






手机微信扫一扫联系客服
联系电话:18046269997



 APP安装免填邀请码
APP安装免填邀请码 社交分享效果统计
社交分享效果统计 广告投放数据统计
广告投放数据统计 CPA/CPS推广效果统计
CPA/CPS推广效果统计 App地推统计
App地推统计 App拉起
App拉起 网页/应用内直接安装
网页/应用内直接安装 Android多渠道打包
Android多渠道打包 App安装后自动绑定
App安装后自动绑定 App分享效果统计
App分享效果统计 Deeplink深度链接
Deeplink深度链接 手机微信扫一扫联系客服
 261
261阿里、字节、腾讯在企业级AI领域分化出操作系统、知识网络与社交连接三条路线。面对极度碎片化的B端分发生态,App团队亟需通过全渠道归因看清究竟是哪个Agent工作流带来了真实转化。
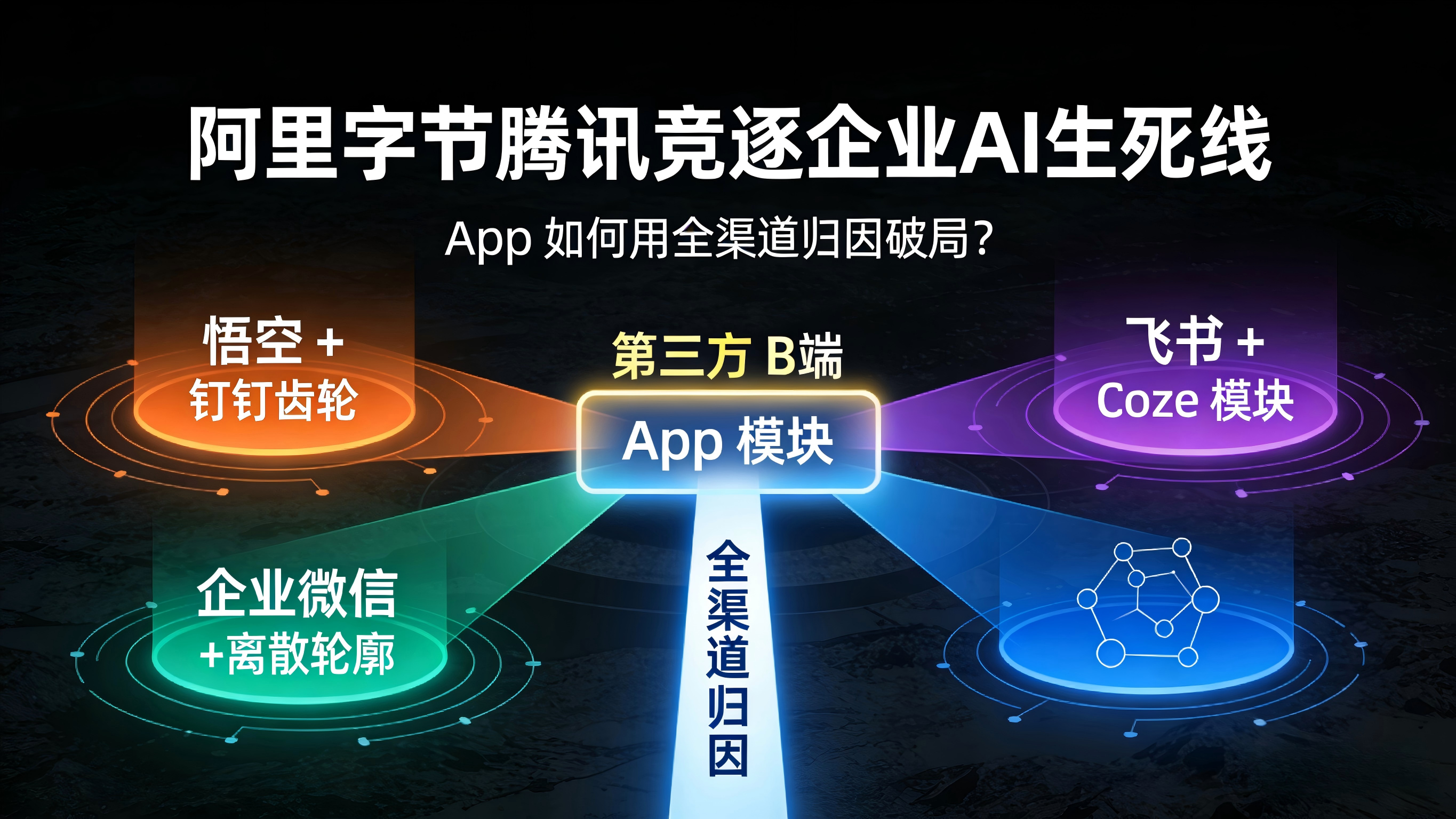 随着消费级大模型热度降温,阿里、字节与腾讯三大巨头已在企业级AI协作市场拉开了决定下一代商业效率的生死战。