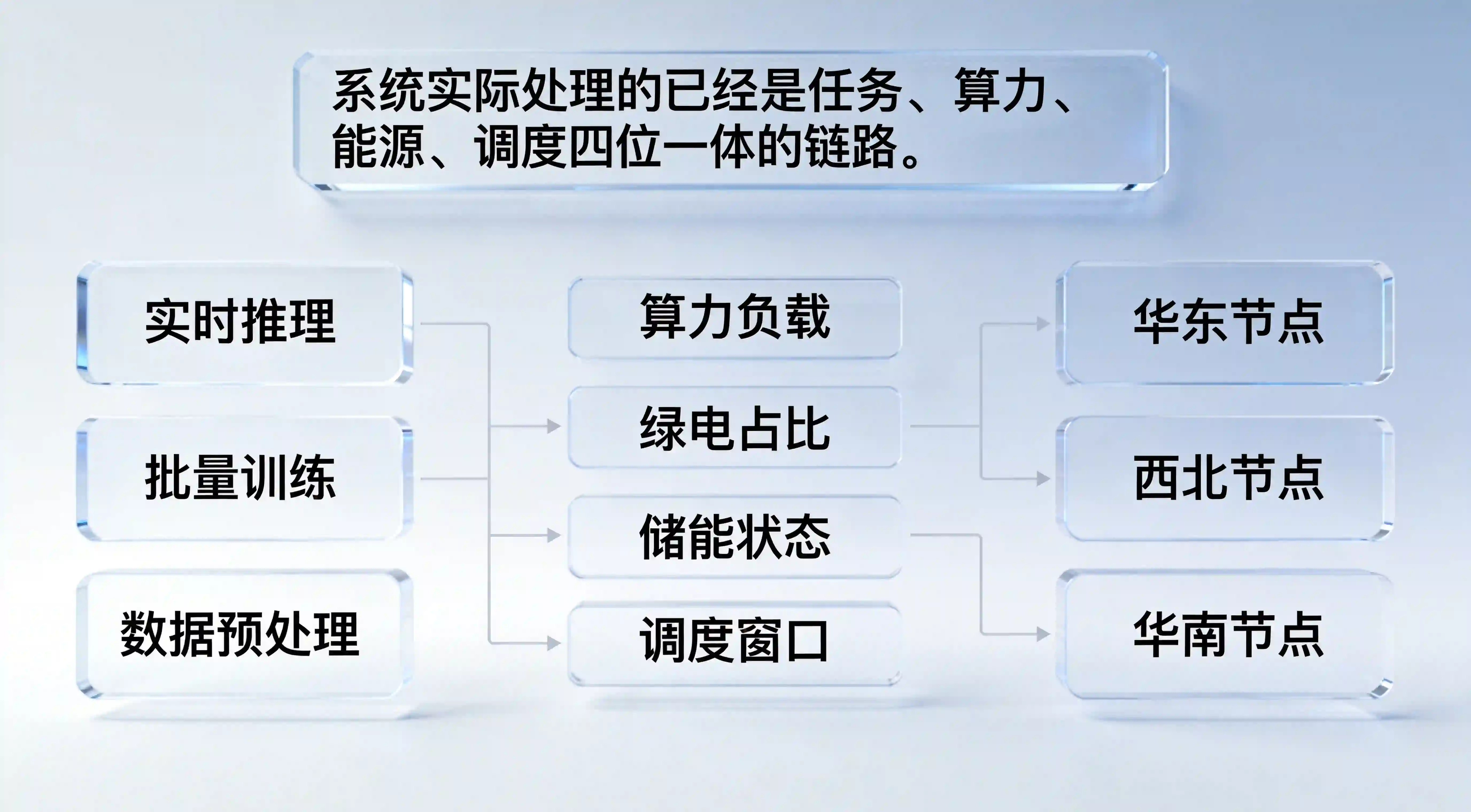
这条新闻最容易被误读成一条能源投资线索,但如果放到 xinstall 视角里,更重要的问题其实是:当应用的可用性越来越依赖底层算电协同,原来那套用户路径分析还有多少解释力?
过去做增长时,团队最熟悉的是页面漏斗。用户从广告、自然流量、活动入口或分享链接进入 App,完成注册、激活、浏览、转化,路径大致发生在单设备、单会话、单系统里。可 AI 应用进入高频调用时代之后,事情开始变化:
这会带来一个很重要的变化:未来很多“体验问题”并不是页面设计问题,而是链路供给问题。比如用户为什么在某个场景里生成更慢、为什么某段时间任务响应更稳、为什么某个区域调用更便宜、为什么某些企业客户更适合被接到特定节点,这些都已经不只是前端指标能解释的事。
也就是说,AI 应用的增长分析会越来越像“任务完成分析”,而不是“页面点击分析”。只看注册、点击、停留、转化,已经不足以解释真实的产品表现。团队必须把后台的任务调度、资源路径和供给状态一起纳入理解框架。
问题是什么?
很多团队会把所有增长表现都归因到渠道质量、投放创意或者产品页面,但在 AI 应用里,用户最终体验还会受到任务调度和供给状态影响。如果不先把入口来源分清,后面就很难判断问题到底出在获客,还是出在承接。
做法是什么?
更稳妥的方式,是先用渠道编号 ChannelCode思路区分不同入口:广告入口、内容入口、分享入口、场景入口、企业工作流入口、系统级入口等。再把这些入口与后续任务完成情况分开观察,而不是简单看最终转化。
带来的好处是什么?
这样团队能先知道“谁把用户带进来了”,再去判断“为什么后面的任务完成效果不一样”。很多时候问题不是渠道差,而是不同入口带来的任务类型差异太大,对底层资源的要求也不同。
问题是什么?
在 AI 应用里,最容易丢失的不是点击数据,而是任务语境。用户明明从一个具体场景进入,比如营销文案生成、客服知识问答、图像分析或代码修复,但一旦进入后端调度,系统如果拿不到足够上下文,就很难做更优分配。
做法是什么?
这里适合采用智能传参思路,把 scene、task_type、intent_level、workflow_id、entry_source、region_hint 这类参数在任务发起时一并带入。这样后端接到的不是一个抽象请求,而是一条带语境的任务。
带来的好处是什么?
一方面,用户体验会更稳定,因为系统知道这个任务对时延、稳定性、生成质量的要求;另一方面,团队分析数据时也更清晰,因为每次调用都不是孤立事件,而是一条带着来源和目标的任务链。
问题是什么?
页面漏斗适合看“谁看了什么、点了什么”,但不适合解释“任务为什么在不同供给状态下表现不同”。尤其在算电协同环境下,很多关键差异发生在页面之后。
做法是什么?
更合适的做法,是围绕任务建立事件图,把 entry_channel、task_type、workflow_id、dispatch_region、energy_mode、latency_bucket、result_status、retry_count 这些节点串起来。这样你看到的不是一个页面序列,而是一条任务真正完成的路径。
带来的好处是什么?
团队就能分辨:到底是哪个入口更值钱,哪类任务更消耗资源,哪些场景最依赖底层协同,哪些任务明明有需求却常在供给端掉链子。这种视角,才更适合 AI 时代的产品分析。
注:本文提到的场景参数承接、任务链路识别、供给侧状态关联等,属于围绕 AI 应用与复杂基础设施协同趋势的工程化建议。不同终端类型、部署架构、算力资源、区域策略和业务模式差异较大,具体链路还原能力通常需要结合业务系统做定制化设计,不宜理解为所有场景下都能以统一方案直接落地。

