






手机微信扫一扫联系客服
联系电话:18046269997



 APP安装免填邀请码
APP安装免填邀请码 社交分享效果统计
社交分享效果统计 广告投放数据统计
广告投放数据统计 CPA/CPS推广效果统计
CPA/CPS推广效果统计 App地推统计
App地推统计 App拉起
App拉起 网页/应用内直接安装
网页/应用内直接安装 Android多渠道打包
Android多渠道打包 App安装后自动绑定
App安装后自动绑定 App分享效果统计
App分享效果统计 Deeplink深度链接
Deeplink深度链接 手机微信扫一扫联系客服
 325
325GitHub将用户代码默认纳入AI训练库引发开发者强烈抵制。在“无数据不AI,无数据不增长”的当下,SaaS工具与App出海团队该如何利用ChannelCode等底层技术,在追求精准归因的同时守住隐私合规底线?
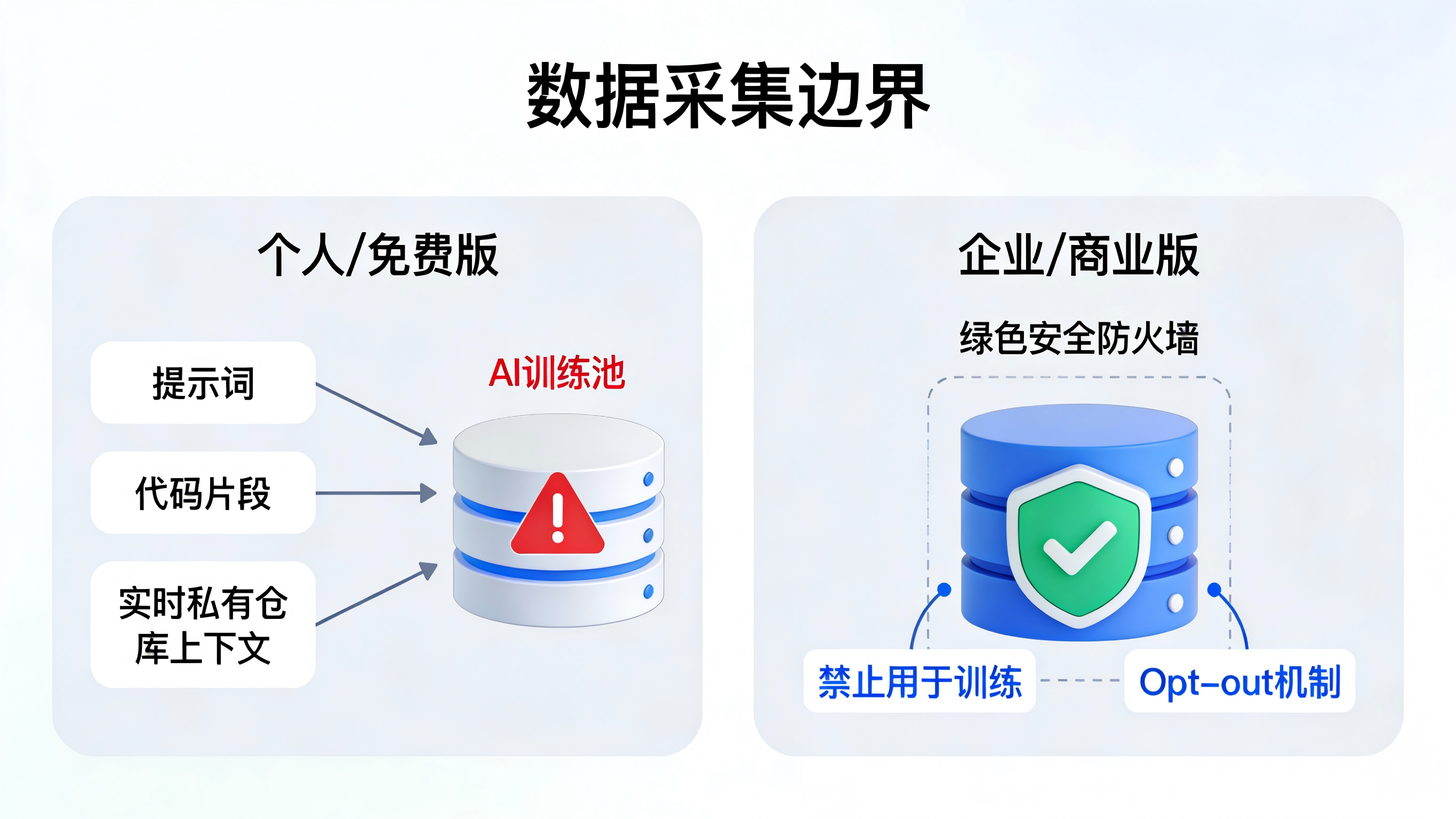 科技巨头的“霸王条款”再次点燃了开发者的怒火。近期,全球最大的代码托管平台 GitHub 宣布调整 Copilot 规则:自 4 月 24 日起,免费版和个人专业版用户的交互数据(包括输入代码、采纳的建议甚至私有仓库的实时读写上下文)将被“默认”用于训练其 AI 模型。用户若不想被“白嫖”,必须穿过迷宫般的设置页面手动退出。
科技巨头的“霸王条款”再次点燃了开发者的怒火。近期,全球最大的代码托管平台 GitHub 宣布调整 Copilot 规则:自 4 月 24 日起,免费版和个人专业版用户的交互数据(包括输入代码、采纳的建议甚至私有仓库的实时读写上下文)将被“默认”用于训练其 AI 模型。用户若不想被“白嫖”,必须穿过迷宫般的设置页面手动退出。
这一举动不仅引发了开源社区的集体讨伐,更撕开了一个横亘在现代软件工程与商业增长之间的深层矛盾:平台对海量“真实世界数据”的极度渴求,与终端用户(及开发者)对隐私安全底线的死守。
对于正在全球市场打拼的 SaaS 工具和出海 App 而言,GitHub 的翻车是一堂深刻的警示课:在依靠数据驱动归因与增长的今天,如何才能在不触碰隐私红线的前提下,算清流量账本?