当底层办公系统逐渐被形态各异的智能体(Agent)接管,第三方B端App的流量入口与唤起场景正被彻底打碎。对于开发与增长团队而言,如何在极度碎片化的巨头调度逻辑中,精准追踪并算清每一笔业务转化的真实来源,成为了生死攸关的必答题。
随着消费级大模型热度降温,阿里、字节与腾讯三大巨头已在企业级AI协作市场拉开了决定下一代商业效率的生死战。当底层办公系统逐渐被形态各异的智能体(Agent)接管,第三方B端App的流量入口与唤起场景正被彻底打碎。对于开发与增长团队而言,如何在极度碎片化的巨头调度逻辑中,精准追踪并算清每一笔业务转化的真实来源,成为了生死攸关的必答题。
据36氪等平台的深度商业分析指出,当前三大互联网巨头的企业级AI战略已呈现出完全不同的“生态异构”形态。阿里以“悟空”为中枢,试图彻底重构钉钉底层,打造贯穿电商与供应链的商业操作系统;字节则依托飞书和Coze(扣子)低代码平台,主打可组装的敏捷知识协同网络;腾讯则坚守“连接”基因,利用企业微信打通内部办公与12亿C端私域流量。
这三种不同的路径,意味着未来企业协作模式将从“人机交互”全面转向“智能体自主执行”。