如果你做的是 AI 应用、智能体平台、企业知识助手或自动化工作流,接下来系统设计里不能只监控接口成功率和页面埋点。你还需要开始关注任务在哪跑、成本如何、资源怎么调、哪些场景最吃供给能力。否则很多问题会停留在“感觉最近变慢了”,却永远找不到根因。
至少可以考虑补充这些字段:
这些字段不是为了好看,而是为了让你在问题出现时,知道它到底是入口问题、任务问题,还是供给问题。
过去产品经理很容易把体验问题理解成交互问题:入口不够清晰、按钮不够明显、路径太长、反馈不够强。但在 AI 时代,越来越多体验差异会来自底层资源协同。尤其当系统需要在不同时间、不同区域、不同能源状态下承接任务时,产品其实已经在和基础设施共同定义体验。
这意味着,产品负责人必须开始理解供给约束。不是每个任务都该被同等对待,不是每个场景都该走同一条执行路径,也不是每个高频能力都应该被无限放大。谁更早把产品设计和供给能力一起思考,谁就更可能在稳定性和成本之间找到平衡。
增长团队最习惯分析流量来源、激活率、转化率,但以后会越来越多地碰到另一类问题:用户明明来了,甚至发起了任务,可为什么最后没形成有效留存?有时候原因不在营销,也不在产品,而在任务没有被底层系统稳定接住。
所以增长解释必须升级。除了看用户来自哪里,还要看:
一旦你开始这样看数据,就会明白为什么“算电协同”看起来像基建新闻,实际上却和增长解释权直接相关。
因为 AI 应用每次调用都涉及真实算力和能源成本,后端供给方式会直接影响响应速度、稳定性和成本结构。对用户来说看到的是产品表现,对团队来说背后其实是算和电一起决定了体验上限。
因为它不是单纯的能源新闻,而是新的应用供给逻辑。随着任务越来越多地跨节点执行、跨系统调度、受供给状态影响,传统单页面、单会话的归因方式会越来越难解释真实转化。
绿电运营决定 AI 供给侧的清洁能源来源,储能系统解决风光波动和稳定负载之间的矛盾,电力调度设备则决定系统能不能把复杂任务高效分配出去。它们共同构成了未来 AI 应用稳定运行的基础层。
最现实的变化不是“要懂电力”,而是要承认:产品表现已经越来越受基础设施状态影响。未来很多增长优化和体验优化,必须同时看入口、任务和供给三条线,而不能只盯前端漏斗。
算电协同迎价值重估,真正值得行业关注的,不是又多了一条投资赛道,而是 AI 应用正在进入一个“供给决定增长上限”的阶段。过去应用竞争更像抢入口、抢流量、抢心智;接下来则会越来越像抢稳定供给、抢高效调度、抢可持续承接能力。
对开发者、产品经理和增长负责人来说,这条新闻最大的提醒是:不能再只用移动互联网时代那套方法理解 AI 应用了。当一个任务是否顺畅完成,已经同时取决于用户入口、任务类型、算力调度和能源协同,原来的页面漏斗、单端归因和静态渠道分析就会越来越失真。谁更早把“场景、任务、供给、结果”放进同一个分析框架里,谁就更有机会在下一轮 AI 基础设施升级中,看清真实增长从哪里来。
LingBot-Video开源会改写具身视频路线吗?具身智能世界模型正在以物理正确性为核心演进
2026-07-09