在 GitHub 这次风波中,官方给出的辩护理由是“行业惯例”(Anthropic、微软等皆如此),并声称需要真实数据来优化模型。但科技媒体和开发者一针见血地指出了问题所在:
这种将“消费者当成产品”的做法,其实在早期的移动 App 买量和归因领域也曾大行其道。过去,App 开发者为了追踪广告转化,会肆无忌惮地抓取用户的设备指纹(如明文 IMEI、MAC 地址、甚至相册列表)。但随着欧洲 GDPR 的出台、苹果 iOS 隐私新政(ATT 框架限制 IDFA 追踪)以及国内《个人信息保护法》的收紧,粗放式的数据掠夺已成绝路。TikTok 等巨头如今都在重构合规的广告归因方案以应对隐私信号的丢失。
当 SaaS 工具或 App 进行拉新推广时,无论是投放信息流广告、KOL 分发还是老用户裂变,都需要解答一个核心问题:“这个新注册的高价值用户,到底是谁带来的?”
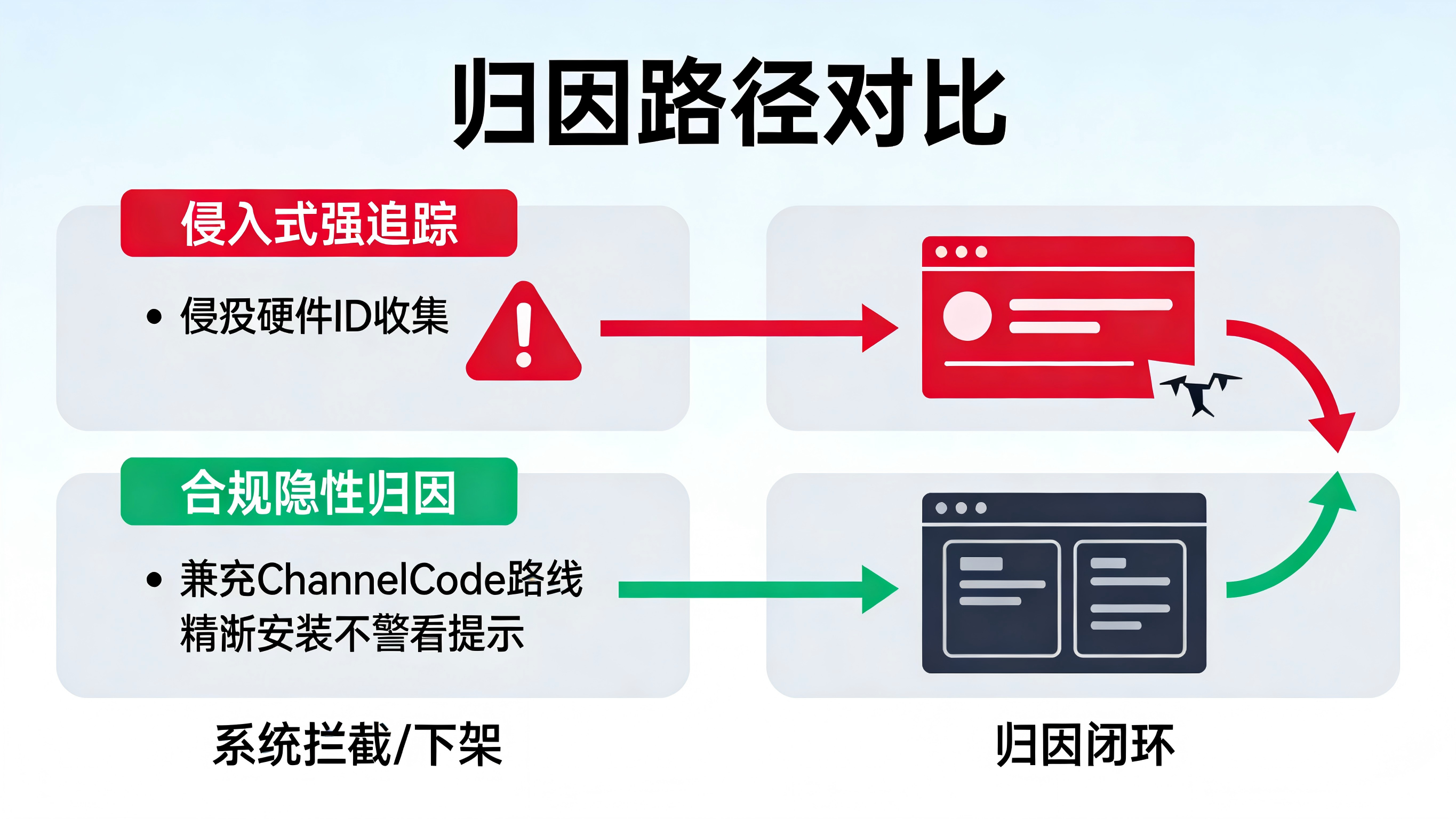
如果采用不合规的强侵入式追踪:
应用在用户首次安装打开时,不给任何提示就直接索要设备全量权限,甚至将账号身份与硬件指纹做强绑定。这种做法极易触发系统级弹窗警告(如 iOS 的“要求 App 不跟踪”),一旦用户拒绝,归因链路立刻断裂。此外,在应用商店上架审核或监管抽查时,这类隐蔽的追踪代码会直接导致 App 被下架。
如果因噎废食放弃归因:
面对极其碎片化的引流渠道(微信群、推特、海外独立站等),如果为了所谓“绝对合规”而放弃所有底层追踪参数,App 的增长团队将彻底变成瞎子。面对上百万的买量账单,无法分辨哪些渠道带来了真实的付费订阅,哪些渠道在用机器人刷量。
既要保护像“私有代码”一样的用户隐私,又要拿到像“模型训练”一样精准的转化数据,开发者急需一套更优雅的技术解法。
注:本文探讨的针对全渠道归因与合规数据追踪的技术,属于对高阶获客策略的前瞻性技术探讨。目前此类高度定制化的底层匹配机制旨在平衡追踪精度与隐私保护,如企业开发者在合规增长方面有类似痛点,欢迎联系 Xinstall 客服团队进行技术探讨或共同定向研发拓展。
为了避免重蹈 GitHub“强行授权”的覆辙,SaaS 及 App 开发者可以通过重构底层的全渠道统计框架,在不触及用户核心隐私的前提下完成归因闭环:
采用非侵入式的间接特征匹配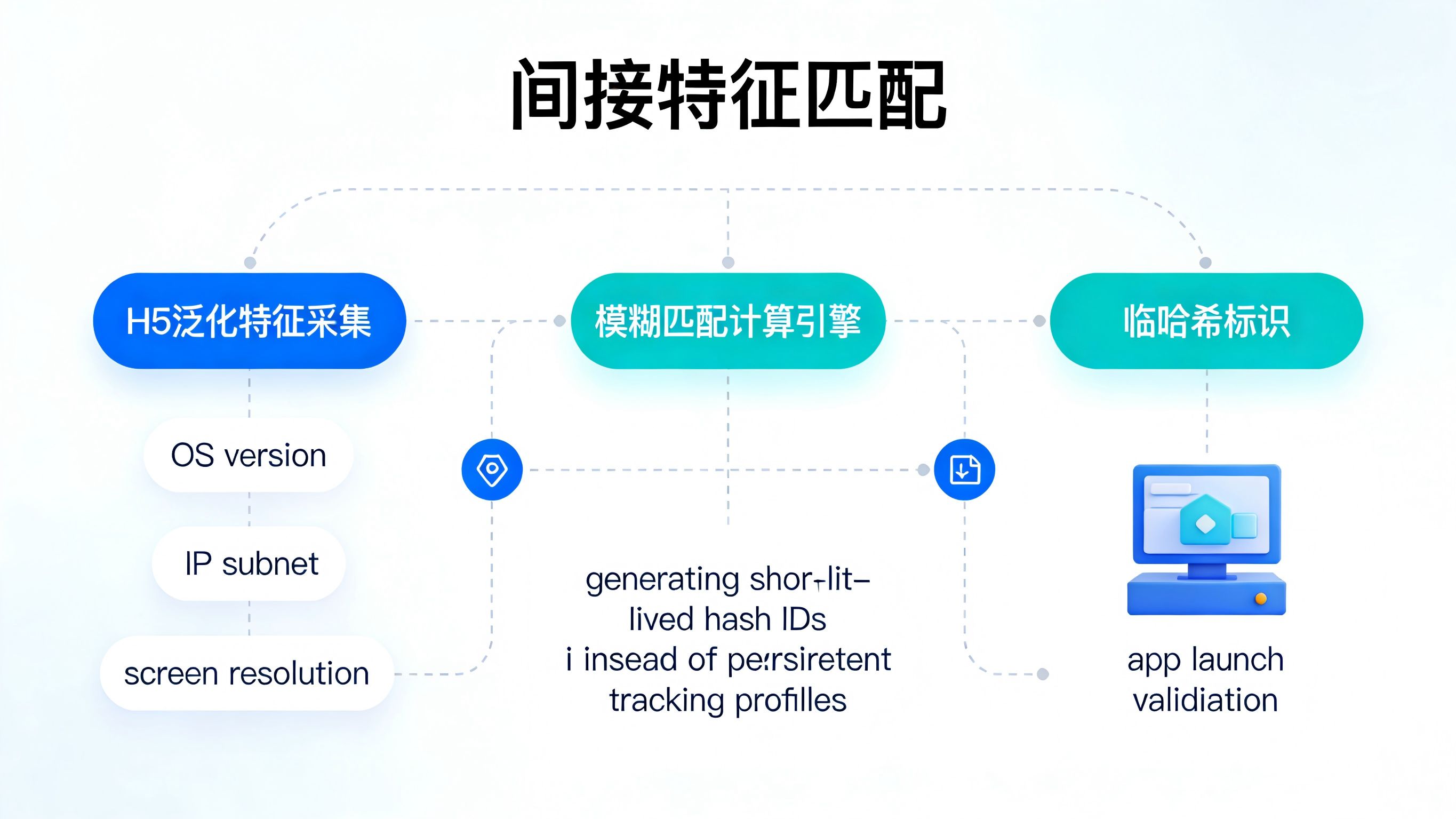
与传统的强制抓取硬件唯一标识不同,现代的归因技术(如 Xinstall 方案)通过采集非隐私的设备基础运行环境特征(如系统版本、屏幕分辨率、IP 网段等泛化数据),结合用户在下载环节的时序信号进行模糊匹配计算。这种机制不需要弹窗索要高危权限,避免了用户的抵触心理,不仅符合《个人信息保护法》中的“最小必要原则”,还能在 iOS 等受限环境下保持极高的归因准确率。
为每个触点分配独立的 ChannelCode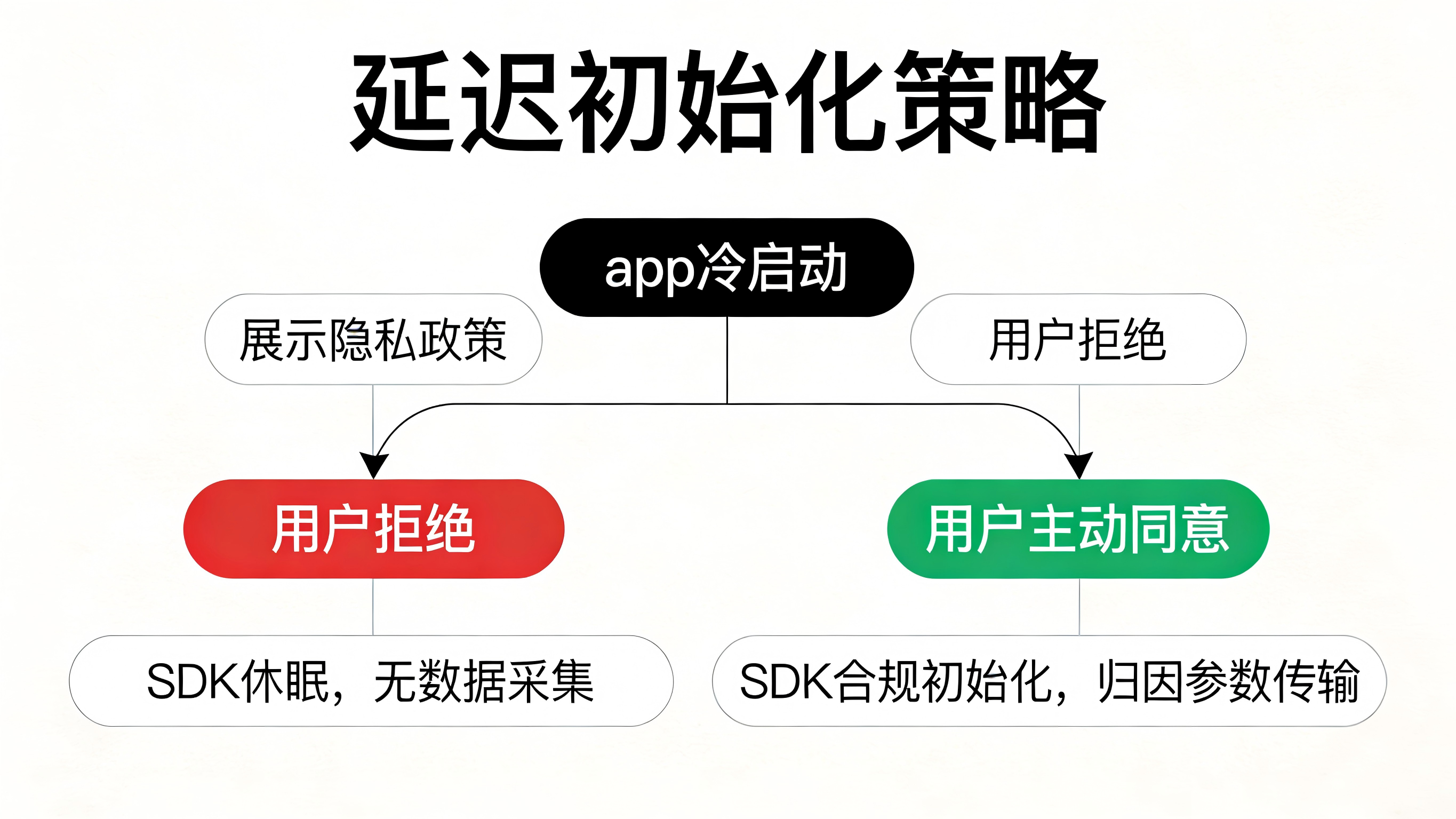