对身处其中的第三方SaaS服务、OA工具或行业App而言,你的应用不再是挂在统一应用商店里的静态商品,而是将被这三家不同逻辑的数字员工(Agent)在后台高频调用的“积木模块”。终端环境正在从单一的人工点击,演变为多云、多系统、多智能体并存的复杂网状结构。
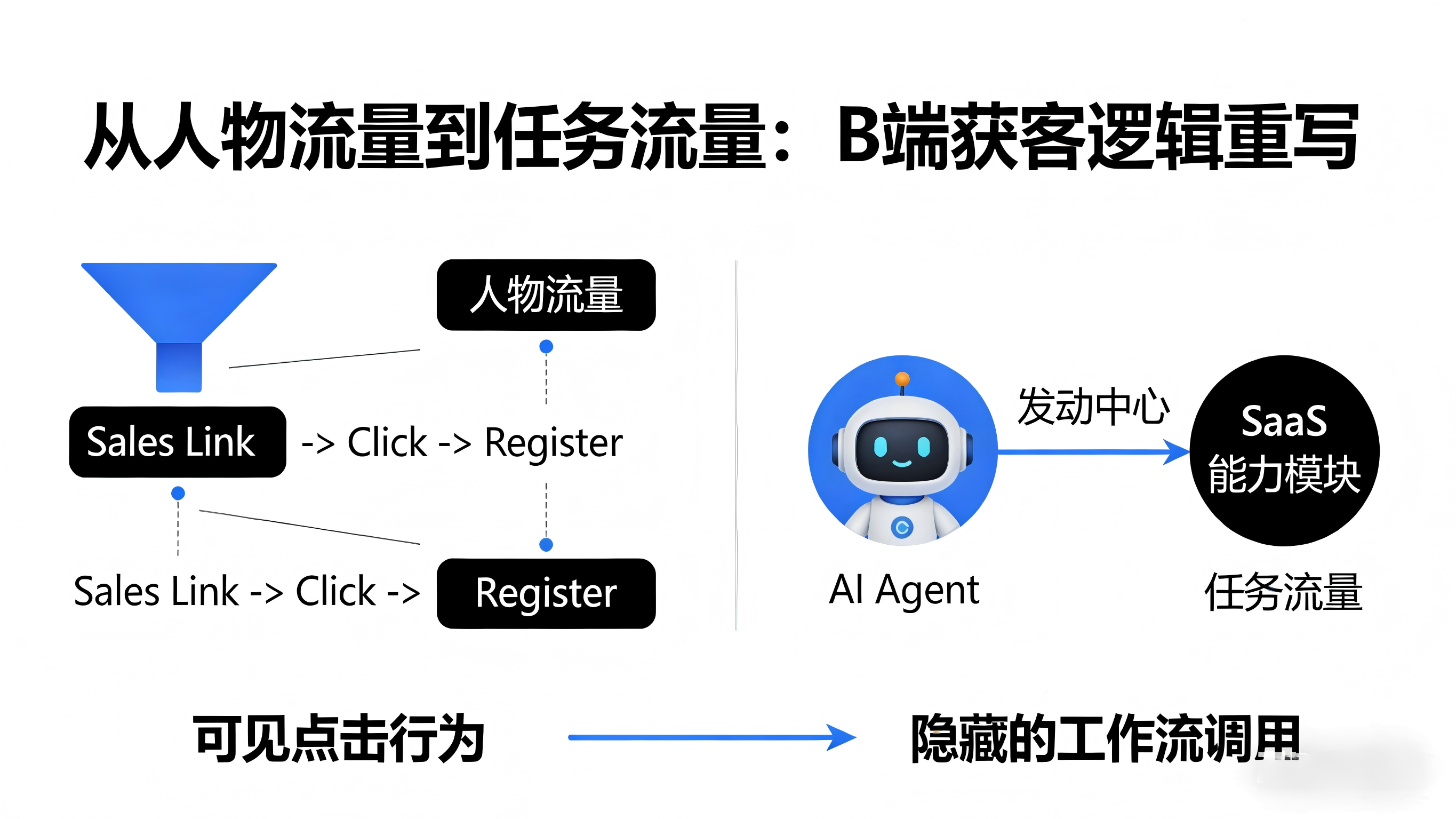
在这一范式转移下,传统的B端获客归因链路已经失效,应用内部的流量结构发生了本质变化。
过去,SaaS或App增长主要依赖用户直接在应用内产生的“人物流量”——销售点击链接、下载注册并开通账号。但现在,大量的调用属于外部Agent工作流发起的“任务流量”。比如,阿里的“悟空”在自动比价时调用了你的供应链App接口,或者字节的Coze智能体在生成报告时拉起了你的数据看板。
这就导致了现有的归因与埋点体系出现严重盲区。当平台报表只显示“本月接口调用量激增”或“新增若干企业注册”时,你根本无法从系统黑盒中分辨:这是真实用户的自然新增,还是来自腾讯WorkBuddy的调度?这些任务是从哪个平台的工作流发起的?如果无法看清这些多云、多Agent生态下的真实流量来源,B端团队就无法评估在不同巨头生态中投入的研发与对接资源是否收回了成本。