支付宝碰一下用户数破4亿会改写线下入口版图?线下AI触点已重组本地生活服务网络
2026-07-09

Grok 4.5发布会让自动化编程爆发?跨平台智能体调用需要独立追踪
2026-07-09

LingBot-Vision开源能解决空间感知?独立自动化追踪成底线
2026-07-08

GPT-5.6发布获美国商务部批准?独立自动化追踪成底
2026-07-08

Claude后门隐患被工信部通报?独立任务流量追踪成底线
2026-07-08

英伟达路线图遭遇产能质疑?底层算力波动倒逼任务流量精细化
2026-07-07

腾讯减持快手改变流量格局?头部生态解绑考验全渠道统计基建
2026-07-07

全球首例AI Agent勒索攻击曝光?AI完全接管黑客链路将如何颠覆生态
2026-07-06

生数科技发布视频大模型Vidu S1?实时交互技术突破或将彻底颠覆内容引流转化
2026-07-06

苹果首款折叠手机被曝出货量不足?全新屏幕终端形态或将彻底颠覆传统应用生态
2026-07-06

延迟深度链接怎么实现?安装后场景还原与归因技术解析
2026-07-02

Claude Sonnet 5把企业AI自动化成本打到四成?智能体时代中端模型正在改写选型逻辑
2026-07-02

AI无法替代人工成共识?人机协作正在重写企业增长与用工逻辑
2026-07-02

Cloudflare精细化AI流量管理上线?默认拦截训练爬虫保护广告与数据资产
2026-07-02






