不需要在 App 端内给用户打上复杂的行为画像标签,而是把“识别”的工作前置到渠道分发端。通过在不同的推广链接或二维码中动态生成渠道编号 ChannelCode,当用户通过该链接下载安装时,系统将这个 ChannelCode 暂存。激活后,后台只需核对这个编号,就能精准统计出不同投放平台(如 Google、Meta 或是某个特定的 KOL)带来的新增量和活跃度,让营销优化有据可依,而不必像 GitHub 那样大面积扫描用户的私有行为内容。
把选择权交还用户:合规的初始化策略
优秀的追踪 SDK 会提供灵活的延迟初始化接口。开发者可以确保在用户明确阅读并同意《隐私政策》之前,SDK 不会收集任何信息。只有当用户点击“同意”后(Opt-in),追踪服务才开始合规地传递归因参数,彻底规避类似 GitHub“默认窃取”带来的信任危机。
面向开发 / 法务团队:
面向产品 / 增长团队:
如果采用非侵入式的特征匹配,归因准确率会下降吗?
传统的硬性 ID 匹配正在被全球操作系统逐步封杀。采用综合特征算法(如 Xinstall 的方案),在绝大多数标准推广场景下,归因准确率依然能保持在 98% 以上。更重要的是,这是在长期合规前提下唯一可持续的规模化追踪方式。