为了在“三国杀”的复杂生态中守住自己的数据主权,App开发者必须在底层重构针对任务流量的归因体系。
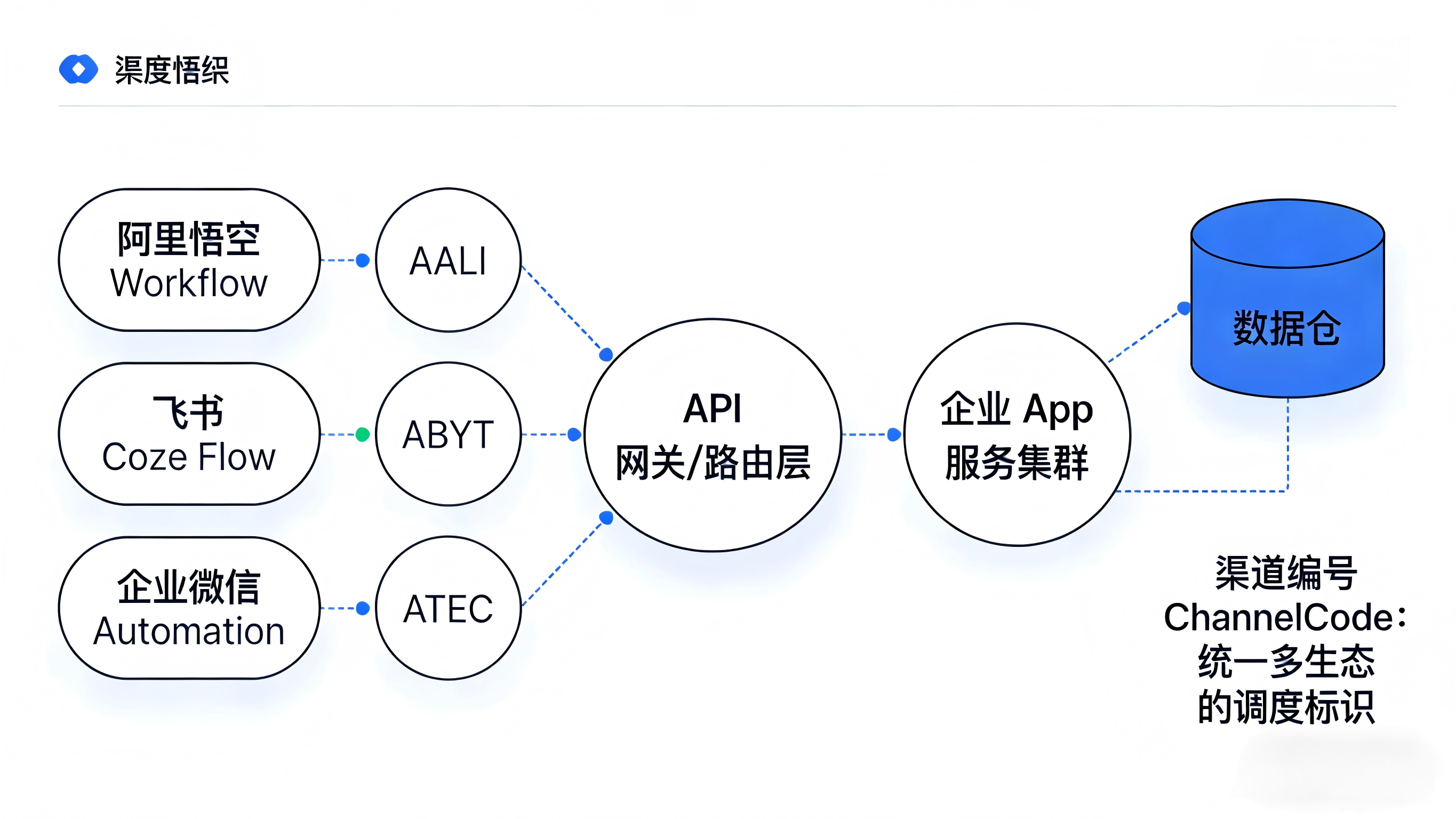
面对阿里、字节、腾讯迥异的系统架构,第三方App绝不能用一套接口“裸奔”承接所有流量。开发团队需要为每一个接入的智能体平台或外部低代码工作流分配专属的渠道编号 ChannelCode。所有的跨端拉起与API请求,必须在参数中强制携带此标识,从而在网关层就精准切分出不同生态的流量来源,避免陷入巨头平台的黑盒统计。
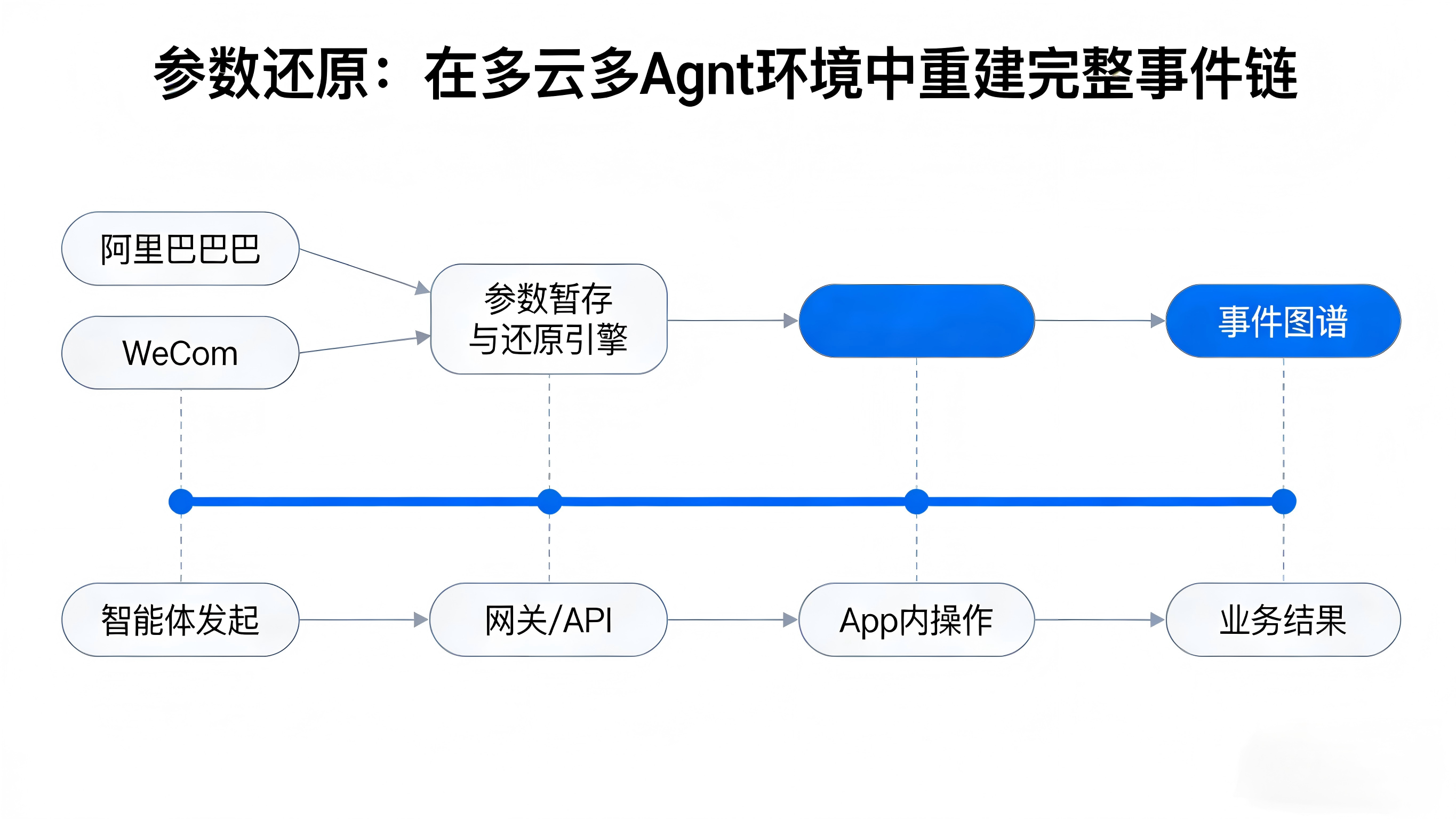
在实际的业务履约中,任务的流转往往会跨越多个终端或系统。正如《亚马逊 AI 战略升级?多云多 Agent 时代 App 该怎么认清流量真身》一文中所拆解的逻辑,你可以利用参数还原技术,在Agent触发调用时暂存上下文信息。当你的App被拉起或在另一台设备上完成授权激活时,系统能瞬间将 workflow_id、agent_platform 与具体的任务场景(Scene)重新串联起来,在数据仓内构建出一张清晰的跨系统事件图。