我们的应用有海外用户,这种追踪方式符合欧洲 GDPR 或加州 CCPA 吗?
合规的传参及统计 SDK 一般不留存能直接对应到自然人真实身份的明文数据(如姓名、真实物理地址等),而是采用匿名化的临时哈希标识进行短时段的转化匹配。只要开发者在出海应用的隐私协议中如实披露必要的数据收集用途(如用于广告防欺诈及转化结算),是完全符合当地监管要求的。
这是否意味着不用再强制用户绑定手机号或微信号了?
是的。如果是为了辨别拉新来源,ChannelCode 和底层参数匹配已经在后台完成了来源记录。产品团队无需在用户刚下载时就设置“注册登录”的高门槛去强行建立身份映射,这极大降低了转化漏斗的流失率。
GitHub Copilot 的规则大改,撕开了 AI 时代巨头对数据饥渴的一角。在可以预见的未来,无论是 AI 训练语料的采集,还是应用增长转化链路的追踪,用户对“数据主权”的敏感度只会越来越高。
在这个“隐私即信任”的新周期里,聪明的产品不会在暗处和用户博弈,而是通过坚实、合规的底层技术(如 ChannelCode 全渠道溯源与免填邀请码基建)去重构转化引擎。当你能用不侵犯用户底线的方式算清每一笔账,你就在同行的猜疑链中拥有了最牢固的护城河。
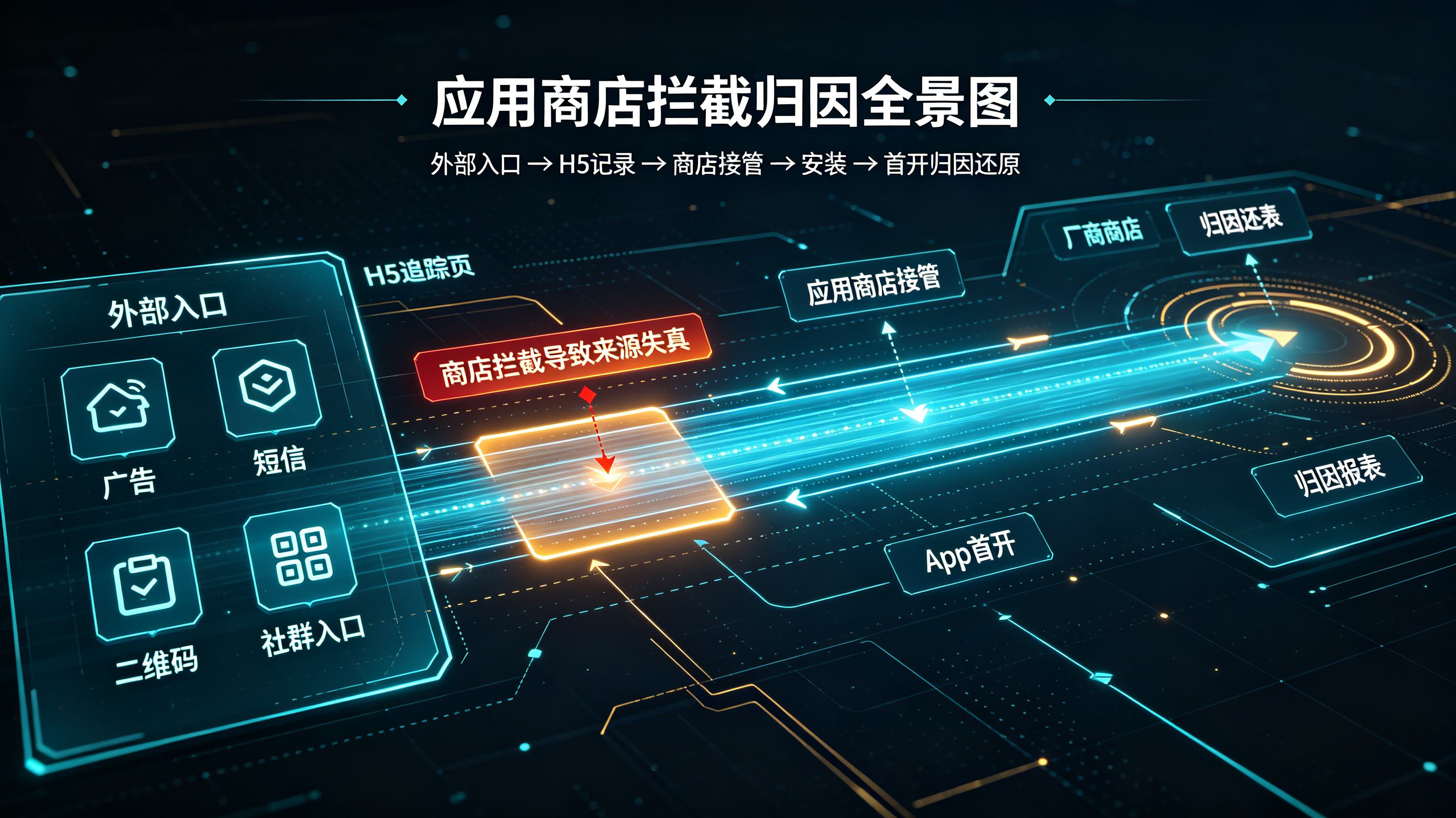
应用商店拦截后怎么归因?下载来源追踪原理解析
2026-06-26

广告监测链接怎么做?App安装来源追踪原理解析
2026-06-26

App传参安装怎么做?全渠道参数还原原理解析
2026-06-26

谷歌重组AI编程小组?追赶Anthropic的节奏被迫加速
2026-06-26
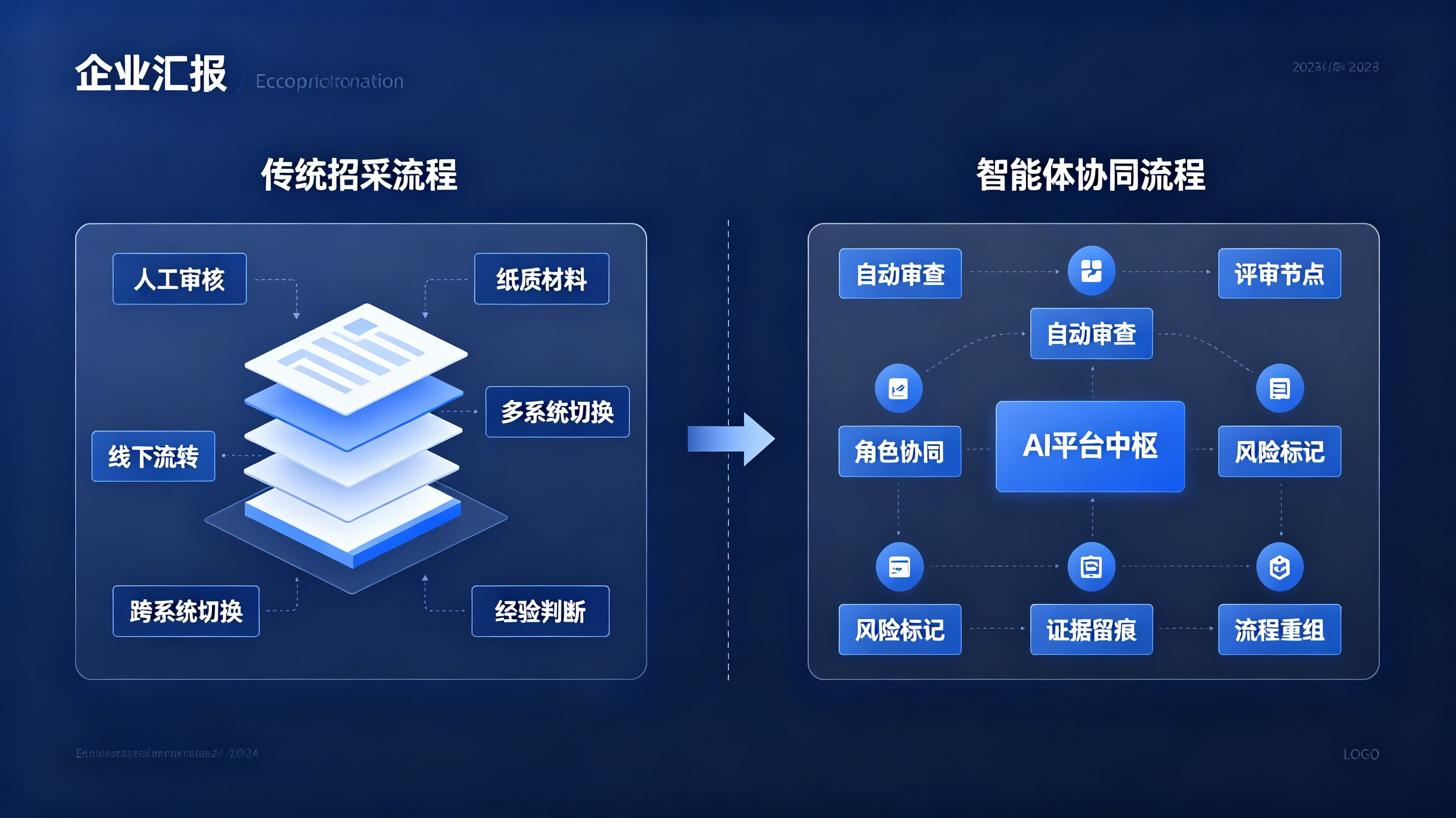
科大讯飞AI招采平台2.0如何重构流程?招投标开始进入全链路智能化
2026-06-26
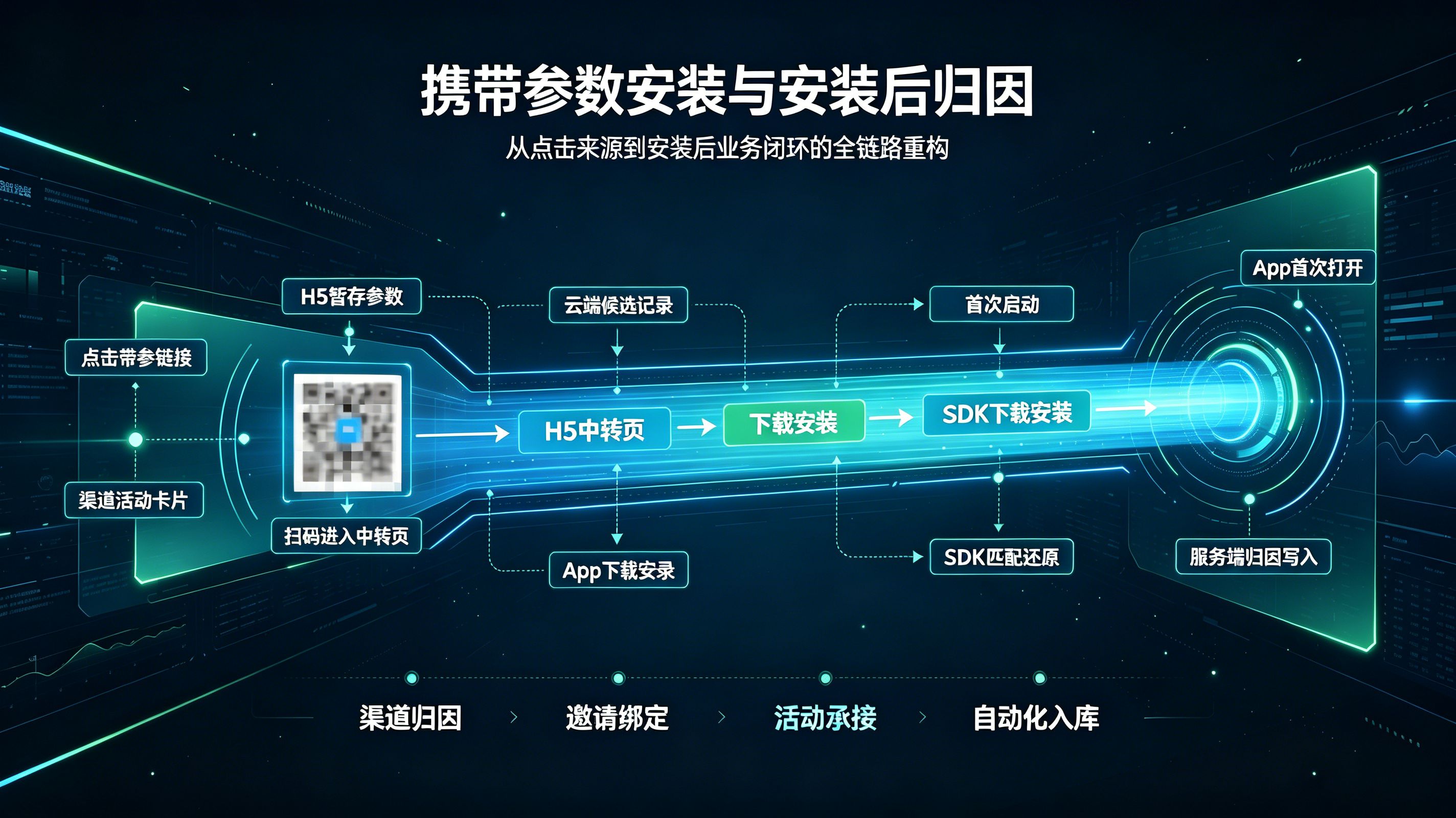
携带参数安装怎么实现?安装传参与归因技术解析