将“人物流量”与“任务流量”的埋点彻底分离。利用全渠道统计能力,把来自钉钉的系统级指令、飞书的卡片调度以及企业微信的外部连接全部纳入统一的数据看板。通过对比不同维度的留存与活跃度,找出真正能为App带来高价值业务转化的智能体通道。
企业AI的演进要求内部团队必须从被动的工具提供者,转变为主动的数据管理者。
面向开发 / 架构团队:
agent_platform(标明阿里/字节/腾讯)、workflow_id 和 risk_level,以适应极其复杂的Agent身份验证。面向产品 / 增长团队:
企业AI平台都在推自己的闭环生态,第三方App还能获取到完整的归因数据吗?
只要你的App作为服务履约方参与了核心节点的交互,就可以通过标准化的URL参数、Header或剪贴板技术进行标识。巨头的闭环主要体现在前端交互,但在系统间的数据交接处,利用传参技术依然可以合规地留存来源凭证。
引入针对Agent流量的归因机制,会大幅增加研发部门的维护成本吗?
不会。成熟的全链路参数还原机制基本已经组件化,它通过旁路日志上报和轻量级的参数拼接来实现,与App的核心业务逻辑是解耦的。实际上,提前梳理好归因字段,反而能省去后期在多套系统中扯皮排错的时间。
面对这三家的不同架构,我们的App该优先对接哪个生态?
这取决于你的产品基因。如果你的App偏向供应链、交易与重度数字化线索,应优先关注阿里的生态流量;若是重在内容沉淀、创意协同,飞书的组件化更适合切入;而如果你的核心场景是帮B端客户做私域和转化,带有社交基因的腾讯连接器则是首选。通过全渠道统计跑一段时间数据,自然会有明确的答案。
据雪球等多家财经平台的产业观察指出,企业级AI的竞争已经彻底告别了“技术炫技”阶段,正式回归降本增效的商业本质。未来不仅是BAT三家在角力,越来越多的垂直行业龙头也会推出自己的私有化Agent平台。
在这一进程中,第三方App对B端客户的影响力,将不再取决于其独立界面的精美程度,而在于其作为“能力插件”的稳定性与可观测性。现在正是重构数据与归因体系的最佳窗口期,只有把复杂的外部调用理成一本“明白账”,应用才能在从“人找事”向“事找人”的范式转移中站稳脚跟,真正享受到这波企业级AI的重构红利。

免打包渠道统计是什么?App免填邀请码技术原理解析
2026-06-23

二维码渠道追踪有什么优势?一人一码技术解析
2026-06-23
毁灭全人类游戏今日登陆新主机?爆款主机游戏跨端种草考验一键拉起基建
2026-06-23

火山引擎暂无拆分上市计划?巨头大模型深耕加速多云底层统计重构
2026-06-23

微信AI小微灰度上线?原生助手操作颠覆闭环渠道归因体系
2026-06-22

OpenAI获最大规模部署?三星接入ChatGPT企业版催生归因需求
2026-06-22

促进平台经济大中小企业协同发展行动方案?智能体成核心
2026-06-19

苹果Xcode27深度集成AI智能体?原生革新引爆场景还原归因
2026-06-19

小米MiMoClaw适配全新框架?终端洗牌确立智能传参获客标准
2026-06-18

寒武纪大涨超14%创新高?硬科技板块爆发倒逼全渠道统计
2026-06-18

上交所发布大模型上市指引?底层应用如何重塑流量归因
2026-06-17

OpenAI硬件全家桶曝光?从无屏音箱到AI伴侣,下一个流量分发中心会是谁
2026-06-16

支付宝测试AI版支付宝?支付巨头打响智能体生态战,开发者如何破解流量黑盒
2026-06-16

阿里发布首个具身大模型?机器人抢走入口,流量洗牌在即
2026-06-16

抖音生活服务文旅生态大会?你投在大屏的拉新二维码还在狂丢参数吗
2026-06-15






