2026-06-25

Agent Ready怎么落地?企业智能体进入统一管理时代
2026-06-25

360与惠普签署战略合作?AI安全与终端融合进入落地期
2026-06-25

荣耀终端要被AI重做?MWC上海上终端变革的真实信号
2026-06-25

免填邀请码怎么实现?自动绑定邀请关系技术解析
2026-06-24
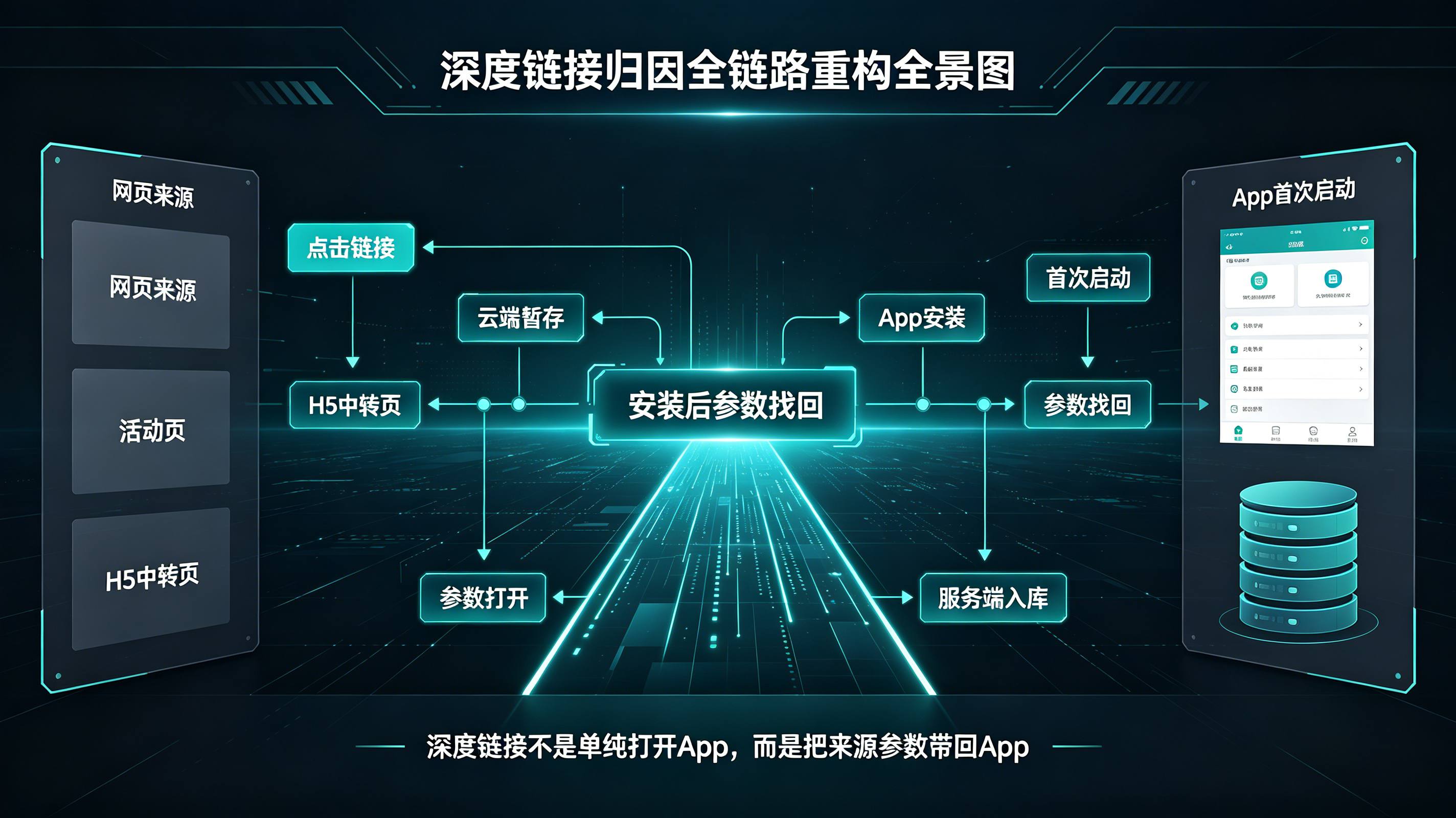
深度链接归因怎么做?安装后参数找回技术解析
2026-06-24

豆包专业版正式推出?AI收费战开打背后的订阅分层与商业验证
2026-06-24
毁灭全人类游戏今日登陆新主机?爆款主机游戏跨端种草考验一键拉起基建
2026-06-24
即梦AI上线原生4K视频生成?打破高糊魔咒,AI视觉算力重塑营销分发底座
2026-06-24

免打包渠道统计是什么?App免填邀请码技术原理解析
2026-06-23






















